icl selective annotation
1.0.0
Código para anotação seletiva em papel torna os modelos de linguagem melhores para alunos de poucas tentativas
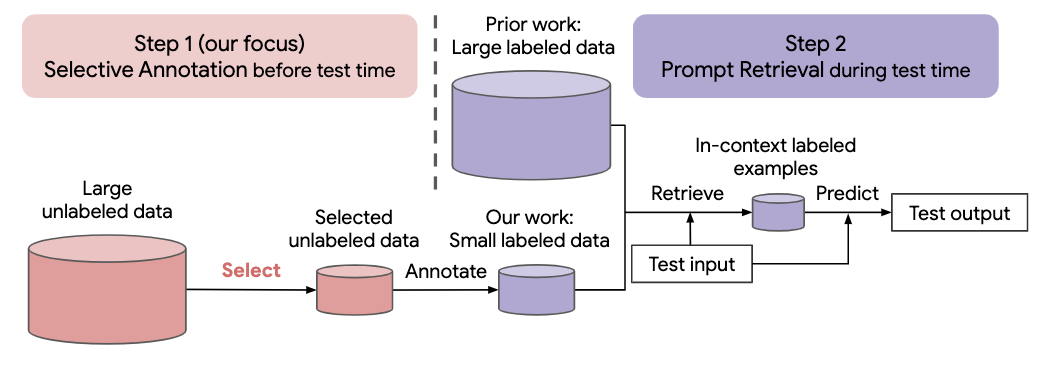
Muitas abordagens recentes para tarefas de linguagem natural baseiam-se nas habilidades notáveis de grandes modelos de linguagem. Grandes modelos de linguagem podem realizar aprendizagem no contexto, onde aprendem uma nova tarefa a partir de algumas demonstrações de tarefas, sem nenhuma atualização de parâmetros. Este trabalho examina as implicações da aprendizagem contextual para a criação de conjuntos de dados para novas tarefas de linguagem natural. Partindo de métodos recentes de aprendizagem no contexto, formulamos uma estrutura de duas etapas com eficiência de anotação: anotação seletiva que escolhe um conjunto de exemplos para anotar a partir de dados não rotulados antecipadamente, seguida por recuperação imediata que recupera exemplos de tarefas do conjunto anotado em tempo de teste. Com base nesta estrutura, propomos um método de anotação seletiva não supervisionado, baseado em gráficos, vote-k , para selecionar diversos exemplos representativos para anotar. Extensos experimentos em 10 conjuntos de dados (abrangendo classificação, raciocínio de bom senso, diálogo e geração de texto/código) demonstram que nosso método de anotação seletiva melhora o desempenho da tarefa por uma grande margem. Em média, vote-k alcança um ganho relativo de 12,9%/11,4% sob um orçamento de anotação de 18/100, em comparação com a seleção aleatória de exemplos para anotar. Em comparação com abordagens de ajuste fino supervisionado de última geração, ele produz desempenho semelhante com 10 a 100 vezes menos custo de anotação em 10 tarefas. Analisamos ainda a eficácia de nossa estrutura em vários cenários: modelos de linguagem com tamanhos variados, métodos alternativos de anotação seletiva e casos em que há uma mudança no domínio dos dados de teste. Esperamos que nossos estudos sirvam de base para anotações de dados à medida que grandes modelos de linguagem são cada vez mais aplicados a novas tarefas
Execute o seguinte comando para clonar este repositório
git clone https://github.com/HKUNLP/icl-selective-annotation
Para estabelecer o ambiente, execute este código no shell:
conda env create -f selective_annotation.yml
conda activate selective_annotation
cd transformers
pip install -e .
Isso criará o ambiente select_annotation que usamos.
Ative o ambiente executando
conda activate selective_annotation
GPT-J como modelo de aprendizagem em contexto, DBpedia como tarefa e vote-k como método de anotação seletiva (1 GPU, 40 GB de memória)
python main.py --task_name dbpedia_14 --selective_annotation_method votek --model_cache_dir models --data_cache_dir datasets --output_dir outputs
Se você achar nosso trabalho útil, cite-nos
@article{Selective_Annotation,
title={Selective Annotation Makes Language Models Better Few-Shot Learners},
author={Hongjin Su and Jungo Kasai and Chen Henry Wu and Weijia Shi and Tianlu Wang and Jiayi Xin and Rui Zhang and Mari Ostendorf and Luke Zettlemoyer and Noah A. Smith and Tao Yu},
journal={ArXiv},
year={2022},
}


