cape webservices
1.0.0
Ponto de entrada para todos os webservices de backend da Cape.
A demonstração do Frontend está aqui (só funciona se você já lançou um Backend).
Cape é um conjunto de bibliotecas de código aberto para gerenciar um modelo de resposta a perguntas que responde a perguntas "lendo" documentos automaticamente. Ele é baseado em modelos de leitura de máquina de última geração treinados em grandes conjuntos de dados e inclui vários mecanismos para facilitar o uso e melhorar com base no feedback do usuário. Ele foi projetado para ser portátil , ou seja, funciona em um único laptop ou em um cluster de máquinas paralelas para acelerar a computação, e é compatível com código aberto para ser usado em todos os níveis de especialização.
Ele permite que os usuários
Existem várias maneiras de usar o Cape:
from cape_responder.responder_core import Responder
Responder.get_answers_from_documents('my-token','How easy is Cape to use', text ="Cape is an open source large-scale question answering system and is super easy to use!")
python3 -m cape_webservices.rundocker run -p 5050:5050 bloomsburyai/capeRecomendamos pelo menos 3 GB de RAM e pelo menos 2 núcleos de CPU modernos (4 se forem virtuais). Se você estiver usando o Docker, aumente os limites de recursos de memória nas preferências do Docker.
Você pode executar uma versão autônoma do webapp que inclui um painel de gerenciamento. Após instalar o docker, atualize e execute a imagem do Cape:
docker pull bloomsburyai/cape && docker run -ti -p 5050:5050 -p 5051:5051 bloomsburyai/cape
Isso iniciará os webservices de back-end e front-end. Por padrão, também criará túneis para ambos, gerando as URLs públicas:
RANDOM_STRING_HERE .ngrok.io?configuration={"api":{"backendURL":"https:// RANDOM_STRING_HERE .ngrok .io:5050","tempo limite":"15000"}} Extraia a versão mais recente da imagem do Docker (levará alguns minutos para baixar todas as dependências e um modelo de leitura de máquina): docker pull bloomsburyai/cape
Execute o contêiner Docker e inicie um console IPython dentro dele usando o seguinte comando: docker run -ti -p 5050:5050 -p 5051:5051 bloomsburyai/cape ipython3
Respondente de importação: from cape_responder.responder_core import Responder
Faça uma pergunta e armazene a resposta (que é uma lista de respostas) e exiba a primeira resposta usando: response = Responder.get_answers_from_documents('my-token','How easy is Cape to use?', text="Cape is an open source large-scale question answering system and is super easy to use!"); print(response[0]['answerText'])
Se você estiver interessado em entender um pouco mais sobre a aparência da resposta, exiba a resposta completa usando: print(response)
Para instalar o Cape nativamente em um sistema Linux, dê uma olhada em implantação/Dockerfile.
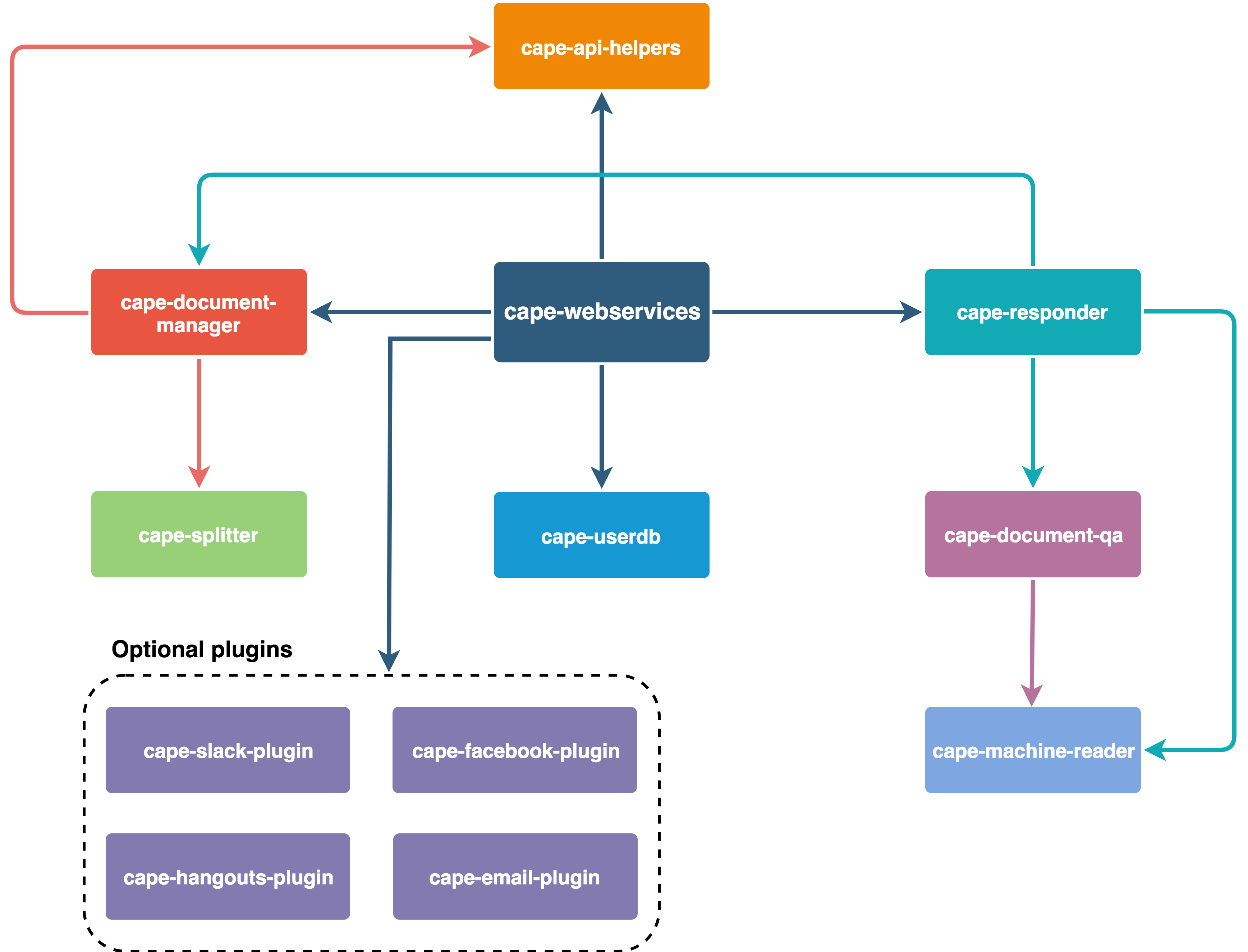
Em resumo, é assim que o Cabo está organizado:


