LM SupCon
1.0.0
Este repositório cobre a implementação do seguinte artigo: Aprendizagem Contrastiva para Alunos de Línguas de Poucos Tiros Baseados em Prompt, de Yiren Jian, Chongyang Gao e Soroush Vosoughi, aceito no NAACL 2022.
Se você achar este repositório útil para sua pesquisa, considere citar o artigo.
@inproceedings { jian-etal-2022-contrastive ,
title = " Contrastive Learning for Prompt-based Few-shot Language Learners " ,
author = " Jian, Yiren and
Gao, Chongyang and
Vosoughi, Soroush " ,
booktitle = " Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies " ,
month = jul,
year = " 2022 " ,
address = " Seattle, United States " ,
publisher = " Association for Computational Linguistics " ,
url = " https://aclanthology.org/2022.naacl-main.408 " ,
pages = " 5577--5587 " ,
abstract = "The impressive performance of GPT-3 using natural language prompts and in-context learning has inspired work on better fine-tuning of moderately-sized models under this paradigm. Following this line of work, we present a contrastive learning framework that clusters inputs from the same class for better generality of models trained with only limited examples. Specifically, we propose a supervised contrastive framework that clusters inputs from the same class under different augmented {``}views{''} and repel the ones from different classes. We create different {``}views{''} of an example by appending it with different language prompts and contextual demonstrations. Combining a contrastive loss with the standard masked language modeling (MLM) loss in prompt-based few-shot learners, the experimental results show that our method can improve over the state-of-the-art methods in a diverse set of 15 language tasks. Our framework makes minimal assumptions on the task or the base model, and can be applied to many recent methods with little modification.",
} Nosso código é fortemente emprestado de LM-BFF e SupCon ( /src/losses.py ).
Este repositório foi testado com Ubuntu 18.04.5 LTS, Python 3.7, PyTorch 1.6.0 e CUDA 10.1. Você precisará de uma GPU de 48 GB para experimentos com RoBERTa-base e 4 GPUs de 48 GB para RoBERTa-large. Realizamos nossos experimentos na Nvidia RTX-A6000 e RTX-8000, mas a Nvidia A100 com 40 GB também deve funcionar.
Usamos conjuntos de dados pré-processados (SST-2, SST-5, MR, CR, MPQA, Subj, TREC, CoLA, MNLI, SNLI, QNLI, RTE, MRPC, QQP) do LM-BFF. LM-BFF oferece scripts úteis para baixar e preparar o conjunto de dados. Basta executar os comandos abaixo.
cd data
bash download_dataset.shEm seguida, use o seguinte comando para gerar conjuntos de dados de 16 disparos que usamos no estudo.
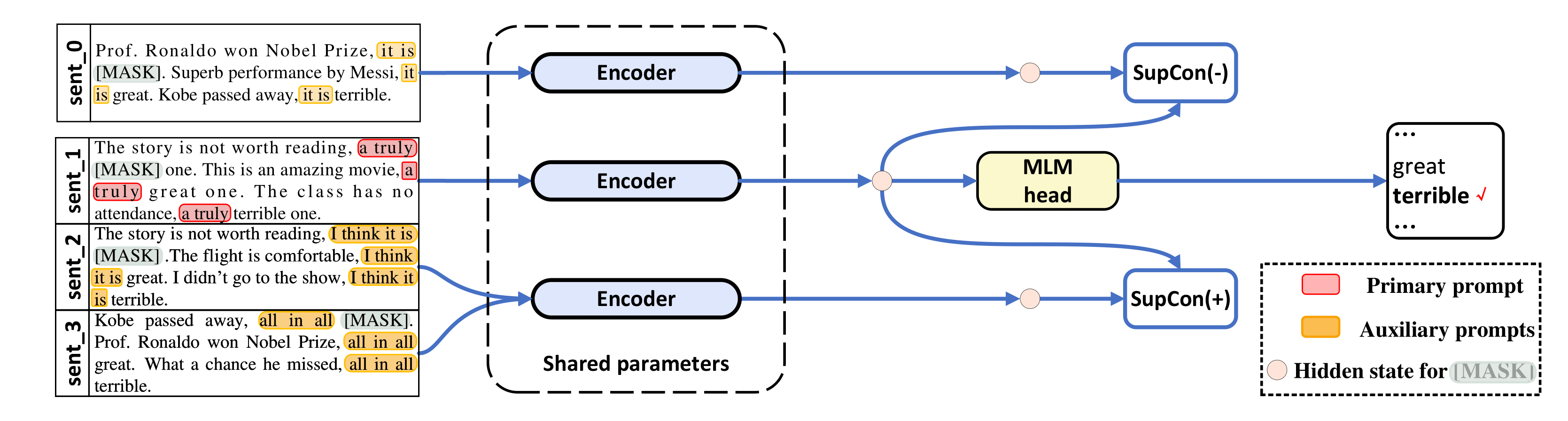
python tools/generate_k_shot_data.py Os prompts primários (modelos) usados para tarefas foram predefinidos em run_experiments.sh . Os modelos auxiliares usados ao gerar múltiplas visualizações de entradas para aprendizagem contrastiva podem ser encontrados em /auto_template/$TASK .
Supondo que você tenha uma GPU em seu sistema, mostramos um exemplo de execução de nosso ajuste fino no SST-5 (modelos aleatórios e demonstrações aleatórias para "visualizações aumentadas" de entradas).
for seed in 13 21 42 87 100 # ### random seeds for different train-test splits
do
for bs in 40 # ### batch size
do
for lr in 1e-5 # ### learning rate for MLM loss
do
for supcon_lr in 1e-5 # ### learning rate for SupCon loss
do
TAG=exp
TYPE=prompt-demo
TASK=sst-5
BS= $bs
LR= $lr
SupCon_LR= $supcon_lr
SEED= $seed
MODEL=roberta-base
bash run_experiment.sh
done
done
done
done
rm -rf result/ Nossa estrutura também se aplica ao método baseado em prompt sem demonstrações, ou seja, TYPE=prompt (neste caso, apenas amostramos modelos aleatoriamente para gerar "visualizações aumentadas"). Os resultados são salvos em log .
Usar RoBERTa-large como modelo básico requer 4 GPUs, cada uma com 48 GB de memória. Você precisa primeiro editar a linha 20 em src/models.py para ser def __init__(self, hidden_size=1024) .
for seed in 13 21 42 87 100 # ### random seeds for different train-test splits
do
for bs in 10 # ### batch size for each GPU, total batch size is then 40
do
for lr in 1e-5 # ### learning rate for MLM loss
do
for supcon_lr in 1e-5 # ### learning rate for SupCon loss
do
TAG=exp
TYPE=prompt-demo
TASK=sst-5
BS= $bs
LR= $lr
SupCon_LR= $supcon_lr
SEED= $seed
MODEL=roberta-large
bash run_experiment.sh
done
done
done
done
rm -rf result/ python tools/gather_result.py --condition "{'tag': 'exp', 'task_name': 'sst-5', 'few_shot_type': 'prompt-demo'}"
Ele coletará os resultados do log e calculará a média e o desvio padrão nessas 5 divisões do teste de trem.
Para qualquer dúvida, entre em contato com os autores.
Obrigado ao LM-BFF e SupCon, pelas implementações preliminares.


