project omega
O último padrão de arquitetura web empresarial que você realmente precisa. Até o próximo.
DR
O objetivo é otimizar a experiência do desenvolvedor, sendo capaz de:
- Desenvolva localmente como se fosse um monólito
- Implante como microsserviços separados
- Simule o ambiente de produção localmente usando docker
Demonstração
project omega Prova de Conceito - Microservices Monolith Hybrid
project omega Demo - Kubernetes Microserves e implantação de contêiner independente
Por que
Quero provar que não precisamos sacrificar a eficiência do desenvolvedor para obter escalabilidade. Mais discussões sobre prós e contras de microsserviços e monólitos aqui: Microsserviços e Monólitos.
Minha impressão é que muitos especialistas do setor querem que acreditemos que estas são nossas três opções principais:
- Monólito
- Microsserviços
- "Híbrido" (não é realmente um híbrido, é um monólito e também alguns microsserviços)
Quero mostrar que não precisamos escolher nenhuma dessas opções. Com um pouco de criatividade podemos ter um verdadeiro “híbrido” que é ao mesmo tempo um monólito e um conjunto de microsserviços. Com minha estratégia atual, não acho que possamos eliminar todas as desvantagens do monólito e dos microsserviços, mas podemos nos livrar de muitos dos pontos problemáticos de ambos.
O que não é
- Não estou tentando criar um framework (pelo menos ainda não...). Estou apenas juntando todos os legos que tenho em uma configuração diferente como um experimento.
- Isto não pretende ser um projeto comunitário. Pretendo fazer alterações drásticas frequentes sem aviso prévio. Se este conceito lhe parece interessante e você gostaria de contribuir, entre em contato comigo primeiro.
Metas do Projeto
- Crie um padrão que funcione para projetos como pequenos projetos de hobby de desenvolvedor único e também dimensione para dezenas ou até centenas de desenvolvedores trabalhando em aplicativos web corporativos grandes e complexos.
- Ser capaz de desenvolver localmente como se fosse um monólito:
- Um repositório. Pelas mesmas razões, as empresas escolhem uma abordagem monorepo.
- Máximo de 3 processos para executar (ui do cliente, servidor, dependências do docker com banco de dados, fila de mensagens, etc). Não queremos que páginas de documentos de configuração sejam instaladas e executadas.
- Ser capaz de implantar como microsserviços.
- Ser capaz de simular um ambiente de produção com microsserviços rodando em contêineres docker.
- Tempo de configuração extremamente rápido. Todas as dependências diferentes de Node e .NET devem ser incluídas como dependências do docker (banco de dados, fila de mensagens, etc.). Novos usuários devem ser capazes de instalar .NET, Node, clonar o repositório e então executar comandos de instalação e execução.
- Recarga a quente extremamente rápida para o cliente e o servidor no ambiente de desenvolvimento.
- Ser capaz de desenvolver e executar o aplicativo em Windows, Linux e Mac.
- Ser capaz de criar rapidamente um novo serviço.
Pilha de tecnologia
A pilha de tecnologia é irrelevante para o conceito de alto nível que estou tentando provar, mas para este projeto usarei:
- .NET 5 para serviços
- Front-end do React (create-react-app básico com texto digitado)
- Docker
Conceitos de alto nível
As empresas com grandes aplicações estão sendo cada vez mais empurradas para microsserviços para que possam escalar horizontalmente (entre outros motivos). Então, para conseguir isso, estamos analisando algo como o seguinte:
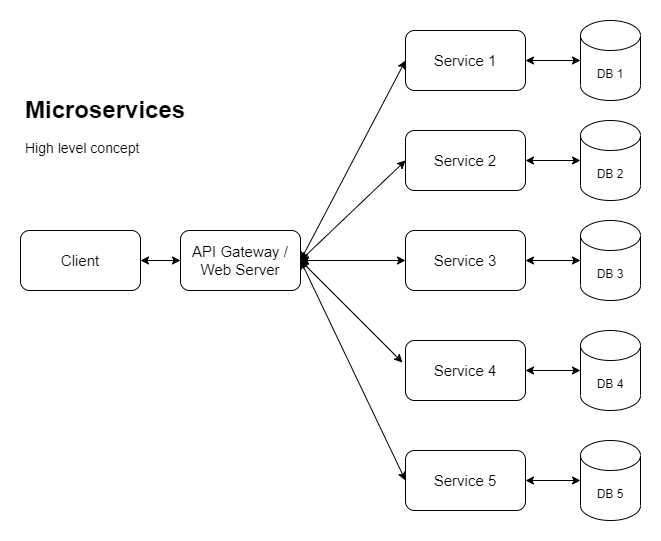
Aqui está outra versão mostrando uma maneira como o dimensionamento horizontal pode ser implementado:
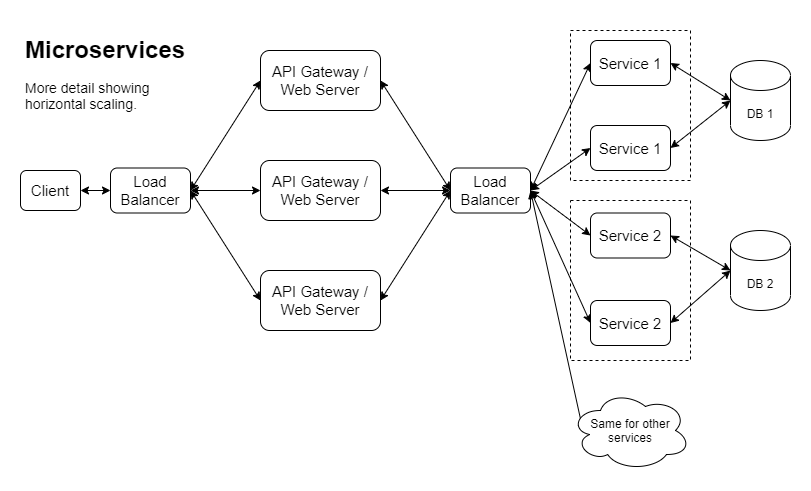
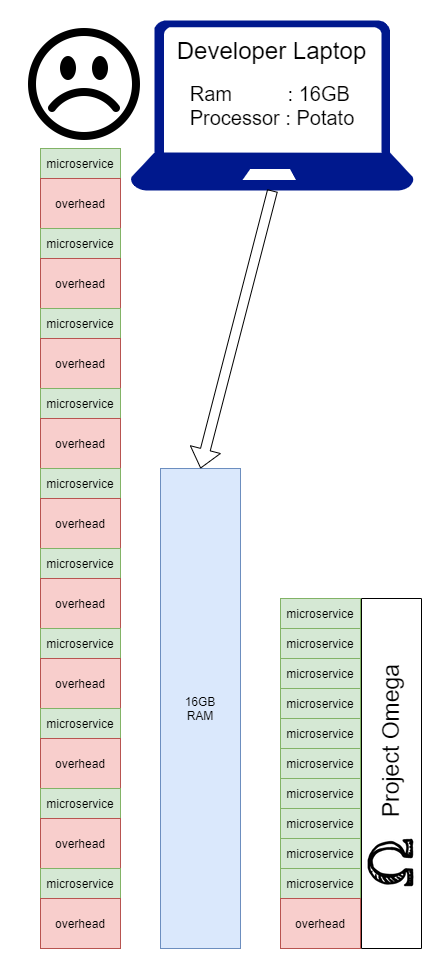
Se seguirmos esse caminho, acabaremos com um problema real de desenvolvimento local. Realmente depende de como é o produto, de quantos desenvolvedores existem e de quem trabalha em quê e com que frequência. Dito isto, uma grande parte das empresas que escolhem microsserviços acabará em uma situação em que os desenvolvedores terão que fazer algumas escolhas difíceis sobre como fazer o seu desenvolvimento diário. Com project omega , o objetivo é mostrar que podemos eliminar a sobrecarga de executar um serviço localmente, combinando todos eles em um aplicativo durante a execução local:
Aqui está a estrutura da pasta:
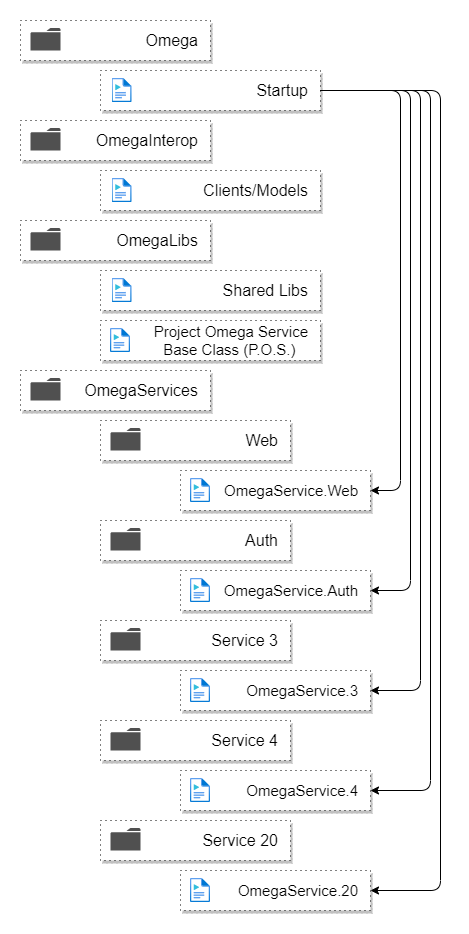
E aqui está como seria implantado como microsserviços:
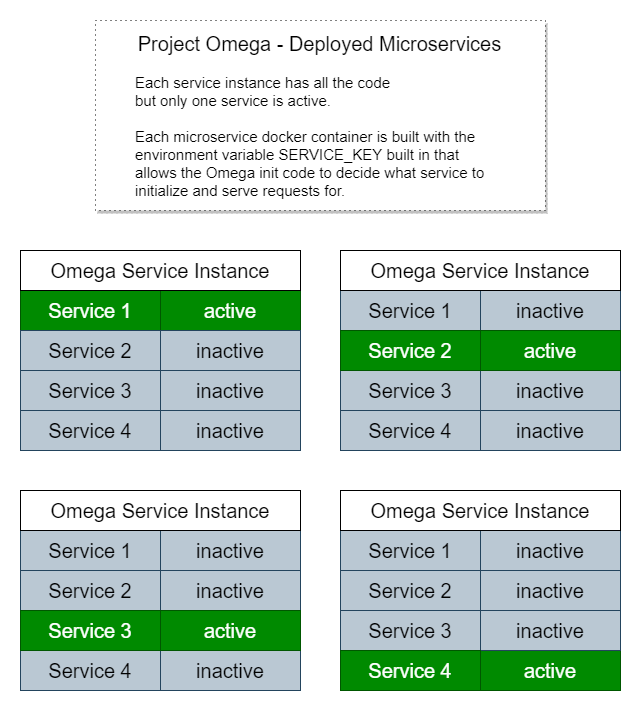
Cada instância possui uma cópia de todo o código, mas executa apenas inicialização, rotas de endpoint de serviço e processos de trabalho para um microsserviço específico.
É por isso que é tão simples executar o aplicativo localmente como um monólito, porque simplesmente procuramos por uma variável de ambiente chamada SERVICE_KEY ou, se ela não estiver presente, inicializamos todos os serviços.
Exemplos de outras inicializações específicas de serviço:
- Configuração de injeção de dependência
- Sequências de conexão do banco de dados
- Migrações de banco de dados
- Inicialização da fila de mensagens
- Configurar conectividade de cache distribuído
- Outra configuração de conectividade de recursos de nuvem
- Inicialização de API de terceiros
Quando Startup é chamado, ele verifica os assemblies em busca de tipos que herdam ProjectOmegaService , cria uma instância e executa a lógica de inicialização desse serviço. Ao executar localmente, todos eles serão executados.
Instruções de configuração
Pré-requisitos de instalação:
Observe que obter a versão mais recente do docker em execução no Windows pode exigir algumas etapas extras se você não faz isso há algum tempo, como instalar o WSL 2 e atualizar sua distribuição WSL. Siga as instruções no site do Docker.
Passos:
- Clonar este repositório
- Em um terminal do repo root, execute
yarn run installAll - Se você deseja executar o SQL Server em uma porta diferente de 1434:
- Execute
yarn run syncEnvFiles - Altere
OMEGA_DEFAULT_DB_PORT e OMEGA_MSSQL_HOST_PORT em .env.server
- Inicie as dependências usando o comando
yarn run dockerDepsUpDetached - Execute migrações de banco de dados na primeira vez que executar ou quando receber alterações de outra pessoa com atualizações de banco de dados:
yarn run dbMigrate - Execute o aplicativo no modo de desenvolvimento local usando uma destas opções:
- Opção 1: em um terminal do repo root run
yarn run both (isso usa simultaneamente para executar os comandos das opções 2) - Opção 2: use 2 terminais separados. Em um terminal,
yarn run client e no outro execute yarn run server
- Acesse https://localhost:3000 (clique após o aviso https)
Antes de executar testes de unidade com dotnet test pela primeira vez ou depois de adicionar testes de unidade no novo esquema de banco de dados:
- Inicie dependências se ainda não estiver em execução com
yarn run dockerDepsUpDetached - Execute
yarn run testDbMigrate - Em seguida, execute
dotnet test
Para simular produção e microsserviços no docker:
- Certifique-se de que as dependências do docker estejam em execução com
yarn run dockerDepsUpDetached - Em um terminal do repo root, execute
yarn run dockerRecreateFull - Acesse https://localhost:3000 (clique após o aviso https)
Próximas etapas
- Registrando alterações
- Experimente o formatador Serilog json
- Adicionar ID de correlação e outras informações contextuais às entradas de log
- Adicione documentação adicional
- Diagramas de como funciona a simulação do docker
- Dependências do Docker
- Descrição de texto do que é, como funciona
- Diagramas de como o docker deps se encaixa no processo de desenvolvimento
- Documentação de roteamento/proxy
- Migrações de banco de dados
- Teste RPC entre serviços em vez de chamadas rest http (talvez com algo assim: https://github.com/aspnet/AspLabs/tree/main/src/GrpcHttpApi)
- Adicionar à classe base do cliente entre serviços para abstrair o tratamento e registro de erros
- Implementação de autenticação
- Registro de site front-end
- Autenticação de serviço para serviço (OAuth?)
- Geração automática de documentação (saída de documentação swagger e html xml)
- Configuração de fila e serviços de processo de trabalho
- Definição abstrata de fila (para permitir o uso de serviços em nuvem como opção)
- Serviço básico de tipo de processo de trabalho com um loop de eventos procurando mensagens
- RabbitMQ em docker-compose.deps.yml
- Implementação básica do RabbitMQ conectada ao serviço de processo de trabalho
- Trabalho adicional de demonstração local do Kubernetes
- O banco de dados provavelmente exigirá aprender como usar um volume persistente do Kubernetes, a menos que eu consiga descobrir como ajustar a rede para expor o banco de dados host
- Adicione Seq ou torne a funcionalidade Seq opcional e não a use ao executar em kubernetes
- Metaprojeto/script para analisar solução
- Analise os serviços afetados com base nos arquivos alterados (para granularidade de implantação)
- Andaimes do projeto:
- Capacidade de criar uma nova cópia do projeto usando alguma outra "chave" do projeto além do Omega para todos os nomes de projetos/diretórios
- Capacidade de fazer com que um novo projeto ative contêineres docker e faça testes de integração eficazes para garantir a criação bem-sucedida de um novo projeto
Diversos
Se você estiver desenvolvendo no Linux, poderá encontrar este erro ao iniciar o servidor:
System.AggregateException: Ocorreram um ou mais erros. (O limite de usuário configurado (128) no número de instâncias do inotify foi atingido ou o limite por processo no número de descritores de arquivos abertos foi atingido.)
Isso provavelmente é causado por muitas monitorações de arquivos sendo usadas pelo vscode. Você pode aumentar o limite de instâncias inotify (não apenas o limite de observação, que provavelmente já está definido como muito alto em seu arquivo /etc/sysctl.conf ) executando este comando:
echo fs.inotify.max_user_instances=524288 | sudo tee -a /etc/sysctl.conf && sudo sysctl -p
Outra documentação
Análise de custo-benefício do padrão de design: DesignPatternCostBenefit.md
Variações de padrão de design: DesignPatternVariations.md
Decisões: Decisões.md
Filosofias e reclamações de desenvolvimento de software: https://gist.github.com/mikey-t/3d5d6f0f5316abf9e74fb553be9fdef3


