DiSQ Score
1.0.0
Implementação oficial do nosso artigo: Questionamento Socrático Discursivo: Avaliando a Fidelidade da Compreensão das Relações Discursivas dos Modelos de Linguagem (2024) Yisong Miao, Hongfu Liu, Wenqiang Lei, Nancy F. Chen, Min-Yen Kan.
PDF do artigo: https://yisong.me/publications/acl24-DiSQ-CR.pdf
Slides: https://yisong.me/publications/acl24-DiSQ-Slides.pdf
Pôster: https://yisong.me/publications/acl24-DiSQ-Poster.pdf
git clone [email protected]:YisongMiao/DiSQ-Score.git
conda activate
cd DiSQ-Score
cd scripts
pip install -r requirements.txt
Gostaria de saber a DiSQ Score para qualquer modelo de linguagem? Você está convidado a usar este comando de uma linha!

Fornecemos um comando simplificado para avaliar qualquer modelo de linguagem (LM) hospedado no hub do modelo HuggingFace. Recomenda-se usar isso para qualquer modelo novo (especialmente aqueles não estudados em nosso artigo).
bash scripts/one_model.sh <modelurl>
A variável < modelurl > especifica o caminho abreviado no hub huggingface, por exemplo,
bash scripts/one_model.sh meta-llama/Meta-Llama-3-8B
Antes de executar os arquivos bash, edite o arquivo bash para especificar o caminho para o cache HuggingFace local.
Por exemplo, em scripts/one_model.sh:
#!/bin/bash
# Please define your own path here
huggingface_path=YOUR_PATH
você pode alterar YOUR_PATH para o local absoluto do diretório do seu Huggingface Cache (por exemplo, /disk1/yisong/hf-cache ).
Recomendamos pelo menos 200 GB de espaço livre.
Um arquivo de texto de saída será salvo em data/results/verbalizations/Meta-Llama-3-8B.txt , que contém:
=== The results for model: Meta-Llama-3-8B ===
Dataset: pdtb
DiSQ Score : 0.206
Targeted Score: 0.345
Counterfactual Score: 0.722
Consistency: 0.827
DiSQ Score for Comparison.Concession: 0.188
DiSQ Score for Comparison.Contrast: 0.22
DiSQ Score for Contingency.Reason: 0.164
DiSQ Score for Contingency.Result: 0.177
DiSQ Score for Expansion.Conjunction: 0.261
DiSQ Score for Expansion.Equivalence: 0.221
DiSQ Score for Expansion.Instantiation: 0.191
DiSQ Score for Expansion.Level-of-detail: 0.195
DiSQ Score for Expansion.Substitution: 0.151
DiSQ Score for Temporal.Asynchronous: 0.312
DiSQ Score for Temporal.Synchronous: 0.084
=== End of the results for model: Meta-Llama-3-8B ===
=== The results for model: Meta-Llama-3-8B ===
Dataset: ted
DiSQ Score : 0.233
Targeted Score: 0.605
Counterfactual Score: 0.489
Consistency: 0.787
DiSQ Score for Comparison.Concession: 0.237
DiSQ Score for Comparison.Contrast: 0.268
DiSQ Score for Contingency.Reason: 0.136
DiSQ Score for Contingency.Result: 0.211
DiSQ Score for Expansion.Conjunction: 0.268
DiSQ Score for Expansion.Equivalence: 0.205
DiSQ Score for Expansion.Instantiation: 0.194
DiSQ Score for Expansion.Level-of-detail: 0.222
DiSQ Score for Expansion.Substitution: 0.176
DiSQ Score for Temporal.Asynchronous: 0.156
DiSQ Score for Temporal.Synchronous: 0.164
=== End of the results for model: Meta-Llama-3-8B ===
Armazenamos nossos conjuntos de dados em arquivos JSON localizados em data/datasets/dataset_pdtb.json e data/datasets/dataset_ted.json . Por exemplo, vamos pegar uma instância do conjunto de dados PDTB:
"2": {
"Didx": 2,
"arg1": "and special consultants are springing up to exploit the new tool",
"arg2": "Blair Entertainment, has just formed a subsidiary -- 900 Blair -- to apply the technology to television",
"DR": "Expansion.Instantiation.Arg2-as-instance",
"Conn": "for instance",
"events": [
[
"special consultants springing",
"Blair Entertainment formed a subsidiary -- 900 Blair -- to apply the technology to television"
],
[
"special consultants exploit the new tool",
"Blair Entertainment formed a subsidiary -- 900 Blair -- to apply the technology to television"
]
],
"context": "Other long-distance carriers have also begun marketing enhanced 900 service, and special consultants are springing up to exploit the new tool. Blair Entertainment, a New York firm that advises TV stations and sells ads for them, has just formed a subsidiary -- 900 Blair -- to apply the technology to television. "
},
Aqui estão os campos nesta entrada do dicionário:
Didx : O ID do discurso.arg1 e arg2 : Os dois argumentos.DR : A relação discursiva.Conn : O conectivo discursivo.events : uma lista de pares, armazenando os pares de eventos previstos como sinais salientes.context : O contexto do discurso. cd DiSQ-Score
bash scripts/question_generation.sh
Este arquivo bash chamará question_generation.py para gerar perguntas em diferentes configurações.
Os argumentos para question_generation.py são os seguintes:
--dataset : especifica o conjunto de dados, pdtb ou ted .--modelname : Aliases para modelos foram criados. 13b refere-se a LLaMA2-13B, 13bchat a LLaMA2-13B-Chat e vicuna-13b a Vicuna-13B. As URLs específicas para esses modelos podem ser encontradas em disq_config.py .--version : especifica qual versão dos modelos de prompt usar, com opções v1 , v2 , v3 e v4 .--paraphrase : Substitui as perguntas padrão por suas versões parafraseadas, com opções p1 e p2 . Ao contrário das funções padrão que chamam qa_utils.py , as funções parafraseadas chamam qa_utils_p1.py e qa_utils_p2.py , respectivamente.--feature : especifica quais recursos linguísticos usar para as questões para discussão. As características linguísticas incluem conn (conectivo discursivo) e context (contexto discursivo). Os dados históricos de controle de qualidade requerem um script separado. A saída será armazenada, por exemplo, em data/questions/dataset_pdtb_prompt_v1.json na configuração dataset==pdtb e version==v1 .
Pedimos aos nossos usuários que gerem as perguntas por conta própria porque essa abordagem é automática e ajuda a economizar espaço em nosso repositório GitHub (que pode somar cerca de 200 MB). Se você não conseguir executar o arquivo bash, entre em contato conosco para obter os arquivos de perguntas.
cd DiSQ-Score
bash scripts/question_answering.sh
Este arquivo bash chamará question_answering.py para realizar o Questionamento Socrático Discursivo (DiSQ) para qualquer modelo. question_answering.py pega todos os argumentos de question_generation.py , mais os seguintes novos argumentos:
--modelurl : especifica a URL para quaisquer novos modelos que não estejam atualmente no arquivo de configuração. Por exemplo, 'meta-llama/Meta-Llama-3-8B' especifica o modelo LLaMA3-8B e substituirá o argumento modelname .--hf-path : especifica o caminho para armazenar os parâmetros do modelo grande. Recomenda-se pelo menos 200 GB de espaço livre em disco.--device_number : especifica o ID da GPU a ser usada. A saída será armazenada em, por exemplo, data/results/13bchat_dataset_pdtb_prompt_v1/ . A previsão para cada pergunta é uma lista de tokens e suas probabilidades, armazenada em um arquivo pickle dentro da pasta.
Advertência: o modelo Wizard foi retirado pelos desenvolvedores. Aconselhamos os usuários a não experimentarem esses modelos. Verifique o tópico de discussão em: https://huggingface.co/posts/WizardLM/329547800484476.
cd DiSQ-Score
bash scripts/eval.sh
Este arquivo bash chamará eval.py para avaliar as previsões do modelo obtidas anteriormente.
eval.py usa o mesmo conjunto de parâmetros que question_answering.py .
O resultado da avaliação será armazenado em disq_score_pdtb.csv se o conjunto de dados especificado for PDTB.
Existem 20 colunas no arquivo CSV, a saber:
taskcode : indica a configuração que está sendo testada, por exemplo, dataset_pdtb_prompt_v1_13bchat .modelname : especifica qual modelo de linguagem está sendo testado.version : Indica a versão do prompt.paraphrase : o parâmetro para paráfrase.feature : especifica qual recurso foi usado.Overall : A DiSQ Score .Targeted : Pontuação direcionada, um dos três componentes do DiSQ Score .Counterfactual : pontuação contrafactual, um dos três componentes do DiSQ Score .Consistency : Pontuação de consistência, um dos três componentes do DiSQ Score .Comparison.Concession : A DiSQ Score para esta relação discursiva específica.Observe que escolhemos os melhores resultados entre as versões v1 a v4 para marginalizar o impacto dos modelos de prompt.
Para fazer isso, eval.py extrai automaticamente os melhores resultados:
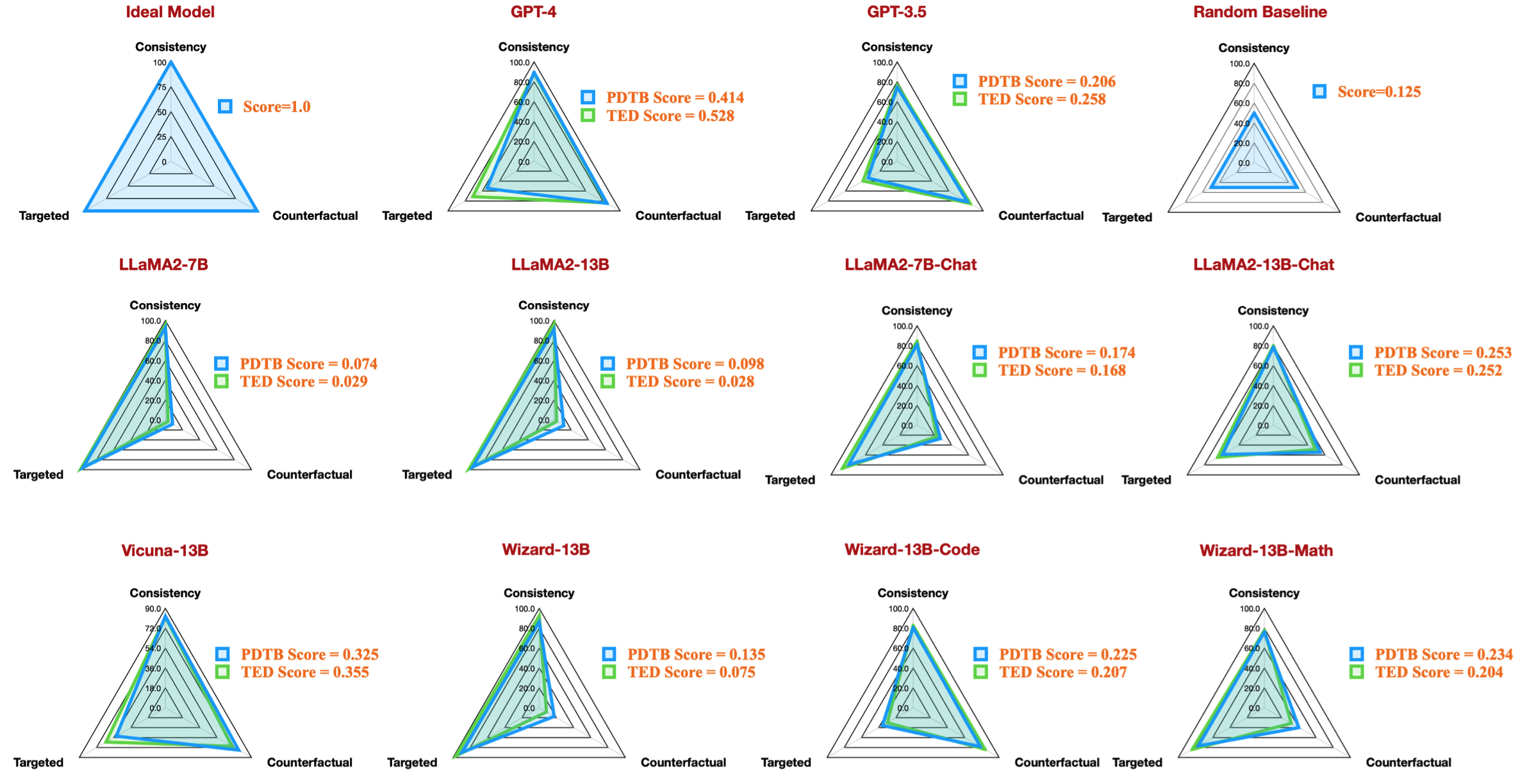
| código de tarefa | nome do modelo | versão | paráfrase | recurso | Geral | Direcionado | Contrafactual | Consistência | Comparação.Concessão | Comparação.Contraste | Contingência. Razão | Contingência.Resultado | Expansão.Conjunção | Expansão.Equivalência | Expansão.Instanciação | Expansão.Nível de detalhe | Expansão.Substituição | Temporal.Assíncrono | Temporal.Síncrono |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| conjunto de dados_pdtb_prompt_v4_7b | 7b | v4 | 0,074 | 0,956 | 0,084 | 0,929 | 0,03 | 0,083 | 0,095 | 0,095 | 0,077 | 0,054 | 0,086 | 0,068 | 0,155 | 0,036 | 0,047 | ||
| dataset_pdtb_prompt_v1_7bchat | 7bchat | v1 | 0,174 | 0,794 | 0,271 | 0,811 | 0,231 | 0,435 | 0,132 | 0,173 | 0,214 | 0,105 | 0,121 | 0,15 | 0,199 | 0,107 | 0,04 | ||
| conjunto de dados_pdtb_prompt_v2_13b | 13b | v2 | 0,097 | 0,945 | 0,112 | 0,912 | 0,037 | 0,099 | 0,081 | 0,094 | 0,126 | 0,101 | 0,113 | 0,107 | 0,077 | 0,083 | 0,093 | ||
| dataset_pdtb_prompt_v1_13bchat | 13bchat | v1 | 0,253 | 0,592 | 0,545 | 0,785 | 0,195 | 0,485 | 0,129 | 0,173 | 0,289 | 0,155 | 0,326 | 0,373 | 0,285 | 0,194 | 0,028 | ||
| conjunto de dados_pdtb_prompt_v2_vicuna-13b | vicunha-13b | v2 | 0,325 | 0,512 | 0,766 | 0,829 | 0,087 | 0,515 | 0,201 | 0,352 | 0,369 | 0,0 | 0,334 | 0,46 | 0,199 | 0,511 | 0,074 |
Por exemplo, esta tabela mostra o melhor resultado para conjuntos de dados PDTB para modelos de código aberto disponíveis, que reproduzem a figura do radar em nosso artigo:
Também fornecemos instruções para avaliar questões de discussão sobre características linguísticas:
--feature como conn e context em question_generation.py (Etapa 1) e execute novamente todos os experimentos.question_generation_history.py . Este script extrairá respostas dos resultados de controle de qualidade armazenados e gerará novas perguntas.Para a maioria dos PNLers, provavelmente você será capaz de executar nosso código com seus ambientes virtuais (conda) existentes.
Quando realizamos nossos experimentos, as versões do pacote eram as seguintes:
torch==2.0.1
transformers==4.30.0
sentencepiece
protobuf
scikit-learn
pandas
No entanto, observamos que os modelos mais recentes exigem versões de pacotes atualizadas:
torch==2.4.0
transformers==4.43.3
sentencepiece
protobuf
scikit-learn
pandas
Se você achar nosso trabalho interessante, fique à vontade para experimentar nosso conjunto de dados/base de código.
Por favor, cite nossa pesquisa se você usou nosso conjunto de dados/base de código:
@inproceedings{acl24discursive,
title={Discursive Socratic Questioning: Evaluating the Faithfulness of Language Models' Understanding of Discourse Relations},
author={Yisong Miao , Hongfu Liu, Wenqiang Lei, Nancy F. Chen, and Min-Yen Kan},
booktitle={Proceedings of the Annual Meeting fof the Association of Computational Linguistics},
month={August},
year={2024},
organization={ACL},
address = "Bangkok, Thailand",
}
Se você tiver dúvidas ou relatórios de bugs, levante um problema ou entre em contato conosco diretamente pelo e-mail:
Endereço de email: ?@?
onde ?️= yisong , ?= comp.nus.edu.sg
CC por 4,0


