pianola
1.0.0
 pianola em ação" style="max-width: 100%;">
pianola em ação" style="max-width: 100%;">
pianola é um aplicativo que reproduz música de piano gerada por IA. Os usuários propagam (ou seja, "avisam") o modelo de IA tocando notas no teclado ou escolhendo trechos de exemplos de peças clássicas.
Neste leia-me, explicamos como funciona a IA e entramos em detalhes sobre a arquitetura do modelo.
A música pode ser representada de várias maneiras, desde formas de onda de áudio brutas até padrões MIDI semiestruturados. Na pianola , dividimos as batidas musicais em intervalos regulares e uniformes (por exemplo, semicolcheias/semicolcheias). As notas tocadas dentro de um intervalo são consideradas pertencentes ao mesmo intervalo de tempo, e uma série de intervalos de tempo forma uma sequência. Usando a sequência baseada em grade como entrada, o modelo de IA prevê as notas no próximo passo de tempo, que por sua vez é usado como entrada para prever o passo de tempo subsequente de maneira autoregressiva.
Além das notas a serem tocadas, o modelo também prevê a duração (tempo que a nota é pressionada) e a velocidade (com que força uma tecla é tocada) de cada nota.
O modelo é composto por três módulos: um incorporador, um transformador e um decodificador. Esses módulos são emprestados de arquiteturas bem conhecidas, como redes Inception, transformadores LLaMA e cadeias classificadoras multi-rótulos, mas são adaptados para trabalhar com dados musicais e combinados em uma abordagem inovadora.
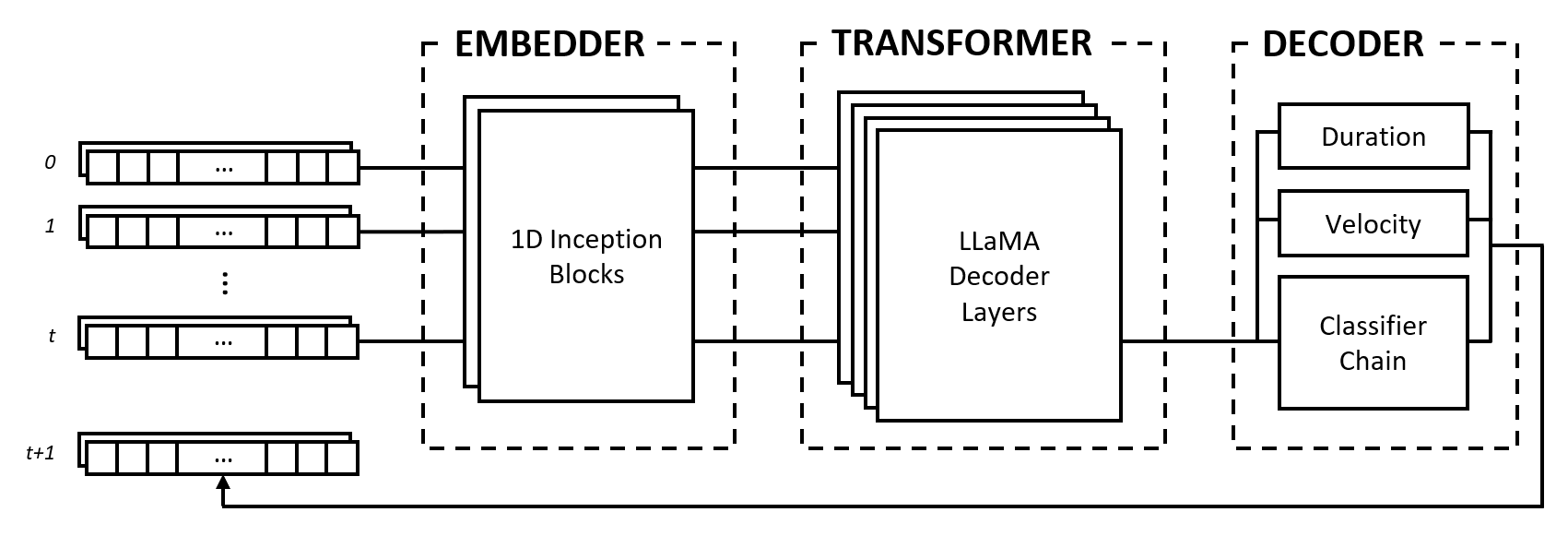
O incorporador converte cada passo de tempo de entrada da forma (num_notes, num_features) em um vetor de incorporação que pode ser alimentado no transformador. No entanto, ao contrário dos embeddings de texto que mapeiam vetores one-hot para outro espaço dimensional, fornecemos um viés indutivo aplicando camadas convolucionais e de agrupamento na entrada. Fazemos isso por vários motivos:
2^num_notes , onde num_notes é 64 ou 88, para pianos normais), portanto, não é possível representá-las como vetores one-hot.Para permitir que o incorporador aprenda quais distâncias são úteis, nos inspiramos nas redes Inception e empilhamos convoluções de tamanhos variados de kernel.
O módulo transformador é composto por camadas transformadoras LLaMA que aplicam autoatenção à sequência de vetores de incorporação de entrada.
Como muitos modelos generativos de IA, este módulo usa apenas a parte "decodificadora" do modelo Transformers original de Vaswani et al. (2017). Usamos aqui o rótulo “transformador” para diferenciar este módulo do seguinte, que faz a própria decodificação dos estados produzidos pelas camadas de autoatenção.
Escolhemos a arquitetura LLaMA em vez de outros tipos de transformadores principalmente porque ela usa incorporações posicionais rotativas (RoPE), que codifica posições relativas com decaimento de distância ao longo de intervalos de tempo. Dado que representamos os dados musicais como intervalos fixos, as posições relativas, bem como as distâncias entre os passos de tempo, são informações importantes que o transformador pode usar explicitamente para compreender e gerar música com ritmo consistente.
O decodificador capta os estados atendidos e prevê as notas a serem tocadas juntamente com suas durações e velocidades. O módulo é composto por vários subcomponentes, nomeadamente uma cadeia classificadora para previsão de notas e perceptrons multicamadas (MLPs) para previsões de características.
A cadeia de classificadores consiste em classificadores binários num_notes , ou seja, um para cada tecla de um piano, para criar um classificador multi-rótulo. Para aproveitar as correlações entre as notas, os classificadores binários são encadeados de modo que o resultado das notas anteriores afete as previsões para as notas seguintes. Por exemplo, se houver uma correlação positiva entre notas de oitava, uma nota mais baixa ativa (por exemplo, C3 ) resulta em uma probabilidade maior de a nota mais alta (por exemplo, C4 ) ser prevista. Isto também é benéfico em casos de correlações negativas, onde se pode escolher entre duas notas adjacentes que resultam numa escala maior ou menor (por exemplo, CDE vs CD-Eb ), mas não ambas.
Para eficiência computacional, limitamos o comprimento da cadeia a 12 elos, ou seja, uma oitava. Finalmente, uma estratégia de decodificação por amostragem é usada para selecionar notas relativas às suas probabilidades de predição.
Os recursos de duração e velocidade são tratados como problemas de regressão e são previstos usando MLPs vanilla. Embora os recursos sejam previstos para cada nota, usamos uma função de perda personalizada durante o treinamento que agrega apenas as perdas de recursos de notas ativas, semelhante à função de perda usada em uma tarefa de classificação de imagem com localização.
Nossa escolha de representar os dados musicais como uma grade tem suas vantagens e desvantagens. Discutimos esses pontos comparando-os com o vocabulário baseado em eventos proposto por Oore et al. (2018), uma contribuição altamente citada na geração musical.
Uma das principais vantagens da nossa abordagem é a dissociação da compreensão micro e macro da música, o que leva a uma clara separação de funções entre o incorporador e o transformador. O papel do primeiro é interpretar a interação das notas em um nível micro, por exemplo, como as distâncias relativas entre as notas formam relações musicais como acordes, e a tarefa do último é sintetizar essas informações na dimensão do tempo para compreender o estilo musical em um nível macro. nível.
Em contraste, uma representação baseada em eventos coloca todo o fardo sobre um modelo de sequência para interpretar tokens one-hot que podem representar pitch, tempo ou velocidade, três conceitos distintos. Huang et al. (2018) descobrem que é necessário adicionar um mecanismo de atenção relativa ao seu modelo Transformer para gerar continuações coerentes, o que sugere que o modelo requer um viés indutivo para ter um bom desempenho com esta representação.
Em uma representação em grade, a escolha da duração do intervalo é uma compensação entre fidelidade e dispersão dos dados. Um intervalo mais longo reduz a granularidade dos tempos das notas, reduzindo a expressividade musical e potencialmente comprimindo elementos rápidos como trinados e notas repetidas. Por outro lado, um intervalo mais curto aumenta exponencialmente a dispersão, introduzindo muitos intervalos de tempo vazios, o que é um problema significativo para os modelos Transformer, pois eles são limitados no comprimento da sequência.
Além disso, os dados musicais podem ser mapeados para uma grade através da passagem do tempo ( 1 timestep == X milliseconds ) ou conforme escrito em uma partitura ( 1 timestep == 1 sixteenth note/semiquaver ), cada um com suas próprias compensações . Uma representação baseada em eventos evita completamente esses problemas, especificando a passagem do tempo como um evento.
Apesar de suas desvantagens, a representação em grade tem uma vantagem prática, pois é muito mais fácil de trabalhar no desenvolvimento da pianola . A saída do modelo é legível por humanos e o número de passos de tempo corresponde a um período fixo de tempo, tornando o desenvolvimento de novos recursos muito mais rápido.
Além disso, a pesquisa sobre a extensão dos comprimentos de sequência dos modelos Transformer e as melhorias contínuas no hardware reduzirão progressivamente os problemas causados pela dispersão de dados e, no final de 2023, estamos vendo grandes modelos de linguagem que podem lidar com dezenas de milhares de tokens. À medida que as técnicas são otimizadas e o hardware poderoso se torna mais acessível, acreditamos que a fidelidade continuará a melhorar, tal como aconteceu com a geração de imagens, levando a uma maior expressividade e nuances na música gerada por IA.
O código-fonte deste projeto é visível publicamente para fins de pesquisa acadêmica e compartilhamento de conhecimento. Todos os direitos são retidos pelo(s) criador(es), a menos que as permissões tenham sido explicitamente concedidas.
Ícone do site modificado do Freepik - Flaticon.
Entre em contato pelo Outlook.com no endereço bruce <dot> ckc .


