CTCWordBeamSearch
1.0.0
Decodificador de Classificação Temporal Conexionista (CTC) com dicionário e Modelo de Linguagem (LM).
pip install .tests/ e execute pytest para verificar se a instalação funcionou O exemplo de brinquedo a seguir mostra como usar a pesquisa por feixe de palavras. O modelo hipotético (por exemplo, um modelo de reconhecimento de texto) é capaz de reconhecer 3 caracteres diferentes: "a", "b" e " " (espaço em branco). As palavras nesse exemplo de brinquedo podem conter os caracteres "a" e "b" (mas não " ", que é o separador de palavras). O modelo de linguagem é treinado a partir de um corpus de texto que contém apenas duas palavras: “a” e “ba”.
Neste trecho de código, uma instância de pesquisa de feixe de palavras é criada e uma matriz numpy em forma de TxBx(C+1) é decodificada:
import numpy as np
from word_beam_search import WordBeamSearch
corpus = 'a ba' # two words "a" and "ba", separated by whitespace
chars = 'ab ' # the characters that can be recognized (in this order)
word_chars = 'ab' # characters that form words
# RNN output
# 3 time-steps and 4 characters per time time ("a", "b", " ", CTC-blank)
mat = np . array ([[[ 0.9 , 0.1 , 0.0 , 0.0 ]],
[[ 0.0 , 0.0 , 0.0 , 1.0 ]],
[[ 0.6 , 0.4 , 0.0 , 0.0 ]]])
# initialize word beam search (only do this once in your code)
wbs = WordBeamSearch ( 25 , 'Words' , 0.0 , corpus . encode ( 'utf8' ), chars . encode ( 'utf8' ), word_chars . encode ( 'utf8' ))
# compute label string
label_str = wbs . compute ( mat )O decodificador retorna uma lista com uma string de rótulo decodificada para cada elemento do lote. Para finalmente obter as strings de caracteres, mapeie cada rótulo para seu caractere correspondente:
char_str = [] # decoded texts for batch
for curr_label_str in label_str :
s = '' . join ([ chars [ label ] for label in curr_label_str ])
char_str . append ( s )Exemplos:
tests/test_word_beam_search.py Parâmetros do construtor da classe WordBeamSearch :
0<len(wordChars)<len(chars) . Caso apenas palavras isoladas tenham que ser detectadas, não há necessidade de caractere de separação, portanto os dois parâmetros também podem ser iguais: 0<len(wordChars)<=len(chars) Entrada para o método WordBeamSearch.compute :
A pesquisa de feixe de palavras é um algoritmo de decodificação CTC. Ele é usado para tarefas de reconhecimento de sequência, como reconhecimento de texto manuscrito ou reconhecimento automático de fala.
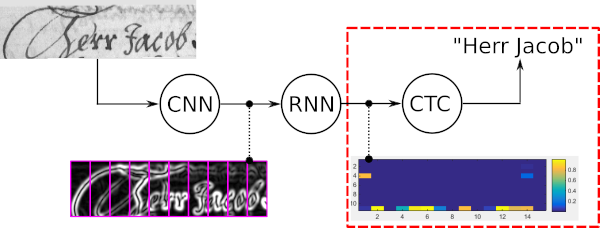
As quatro propriedades principais da pesquisa por feixe de palavras são:
O exemplo a seguir mostra um caso de uso típico de pesquisa por feixe de palavras junto com os resultados fornecidos por cinco decodificadores diferentes. A decodificação do melhor caminho e a pesquisa de feixe baunilha erram as palavras, pois esses decodificadores usam apenas a saída ruidosa do modelo óptico. Estender a pesquisa vanilla beam por um LM em nível de caractere melhora o resultado, permitindo apenas sequências de caracteres prováveis. A passagem de token usa um dicionário e um LM em nível de palavra e, portanto, acerta todas as palavras. No entanto, não é capaz de reconhecer cadeias de caracteres arbitrárias como números. A pesquisa por feixe de palavras é capaz de reconhecer as palavras usando um dicionário, mas também é capaz de identificar corretamente os caracteres que não são palavras.

Mais informações:
extras/prototype/extras/tf/ Por favor, cite o artigo a seguir se você estiver usando a pesquisa por feixe de palavras em seu trabalho de pesquisa.
@inproceedings{scheidl2018wordbeamsearch,
title = {Word Beam Search: A Connectionist Temporal Classification Decoding Algorithm},
author = {Scheidl, H. and Fiel, S. and Sablatnig, R.},
booktitle = {16th International Conference on Frontiers in Handwriting Recognition},
pages = {253--258},
year = {2018},
organization = {IEEE}
}


