amazon sagemaker clip search
1.0.0
Este repositório tem como objetivo construir um protótipo de mecanismo de pesquisa baseado em aprendizado de máquina (ML) para recuperar e recomendar produtos com base em consultas de texto ou imagem. Este é um guia passo a passo sobre como criar modelos SageMaker com pré-treinamento de imagem e linguagem contrastante (CLIP), usar os modelos para codificar imagens e texto em embeddings, ingerir embeddings no índice do Amazon OpenSearch Service e consultar o índice usando a funcionalidade k-vizinhos mais próximos (KNN) do OpenSearch Service.
A recuperação baseada em incorporação (EBR) é bem utilizada em sistemas de pesquisa e recomendação. Ele usa algoritmos de pesquisa de vizinho mais próximo (aproximado) para encontrar itens semelhantes ou intimamente relacionados em um armazenamento incorporado (também conhecido como banco de dados vetorial). Os mecanismos de pesquisa clássicos dependem fortemente da correspondência de palavras-chave e ignoram o significado lexical ou o contexto da consulta. O objetivo do EBR é fornecer aos usuários a capacidade de encontrar os produtos mais relevantes usando texto livre. É popular porque, em comparação com a correspondência de palavras-chave, aproveita conceitos semânticos no processo de recuperação.
Neste repo, nos concentramos na construção de um protótipo de mecanismo de pesquisa baseado em aprendizado de máquina (ML) para recuperar e recomendar produtos com base em consultas de texto ou imagem. Isso usa o Amazon OpenSearch Service e a funcionalidade de k-vizinhos mais próximos (KNN), bem como o Amazon SageMaker e seu recurso de inferência sem servidor. O Amazon SageMaker é um serviço totalmente gerenciado que oferece a todos os desenvolvedores e cientistas de dados a capacidade de criar, treinar e implantar modelos de ML para qualquer caso de uso com infraestrutura, ferramentas e fluxos de trabalho totalmente gerenciados. O Amazon OpenSearch Service é um serviço totalmente gerenciado que facilita a execução de análises interativas de logs, monitoramento de aplicativos em tempo real, pesquisa de sites e muito mais.
O pré-treinamento contrastivo de linguagem-imagem (CLIP) é uma rede neural treinada em uma variedade de pares de imagem e texto. A(s) rede(s) neural(is) CLIP é(m) capaz(s) de projetar imagens e texto no mesmo espaço latente, o que significa que eles podem ser comparados usando uma medida de similaridade, como similaridade de cosseno. Você pode usar o CLIP para codificar as imagens ou descrições de seus produtos em embeddings e, em seguida, armazená-los em um banco de dados vetorial. Em seguida, seus clientes poderão realizar consultas no banco de dados para recuperar produtos que possam ter interesse. Para consultar o banco de dados, seus clientes precisam fornecer imagens ou texto de entrada e, em seguida, a entrada será codificada com CLIP antes de ser enviada ao banco de dados vetorial para pesquisa KNN.
O banco de dados vetorial aqui desempenha o papel de mecanismo de busca. Este banco de dados vetorial suporta imagens unificadas e pesquisa baseada em texto, o que é particularmente útil nos setores de comércio eletrônico e varejo. Um exemplo de pesquisa baseada em imagens é que seus clientes podem pesquisar um produto tirando uma foto e, em seguida, consultar o banco de dados usando a imagem. Em relação à pesquisa baseada em texto, seus clientes podem descrever um produto em formato de texto livre e depois utilizar o texto como uma consulta. Os resultados da pesquisa serão ordenados por uma pontuação de similaridade (semelhança de cosseno), se um item do seu inventário for mais parecido com a consulta (uma imagem ou texto de entrada), a pontuação será mais próxima de 1, caso contrário a pontuação será mais próxima de 0. Os K produtos principais dos resultados da sua pesquisa são os produtos mais relevantes do seu inventário.
O OpenSearch Service fornece correspondência de texto e incorporação de pesquisa baseada em KNN. Usaremos a incorporação de pesquisa baseada em KNN nesta solução. Você pode usar imagem e texto como consulta para pesquisar itens do inventário. A implementação deste aplicativo de pesquisa unificado de imagem e teste baseado em KNN consiste em duas fases:
A solução usa os seguintes serviços e recursos da AWS:
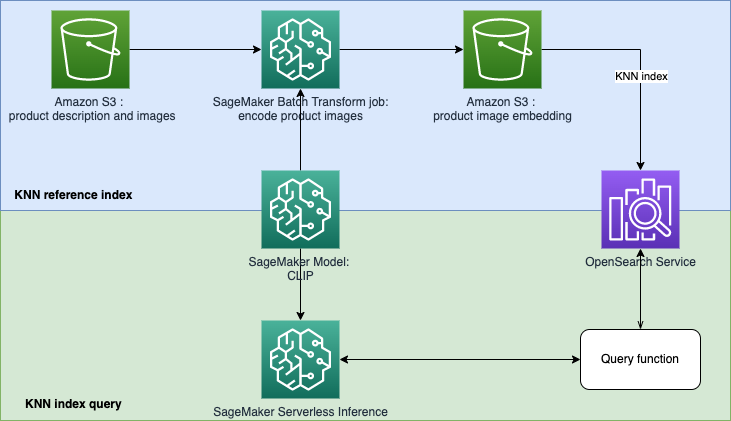
No modelo opensearch.yml , ele criará um domínio OpenSearch e concederá à sua função de execução do SageMaker Studio para usar o domínio.
No template sagemaker-studio-opensearch.yml , irá criar um novo Domínio SageMaker, um perfil de usuário no Domínio e um Domínio OpenSearch. Portanto, você pode usar o perfil de usuário do StageMaker para construir este POC.
Você pode escolher um dos modelos para executar seguindo as etapas listadas abaixo.
Etapa 1: vá para CloudFormation Service em seu console AWS. 
Etapa 2: faça upload de um modelo para criar uma pilha do CloudFormation clip-poc-stack .
Se você já possui um SageMaker Studio em execução, pode usar o modelo opensearch.yml . 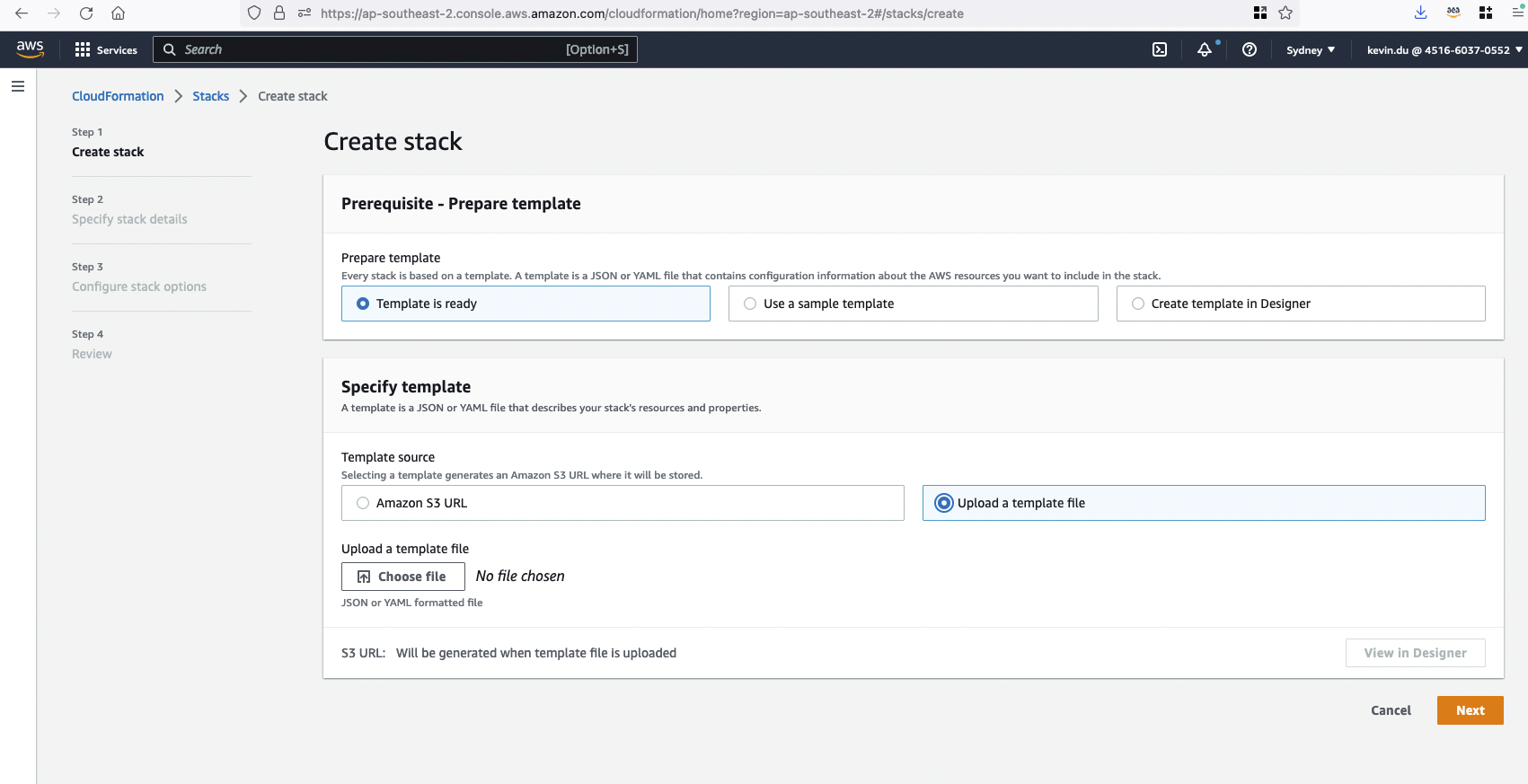
Se você não possui um SageMaker Studio no momento, pode usar o modelo sagemaker-studio-opensearch.yml . Ele criará um domínio Studio e um perfil de usuário para você.
Etapa 3: verifique o status da pilha do CloudFormation. Demorará cerca de 20 minutos para terminar a criação. 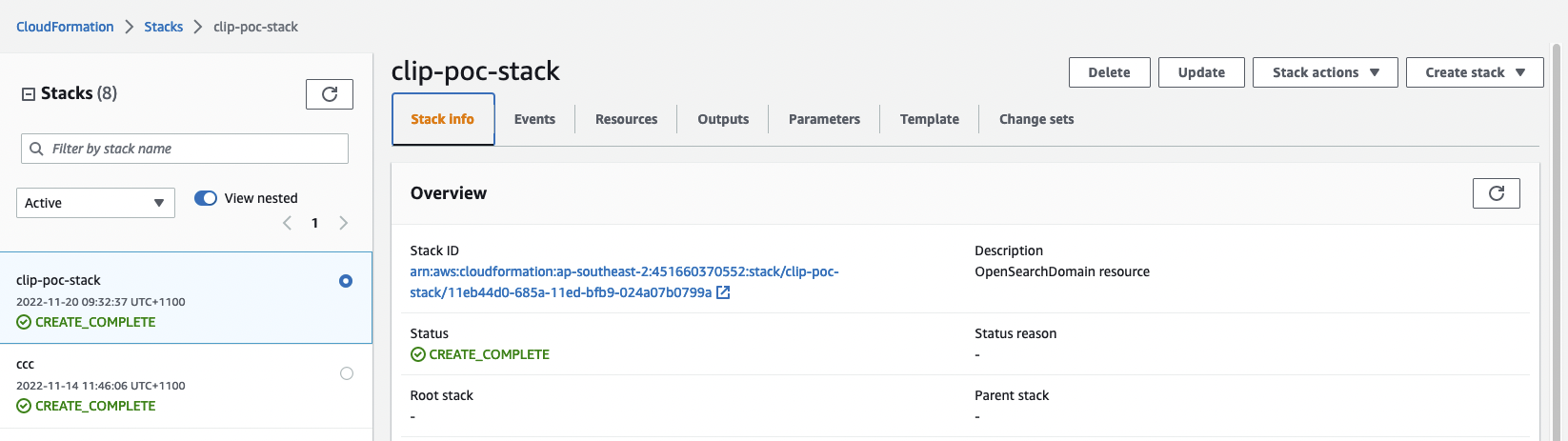
Depois que a pilha for criada, você pode acessar o SageMaker Console e clicar em Open Studio para entrar no ambiente Jupyter. 
Se durante a execução o CloudFormation mostrar erros sobre a função vinculada ao serviço OpenSearch não pode ser encontrada. Você precisa criar uma função vinculada ao serviço executando aws iam create-service-linked-role --aws-service-name es.amazonaws.com em sua conta AWS.
Abra o arquivo blog_clip.ipynb com o SageMaker Studio e use o kernel Data Science Python 3 . Você pode executar células desde o início.
O conjunto de dados de objetos Amazon Berkeley é usado na implementação. O conjunto de dados é uma coleção de 147.702 listagens de produtos com metadados multilíngues e 398.212 imagens de catálogo exclusivas. Usaremos apenas as imagens e nomes dos itens em inglês dos EUA. Para fins de demonstração, usaremos cerca de 1.600 produtos.
Esta seção descreve as considerações de custo para executar esta demonstração. A conclusão do POC implantará um OpenSearch Cluster e um SageMaker Studio que custará menos de US$ 2 por hora. Observação: o preço listado abaixo é calculado usando a região us-east-1. O custo varia de região para região. E o custo também pode mudar com o tempo (o preço aqui é registrado em 22/11/2022).
Outras análises de custos estão abaixo.
Serviço OpenSearch – Os preços variam de acordo com o uso do tipo de instância e o custo de armazenamento. Para obter mais informações, consulte Preço do Amazon OpenSearch Service.
t3.small.search é executada por aproximadamente 1 hora a US$ 0,036 por hora.SageMaker – Os preços variam com base no uso da instância EC2 para aplicativos Studio, trabalhos de transformação em lote e endpoints de inferência sem servidor. Para obter mais informações, consulte Preços do Amazon SageMaker.
ml.t3.medium para Studio Notebooks é executada por aproximadamente 1 hora a US$ 0,05 por hora.ml.c5.xlarge para Batch Transform é executada por aproximadamente 6 minutos a US$ 0,204 por hora.S3 – Baixo custo, os preços variam dependendo do tamanho dos modelos/artefatos armazenados. Os primeiros 50 TB de cada mês custarão apenas US$ 0,023 por GB armazenado. Para obter mais informações, consulte Preços do Amazon S3.
Consulte CONTRIBUINDO para obter mais informações.
Esta biblioteca está licenciada sob a licença MIT-0. Veja o arquivo LICENÇA.


