UniIR
1.0.0
Página inicial | ? Conjunto de dados (referência M-BEIR) | ? Pontos de verificação (modelos UniIR ) | arXiv | GitHub
Este repositório contém a base de código para o artigo ECCV-2024 " UniIR : Training and Benchmarking Universal Multimodal Information Retrievers"
Propomos a estrutura UniIR (Universal multimodal Information Retrieval) para aprender um único recuperador a realizar (possivelmente) qualquer tarefa de recuperação. Ao contrário dos sistemas tradicionais de RI, UniIR precisa seguir as instruções para realizar uma consulta heterogênea para recuperar de um conjunto heterogêneo de candidatos com milhões de candidatos em diversas modalidades.
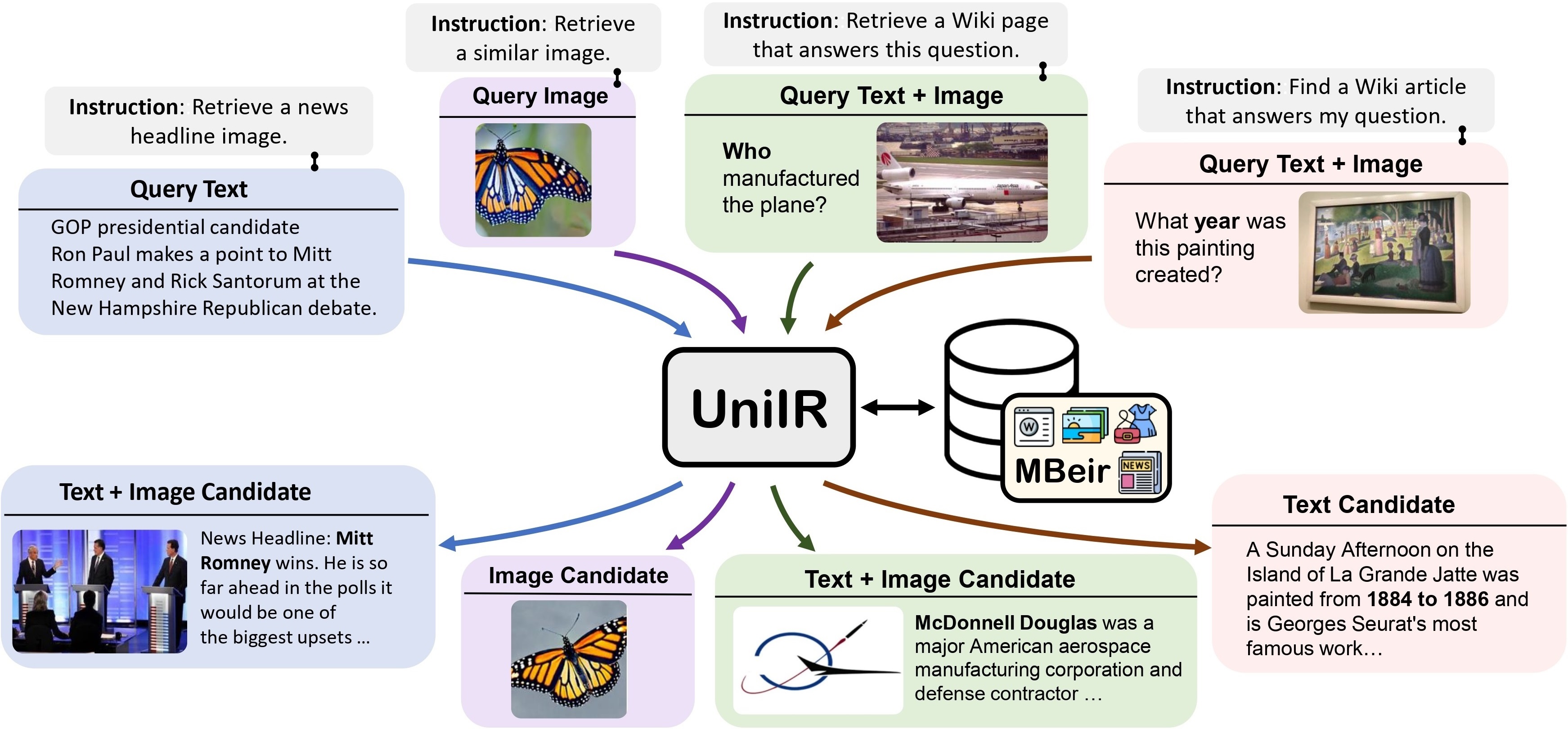 Teaser UniIR" estilo = "largura: 80%; largura máxima: 100%;">
Teaser UniIR" estilo = "largura: 80%; largura máxima: 100%;">
Para treinar e avaliar modelos universais de recuperação multimodal, construímos um benchmark de recuperação em larga escala denominado M-BEIR (Multimodal BEnchmark for Instructed Retrieval).
Fornecemos o conjunto de dados M-BEIR no formato ? Conjunto de dados . Siga as instruções fornecidas na página HF para baixar o conjunto de dados e prepará-los para treinamento e avaliação. Você precisa configurar o GiT LFS e clonar diretamente o repositório:
git clone https://huggingface.co/datasets/TIGER-Lab/M-BEIR
Fornecemos a base de código para treinar e avaliar os modelos UniIR CLIP-ScoreFusion, CLIP-FeatureFusion, BLIP-ScoreFusion e BLIP-FeatureFusion.
Prepare a base de código do projeto UniIR e do ambiente Conda usando os seguintes comandos:
git clone https://github.com/TIGER-AI-Lab/UniIR
cd UniIR
cd src/models/
conda env create -f UniIR _env.ymlPara treinar os modelos UniIR a partir de pontos de verificação CLIP e BLIP pré-treinados, siga as instruções abaixo. Os scripts baixarão automaticamente os pontos de verificação CLIP e BLIP pré-treinados.
Baixe o benchmark M-BEIR seguindo as instruções na seção M-BEIR .
cd src/models/ UniIR _clip/clip_scorefusion/configs_scripts/large/train/inbatch/ Modifique inbatch.yaml para ajuste de hiperparâmetros e run_inbatch.sh para seu próprio ambiente e caminhos.
UniIR _DIR em run_inbatch.sh para o diretório onde deseja armazenar os pontos de verificação.MBEIR_DATA_DIR em run_inbatch.sh para o diretório onde você armazena o benchmark M-BEIR.SRC_DIR em run_inbatch.sh para o diretório onde você armazena a base de código do projeto UniIR (este repositório)..env com WANDB_API_KEY , WANDB_PROJECT e WANDB_ENTITY esteja definido.Em seguida, você pode executar o seguinte comando para treinar o modelo UniIR CLIP_SF Large.
bash run_inbatch.sh cd src/models/ UniIR _blip/blip_featurefusion/configs_scripts/large/train/inbatch/ Modifique inbatch.yaml para ajuste de hiperparâmetros e run_inbatch.sh para seu próprio ambiente e caminhos.
bash run_inbatch.shFornecemos o pipeline de avaliação para os modelos UniIR no benchmark M-BEIR.
Por favor, crie um ambiente para a biblioteca FAISS:
# From the root directory of the project
cd src/common/
conda env create -f faiss_env.ymlBaixe o benchmark M-BEIR seguindo as instruções na seção M-BEIR .
Você pode treinar os modelos UniIR do zero ou baixar os pontos de verificação UniIR pré-treinados seguindo as instruções na seção Model Zoo .
cd src/models/ UniIR _clip/clip_scorefusion/configs_scripts/large/eval/inbatch/ Modifique embed.yaml , index.yaml , retrieval.yaml e run_eval_pipeline_inbatch.sh para seu próprio ambiente, caminhos e configurações de avaliação.
UniIR _DIR em run_eval_pipeline_inbatch.sh para o diretório onde deseja armazenar arquivos grandes, incluindo pontos de verificação, embeddings, índice e resultados de recuperação. Então você pode colocar o arquivo clip_sf_large.pth no seguinte caminho: $ UniIR _DIR /checkpoint/CLIP_SF/Large/Instruct/InBatch/clip_sf_large.pthmodel.ckpt_config no arquivo embed.yaml .MBEIR_DATA_DIR em run_eval_pipeline_inbatch.sh para o diretório onde você armazena o benchmark M-BEIR.SRC_DIR em run_eval_pipeline_inbatch.sh para o diretório onde você armazena a base de código do projeto UniIR (este repositório). A configuração padrão avaliará o modelo UniIR CLIP_SF Large nos benchmarks M-BEIR (conjunto de candidatos heterogêneos de 5,6 milhões) e M-BEIR_local (conjunto de candidatos homogêneos). UNION nos arquivos yaml refere-se ao M-BEIR (conjunto de candidatos heterogêneos de 5,6 milhões). Você pode seguir os comentários nos arquivos yaml e modificar as configurações para avaliar o modelo apenas no benchmark M-BEIR_local.
bash run_eval_pipeline_inbatch.sh embed , index , logger e retrieval_results serão salvos no diretório $ UniIR _DIR .
cd src/models/unii_blip/blip_featurefusion/configs_scripts/large/eval/inbatch/ Da mesma forma, se você baixar nosso modelo UniIR pré-treinado, poderá colocar o arquivo blip_ff_large.pth no seguinte caminho:
$ UniIR _DIR /checkpoint/BLIP_FF/Large/Instruct/InBatch/blip_ff_large.pthA configuração padrão avaliará o modelo UniIR BLIP_FF Large nos benchmarks M-BEIR e M-BEIR_local.
bash run_eval_pipeline_inbatch.shA avaliação UniRAG é muito semelhante à avaliação padrão, com as seguintes diferenças:
retrieval_results . Isto é útil quando os resultados recuperados serão usados em aplicações downstream como RAG.retrieve_image_text_pairs em retrieval.yaml estiver definido como True , um candidato complementar será buscado para cada candidato com modalidade somente text ou image . Com esta configuração, o candidato e seu complemento terão sempre a modalidade image, text . Os candidatos complementares são obtidos usando os candidatos originais como consultas (por exemplo, query text -> candidate image -> complement candidate text ).InBatch e inbatch por UniRAG e unirag , respectivamente. Fornecemos os pontos de verificação do modelo UniIR no ? Pontos de verificação . Você pode usar diretamente os pontos de verificação para tarefas de recuperação ou ajustar os modelos para suas próprias tarefas de recuperação.
| Nome do modelo | Versão | Tamanho do modelo | Link do modelo |
|---|---|---|---|
| UniIR (CLIP-SF) | Grande | 5,13GB | Link para baixar |
| UniIR (BLIP-FF) | Grande | 7,49GB | Link para baixar |
Você pode baixá-los por
git clone https://huggingface.co/TIGER-Lab/UniIR
BibTeX:
@article { wei2023 UniIR ,
title = { UniIR : Training and benchmarking universal multimodal information retrievers } ,
author = { Wei, Cong and Chen, Yang and Chen, Haonan and Hu, Hexiang and Zhang, Ge and Fu, Jie and Ritter, Alan and Chen, Wenhu } ,
journal = { arXiv preprint arXiv:2311.17136 } ,
year = { 2023 }
}

