Study Bot
1.0.0
Study-Bot é um projeto de código aberto desenvolvido por Edumakers do Tecnológico de Monterrey . Ele foi projetado para ajudar alunos com deficiência visual a revisar o material do curso acadêmico. É um companheiro de estudo com tecnologia de IA que incorpora várias tecnologias, incluindo Whisper, GPT-3.5-turbo-16k, conversão de texto em fala Elevenlabs e OpenCV. Para fins de teste, um exemplo de material do curso foi gerado usando ChatGPT.
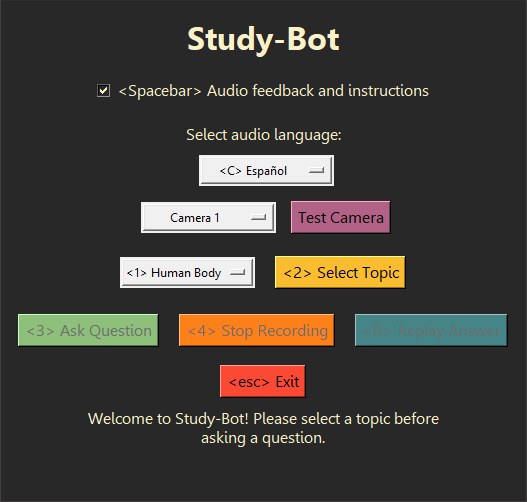
O Study-Bot pode: ouvir a pergunta do usuário, analisar o material de origem do tema que deseja estudar, detectar o material de educação física que está segurando pela cor ou marcador ArUco, gerar uma resposta e lê-la em voz alta para o usuário como um aplicativo executável acessível. Para fins de desenvolvimento e teste, ele pode ser executado através do interpretador Python como um programa CLI ou com uma GUI .
Alguns bons próximos passos poderiam ser incorporar este sistema em uma interface de usuário mais avançada para distribuição como um aplicativo de desktop, criar um modelo de visão computacional que possa detectar o material educacional físico sem depender de cores ou marcadores ArUco, bem como algumas melhorias de desempenho e novos recursos interativos.
É recomendado usar Python 3.9.9 para que a biblioteca whisper possa ser usada sem problemas. Para evitar a remoção da instalação atual do Python , você pode usar um ambiente virtual para usar esta versão específica do Python . Para instalar as dependências necessárias, execute o seguinte comando:
pip install -r requirements.txt Existem algumas etapas adicionais que precisam ser executadas antes de poder executar o projeto, como a aquisição de suas próprias chaves de API para os serviços de IA usados aqui. Para obter mais informações, consulte a pasta Documentation para obter um guia completo sobre como usar este projeto.
Study-Bot depende dos seguintes serviços e tecnologias existentes:
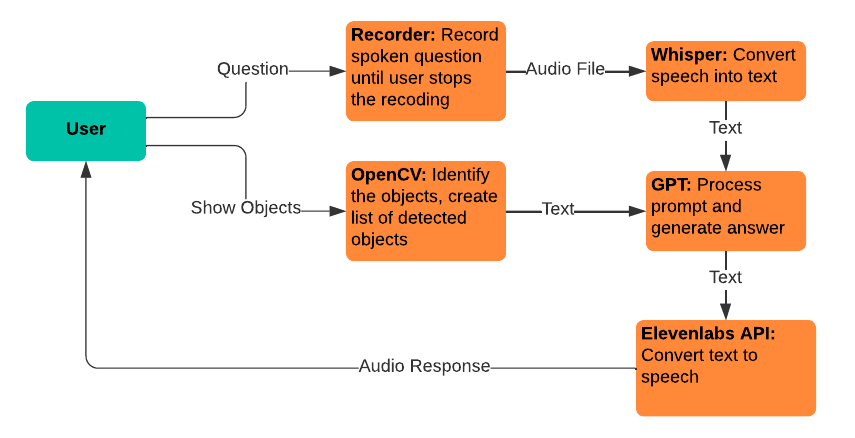
Sussurro: usado para conversão de fala em texto, permitindo que os usuários falem suas perguntas para alimentar o modelo GPT.
gpt-3.5-turbo-16k: Usado para processamento de perguntas e geração de respostas. A versão 16k do modelo foi escolhida por seu tamanho de janela de contexto de 16.385 tokens, necessário para processar uma grande quantidade de material de origem.
Conversão de texto para fala Elevenlabs: Usado para conversão de texto para fala, permitindo que os usuários ouçam as respostas geradas pelo modelo GPT.
OpenCV: Usado para identificação de objetos físicos, para auxiliar o modelo GPT-3.5-16k a responder perguntas com o contexto adicional do que o usuário está segurando.
Use este projeto como referência para você mesmo ou faça um fork para fazer suas próprias contribuições. Problemas do GitHub relacionados a solicitações de recursos e relatórios de bugs são bem-vindos e especialmente valorizados se incluirem feedback de usuários com deficiência visual.


