Projeto de geração aumentada de recuperação (RAG)
If this project helps you, consider buying me a coffee ☕. Your support helps me keep contributing to the open-source community!
A plataforma oficial da BRAGAI será lançada em breve. Entre na lista de espera para ser um dos primeiros a adotar!
Este repositório contém uma exploração abrangente de Retrieval-Augmented Generation (RAG) para vários aplicativos. Cada notebook fornece um guia prático e detalhado para configurar e experimentar o RAG, desde um nível introdutório até implementações avançadas, incluindo consultas múltiplas e construções RAG personalizadas.
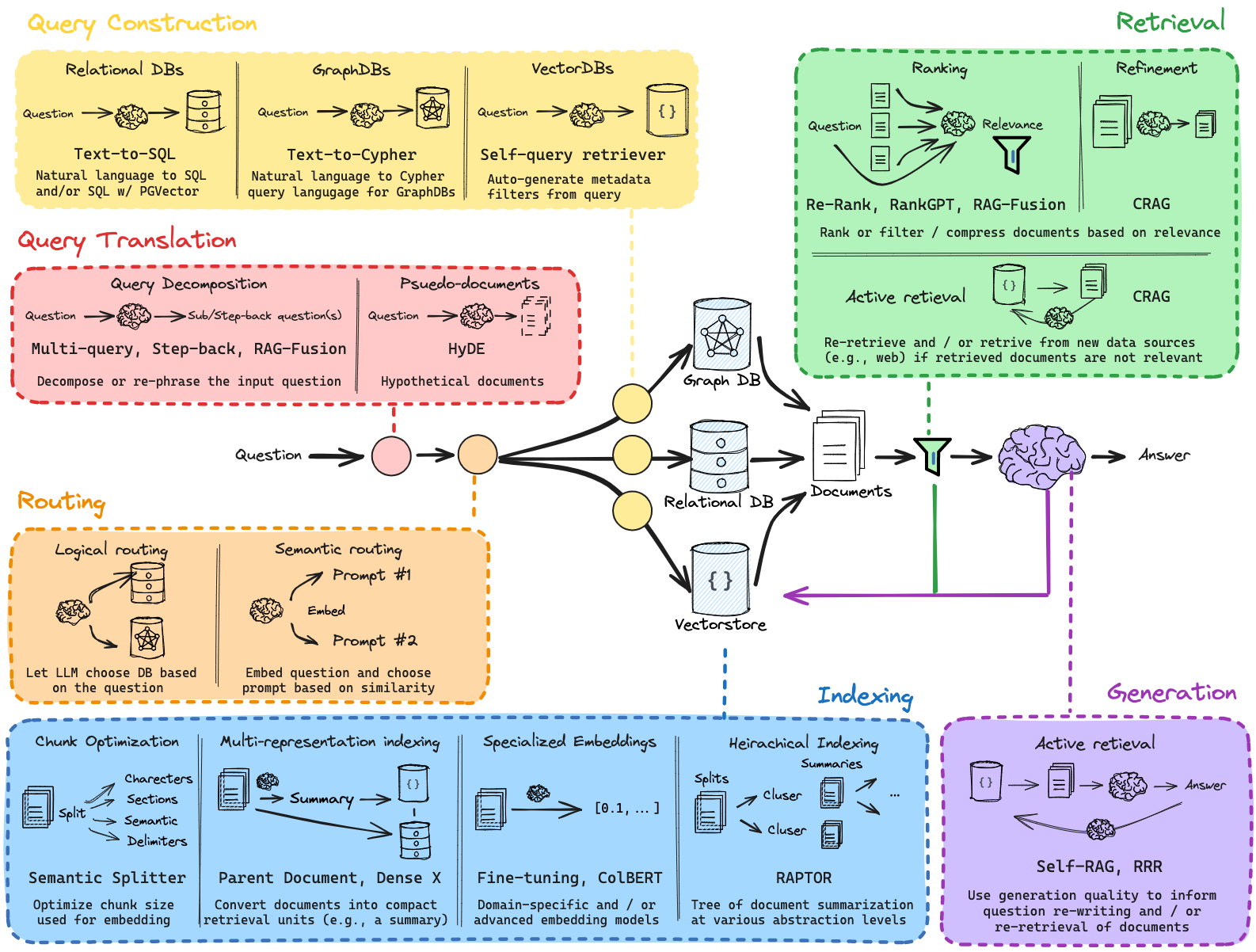
Estrutura do Projeto
Se você quiser ir direto para ele, verifique o arquivo full_basic_rag.ipynb -> este arquivo fornecerá um código inicial padrão de um chatbot RAG totalmente personalizável.
Certifique-se de executar seus arquivos em um ambiente virtual (seção de checkout Get Started )
Os seguintes notebooks podem ser encontrados no diretório tutorial_notebooks/ .
[1]_rag_setup_overview.ipynb
Este caderno introdutório fornece uma visão geral da arquitetura RAG e sua configuração básica. O caderno percorre:
- Configuração do ambiente : configuração do ambiente, instalação de bibliotecas necessárias e configurações de API.
- Carregamento inicial de dados : carregadores básicos de documentos e métodos de pré-processamento de dados.
- Geração de incorporação : geração de embeddings usando vários modelos, incluindo embeddings da OpenAI.
- Armazenamento de vetores : Configurando um armazenamento de vetores (ChromaDB/Pinecone) para pesquisa eficiente de similaridade.
- Pipeline RAG básico : criação de um pipeline simples de recuperação e geração para servir como linha de base.
[2]_rag_with_multi_query.ipynb
Com base no básico, este notebook apresenta técnicas de multiconsulta no pipeline RAG, explorando:
- Configuração de múltiplas consultas : configuração de múltiplas consultas para diversificar a recuperação.
- Técnicas avançadas de incorporação : utilização de vários modelos de incorporação para refinar a recuperação.
- Pipeline com Multi-Querying : Implementando o tratamento de múltiplas consultas para melhorar a relevância na geração de respostas.
- Comparação e análise : comparação de resultados com pipelines de consulta única e análise de melhorias de desempenho.
[3]_rag_routing_and_query_construction.ipynb
Este notebook se aprofunda na personalização de um pipeline RAG. Abrange:
- Roteamento lógico: implementa roteamento baseado em função para classificar consultas de usuários em fontes de dados apropriadas com base em linguagens de programação.
- Roteamento semântico: usa incorporações e similaridade de cosseno para direcionar perguntas para um prompt de matemática ou física, otimizando a precisão da resposta.
- Estruturação de consulta para filtros de metadados: define esquema de pesquisa estruturado para metadados de tutoriais do YouTube, permitindo filtragem avançada (por exemplo, por contagem de visualizações, data de publicação).
- Solicitação de pesquisa estruturada: aproveita as solicitações do LLM para gerar consultas de banco de dados para recuperar conteúdo relevante com base na entrada do usuário.
- Integração com armazenamentos de vetores: vincula consultas estruturadas a armazenamentos de vetores para recuperação eficiente de dados.
[4]_rag_indexing_and_advanced_retrieval.ipynb
Continuando com a personalização anterior, este notebook explora:
- Prefácio sobre fragmentação de documentos: aponta para recursos externos para técnicas de fragmentação de documentos.
- Indexação multi-representação: configura uma estrutura de indexação multivetorial para lidar com documentos com diferentes incorporações e representações.
- Armazenamento na memória para resumos: usa InMemoryByteStore para armazenar resumos de documentos junto com documentos pai, permitindo recuperação eficiente.
- Configuração do MultiVectorRetriever: Integra múltiplas representações vetoriais para recuperar documentos relevantes com base nas consultas do usuário.
- Implementação RAPTOR: explora o RAPTOR, um modelo avançado de indexação e recuperação, vinculado a recursos detalhados.
- Integração ColBERT: demonstra indexação e recuperação de vetor em nível de token baseado em ColBERT, que captura o significado contextual em um nível refinado.
- Exemplo da Wikipedia com ColBERT: recupera informações sobre Hayao Miyazaki usando o modelo de recuperação ColBERT para demonstração.
[5]_rag_retrieval_and_reranking.ipynb
Este notebook final reúne os componentes do sistema RAG, com foco em escalabilidade e otimização:
- Carregamento e divisão de documentos: carrega e agrupa documentos para indexação, preparando-os para armazenamento vetorial.
- Geração de múltiplas consultas com RAG-Fusion: usa uma abordagem baseada em prompt para gerar diversas consultas de pesquisa a partir de uma única pergunta de entrada.
- Fusão de classificação recíproca (RRF): implementa RRF para reclassificar várias listas de recuperação, mesclando resultados para melhorar a relevância.
- Configuração da cadeia de recuperação e RAG: constrói uma cadeia de recuperação para responder a consultas, usando classificações fundidas e cadeias RAG para extrair informações contextualmente relevantes.
- Reclassificação de Cohere: demonstra a reclassificação com o modelo de Cohere para compactação e refinamento contextual adicionais.
- Recuperação CRAG e Self-RAG: explora abordagens de recuperação avançadas como CRAG e Self-RAG, com links para exemplos.
- Exploração do impacto de contexto longo: Links para recursos que explicam o impacto da recuperação de contexto longo em modelos RAG.
Começando
Pré-requisitos: Python 3.11.7 (preferencial)
Clone o repositório :
git clone https://github.com/bRAGAI/bRAG-langchain.git
cd bRAG-langchain
Crie um ambiente virtual
python -m venv venv
source venv/bin/activate
Instalar dependências : certifique-se de instalar os pacotes necessários listados em requirements.txt .
pip install -r requirements.txt
Execute os notebooks : comece com [1]_rag_setup_overview.ipynb para se familiarizar com o processo de configuração. Prossiga sequencialmente pelos outros notebooks para construir e experimentar conceitos RAG mais avançados.
Configurar variáveis de ambiente :
Ordem do Caderno : Para acompanhar o projeto de forma estruturada:
Comece com [1]_rag_setup_overview.ipynb
Prossiga com [2]_rag_with_multi_query.ipynb
Em seguida, passe por [3]_rag_routing_and_query_construction.ipynb
Continue com [4]_rag_indexing_and_advanced_retrieval.ipynb
Termine com [5]_rag_retrieval_and_reranking.ipynb
Uso
Após configurar o ambiente e executar os notebooks em sequência, você poderá:
Experimente com geração aumentada de recuperação : use a configuração básica em [1]_rag_setup_overview.ipynb para entender os fundamentos do RAG.
Implementar multiconsulta : aprenda como melhorar a relevância da resposta introduzindo técnicas de multiconsulta em [2]_rag_with_multi_query.ipynb .
Cadernos recebidos (trabalho em andamento)
- Precisão de contexto com RAGAS + LangSmith
- Guia sobre como usar RAGAS e LangSmith para avaliar a precisão do contexto, relevância e precisão de resposta no RAG.
- Implantando aplicativo RAG
- Guia sobre como implantar seu aplicativo RAG
The notebooks and visual diagrams were inspired by Lance Martin's LangChain Tutorial.


