telegram archive server
v0.4.1 - 蔚蓝更新
Um robô de pesquisa e arquivamento de bate-papo em grupo do Telegram adequado para o ambiente CJK.

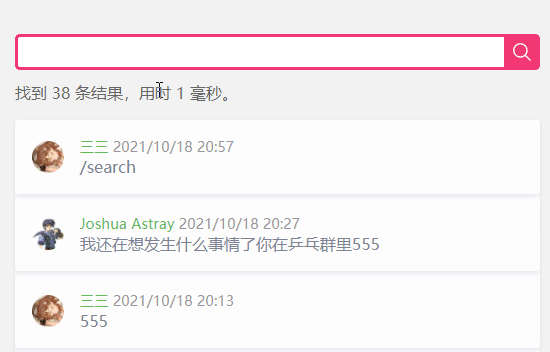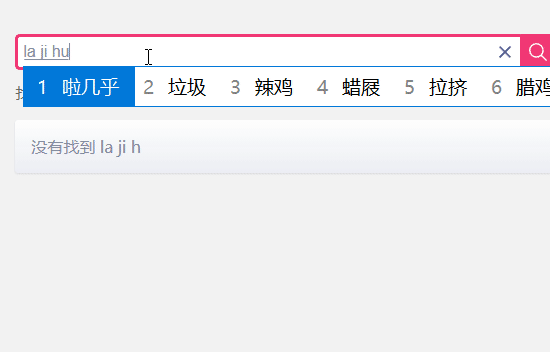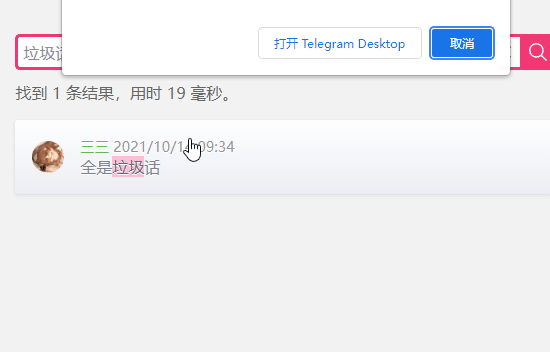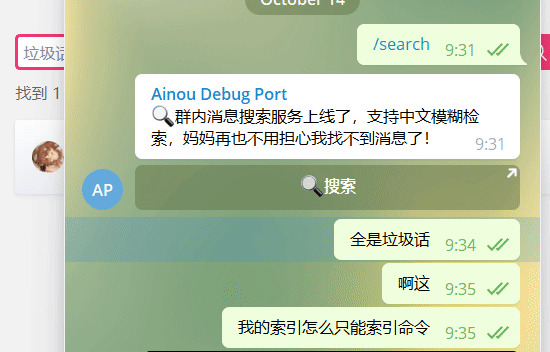
Clique no botão [Pesquisar] para autenticar automaticamente e abrir a interface de pesquisa.
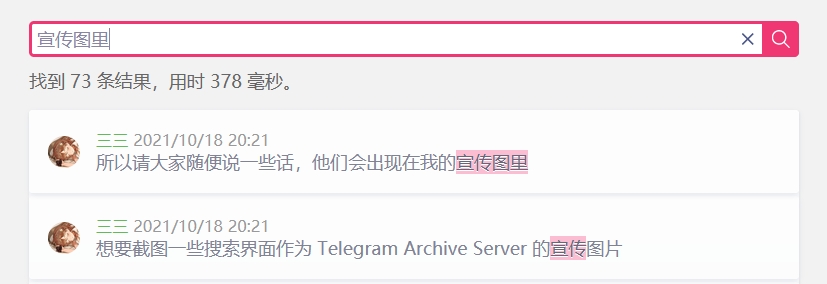
Clique no link da hora para ir para a interface de bate-papo.
Você precisa:
Baixe o arquivo .env.example , consulte os comentários internos e configure adequadamente.
Você pode salvá-lo como .env ou configurá-lo como uma variável de ambiente.
O TAS não fornece um serviço https integrado. Recomenda-se usar Caddy ou software semelhante para reverter o proxy TAS.
docker run -d --restart=always --env-file=.env quay.io/oott123/telegram-archive-serverClaro, você também pode executá-lo usando Kubernetes ou docker-compose.
Se você não possui o Docker ou não deseja usá-lo, também pode compilar e implantar a partir do código-fonte. Neste ponto você também precisa de:
git clone https://github.com/oott123/telegram-archive-server.git
cd telegram-archive-server
# git checkout vX.X.X
cp .env.example .env
vim .env
yarn
yarn build
yarn start Enviar /search no grupo. O Bot pode solicitar que você defina o Domínio, basta seguir as instruções.
Os usuários devem atender aos seguintes critérios para que seu avatar apareça nos resultados da pesquisa:
Como o MeiliSearch tem baixa eficiência de indexação para novas mensagens, as mensagens só entrarão no índice quando qualquer uma das seguintes condições for atendida:
Se o redis não for usado para persistir a fila de mensagens, as mensagens que não entraram na fila podem ser perdidas quando o programa estiver anormal ou o servidor for reiniciado.
Atualmente, apenas a importação de supergrupos é suportada.
Clique no botão de três pontos no cliente de desktop - Exportar histórico de bate-papo, aguarde a conclusão da exportação e obtenha result.json .
implementar:
curl
-H " Content-Type: application/json "
-H " Authorization: Bearer $AUTH_IMPORT_TOKEN "
-XPOST -T result.json
http://localhost:3100/api/v1/import/fromTelegramGroupExportOs registros podem ser importados. Observe que apenas registros de um único grupo podem ser importados por vez.
Se você habilitar a fila de OCR, será necessário o Redis (pode compartilhar uma instância com o cache) e configurar um serviço de reconhecimento de terceiros. O processo de identificação é o seguinte:
O reconhecimento e o armazenamento podem ser concluídos em diferentes instâncias de função: o download de imagens e o armazenamento de texto serão concluídos na instância do Bot, e a instância de OCR só precisa acessar o serviço de OCR.
Esse design permite que os mantenedores projetem uma identificação centralizada off-line (por exemplo, usem uma instância preemptiva para executar o serviço de identificação e desligue-o após a fila ser limpa) para reduzir os custos de identificação.
Se estiver usando um serviço de nuvem de terceiros, você poderá desativar diretamente a fila de OCR ou ativar as funções de Bot e OCR na mesma instância.
Consulte a documentação de reconhecimento de texto do Google Cloud Vision e as regras de faturamento do Google Cloud Vision. A configuração é a seguinte:
OCR_DRIVER=google
OCR_ENDPOINT=eu-vision.googleapis.com # 或者 us-vision.googleapis.com ,决定 Google 在何处存储处理数据
GOOGLE_APPLICATION_CREDENTIALS=/path/to/google/credentials.json # 从 GCP 后台下载的 json 鉴权文件Você precisa de uma instância do paddleocr-web. A configuração é a seguinte:
OCR_DRIVER=paddle-ocr-web
OCR_ENDPOINT=http://127.0.0.1:8980/apiCrie um recurso do Azure Vision e configure as informações do recurso da seguinte forma:
OCR_DRIVER=azure
OCR_ENDPOINT=https://tas.cognitiveservices.azure.com
OCR_CREDENTIALS=000000000000000000000000000000000docker run [...] dist/main ocr,bot
# or
node dist/main ocr,botDEBUG=app: * ,grammy * yarn start:debug Depois que o serviço de pesquisa for autenticado, o servidor irá para: $HTTP_UI_URL/index.html com os seguintes parâmetros de URL:
tas_server – URL base do servidor, no formato http://localhost:3100/api/v1tas_indexName - número do grupo, na forma supergroup1234567890tas_authKey - JWT emitido pelo servidor, que pode ser usado como chave API do MeiliSearch. /api/v1/search/compilable/meili pode ser pesquisado como uma instância normal do MeiliSearch.
O nome do índice deve usar um número de grupo no formato supergroup1234567890 ; a chave API é o JWT emitido pelo servidor.
Observe que o filtro está temporariamente indisponível por motivos de segurança.


