DialogStudio
1.0.0

Papel, Huggingface, Modelo, Twitter
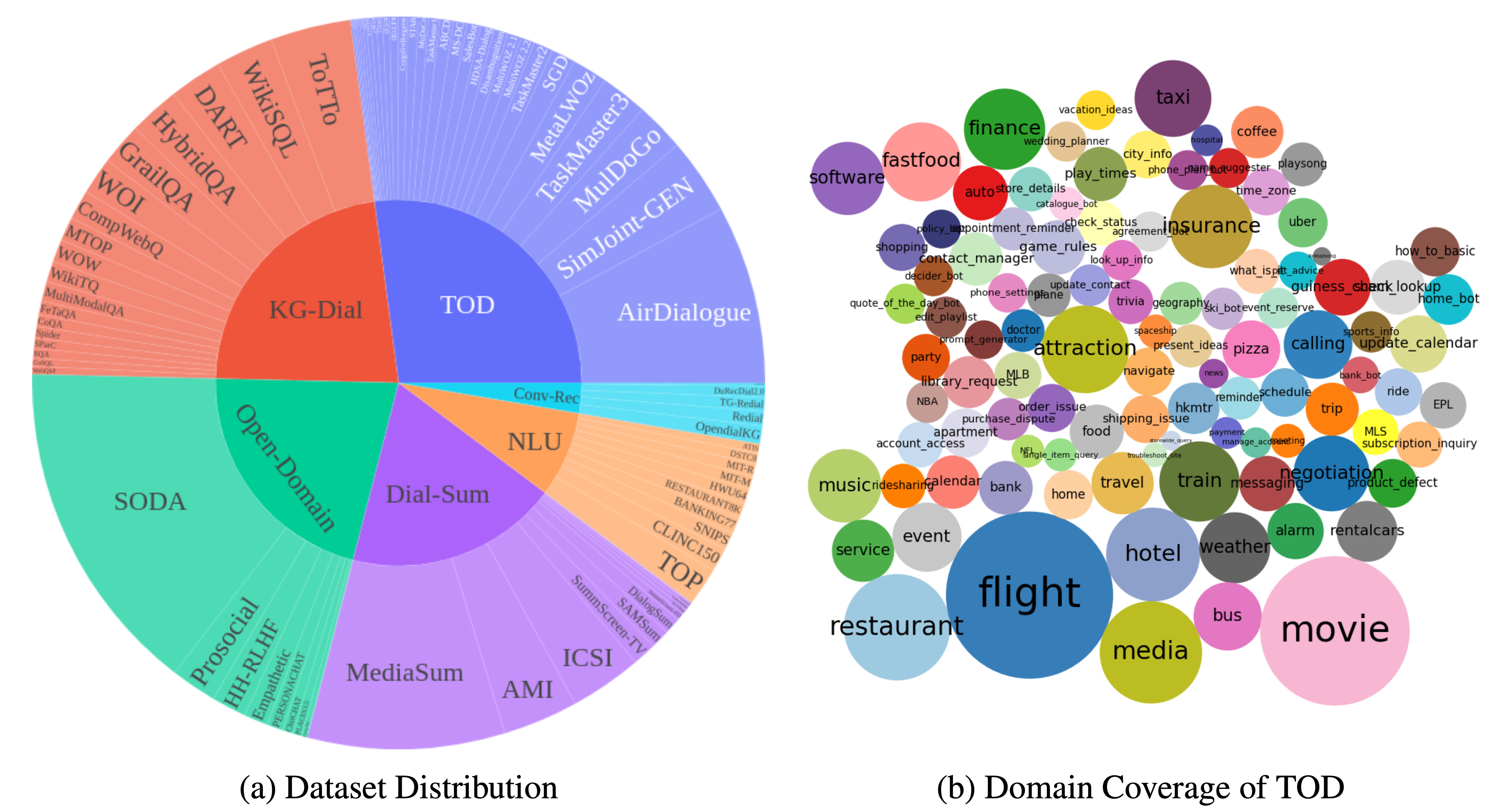
DialogStudio é uma grande coleção e conjuntos de dados de diálogo unificados. A figura abaixo fornece um resumo das estatísticas gerais associadas ao DialogStudio . DialogStudio unificou cada conjunto de dados, preservando suas informações originais, e isso ajuda a apoiar a pesquisa em conjuntos de dados individuais e no treinamento de Large Language Model (LLM). A lista completa de todos os conjuntos de dados disponíveis está aqui.
Os dados podem ser baixados através do Huggingface conforme apresentado em Carregando dados. Também fornecemos exemplos para cada conjunto de dados neste repositório. Para obter detalhes mais granulares e específicos da categoria, consulte as pastas individuais correspondentes a cada categoria na coleção DialogStudio , por exemplo, conjunto de dados MULTIWOZ2_2 na categoria diálogos orientados a tarefas.
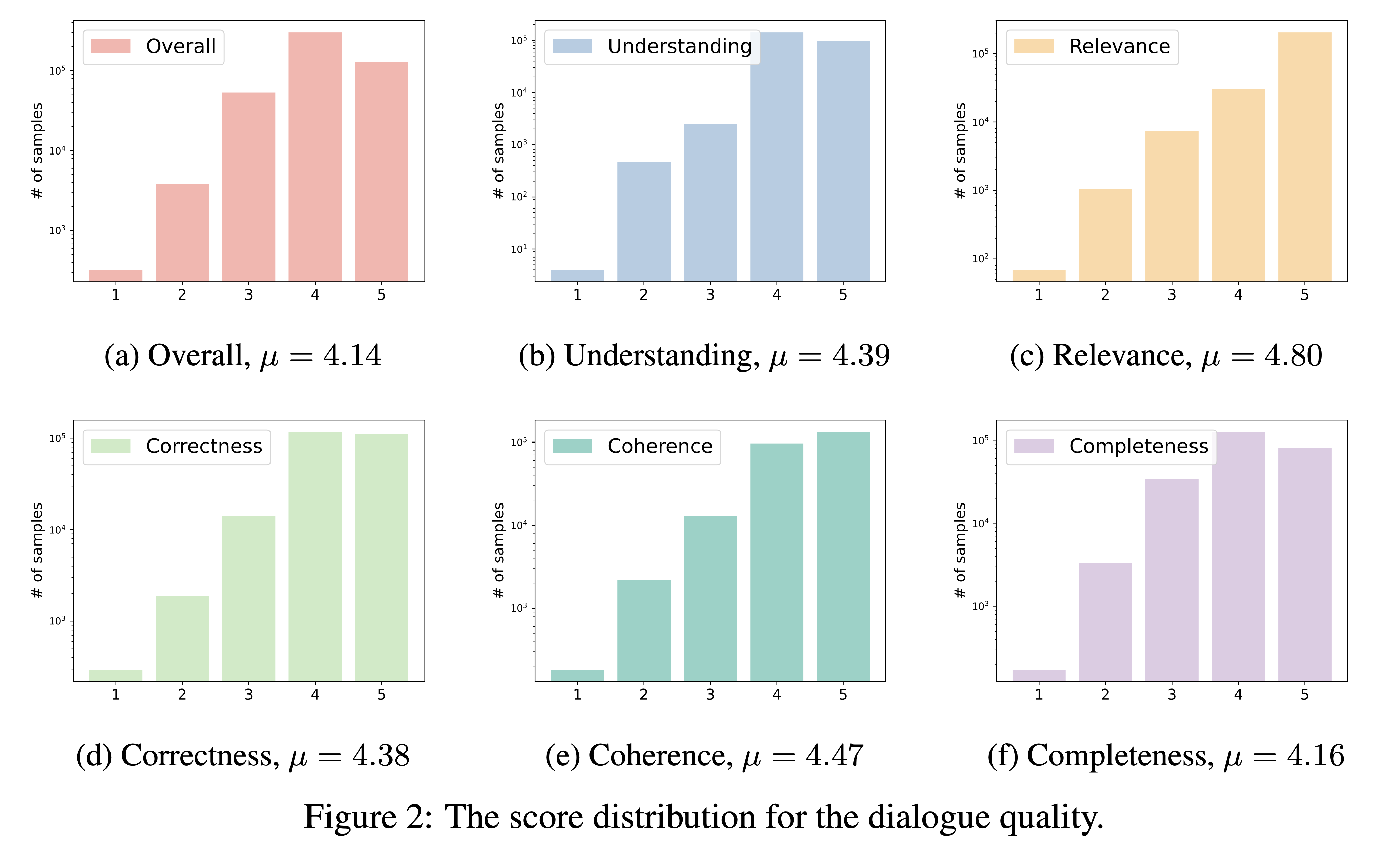
DialogStudio avalia a qualidade do diálogo com base em seis critérios críticos, nomeadamente compreensão, relevância, correção, coerência, integridade e qualidade geral. Cada critério é pontuado numa escala de 1 a 5, sendo as pontuações mais altas reservadas para diálogos excepcionais.
Dado o grande número de conjuntos de dados incorporados ao DialogStudio , utilizamos 'gpt-3.5-turbo' para avaliar 33 conjuntos de dados distintos. O script correspondente utilizado para esta avaliação pode ser acessado através do link.
Os resultados da nossa avaliação da qualidade do diálogo são apresentados abaixo. Pretendemos divulgar pontuações de avaliação para diálogos selecionados individualmente no próximo período.
Você pode carregar qualquer conjunto de dados no DialogStudio do hub HuggingFace reivindicando {dataset_name} , que é exatamente o nome da pasta do conjunto de dados. Todos os conjuntos de dados disponíveis estão descritos no conteúdo do conjunto de dados.
Abaixo está um exemplo para carregar o conjunto de dados MULTIWOZ2_2 na categoria diálogos orientados a tarefas:
Carregar o conjunto de dados
from datasets import load_dataset
dataset = load_dataset ( 'Salesforce/ DialogStudio ' , 'MULTIWOZ2_2' )Aqui está a estrutura de saída do MultiWOZ 2.2
DatasetDict ({
train : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 8437
})
validation : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 1000
})
test : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 1000
})
})Os conjuntos de dados são divididos em várias categorias neste repositório GitHub e no hub HuggingFace. Você pode verificar a tabela do conjunto de dados para obter mais informações. E você pode clicar em cada pasta para conferir alguns exemplos:
Lançamos a versão 1.0 de modelos ( DialogStudio -t5-base-v1.0, DialogStudio -t5-large-v1.0, DialogStudio -t5-3b-v1.0) treinados em alguns conjuntos de dados selecionados DialogStudio . Verifique cada cartão modelo para obter mais detalhes.
Abaixo está um exemplo de execução do modelo na CPU:
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer . from_pretrained ( "Salesforce/ DialogStudio -t5-base-v1.0" )
model = AutoModelForSeq2SeqLM . from_pretrained ( "Salesforce/ DialogStudio -t5-base-v1.0" )
input_text = "Answer the following yes/no question by reasoning step-by-step. Can you write 200 words in a single tweet?"
input_ids = tokenizer ( input_text , return_tensors = "pt" ). input_ids
outputs = model . generate ( input_ids , max_new_tokens = 256 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))Nosso projeto segue a seguinte estrutura no que diz respeito ao licenciamento:
Para obter informações detalhadas sobre licenciamento, consulte as licenças específicas que acompanham os conjuntos de dados originais. É importante familiarizar-se com estes termos, pois não assumimos responsabilidade por questões de licenciamento.
Agradecemos sinceramente a todos os autores de conjuntos de dados que contribuíram para o campo da IA conversacional. Apesar de esforços cuidadosos, podem ocorrer imprecisões em nossas citações ou referências. Se você detectar algum erro ou omissão, levante um problema ou envie uma solicitação pull para nos ajudar a melhorar. Obrigado!
Os dados e código neste repositório são desenvolvidos principalmente ou derivados do artigo abaixo. Se você utilizar conjuntos de dados do DialogStudio , solicitamos que você cite o trabalho original e o nosso próprio trabalho (aceito pelas descobertas da EACL 2024 como um artigo longo).
@article{zhang2023 DialogStudio ,
title={ DialogStudio : Towards Richest and Most Diverse Unified Dataset Collection for Conversational AI},
author={Zhang, Jianguo and Qian, Kun and Liu, Zhiwei and Heinecke, Shelby and Meng, Rui and Liu, Ye and Yu, Zhou and Savarese, Silvio and Xiong, Caiming},
journal={arXiv preprint arXiv:2307.10172},
year={2023}
}
Convidamos com entusiasmo contribuições da comunidade! Junte-se a nós em nossa missão compartilhada de impulsionar o campo da IA conversacional!


