nnl
gpt2-xl assets
nnl é um mecanismo de inferência para modelos grandes em plataforma GPU com pouca memória.
Modelos grandes são grandes demais para caber na memória da GPU. nnl resolve esse problema com uma compensação entre largura de banda PCIE e memória.
Um pipeline de inferência típico é o seguinte:
Com pool de memória GPU e desfragmentação de memória, o NNIL torna possível inferir um modelo grande em uma plataforma GPU de baixo custo.
Este é apenas um projeto de hobby escrito em poucas semanas, atualmente apenas o backend CUDA é suportado.
make lib nnl _cuda.a && make lib nnl _cuda_kernels.aEste comando construirá as duas bibliotecas estáticas: lib/lib nnl _cuda.a e lib/lib nnl _cuda_kernels.a . A primeira é a biblioteca principal com backend CUDA em C++, e a segunda é para os kernels CUDA.
Um programa de demonstração do GPT2-XL (1.6B) é fornecido aqui. Este programa pode ser compilado por este comando:
make gpt2_1558mDepois de baixar todos os pesos do lançamento, podemos executar o seguinte comando em uma plataforma GPU de baixo custo, como GTX 1050 (2 GB de memória):
./bin/gpt2_1558m --max_len 20 " Hi. My name is Feng and I am a machine learning engineer " E a saída é assim: 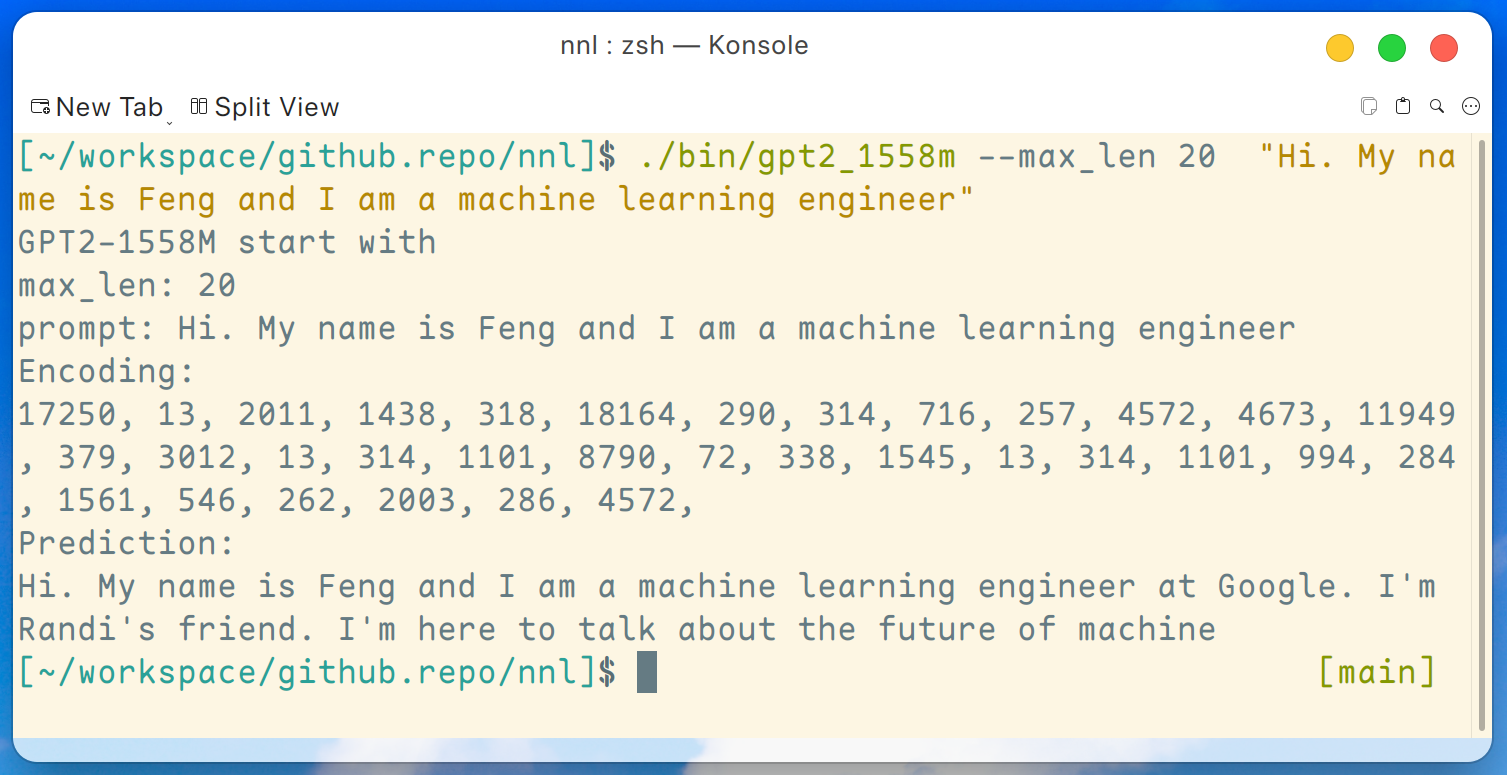
Isenção de responsabilidade: este é apenas um exemplo gerado pelo gpt2-xl, não trabalho no Google e não conheço Randi.
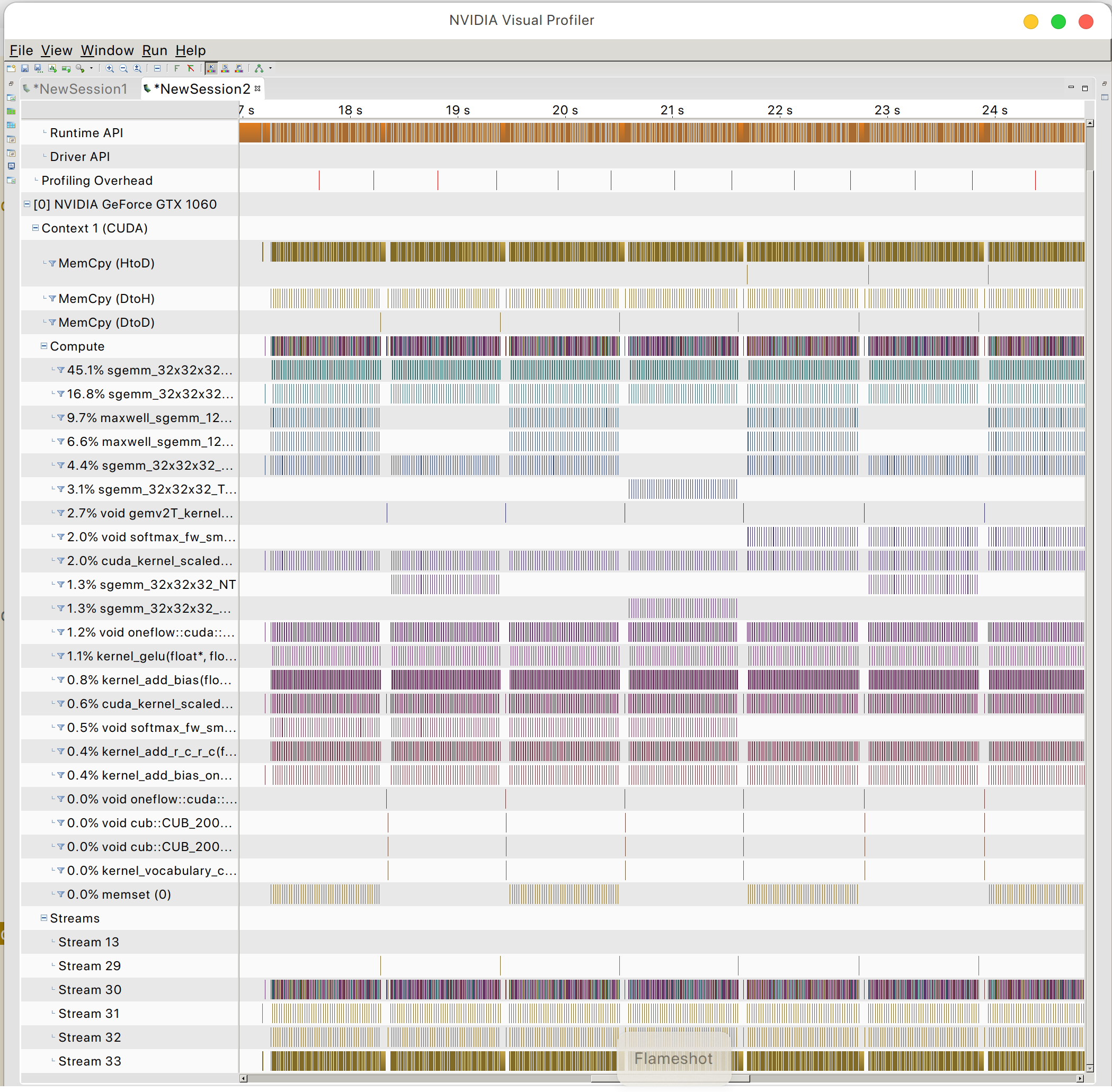
E você pode encontrar o padrão de acesso à memória GPU
PazOSL