alpaca-rlhf
Ajustando LLaMA com RLHF (Aprendizagem por Reforço com Feedback Humano).
Demonstração on-line
Modificações no DeepSpeed Chat
Passo 1
- alpaca_rlhf/deepspeed_chat/training/step1_supervised_finetuning/main.py#main()
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- Treine apenas nas respostas e adicione eos
- Remover end_of_conversation_token
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#PromptDataset# getitem
- Os rótulos diferem da entrada
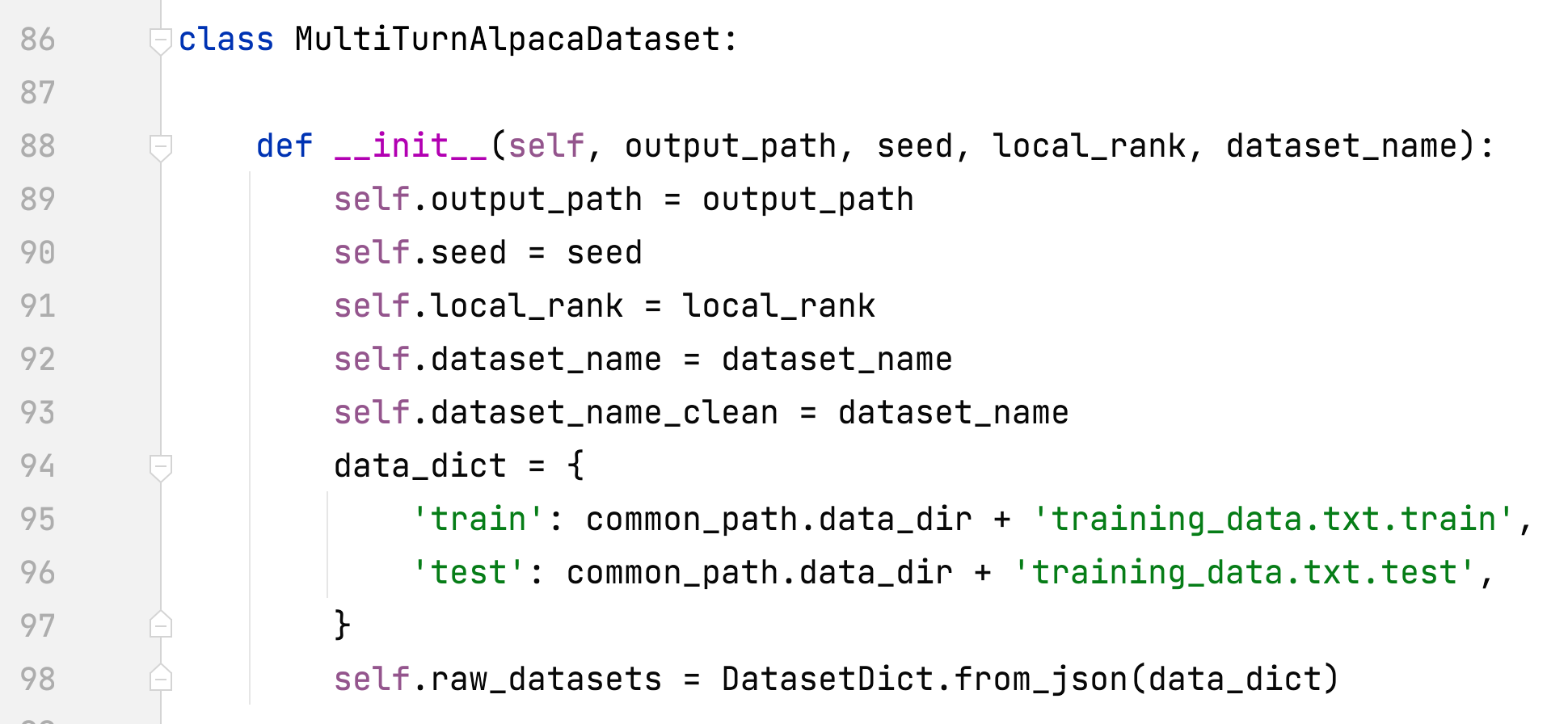
- alpaca_rlhf/deepspeed_chat/training/utils/data/raw_datasets.py#MultiTurnAlpacaDataset
- adicionar MultiTurnAlpacaDataset
- alpaca_rlhf/deepspeed_chat/training/utils/module/lora.py#convert_linear_layer_to_lora
- Suporta vários nomes de módulos para lora
Etapa 2
- alpaca_rlhf/deepspeed_chat/training/step2_reward_model_finetuning/main.py#main()
- alpaca_rlhf/deepspeed_chat/training/utils/model/reward_model.py#RewardModel#forward()
- Corrigindo a instabilidade numérica
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- Remover end_of_conversation_token
Etapa 3
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/main.py#main()
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- Corrigir bug de comprimento máximo
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#DataCollatorRLHF# chamada
- Corrigir bug do lado do preenchimento
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#generate_ Experience
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#_generate_sequence
- Mascare os tokens após o eos
Passo a passo
- Executando todas as três etapas em 2 x A100 80G
- Conjuntos de dados
- Artigo Dahoas/rm-static huggingface GitHub
- MultiTurnAlpaca
- Esta é uma versão multivoltas do conjunto de dados alpaca e é construída com base em AlpacaDataCleaned e ChatAlpaca.
- Insira o diretório ./alpaca_rlhf primeiro e, em seguida, execute os seguintes comandos:
- passo 1: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step1_supervised_finetuning/main.py --sft_only_data_path MultiTurnAlpaca --data_output_path /root/autodl-tmp/rlhf/tmp/ --model_name_or_path decapoda-research/llama-7b-hf --per_device_train_batch_size 8 --per_device_eval_batch_size 8 --max_seq_len 512 --learning_rate 3e-4 --num_train_epochs 1 --gradient_accumulation_steps 8 --num_warmup_steps 100 --output_dir /root/autodl-tmp/rlhf/actor --lora_dim 8 --lora_module_name q_proj,k_proj --only_optimize_lora --deepspeed --zero_stage 2
- quando --sft_only_data_path MultiTurnAlpaca for adicionado, descompacte data/data.zip primeiro.
- passo 2: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step2_reward_model_finetuning/main.py --data_output_path /root/autodl-tmp/rlhf/tmp/ --model_name_or_path decapoda-research/llama-7b -hf --num_padding_at_beginning 0 --per_device_train_batch_size 4 --per_device_eval_batch_size 64 --learning_rate 5e-4 --num_train_epochs 1 --gradient_accumulation_steps 1 --num_warmup_steps 0 --zero_stage 2 --deepspeed --output_dir /root/autodl-tmp/rlhf/critic --lora_dim 8 --lora_module_name q_proj,k_proj --only_optimize_lora
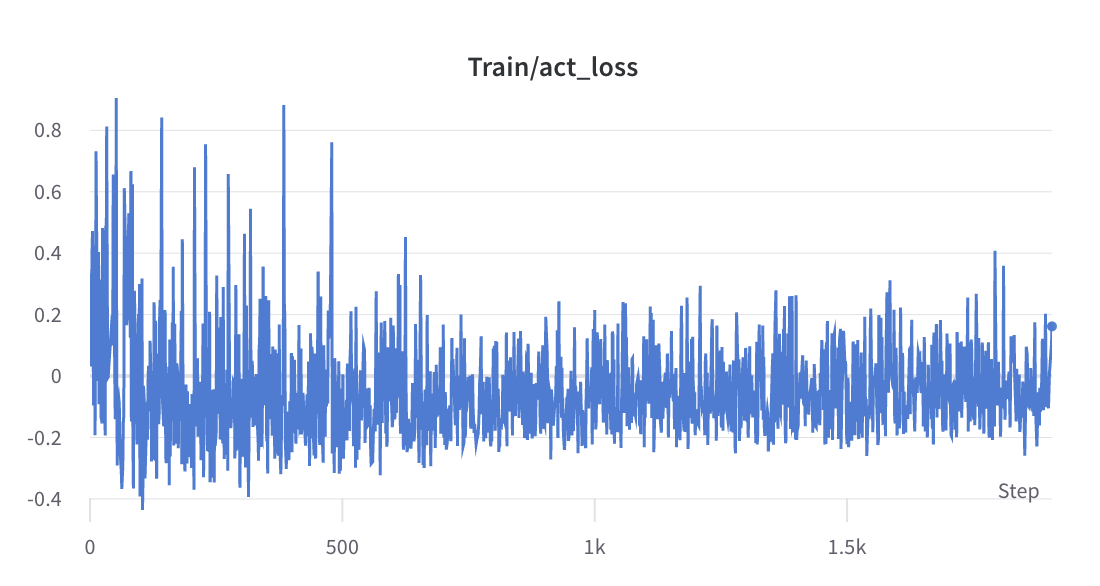
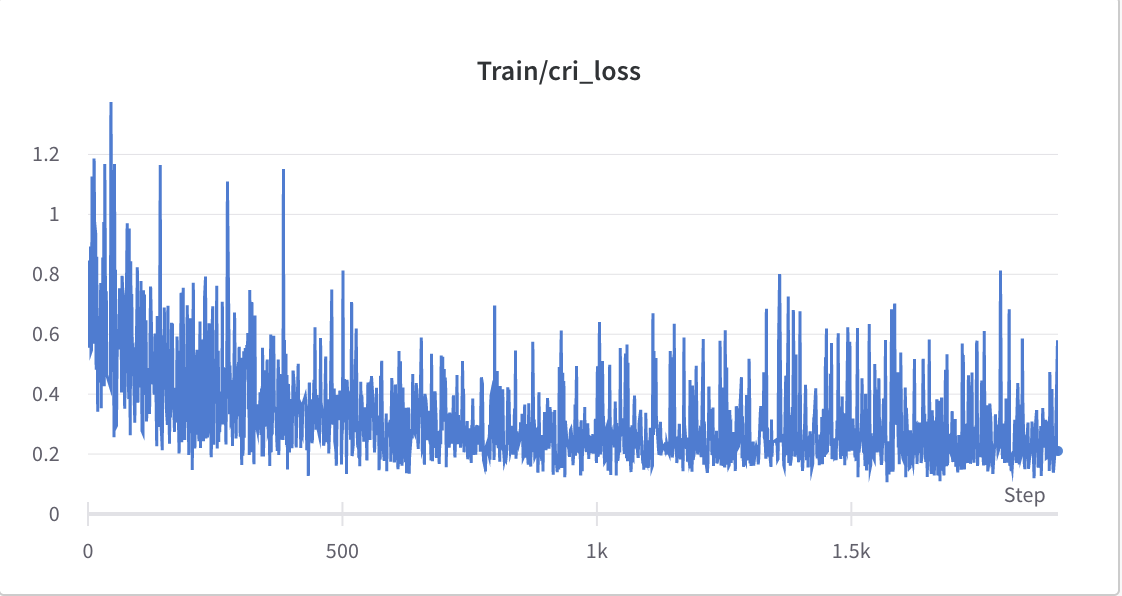
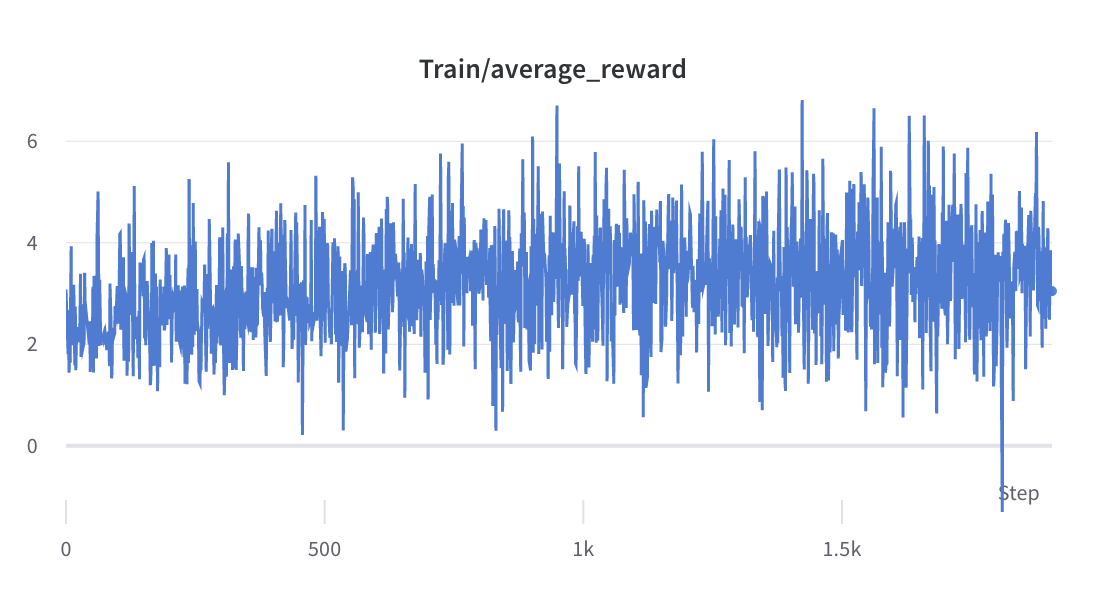
- o processo de treinamento da etapa 2
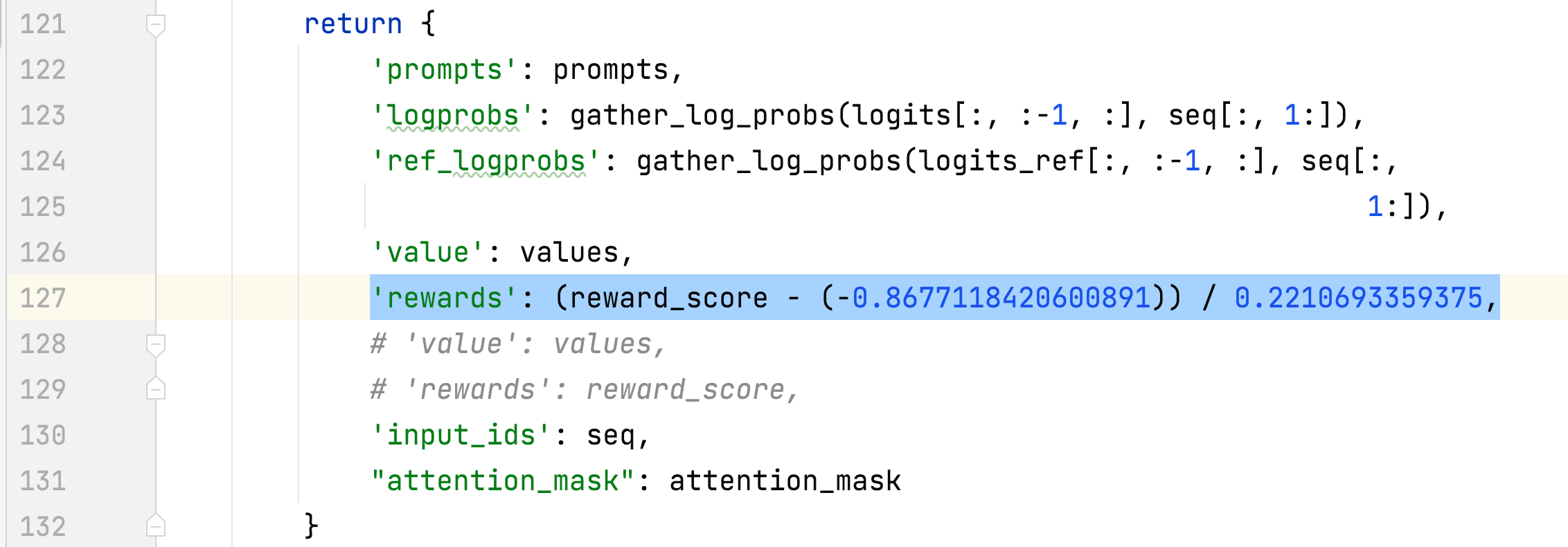
- A média e o desvio padrão da recompensa das respostas escolhidas são coletados e usados para normalizar a recompensa na etapa 3. Em um experimento, eles são -0,8677118420600891 e 0,2210693359375 respectivamente e são usados no alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#generate_ Experience métodos: 'recompensas': (reward_score - (-0,8677118420600891)) / 0,2210693359375.
- passo 3: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/main.py --data_output_path /root/autodl-tmp/rlhf/tmp/ --actor_model_name_or_path /root/autodl-tmp/ rlhf/ator/ --tokenizer_name_or_path decapoda-research/llama-7b-hf --critic_model_name_or_path /root/autodl-tmp/rlhf/critic --actor_zero_stage 2 --critic_zero_stage 2 --num_padding_at_beginning 0 --per_device_train_batch_size 4 --per_device_mini_train_batch_size 4 --ppo_epochs 2 --actor_learning_rate 9.65e-6 --critic_learning_rate 5e-6 --gradient_accumulation_steps 1 --deepspeed --actor_lora_dim 8 --actor_lora_module_name q_proj --critic_lora_dim 8 --critic_lora_module_name q_proj,k_proj --only_optimize_lora --output_dir /root/autodl-tmp/rlhf/final
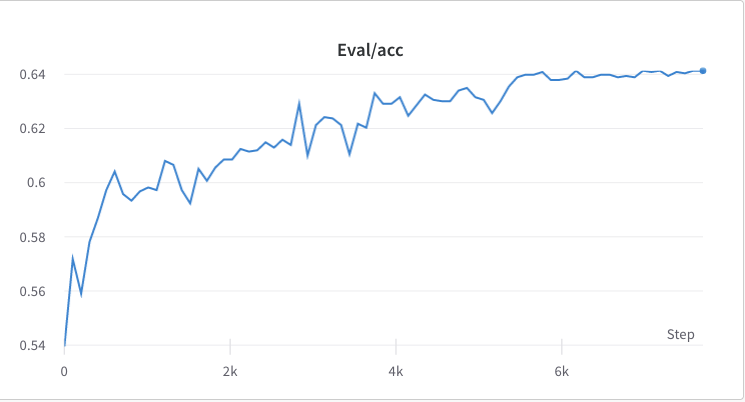
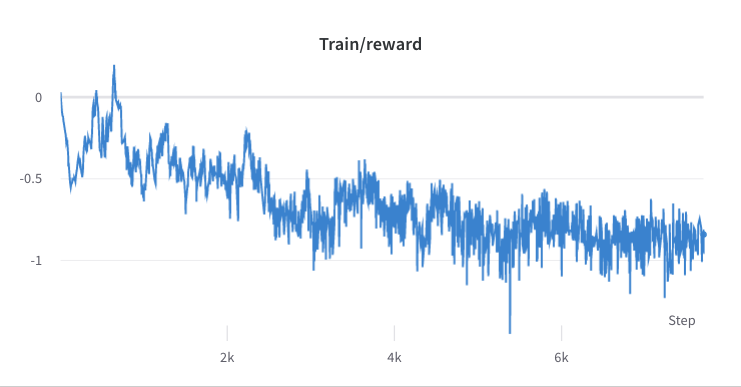
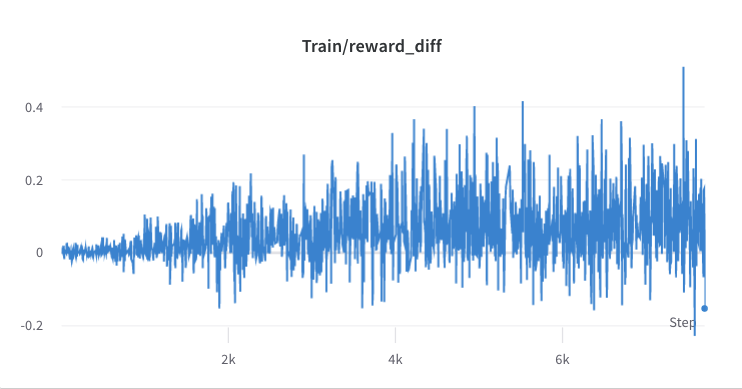
- o processo de treinamento da etapa 3
- Inferência
- nohup sh run_inference.sh 0 alpaca_rlhf/inference/llama_chatbot_gradio.py --path /root/autodl-tmp/rlhf/final/actor > rlhf_inference.log 2>&1 &
- nohup sh run_inference.sh 0 alpaca_rlhf/inference/llama_chatbot_gradio.py --path /root/autodl-tmp/rlhf/actor > sft_inference.log 2>&1 &
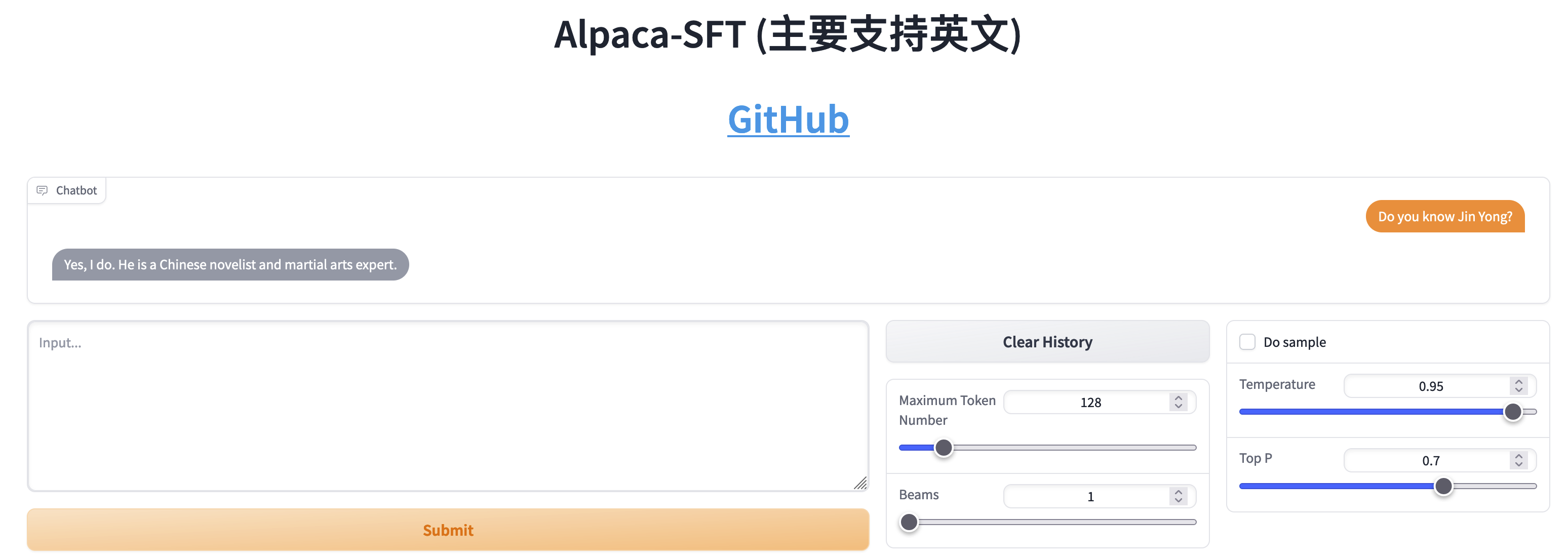
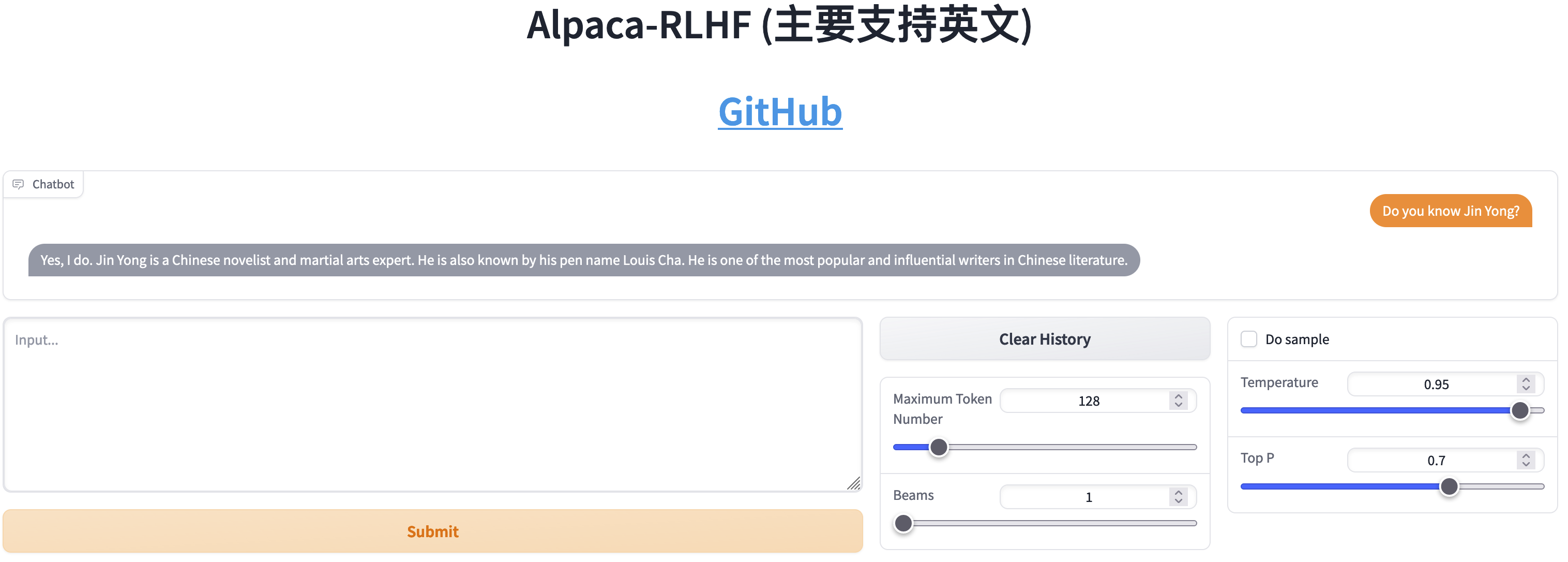
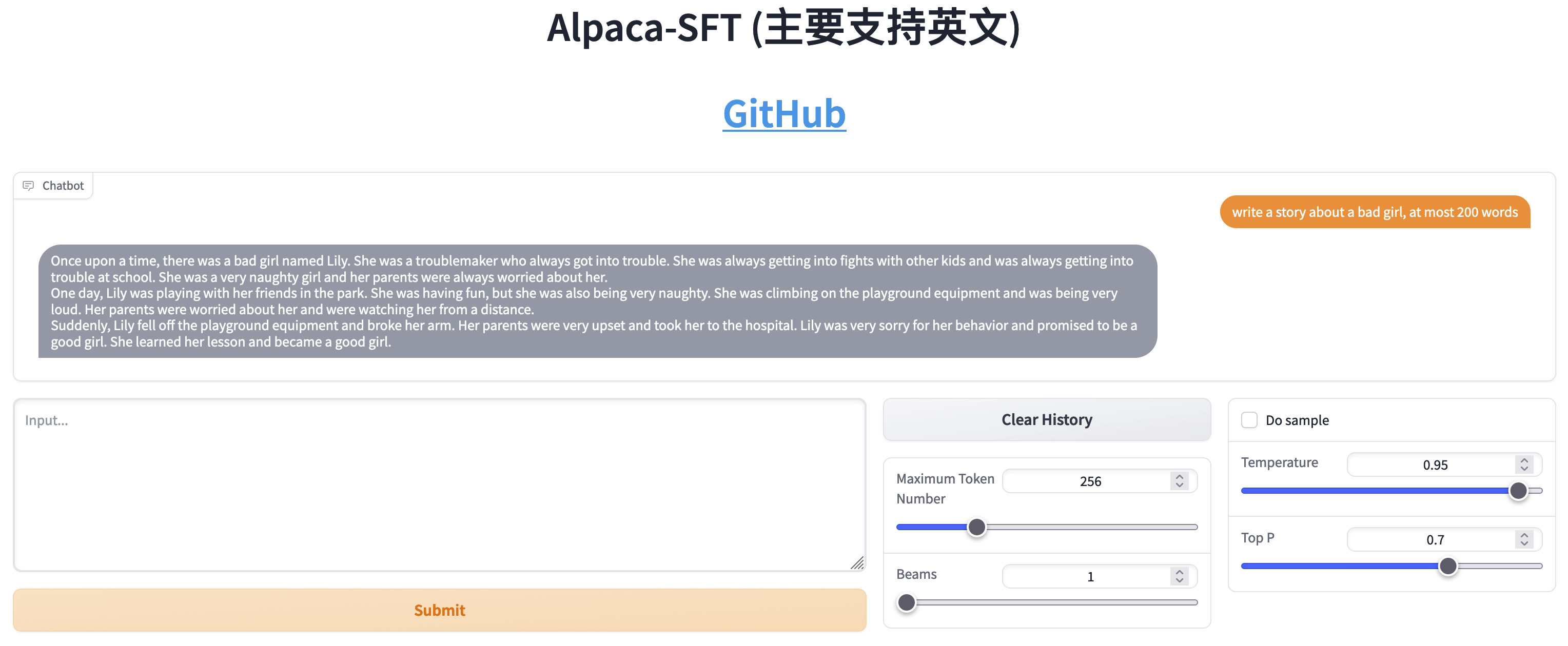
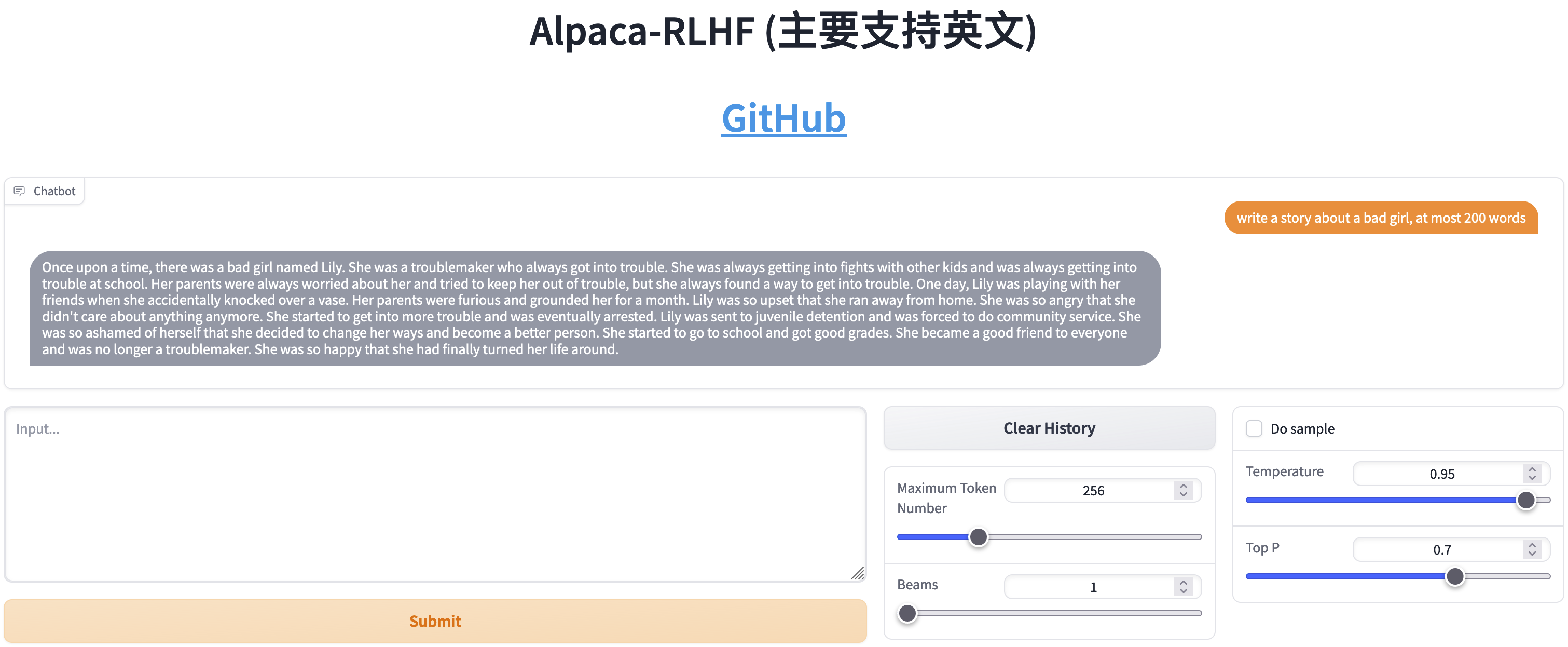
Comparação entre SFT e RLHF
- Bater papo
- Escreva histórias
Referências
Artigos
- 如何正确复现 Instruir GPT / RLHF?
- 影响PPO算法性能的10个关键技巧(附PPO算法简洁Pytorch实现)
Fontes
Ferramentas
Conjuntos de dados
- Conjunto de dados de preferências humanas de Stanford (SHP)
- HH-RLHF
- hh-rlhf
- Treinando um assistente útil e inofensivo com aprendizagem por reforço a partir de feedback humano [artigo]
- Dahoas/estático-hh
- Dahoas/rm-estático
- GPT-4-LLM
- Assistente aberto
Repositórios Relacionados
- minha-alpaca
- alpaca multivoltas