Phi2 mini Chinese
1.0.0
Este projeto é um projeto experimental, com código-fonte aberto e pesos de modelo, e menos dados de pré-treinamento. Se você precisar de um modelo pequeno chinês melhor, pode consultar o projeto ChatLM-mini-Chinese.
Cuidado
Este projeto é um projeto experimental e pode estar sujeito a grandes alterações a qualquer momento, incluindo dados de treinamento, estrutura do modelo, estrutura de diretórios de arquivos, etc. A primeira versão do modelo e verifique tag v1.0
Por exemplo, adicionar pontos no final das frases, converter chinês tradicional em chinês simplificado, excluir sinais de pontuação repetidos (por exemplo, alguns materiais de diálogo têm muitos "。。。。。" ), padronização NFKC Unicode (principalmente o problema de completo- conversão de largura em meia largura e dados de páginas da web u3000 xa0) etc.
Para o processo específico de limpeza de dados, consulte o projeto ChatLM-mini-Chinese.
Este projeto usa o tokenizer BPE byte level . Existem dois tipos de códigos de treinamento fornecidos para segmentadores de palavras: char level e byte level .
Após o treinamento, o tokenizer lembra de verificar se existem símbolos especiais comuns no vocabulário, como t , n , etc. Você pode tentar encode e decode um texto contendo caracteres especiais para ver se ele pode ser restaurado. Se esses caracteres especiais não estiverem incluídos, adicione-os por meio da função add_tokens . Use len(tokenizer) para obter o tamanho do vocabulário tokenizer.vocab_size não conta os caracteres adicionados por meio da função add_tokens .
O treinamento do Tokenizer consome muita memória:
O treinamento de 100 milhões de caracteres byte level requer pelo menos 32G de memória (na verdade, 32G não é suficiente e a troca será acionada com frequência. O treinamento 13600k leva cerca de uma hora).
O treinamento char level de 650 milhões de caracteres (que é exatamente a quantidade de dados na Wikipédia chinesa) requer pelo menos 32G de memória. Como a troca é acionada várias vezes, o uso real é muito maior que 32G. O treinamento 13600K leva cerca de metade. hora.
Portanto, quando o conjunto de dados é grande (nível GB), é recomendável fazer uma amostragem do conjunto de dados ao treinar tokenizer .
Use uma grande quantidade de texto para pré-treinamento não supervisionado, principalmente usando o conjunto de dados BELLE do bell open source .
Formato do conjunto de dados: uma frase para uma amostra. Se for muito longo, pode ser truncado e dividido em múltiplas amostras.
Durante o processo de pré-treinamento do CLM, a entrada e a saída do modelo são as mesmas e, ao calcular a perda de entropia cruzada, devem ser deslocadas em um bit ( shift ).
Ao processar o corpus da enciclopédia, recomenda-se adicionar a marca '[EOS]' ao final de cada entrada. Outro processamento de corpus é semelhante. O final de um doc (que pode ser o final de um artigo ou de um parágrafo) deve ser marcado com '[EOS]' . A marca inicial '[BOS]' pode ser adicionada ou não.
Use principalmente o conjunto de dados do bell open source . Obrigado chefe BELLE.
O formato dos dados para treinamento SFT é o seguinte:
text = f"##提问: n { example [ 'instruction' ] } n ##回答: n { example [ 'output' ][ EOS ]" Quando o modelo calcula a perda, ele irá ignorar a parte antes da marca "##回答:" ( "##回答:" também será ignorado), a partir do final de "##回答:" .
Lembre-se de adicionar a marca especial de final de frase EOS , caso contrário você não saberá quando parar ao decode o modelo. A marca de início da frase BOS pode ser preenchida ou deixada em branco.
Adote um método de otimização de preferência DPO mais simples e que economize memória.
Ajuste o modelo SFT de acordo com as preferências pessoais. O conjunto de dados deve construir três colunas: prompt , chosen e rejected . A coluna rejected contém alguns dados do modelo primário no estágio sft (por exemplo, sft treina 4 epoch e leva um. Modelo de ponto de verificação epoch 0,5) Gerar, se a similaridade entre o rejected gerado e chosen for superior a 0,9, então esses dados não serão necessários.
Existem dois modelos no processo DPO, um é o modelo a ser treinado e o outro é o modelo de referência. Ao carregar, na verdade é o mesmo modelo, mas o modelo de referência não participa das atualizações de parâmetros.
Repositório huggingface de peso do modelo: Phi2-Chinese-0.2B
from transformers import AutoTokenizer , AutoModelForCausalLM , GenerationConfig
import torch
device = torch . device ( "cuda" ) if torch . cuda . is_available () else torch . device ( "cpu" )
tokenizer = AutoTokenizer . from_pretrained ( 'charent/Phi2-Chinese-0.2B' )
model = AutoModelForCausalLM . from_pretrained ( 'charent/Phi2-Chinese-0.2B' ). to ( device )
txt = '感冒了要怎么办?'
prompt = f"##提问: n { txt } n ##回答: n "
# greedy search
gen_conf = GenerationConfig (
num_beams = 1 ,
do_sample = False ,
max_length = 320 ,
max_new_tokens = 256 ,
no_repeat_ngram_size = 4 ,
eos_token_id = tokenizer . eos_token_id ,
pad_token_id = tokenizer . pad_token_id ,
)
tokend = tokenizer . encode_plus ( text = prompt )
input_ids , attention_mask = torch . LongTensor ([ tokend . input_ids ]). to ( device ),
torch . LongTensor ([ tokend . attention_mask ]). to ( device )
outputs = model . generate (
inputs = input_ids ,
attention_mask = attention_mask ,
generation_config = gen_conf ,
)
outs = tokenizer . decode ( outputs [ 0 ]. cpu (). numpy (), clean_up_tokenization_spaces = True , skip_special_tokens = True ,)
print ( outs ) ##提问:
感冒了要怎么办?
##回答:
感冒是由病毒引起的,感冒一般由病毒引起,以下是一些常见感冒的方法:
- 洗手,特别是在接触其他人或物品后。
- 咳嗽或打喷嚏时用纸巾或手肘遮住口鼻。
- 用手触摸口鼻,特别是喉咙和鼻子。
- 如果咳嗽或打喷嚏,可以用纸巾或手绢来遮住口鼻,但要远离其他人。
- 如果你感冒了,最好不要触摸自己的眼睛、鼻子和嘴巴。
- 在感冒期间,最好保持充足的水分和休息,以缓解身体的疲劳。
- 如果您已经感冒了,可以喝一些温水或盐水来补充体液。
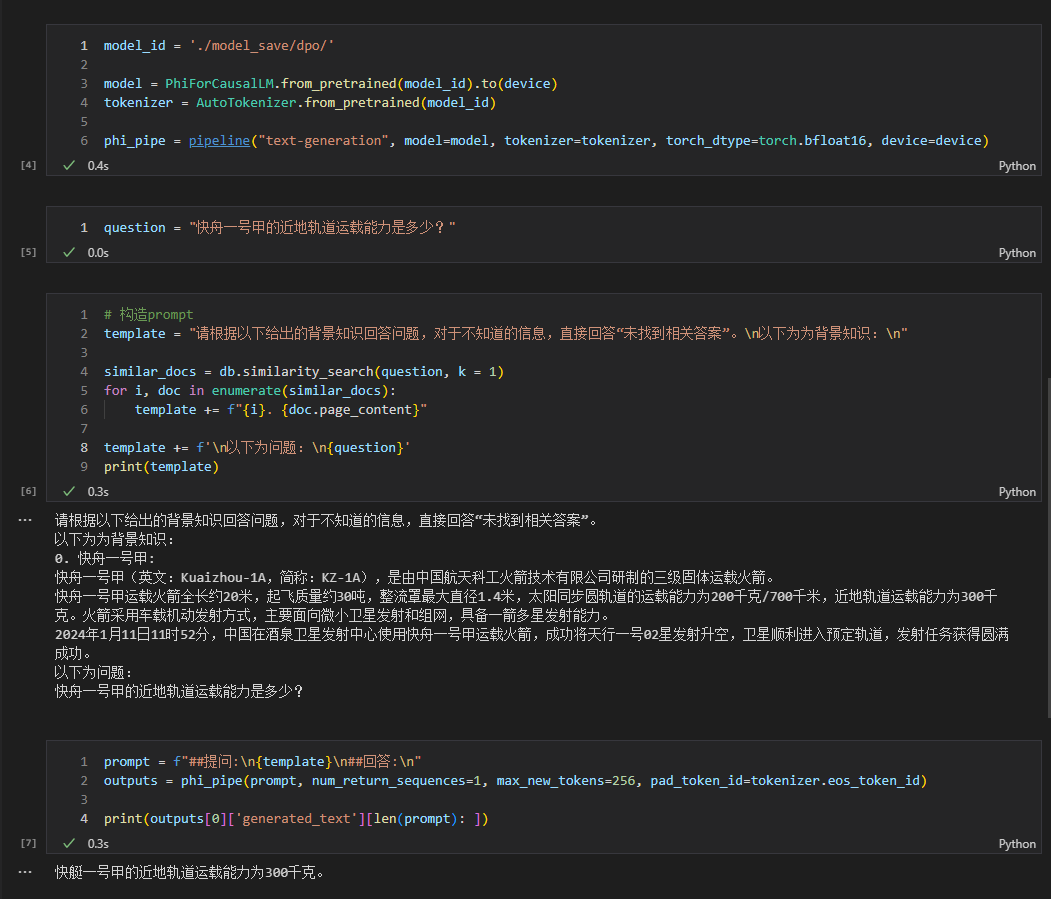
- 另外,如果感冒了,建议及时就医。 Consulte rag_with_langchain.ipynb para o código específico.
Se você acha que este projeto é útil para você, cite-o.
@misc{Charent2023,
author={Charent Chen},
title={A small Chinese causal language model with 0.2B parameters base on Phi2},
year={2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/charent/Phi2-mini-Chinese}},
}
Este projeto não assume os riscos e responsabilidades de segurança de dados e riscos de opinião pública causados por modelos e códigos de código aberto, ou os riscos e responsabilidades decorrentes de qualquer modelo ser enganado, abusado, disseminado ou explorado indevidamente.


