JustJoking.ai
1.0.0
Neste projeto treinei um modelo de transformador para gerar piadas curtas. Então, com uma ligeira modificação no método de inferência, consegui usar o mesmo modelo de forma que, dada uma string inicial como entrada, o modelo tenta completá-la de forma humorística.
Existem dois notebooks fazendo a mesma tarefa.
Resultado da geração de piada 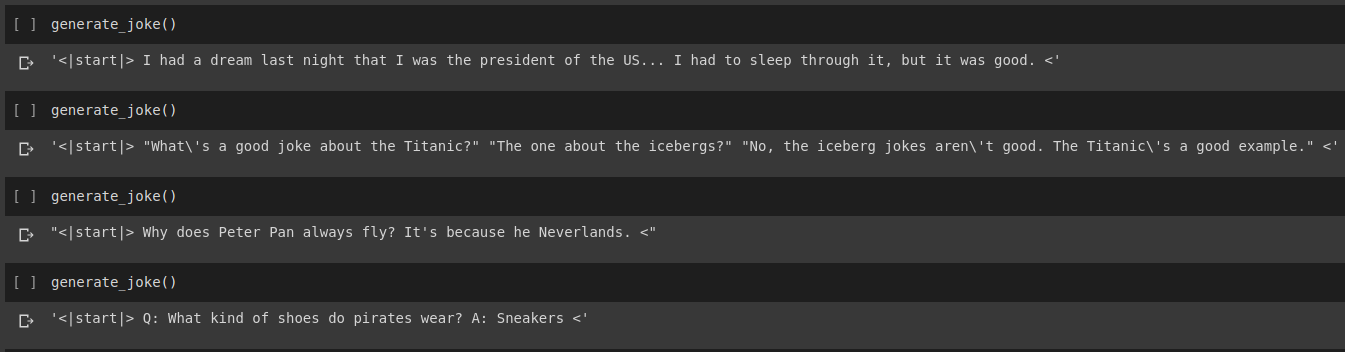
Resultado da conclusão da frase 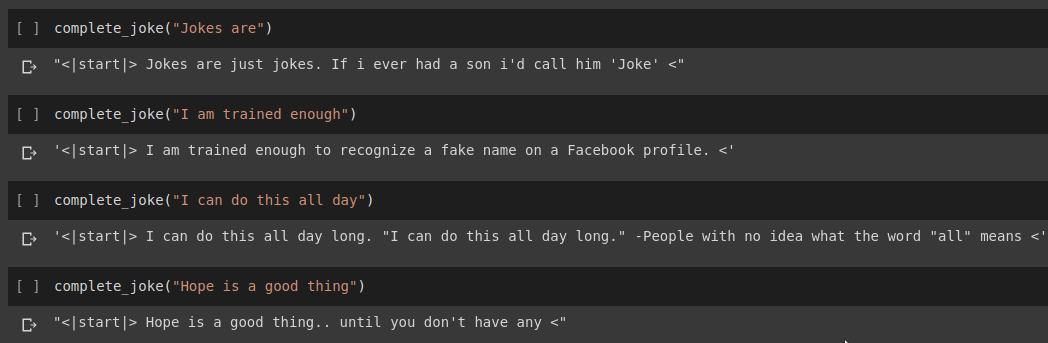
Resultados 
Para nossa tarefa usaremos o conjunto de dados fornecido no Kaggle. É um csv contendo mais de 200.000 piadas curtas retiradas do Reddit.
Nota: Como o conjunto de dados foi simplesmente retirado de vários subreddits, um grande número de piadas no conjunto de dados são bastante racistas e sexistas. Visto que qualquer IA assume seus dados de treinamento como fonte única de conhecimento, deve-se esperar que às vezes nosso modelo gere piadas semelhantes.
Depois de tokenizar nossa string de piada, adicionamos um start_token e um end_token no final da lista tokenizada. Além disso, como nossa string de piada pode ter comprimentos diferentes, também aplicamos preenchimento em todas as strings a um max_length especificado para que todos os tensores tenham formato semelhante em nossos lotes.
O código para isso pode ser encontrado no notebook Joke Generation.ipynb . Neste iremos importar o modelo GPT2Tokenizer e TFGPT2LMHead da biblioteca HuggingFace. O código é escrito em Tensorflow2. O notebook contém comentários que fornecem explicações para o código em locais adequados. Além disso, o HuggingFace Docs fornece uma boa documentação sobre quais são os parâmetros de entrada e o valor de retorno do modelo. Para a implementação baseada em PyTorch, consulte o repositório Humour.ai de Tanul Singh
O código para isso pode ser encontrado no notebook Joke_Completion_Pure_TF2_Implementation.ipynb . Levando o projeto um passo adiante para uma compreensão mais profunda de como as coisas estão funcionando, tentei construir um transformador sem biblioteca externa. Referi-me ao tutorial para Transformers fornecido pelo Tensorflow e coloquei algumas das explicações mencionadas em seu tutorial em meu notebook com mais explicações para que seja fácil entender o que está acontecendo.
Primeiro construí um tokenizer para nosso conjunto de dados e tokenizei as strings usando-o. Em seguida, construímos uma camada para Positional Encodings e MultiHeadAttention . Além disso, usei uma Lambda layer para criar as máscaras adequadas para nossos dados.
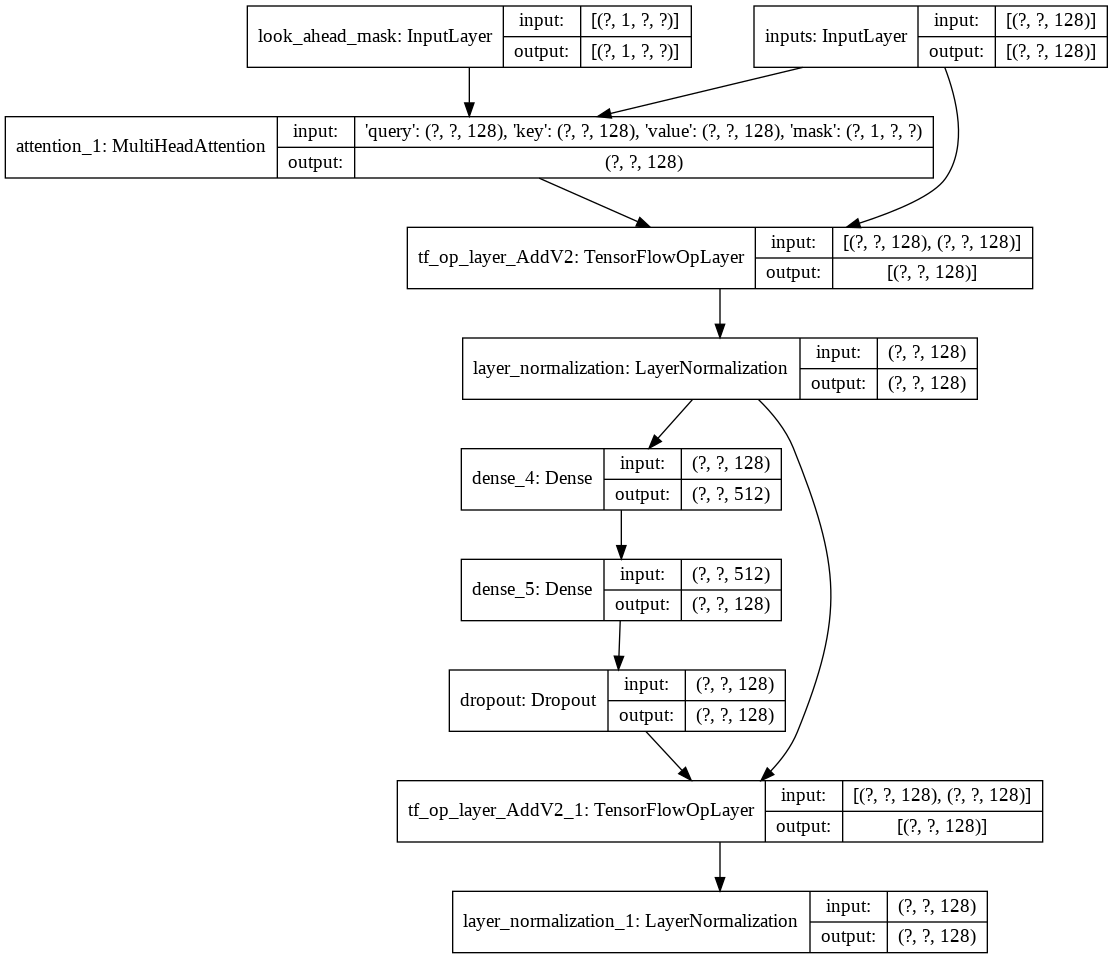
Então criei a construção de uma única decoder layer para nosso decodificador. A seguir está a arquitetura de uma única camada decodificadora.
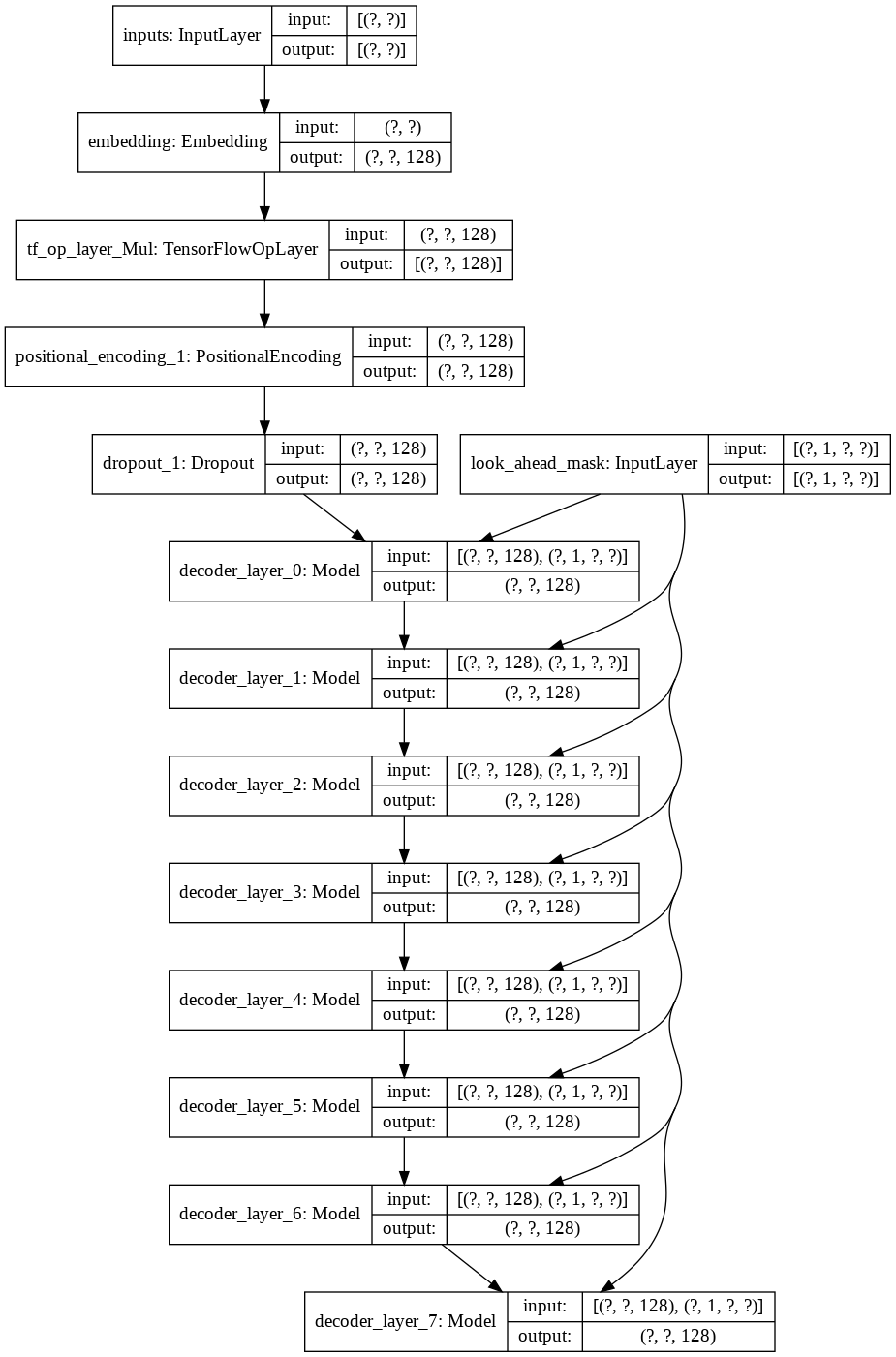
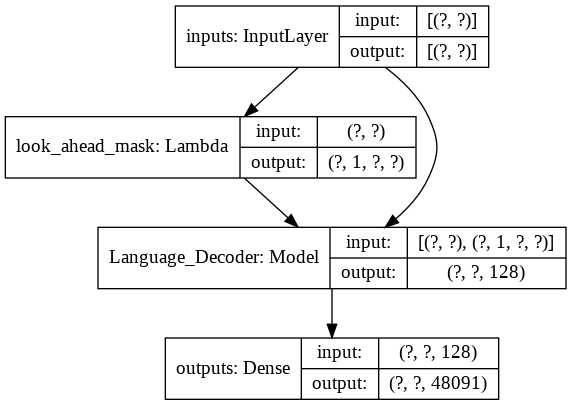
Para o modelo final transformer ele pega os tokens de entrada, passa-os pela camada lamda para obter a máscara e passa a máscara e os tokens para nosso decodificador de linguagem, cuja saída é então passada por uma camada densa. A seguir está a arquitetura do nosso modelo final.