LLaMA LoRA Tuner
v0.0.20230421
Facilitando a avaliação e o ajuste fino de modelos LLaMA com adaptação de baixa classificação (LoRA).
Atualizar :
No ramo
dev, há uma nova interface de bate-papo e uma nova configuração do modo de demonstração como uma maneira simples e fácil de demonstrar novos modelos.Porém, a nova versão ainda não possui o recurso de ajuste fino e não é compatível com versões anteriores, pois utiliza uma nova forma de definir como os modelos são carregados, e também um novo formato de modelos de prompt (do LangChain).
Para mais informações, consulte: #28.
LLM.Tuner.Chat.UI.in.Demo.Mode.mp4
Veja uma demonstração no Hugging Face * Serve apenas para demonstração da interface do usuário. Para tentar treinamento ou geração de texto, execute no Colab.
Instalado e funcionando com 1 clique no Google Colab com tempo de execução de GPU padrão.
Carrega e armazena dados no Google Drive.
Avalie vários modelos de LLaMA LoRA armazenados em sua pasta ou no Hugging Face. 
Alterne entre modelos básicos, como decapoda-research/llama-7b-hf , nomic-ai/gpt4all-j , databricks/dolly-v2-7b , EleutherAI/gpt-j-6b ou EleutherAI/pythia-6.9b .
Ajuste modelos LLaMA com diferentes modelos de prompt e formato de conjunto de dados de treinamento. 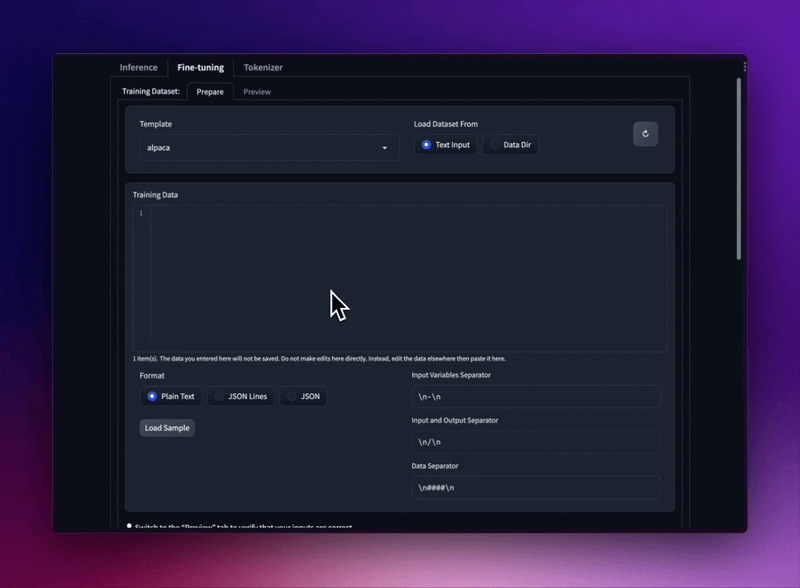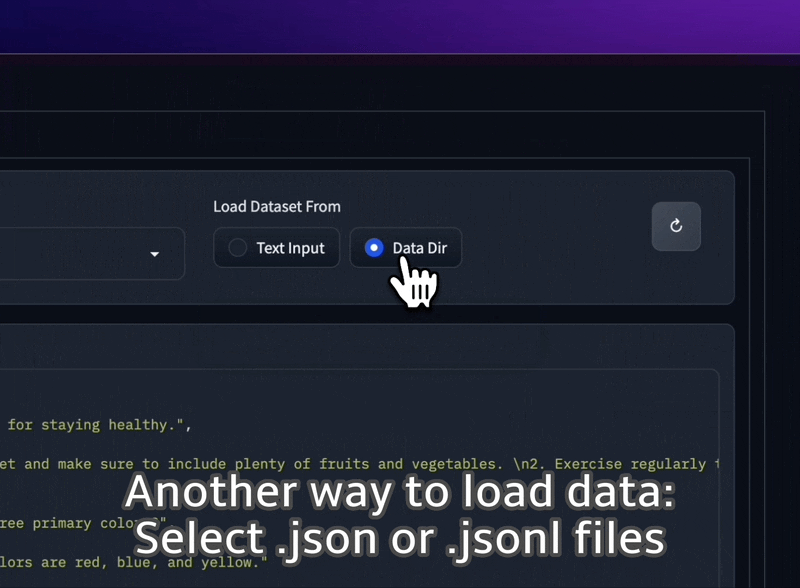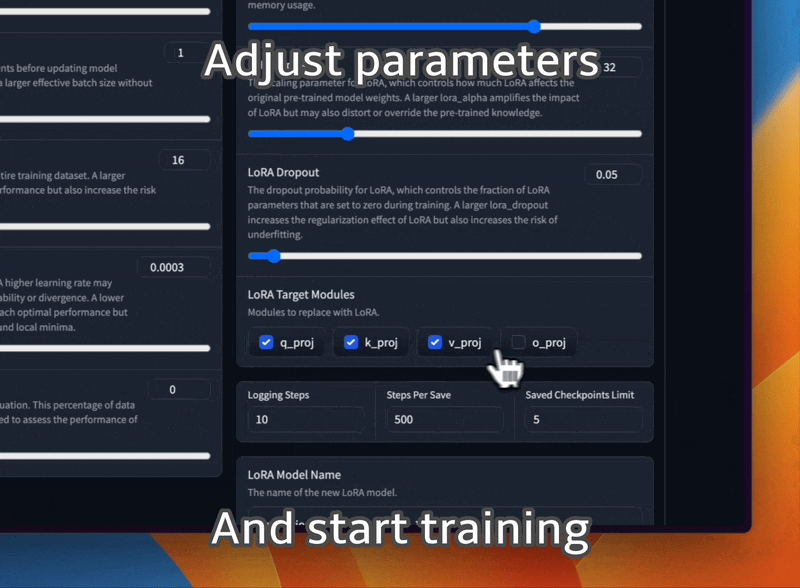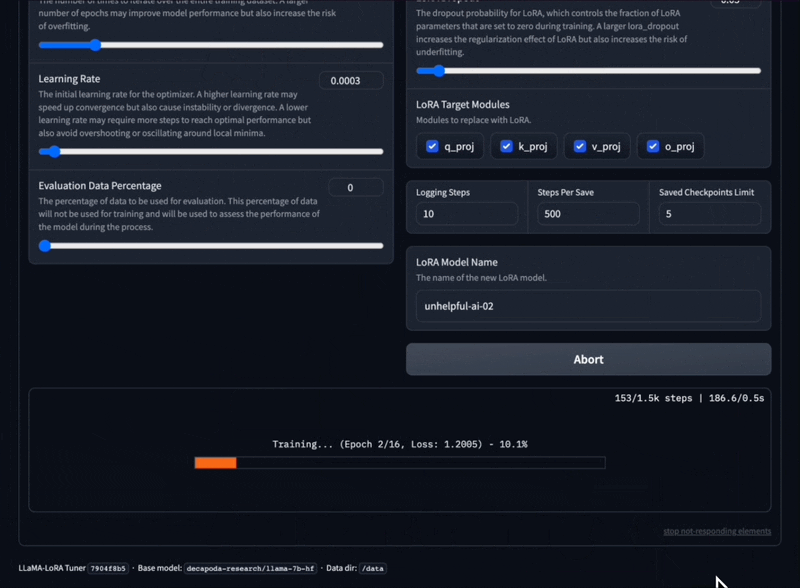
Carregue conjuntos de dados JSON e JSONL de sua pasta ou cole texto simples diretamente na IU.
Suporta o formato Stanford Alpaca seed_tasks, alpaca_data e OpenAI "prompt"-"conclusão".
Use modelos de prompt para manter seu conjunto de dados SECO.
Existem várias maneiras de executar este aplicativo:
Execute no Google Colab : A maneira mais simples de começar, tudo que você precisa é de uma conta do Google. O tempo de execução da GPU padrão (gratuito) é suficiente para executar a geração e o treinamento com tamanho de microlote de 8. No entanto, a geração e o treinamento de texto são muito mais lentos do que em outros serviços em nuvem, e o Colab pode encerrar a execução por inatividade durante a execução de tarefas longas.
Execute em um serviço de nuvem via SkyPilot : se você tiver uma conta de serviço de nuvem (Lambda Labs, GCP, AWS ou Azure), poderá usar o SkyPilot para executar o aplicativo em um serviço de nuvem. Um bucket de nuvem pode ser montado para preservar seus dados.
Execute localmente : depende do hardware que você possui.
Veja o vídeo para obter instruções passo a passo.
Abra este Colab Notebook e selecione Runtime > Run All ( ⌘/Ctrl+F9 ).
Você será solicitado a autorizar o acesso ao Google Drive, pois o Google Drive será usado para armazenar seus dados. Consulte a seção "Config"/"Google Drive" para configurações e mais informações.
Após aproximadamente 5 minutos de execução, você verá o URL público na saída da seção "Launch"/"Start Gradio UI" (como Running on public URL: https://xxxx.gradio.live ). Abra o URL em seu navegador para usar o aplicativo.
Após seguir o guia de instalação do SkyPilot, crie um .yaml para definir uma tarefa para execução do aplicativo:
# llm-tuner.yamlresources: aceleradores: A10:1 # 1x GPU NVIDIA A10, cerca de US$ 0,6/h em Lambda Cloud. Execute `sky show-gpus` para tipos de GPU suportados e `sky show-gpus [GPU_NAME]` para obter informações detalhadas de um tipo de GPU.
nuvem: lambda # Opcional; se deixado de fora, o SkyPilot escolherá automaticamente o cloud.file_mounts mais barato: # Monte um armazenamento em nuvem presistido que será usado como diretório de dados.
# (para armazenar modelos treinados de conjuntos de dados de treinamento)
# Consulte https://skypilot.readthedocs.io/en/latest/reference/storage.html para obter detalhes.
/data:name: llm-tuner-data # Certifique-se de que este nome seja exclusivo ou que você seja o proprietário deste bucket. Se não existir, o SkyPilot tentará criar um bucket com este nome.store: s3 # Pode ser um dos modos [s3, gcs]: MOUNT# Clone o repositório LLaMA-LoRA Tuner e instale suas dependências.setup: | conda create -q python=3.8 -n llm-tuner -y conda activate llm-tuner # Clone o repositório LLaMA-LoRA Tuner e instale suas dependências [ ! -d llm_tuner] && git clone https://github.com/zetavg/LLaMA-LoRA-Tuner.git llm_tuner echo 'Instalando dependências...' pip install -r llm_tuner/requirements.lock.txt # Opcional: instale wandb para habilite o registro em pesos e preconceitos pip install wandb # Opcional: corrija bitsandbytes para solucionar o erro "libbitsandbytes_cpu.so: símbolo indefinido: cget_col_row_stats" BITSANDBYTES_LOCATION="$(pip show bitsandbytes | grep 'Location' | awk '{print $2}')/bitsandbytes" [ -f "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so" ] && [ ! -f "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so.bak" ] && [ -f "$BITSANDBYTES_LOCATION/libbitsandbytes_cuda121.so" ] && echo 'Corrigindo bitsandbytes para suporte de GPU...' && mv "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so" "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so.bak" && cp "$BITSANDBYTES_LOCATION/libbitsandbytes_cuda121.so" "$BITSANDBYTES_LOCATION/libbitsandbytes_cpu.so" conda install -q cudatoolkit -y echo 'Dependências instaladas.' # Opcional: instale e configure o Cloudflare Tunnel para expor o aplicativo à Internet com um nome de domínio personalizado [ -f /data/secrets/cloudflared_tunnel_token.txt ] && echo "Installing Cloudflare" && curl -L --output cloudflared.deb https: //github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64.deb && sudo dpkg -i cloudflared.deb && sudo desinstalação do serviço cloudflared || : && sudo cloudflared service install "$(cat /data/secrets/cloudflared_tunnel_token.txt | tr -d 'n')" # Opcional: modelos de pré-download echo "Pré-download de modelos básicos para que você não precise esperar por muito tempo quando o aplicativo estiver pronto..." python llm_tuner/download_base_model.py --base_model_names='decapoda-research/llama-7b-hf,nomic-ai/gpt4all-j'# Inicie o aplicativo. `hf_access_token`, `wandb_api_key` e `wandb_project` são opcionais.run: | conda ativar llm-tuner python llm_tuner/app.py --data_dir='/data' --hf_access_token="$([ -f /data/secrets/hf_access_token.txt ] && cat /data/secrets/hf_access_token.txt | tr -d 'n')" --wandb_api_key="$([ -f /data/secrets/wandb_api_key.txt ] && cat /data/secrets/wandb_api_key.txt | tr -d 'n')" --wandb_project='llm-tuner' --timezone='Atlantic/Reykjavik' --base_model='decapoda-research/llama-7b -hf' --base_model_choices='decapoda-research/llama-7b-hf,nomic-ai/gpt4all-j,databricks/dolly-v2-7b' --shareEm seguida, inicie um cluster para executar a tarefa:
sky launch -c llm-tuner llm-tuner.yaml
-c ... é um sinalizador opcional para especificar um nome de cluster. Se não for especificado, o SkyPilot irá gerar um automaticamente.
Você verá o URL público do aplicativo no terminal. Abra o URL em seu navegador para usar o aplicativo.
Observe que sair sky launch sairá apenas do streaming de log e não interromperá a tarefa. Você pode usar sky queue --skip-finished para ver o status de tarefas em execução ou pendentes, sky logs <cluster_name> <job_id> conectar-se novamente ao streaming de log e sky cancel <cluster_name> <job_id> para interromper uma tarefa.
Quando terminar, execute sky stop <cluster_name> para interromper o cluster. Para encerrar um cluster, execute sky down <cluster_name> .
Lembre-se de parar ou desligar o cluster quando terminar para evitar cobranças inesperadas. Execute sky cost-report para ver o custo dos seus clusters.
Para fazer login na máquina em nuvem, execute ssh <cluster_name> , como ssh llm-tuner .
Se você tiver sshfs instalado em sua máquina local, poderá montar o sistema de arquivos da máquina em nuvem em seu computador local executando um comando como o seguinte:
mkdir -p /tmp/llm_tuner_server && umount /tmp/llm_tuner_server || : && sshfs llm-tuner:/ /tmp/llm_tuner_server
conda create -y python=3.8 -n llm-tuner conda ativa o sintonizador llm
pip instalar -r requisitos.lock.txt python app.py --data_dir='./data' --base_model='decapoda-research/llama-7b-hf' --timezone='Atlântico/Reykjavik' --share
Você verá os URLs locais e públicos do aplicativo no terminal. Abra o URL em seu navegador para usar o aplicativo.
Para obter mais opções, consulte python app.py --help .
Para testar a UI sem carregar o modelo de linguagem, use o sinalizador --ui_dev_mode :
python app.py --data_dir='./data' --base_model='decapoda-research/llama-7b-hf' --share --ui_dev_mode
Para usar o Gradio Auto-Reloading, um arquivo
config.yamlé necessário, pois os argumentos da linha de comando não são suportados. Há um arquivo de exemplo para começar:cp config.yaml.sample config.yaml. Depois, basta executargradio app.py.
Veja o vídeo no YouTube.
https://github.com/tloen/alpaca-lora
https://github.com/lxe/simple-llama-finetuner
...
A confirmar


