Patron
1.0.0
Este repositório contém o código para nosso artigo ACL 2023 Seleção de dados de inicialização a frio para ajuste fino do modelo de linguagem de poucas tentativas: uma abordagem de propagação de incerteza baseada em prompt.
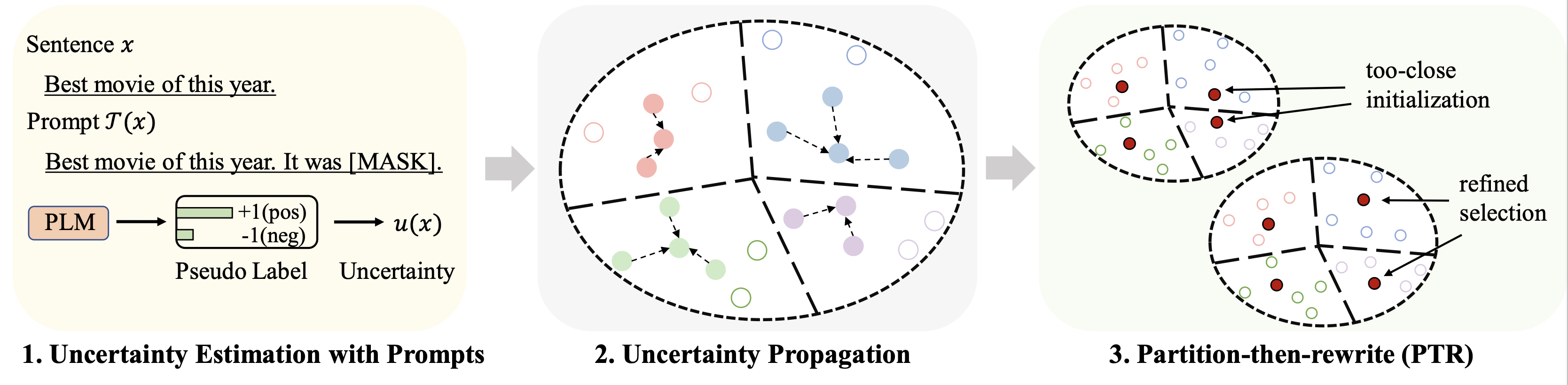
Os resultados em diferentes conjuntos de dados (usando 128 rótulos como orçamento) para ajuste fino são resumidos da seguinte forma:
| Método | IMDB | Yelp completo | AGNews | Yahoo! | DBPedia | TREC | Significar |
|---|---|---|---|---|---|---|---|
| Supervisão Completa (base RoBERTa) | 94,1 | 66,4 | 94,0 | 77,6 | 99,3 | 97,2 | 88,1 |
| Amostragem Aleatória | 86,6 | 47,7 | 84,5 | 60,2 | 95,0 | 85,6 | 76,7 |
| Melhor linha de base (Chang et al. 2021) | 88,5 | 46,4 | 85,6 | 61,3 | 96,5 | 87,7 | 77,6 |
| Patron (nosso) | 89,6 | 51.2 | 87,0 | 65,1 | 97,0 | 91,1 | 80,2 |
Para aprendizado baseado em prompt, usamos o mesmo pipeline do LM-BFF. O resultado com 128 rótulos é mostrado a seguir.
| Método | IMDB | Yelp completo | AGNews | Yahoo! | DBPedia | TREC | Significar |
|---|---|---|---|---|---|---|---|
| Supervisão Completa (base RoBERTa) | 94,1 | 66,4 | 94,0 | 77,6 | 99,3 | 97,2 | 88,1 |
| Amostragem Aleatória | 87,7 | 51.3 | 84,9 | 64,7 | 96,0 | 85,0 | 78,2 |
| Melhor linha de base (Yuan et al., 2020) | 88,9 | 51,7 | 87,5 | 65,9 | 96,8 | 86,5 | 79,5 |
| Patron (nosso) | 89,3 | 55,6 | 87,8 | 67,6 | 97,4 | 88,9 | 81,1 |
python 3.8
transformers==4.2.0
pytorch==1.8.0
scikit-learn
faiss-cpu==1.6.4
sentencepiece==0.1.96
tqdm>=4.62.2
tensorboardX
nltk
openprompt
Usamos os quatro conjuntos de dados a seguir para os experimentos principais.
| Conjunto de dados | Tarefa | Número de aulas | Número de dados/dados de teste não rotulados |
|---|---|---|---|
| IMDB | Sentimento | 2 | 25k/25k |
| Yelp completo | Sentimento | 5 | 39k/10k |
| AG Notícias | Tópico de notícias | 4 | 119 mil/7,6 mil |
| Yahoo! Respostas | Tópico de controle de qualidade | 5 | 180k/30,1k |
| DBPedia | Tópico de Ontologia | 14 | 280 mil/70 mil |
| TREC | Tópico da pergunta | 6 | 5k/0,5k |
Os dados processados podem ser encontrados neste link. A pasta para colocar esses conjuntos de dados será descrita nas partes a seguir.
Execute os seguintes comandos
python gen_embedding_simcse.py --dataset [the dataset you use] --gpuid [the id of gpu you use] --batchsize [the number of data processed in one time]
Fornecemos a pseudo previsão obtida por meio de prompts no link acima para conjuntos de dados. Consulte os documentos originais para obter detalhes.
Execute os seguintes comandos (exemplo no conjunto de dados AG News)
python Patron _sample.py --dataset agnews --k 50 --rho 0.01 --gamma 0.5 --beta 0.5
Alguns hiperparâmetros importantes:
rho : o parâmetro usado para propagação de incerteza na Eq. 6 do papelbeta : a regularização da distância na Eq. 8 do papelgamma : o peso do termo de regularização na Eq. 10 do papel Consulte a pasta finetune para obter instruções detalhadas.
Consulte a pasta prompt_learning para obter instruções detalhadas.
Veja este link como o pipeline para gerar as previsões baseadas em prompts. Observe que você precisa personalizar seus verbalizadores e modelos de prompt.
Para gerar os embeddings de documentos, você pode seguir os comandos acima usando SimCSE.
Depois de gerar o índice para os dados selecionados, você poderá usar os pipelines em Running Fine-tuning Experiments e Running Prompt-based Learning Experiments para experimentos de aprendizado baseados em prompt e ajuste fino de poucos disparos.
Por favor, cite o seguinte artigo se você achar este repositório útil para sua pesquisa. Desde já, obrigado!
@article{yu2022 Patron ,
title={Cold-Start Data Selection for Few-shot Language Model Fine-tuning: A Prompt-Based Uncertainty Propagation Approach
},
author={Yue Yu and Rongzhi Zhang and Ran Xu and Jieyu Zhang and Jiaming Shen and Chao Zhang},
journal={arXiv preprint arXiv:2209.06995},
year={2022}
}
Gostaríamos de agradecer aos autores do repositório SimCSE e OpenPrompt pelo código bem organizado.


