aug pe
1.0.0
? Artigo • Dados (Yelp/OpenReview/PubMed) • Página do projeto
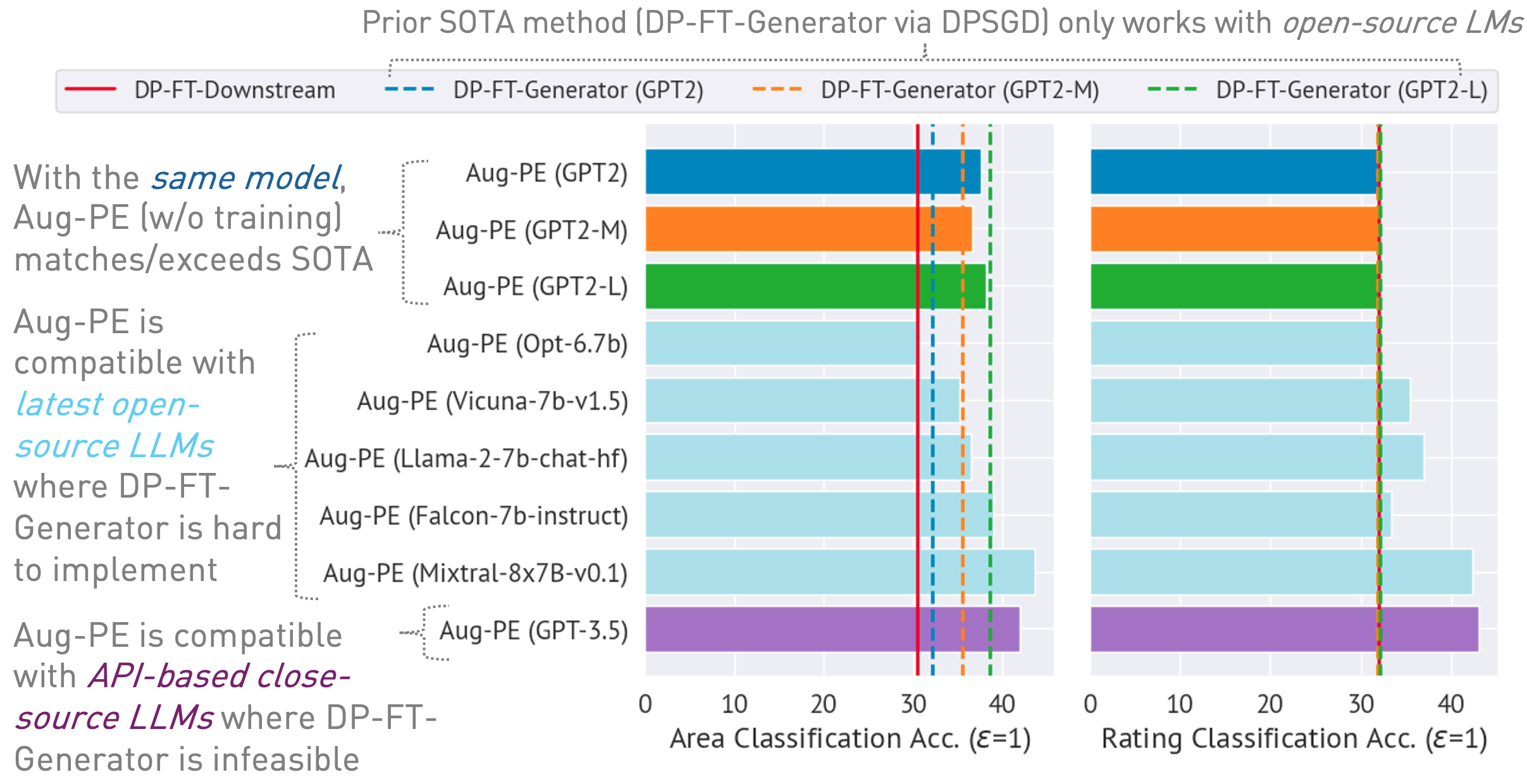
Este repositório implementa o algoritmo Augmented Private Evolution (Aug-PE), aproveitando o acesso da API de inferência a grandes modelos de linguagem (LLMs) para gerar texto sintético diferencialmente privado (DP) sem a necessidade de treinamento de modelo. Comparamos o ajuste fino de DP-SGD e Aug-PE:

Sob
03/13/2024 : Está disponível a página do projeto, que descreve o algoritmo e seus resultados.03/11/2024 : Código e papel ArXiv estão disponíveis. conda env create -f environment.yml
conda activate augpe
Os conjuntos de dados estão localizados em data/{dataset} onde dataset é yelp , openreview e pubmed .
Baixe o Yelp train.csv (1.21G) e PubMed train.csv (117 MB) neste link ou execute:
bash scripts/download_data.sh # download yelp train.csv and pubmed train.csvDescrição do conjunto de dados:
Incorporações de pré-cálculo para dados privados (linha 1 no algoritmo Aug-PE):
bash scripts/embeddings.sh --openreview # Compute private embeddings
bash scripts/embeddings.sh --pubmed
bash scripts/embeddings.sh --yelp Nota: Calcular embeddings para OpenReview e PubMed é relativamente rápido. No entanto, devido ao grande tamanho do conjunto de dados do Yelp (1,9 milhão de amostras de treinamento), o processo pode levar aproximadamente 40 minutos.
Calcule o nível de ruído DP para seu conjunto de dados em notebook/dp_budget.ipynb considerando o orçamento de privacidade
Para visualização com Wandb, configure --wandb_key e --project com sua chave e nome do projeto em dpsda/arg_utils.py .
Utilize LLMs de código aberto da Hugging Face para gerar dados sintéticos:
export CUDA_VISIBLE_DEVICES=0
bash scripts/hf/{dataset}/generate.sh # Replace `{dataset}` with yelp, openreview, or pubmedAlguns hiperparâmetros principais:
noise : ruído DP.epoch : usamos 10 épocas para configuração de DP. Para a configuração não DP, usamos 20 épocas para o Yelp e 10 épocas para outros conjuntos de dados.model_type : modelo em huggingface, como ["gpt2", "gpt2-medium", "gpt2-large", "meta-llama/Llama-2-7b-chat-hf", "tiiuae/falcon-7b-instruct" , "facebook/opt-6.7b", "lmsys/vicuna-7b-v1.5", "mistralai/Mixtral-8x7B-Instruct-v0.1"].num_seed_samples : número de amostras sintéticas.lookahead_degree : número de variações para estimativa de incorporação de amostra sintética (linha 5 no algoritmo Aug-PE). O padrão é 0 (autoincorporação).L : relacionado ao número de variações para gerar amostras sintéticas candidatas (linha 18 no algoritmo Aug-PE)feat_ext : modelo de incorporação em transformadores de frases huggingface.select_syn_mode : selecione amostras sintéticas de acordo com votos ou probabilidade do histograma. O padrão é rank (linha 19 no algoritmo Aug-PE)temperature : temperatura para geração de LLM.Ajuste o modelo downstream com texto sintético DP e avalie a precisão do modelo em dados de teste reais:
bash scripts/hf/{dataset}/downstream.sh # Finetune downstream model and evaluate performance Meça a distância de distribuição de incorporação:
bash scripts/hf/{dataset}/metric.sh # Calculate distribution distancePara um processo simplificado que combina todas as etapas de geração e avaliação:
bash scripts/hf/template/{dataset}.sh # Complete workflow for each dataset Usamos modelo de código fechado via API Azure OpenAI. Defina sua chave e endpoint em apis/azure_api.py
MODEL_CONFIG = {
'gpt-3.5-turbo' :{ "openai_api_key" : "YOUR_AZURE_OPENAI_API_KEY" ,
"openai_api_base" : "YOUR_AZURE_OPENAI_ENDPOINT" ,
"engine" : 'YOUR_DEPLOYMENT_NAME' ,
},
} Aqui engine poderia ser gpt-35-turbo no Azure.
Execute o script a seguir para gerar dados sintéticos, avaliá-los na tarefa downstream e calcular a distância de distribuição de incorporação entre dados reais e sintéticos:
bash scripts/gpt-3.5-turbo/{dataset}.shUsamos prompts relacionados ao comprimento do texto para GPT-3.5 para controlar o comprimento do texto gerado. Introduzimos vários hiperparâmetros adicionais aqui:
dynamic_len é usado para ativar o mecanismo de comprimento dinâmico.word_var_scale : variação do ruído gaussiano usada para determinar target_word.max_token_word_scale : número máximo de tokens por palavra. Definimos o max_token para geração de LLM com base em target_word (especificado no prompt) e max_token_word_scale. Use o notebook para calcular a diferença de distribuição do comprimento do texto entre dados reais e sintéticos: notebook/text_lens_distribution.ipynb
Se você achar nosso trabalho útil, considere citá-lo da seguinte forma:
@inproceedings {
xie2024differentially,
title = { Differentially Private Synthetic Data via Foundation Model {API}s 2: Text } ,
author = { Chulin Xie and Zinan Lin and Arturs Backurs and Sivakanth Gopi and Da Yu and Huseyin A Inan and Harsha Nori and Haotian Jiang and Huishuai Zhang and Yin Tat Lee and Bo Li and Sergey Yekhanin } ,
booktitle = { Forty-first International Conference on Machine Learning } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=LWD7upg1ob }
}Se você tiver alguma dúvida relacionada ao código ou ao artigo, sinta-se à vontade para enviar um e-mail para Chulin ([email protected]) ou abrir um problema.


