Cronograma de ChatGPT, GenerativeAI e LLMs
Este repositório organiza uma linha do tempo dos principais eventos (produtos, serviços, artigos, GitHub, postagens de blog e notícias) que ocorreram antes e depois do anúncio do ChatGPT.
Ele está selecionando uma variedade de informações nesta linha do tempo, com foco particular em LLM e IA generativa.
Talvez seja uma cena da história mais quente, então pensei que seria importante guardar bem essas lembranças, então organizei-as.
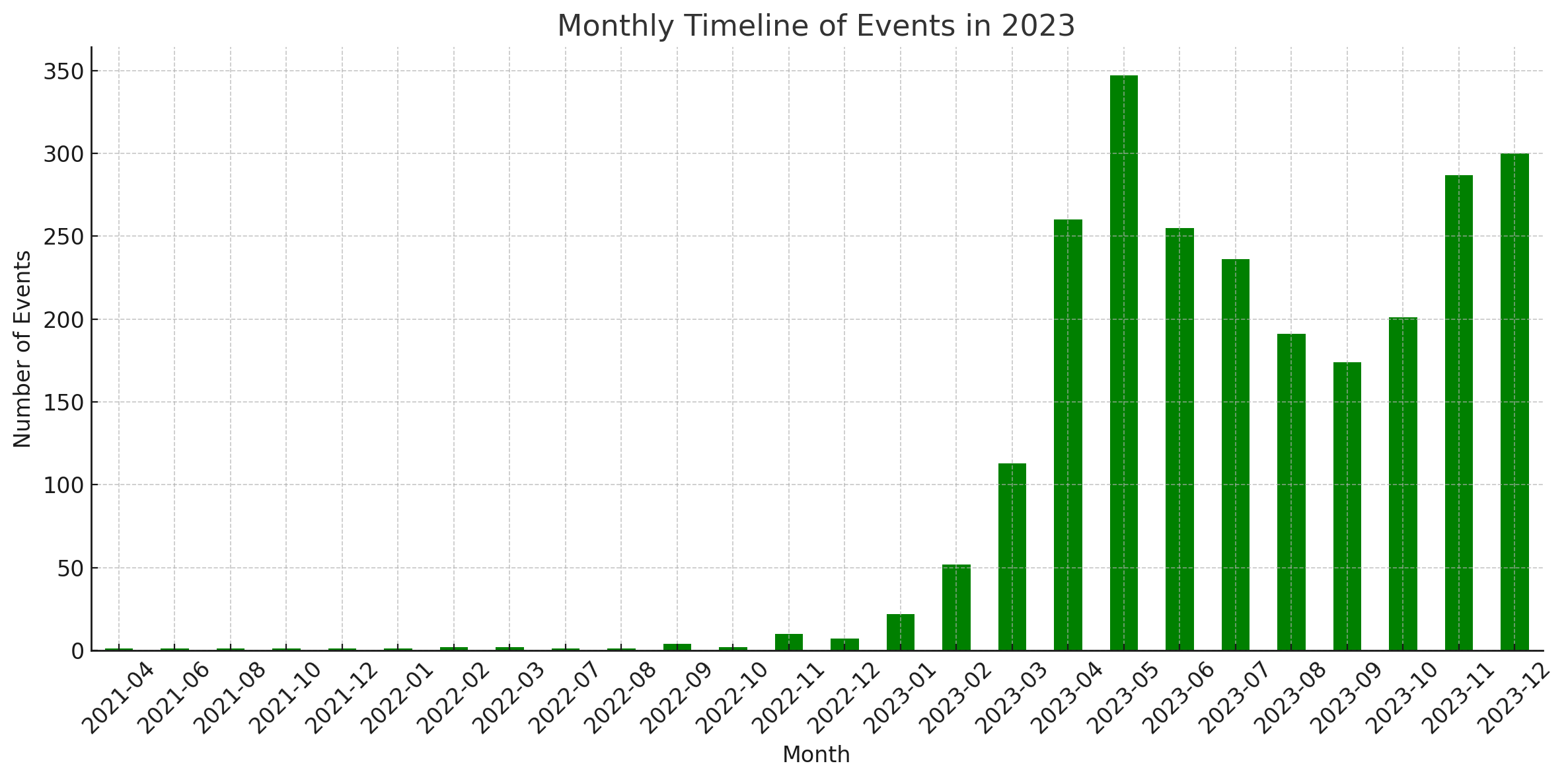
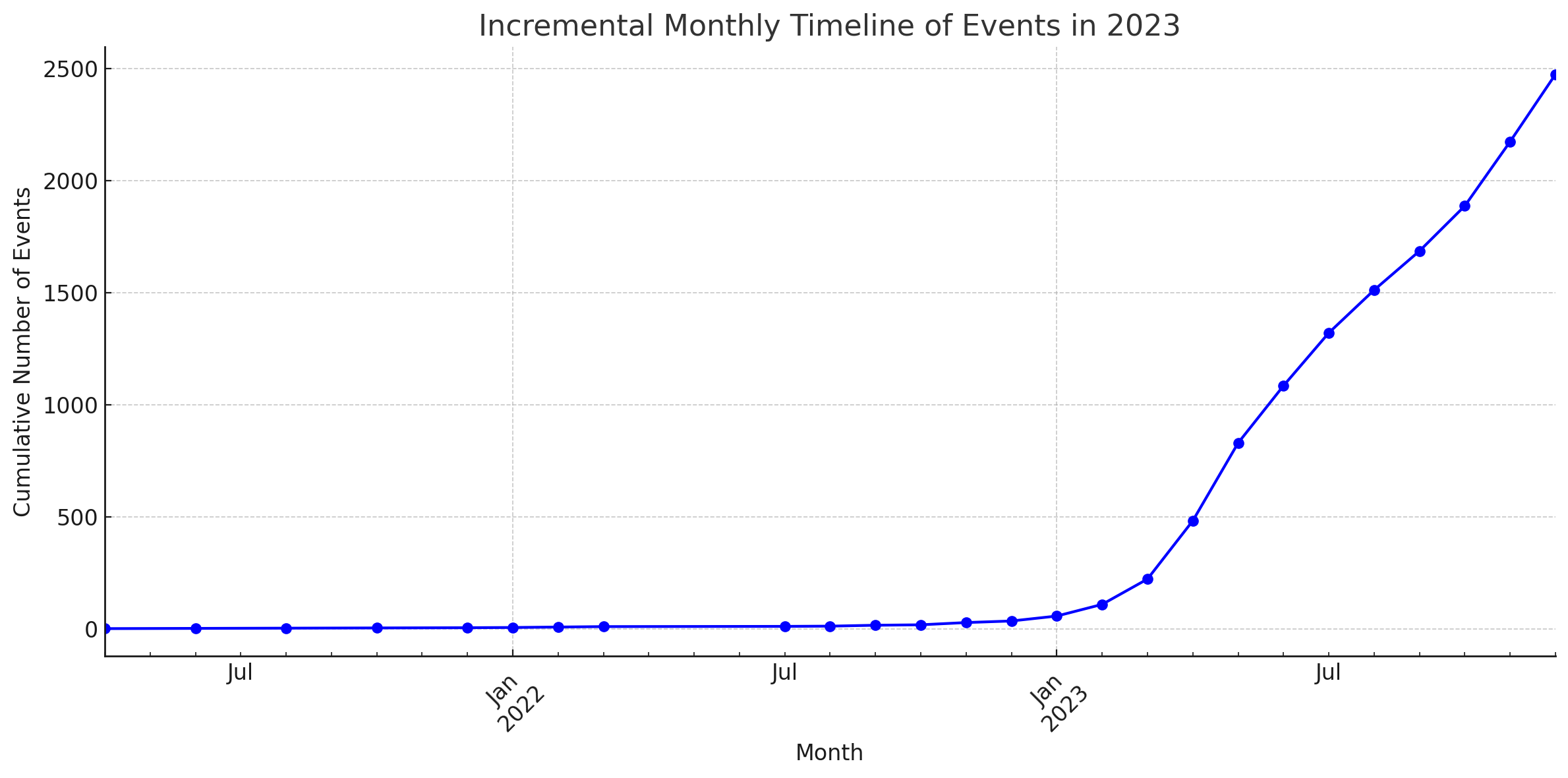
Estatísticas
Esses diagramas foram gerados pelo Code Interpreter do ChatGPT.
Contribuindo
Problemas e solicitações pull são muito apreciados. Se você nunca contribuiu para um projeto de código aberto antes, ficarei mais do que feliz em orientá-lo sobre como criar uma solicitação pull.
Você pode começar abrindo um problema descrevendo o problema que deseja resolver e prosseguiremos a partir daí.
Emoji
arXiv, PDF?, arxiv-vanity?, página de papel?, artigos com código ✳️, Github
Licença
Este documento está licenciado sob a licença MIT © Jonghong Jeon(전종홍)
Linha do tempo V2
2024
- 17/05 - OpenAI fecha acordo com Reddit para treinar sua IA em suas postagens
(Notícias), - 17/05 - OpenAI dissolve equipe focada em riscos de IA de longo prazo, menos de um ano após anunciá-lo
(Notícias), - 17/05 - Relatório Científico Internacional sobre a Segurança da IA Avançada
(Blogue), - 16/05 - TRANSIC: Transferência de política Sim-to-Real aprendendo com correção on-line
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16/05 - Toon3D: Vendo desenhos animados de uma nova perspectiva
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16/05 - Testando a confiabilidade de um modelo de grande linguagem baseado em IA para extrair informações ecológicas da literatura científica
(Notícias), - 16/05 - Aprendizagem In-Context Many-Shot em Modelos Fundamentais Multimodais
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16/05 - Como fazer uma pausa na IA antes que seja tarde demais
(Notícias), - 16/05 - Aterramento DINO 1.5: Avançar a "borda" da detecção de objetos em conjunto aberto
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16/05 - Mineração e Análise da Loja GPT
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16/05 - Dual3D: geração eficiente e consistente de texto para 3D com difusão latente multivisualização de modo duplo
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16/05 - Chameleon: Modelos de Fundação Early-Fusion Modal Misto
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16/05 - CAT3D: Crie qualquer coisa em 3D com modelos de difusão multivisualização
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 15/05 - Xmodel-VLM: uma linha de base simples para modelo de linguagem de visão multimodal
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 15/05 - LoRA aprende menos e esquece menos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 15/05 - A marca d’água invisível de IA do Google ajudará a identificar textos e vídeos geradores
(Notícias), - 15/05 – Google I/O 2024: tudo anunciado
(Blogue), - 15/05 - BEHAVIOR Vision Suite: geração de conjunto de dados customizáveis via simulação
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 15/05 - ALPINE: Revelando a Capacidade de Planejamento da Aprendizagem Autoregressiva em Modelos de Linguagem
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14/05 - Entendendo a lacuna de desempenho entre algoritmos de alinhamento online e offline
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14/05 - SpeechVerse: um modelo de linguagem de áudio generalizável em larga escala
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14/05 - SpeechGuard: Explorando a robustez adversária de modelos multimodais de grandes linguagens
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14/05 - Não há tempo a perder: aproveite o tempo no canal para entender o vídeo móvel
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14/05 - Hunyuan-DiT: um poderoso transformador de difusão multi-resolução com compreensão refinada do chinês
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14/05 - Geração composicional de texto para imagem com representações de blob denso
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14/05 - Além das leis de escala: entendendo o desempenho do transformador com memória associativa
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 13/05 - SambaNova SN40L: Dimensionando a parede de memória de IA com fluxo de dados e composição de especialistas
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 13/05 - Fluxo de trabalho RLHF: da modelagem de recompensas ao RLHF online
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 13/05 - Plot2Code: uma referência abrangente para avaliação de modelos multimodais de grandes linguagens na geração de código a partir de gráficos científicos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 13/05 - OpenAI revela o mais novo modelo de IA, GPT-4o
(Notícias), - 13/05 - MS MARCO Web Search: um conjunto de dados da Web em grande escala e rico em informações com milhões de rótulos de cliques reais
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 13/05 - Quanta pesquisa está sendo escrita por grandes modelos de linguagem?
(Blogue), - 13/05 - Olá GPT-4o
(Blogue), - 13/05 - Coin3D: Geração de ativos 3D controláveis e interativos com condicionamento guiado por proxy
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 11/05 - Piccolo2: Incorporação de texto geral com treinamento de perda híbrida multitarefa
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 11/05 - LogoMotion: geração de código visualmente fundamentado para animação com reconhecimento de conteúdo
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 10/05 - INSPECT - Uma estrutura de código aberto para avaliações de grandes modelos de linguagem
(Blogue), - 10/05 - AI Safety Institute lança nova plataforma de avaliações de segurança de IA
(Notícias), - 07/05 - SUTRA: Arquitetura de Modelo de Linguagem Multilíngue Escalável
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 07/05 - Meta lança Llama 3 Open Source LLM
(Notícias), - 03/05 - O que importa na construção de modelos de linguagem de visão?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 02/05 - WildChat: 1 milhão de registros de interação ChatGPT disponíveis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 02/05 - StoryDiffusion: Autoatenção consistente para geração de imagens e vídeos de longo alcance
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 02/05 - Prometheus 2: Um modelo de linguagem de código aberto especializado na avaliação de outros modelos de linguagem
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 02/05 - NeMo-Aligner: Kit de ferramentas escalável para alinhamento eficiente de modelos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 02/05 - LLM-AD: Sistema de descrição de áudio baseado em modelo de linguagem grande
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 02/05 - FLAME: Alinhamento sensível à factualidade para grandes modelos de linguagem
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 02/05 - Personalização de modelos de texto para imagem com um único par de imagens
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 01/05 - Campos Gaussianos Podados Espectralmente com Compensação Neural
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 01/05 - Otimização de preferência de reprodução automática para alinhamento de modelo de idioma
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 01/05 - Maior tamanho do lote de edição é sempre melhor? -- Um estudo empírico sobre edição de modelos com Llama-3
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 01/05 - Clover: Decodificação especulativa leve e regressiva com conhecimento sequencial
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 01/05 - Um exame cuidadoso do desempenho de grandes modelos de linguagem na aritmética do ensino fundamental
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - Verificador visual de fatos: possibilitando a geração de legendas detalhadas de alta fidelidade
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - STT: Monitoramento de estado com transformadores para direção autônoma
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - SemantiCodec: um codec de áudio semântico com taxa de bits ultrabaixa para som geral
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - Octopus v4: Gráfico de modelos de linguagem
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - MotionLCM: Geração de movimento controlável em tempo real via modelo de consistência latente
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - MicroDreamer: geração 3D de tiro zero em sim20 segundos por reconstrução iterativa baseada em pontuação
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - Lightplane: Componentes Altamente Escaláveis para Campos Neurais 3D
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - KAN: Redes Kolmogorov-Arnold
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - Otimização de preferências de raciocínio iterativo
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - Ponto Invisível: Gerando Cenas 3D Suaves com Pintura em Profundidade
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - InstantFamily: Atenção Mascarada para Geração de Imagens Multi-ID Zero-shot
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - GS-LRM: Grande Modelo de Reconstrução para Respingos Gaussianos 3D
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - Estendendo o contexto do Llama-3 dez vezes durante a noite
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - DOCCI: Descrições de imagens conectadas e contrastantes
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30/04 - Modelos de linguagem grande melhores e mais rápidos por meio de previsão de vários tokens
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29/04 - Caneta: Seleção Automática de Adaptador para Modelos de Difusão
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29/04 - SAGS: Respingos gaussianos 3D com reconhecimento de estrutura
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29/04 - Substituindo Juízes por Júris: Avaliando Gerações LLM com um Painel de Modelos Diversos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29/04 - Perfil de IA generativa NIST AI RMF
(Notícias), - 29/04 - LoRA Land: 310 LLMs ajustados que rivalizam com GPT-4, um relatório técnico
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29/04 - Canguru: Decodificação autoespeculativa sem perdas via saída dupla antecipada
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29/04 - Capacidades dos Modelos Gêmeos na Medicina
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 28/04 - Paint by Inpaint: Aprendendo a adicionar objetos de imagem removendo-os primeiro
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 28/04 - LEGENT: Plataforma Aberta para Agentes Corporativos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 27/04 - Ag2Manip: Aprendendo novas habilidades de manipulação com representações visuais e de ação independentes de agente
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 26/04 - MaPa: Pintura de material fotorrealista baseada em texto para formas 3D
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 26/04 - BlenderAlchemy: Edição de Gráficos 3D com Modelos de Linguagem de Visão
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - Relatório Técnico Tele-FLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - SEED-Bench-2-Plus: Benchmarking de modelos multimodais de grandes linguagens com compreensão visual rica em texto
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - Revisitando a avaliação de texto para imagem com Gecko: sobre métricas, prompts e classificações humanas
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - PLLaVA: extensão LLaVA sem parâmetros de imagens para vídeos para legendas densas de vídeo
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - Faça seu LLM utilizar totalmente o contexto
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - Liste os itens um por um: uma nova fonte de dados e paradigma de aprendizagem para LLMs multimodais
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - Pular camada: habilitando inferência de saída antecipada e decodificação autoespeculativa
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - Interactive3D: Crie o que você deseja com a Interactive 3D Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - Quão longe estamos do GPT-4V? Fechando a lacuna para modelos multimodais comerciais com suítes de código aberto
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25/04 - ConsistentID: geração de retrato com preservação multimodal de identidade refinada
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - XC-Cache: Atendimento cruzado ao contexto em cache para inferência LLM eficiente
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - A Ética dos Assistentes Avançados de IA
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - PuLID: Personalização Pure e Lightning ID via Contrastive Alignment
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - NeRF-XL: Dimensionando NeRFs com múltiplas GPUs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - MotionMaster: transferência de movimento de câmera sem treinamento para geração de vídeo
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - MoDE: CLIP Data Experts via Clustering
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - MMT-Bench: um benchmark multimodal abrangente para avaliar grandes modelos de visão-linguagem em direção a AGI multitarefa
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - MaGGIe: Esteira de Instância Humana Gradual Guiada Mascarada
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - ID-Aligner: Aprimorando a geração de texto para imagem com preservação de identidade com aprendizado de feedback de recompensa
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - Elementos de imagem editáveis para síntese controlável
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - CatLIP: Precisão de reconhecimento visual em nível CLIP com pré-treinamento 2,7x mais rápido em dados de imagem e texto em escala web
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24/04 - BASS: Amostragem especulativa em lote otimizada para atenção
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 23/04 - Transformadores podem representar modelos de linguagem n-gram
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 23/04 - Relatório Técnico Pegasus-v1
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 23/04 - Mistura de especialistas com múltiplas cabeças
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 23/04 - FlashSpeech: Síntese Eficiente de Fala Zero-Shot
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - SnapKV: LLM sabe o que você procura antes da geração
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - SEED-X: Modelos Multimodais com Compreensão e Geração Unificada de Multigranularidade
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - Reconstrução de Coordenadas de Cena: Posicionamento de Coleções de Imagens via Aprendizado Incremental de um Relocalizador
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - Relatório Técnico Phi-3: Um modelo de linguagem altamente capaz localmente em seu telefone
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - OpenELM: uma família de modelos de linguagem eficiente com treinamento de código aberto e estrutura de inferência
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - MultiBooth: Rumo à geração de todos os seus conceitos em uma imagem a partir de texto
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - Aprendendo o controle de locomoção H-Infinity
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - Quão bons são os modelos LLaMA3 quantizados de baixo bit? Um estudo empírico
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - Alinhe suas etapas: otimizando cronogramas de amostragem em modelos de difusão
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22/04 - Um Agente Multimodal de Interpretabilidade Automatizado
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 21/04 - Hyper-SD: Modelo de consistência segmentada por trajetória para síntese eficiente de imagens
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 21/04 - AdvPrompter: Solicitação Adversarial Adaptativa Rápida para LLMs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 20/04 - Modelos de consistência musical
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - A hierarquia de instruções: treinando LLMs para priorizar instruções privilegiadas
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - TextSquare: Ampliando o ajuste de instrução visual centrado em texto
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - PhysDreamer: Interação Baseada em Física com Objetos 3D via Geração de Vídeo
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - LLM-R2: Um sistema de reescrita baseado em regras aprimorado com modelo de linguagem grande para aumentar a eficiência da consulta
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - Quão real é real? Uma estrutura de avaliação humana para exemplos adversários irrestritos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - Até onde podemos ir com o reparo prático do programa em nível de função?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - Groma: Tokenização visual localizada para fundamentar modelos multimodais de grandes linguagens
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - O Splatting Gaussiano precisa de inicialização do SFM?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19/04 - AutoCrawler: um agente web de compreensão progressiva para geração de web crawler
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - TriForce: Aceleração sem perdas de geração de sequências longas com decodificação especulativa hierárquica
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - Rumo ao autoaperfeiçoamento de LLMs por meio da imaginação, pesquisa e crítica
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - Reutilize suas recompensas: transferência de modelo de recompensa para alinhamento interlingual Zero-Shot
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - Reka Core, Flash e Edge: uma série de poderosos modelos de linguagem multimodal
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - OpenBezoar: modelos pequenos, econômicos e abertos treinados em combinações de dados de instrução
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - MeshLRM: Grande modelo de reconstrução para malha de alta qualidade
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - Apresentando a versão 0.5 do AI Safety Benchmark da MLCommons
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - Apresentando Meta Llama 3: O LLM disponível abertamente mais capaz até o momento
(Blogue), - 18/04 - EdgeFusion: geração de texto para imagem no dispositivo
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - BLINK: Modelos multimodais de grandes linguagens podem ver, mas não perceber
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18/04 - AniClipart: Animação de clipart com antecedentes de texto para vídeo
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 17/04 - MoA: Mistura de atenção para desemaranhamento sujeito-contexto na geração de imagens personalizadas
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 17/04 - FlowMind: Geração automática de fluxo de trabalho com LLMs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 17/04 - Tipografia Dinâmica: Dando Vida às Palavras
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 17/04 - API Stable Diffusion 3 agora disponível
(Twitter), (Blog), (Demonstração), - 16/04 - VASA-1: Rostos falantes realistas com áudio gerados em tempo real
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 16/04 - A secretária de Comércio dos EUA, Gina Raimondo, anuncia expansão da equipe de liderança do US AI Safety Institute
(Notícias), - 16/04 - Geração de música longa com difusão latente
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 15/04 - Avaliadores do LLM reconhecem e favorecem suas próprias gerações
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 15/04 - Video2Game: ambiente em tempo real, interativo, realista e compatível com navegador a partir de um único vídeo
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 15/04 - Tango 2: Alinhando gerações de texto para áudio baseadas em difusão por meio da otimização de preferência direta
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 15/04 - Domando o modelo de difusão latente para pintura de campo de radiação neural
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 15/04 - Opus pode operar como uma máquina de Turing
(twitter), - 15/04 - MathGPT: Aproveitando o Llama 2 para criar uma plataforma de aprendizagem altamente personalizada
- 15/04 - HQ-Edit: um conjunto de dados de alta qualidade para edição de imagens baseada em instruções
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 15/04 - Ctrl-Adapter: Uma estrutura eficiente e versátil para adaptar diversos controles a qualquer modelo de difusão
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 15/04 - Compressão Representa Inteligência Linearmente
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 15/04 - CompGS: Representação Eficiente de Cena 3D via Splatting Gaussiano Comprimido
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 14/04 - TextHawk: Explorando a percepção refinada e eficiente de modelos multimodais de grandes linguagens
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 13/04 - Cathie Wood entra no boom do ChatGPT com nova aposta OpenAI
(Notícias), - 12/04 - CLIP de dimensionamento (redução): uma análise abrangente de dados, arquitetura e estratégias de treinamento
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 12/04 - Testando o conhecimento 3D de modelos de base visual
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 12/04 - Pré-treinamento de LMs de base pequena com menos tokens
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 12/04 - Sobre a Robustez da Orientação Linguística para Tarefas de Visão de Baixo Nível: Resultados da Estimativa de Profundidade
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 12/04 - MonoPatchNeRF: Melhorando campos de radiação neural com orientação monocular baseada em patch
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 12/04 - Megalodon: Pré-treinamento e inferência LLM eficiente com comprimento de contexto ilimitado
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 12/04 - O ChatGPT está transformando o estilo de escrita dos acadêmicos?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 12/04 - COCONut: Modernizando a Segmentação COCO
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 12/04 - AI Chip reduz orçamento de energia em mais de 99 por cento
(Notícias), - 12/04 - AdapterSwap: Treinamento Contínuo de LLMs com Remoção de Dados e Garantias de Controle de Acesso
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 12/04 - Prévia da Visão Grok-1.5
(Demonstração), - 12/04 - O bom, o mau e o alfinete humano
(Notícias), - 12/04 - Usuários pagos do ChatGPT agora podem acessar o GPT-4 Turbo
(Twitter), (Notícias), , () - 11/04 - A necessidade de conselhos de padrões de auditoria de IA
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 11/04 - Transformador de Lembrança para Aprendizagem Contínua
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - Amazon adiciona Andrew Ng, uma voz líder em inteligência artificial, ao seu conselho de administração
(Notícias), - 11/04 - Adobe está comprando vídeos por US$ 3 por minuto para construir um modelo de IA
(Notícias), - 11/04 - UltraEval: uma plataforma leve para avaliação flexível e abrangente para LLMs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 11/04 - Eficiência transferível e baseada em princípios para segmentação de vocabulário aberto
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 11/04 - Agente SWE
(twitter), (demonstração), , () - 11/04 - Laneformer esparso
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - Rho-1: Nem todos os tokens são o que você precisa
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 11/04 - ResearchAgent: Geração de Ideias de Pesquisa Iterativa sobre Literatura Científica com Grandes Modelos de Linguagem
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - RecurrentGemma: Superando os transformadores para modelos eficientes de linguagem aberta
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - OSWorld: Benchmarking de Agentes Multimodais para Tarefas Abertas em Ambientes de Computador Reais
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - LLoCO: Aprendendo Longos Contextos Offline
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - Aproveitando grandes modelos de linguagem (LLMs) para apoiar a anotação colaborativa de dados de risco on-line de IA humana
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - JetMoE: Alcançando o desempenho do Llama2 com 0,1 milhão de dólares
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) (Projeto), (twitter), , (✳️), () - 11/04 - HGRN2: RNNs Lineares Gated com Expansão de Estado
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 11/04 - Das palavras aos números: seu grande modelo de linguagem é secretamente um regressor capaz quando dados exemplos no contexto
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - Ferret-v2: uma linha de base aprimorada para referência e fundamentação com modelos de linguagem grandes
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - ControlNet++: Melhorando os controles condicionais com feedback de consistência eficiente
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - Detecção de anomalias de vídeo com reconhecimento de contexto em conjuntos de dados de longo prazo
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - ChatGPT-3.5, Claude 3 chuta o traseiro pixelado no torneio Street Fighter III para LLMs
(Notícias), - 11/04 - ChatGPT pode prever o futuro quando conta histórias ambientadas no futuro sobre o passado
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - Melhores práticas e lições aprendidas em dados sintéticos para modelos de linguagem
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - Benchmark LLMs lutando em Street Fighter 3
(Demonstração), , () - 11/04 - Diálogos de Áudio: conjunto de dados de diálogos para compreensão de áudio e música
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - Aplicar orientação em um intervalo limitado melhora a qualidade da amostra e da distribuição em modelos de difusão
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11/04 - AmpleGCG: Aprendendo um modelo generativo universal e transferível de sufixos adversários para jailbreak de LLMs abertos e fechados
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 10/04 - Ferramenta de transparência LM: ferramenta interativa para análise de modelos de linguagem de transformadores
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 10/04 - Gemini 1.5 Pro agora entende áudio
(twitter), - 10/04 - Explorando a profundidade do conceito: como grandes modelos de linguagem adquirem conhecimento em diferentes camadas?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 10/04 - Arquiteto Urbano: Geração de Cena Urbana 3D Direcionável com Layout Prévio
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 10/04 - RealmDreamer: geração de cenas 3D baseada em texto com pintura interna e difusão de profundidade
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 10/04 - OpenAI e Meta estão prestes a lançar modelos de IA capazes de raciocinar como humanos, diz relatório
(Notícias), - 10/04 - MetaCheckGPT - Um detector de alucinações multitarefa usando incerteza LLM e metamodelos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 10/04 - Meta confirma que seu LLM de código aberto Llama 3 chegará no próximo mês
(Notícias), - 10/04 - Não deixe nenhum contexto para trás: transformadores de contexto infinito eficientes com atenção infinita
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 10/04 - XAI incremental: compreensão memorável de IA com explicações incrementais
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 10/04 - DreamScene360: Geração irrestrita de cena de texto para 3D com salpicos panorâmicos gaussianos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 10/04 - Mapo Tofu Contém Café? Sondando LLMs para conhecimento cultural relacionado à alimentação
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 10/04 - BRAVE: Ampliando a codificação visual de modelos de linguagem visual
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 10/04 - A startup de IA Mistral lança um modelo de IA de 281 GB para rivalizar com OpenAI, Meta e Google
(Notícias), - 10/04 - Comunicação Semântica Generativa Orientada por Agente para Vigilância Remota
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 10/04 - Adaptando o Decodificador LLaMA ao Vision Transformer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 10/04 - Uma Pesquisa sobre a Integração de IA Generativa para Pensamento Crítico em Redes Móveis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 09/04 - Dê uma olhada! Repensando como avaliar o Jailbreak do modelo de linguagem
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 09/04 - RÉGUA: Qual é o tamanho real do contexto de seus modelos de linguagem de contexto longo?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 09/04 - Revisão da densificação em respingos gaussianos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 09/04 - Reconstruindo objetos portáteis em 3D
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 09/04 - RAR-b: Raciocínio como referência de recuperação
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 09/04 - Engenharia de Prompt de Preservação de Privacidade: Uma Pesquisa
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 09/04 - Sobre Avaliação da Eficiência do Código Fonte Gerado por LLMs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 09/04 - Relatório Técnico OmniFusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 09/04 - MuPT: um transformador pré-treinado de música simbólica generativa
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 09/04 - MiniCPM: Revelando o Potencial de Modelos de Pequenas Linguagens com Estratégias de Treinamento Escaláveis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 09/04 - Magic-Boost: Impulsione a geração 3D com difusão condicionada Mutli-View
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 09/04 - LLM2Vec: Grandes modelos de linguagem são codificadores de texto secretamente poderosos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - InternLM-XComposer2-4KHD: um modelo pioneiro de grande visão e linguagem que lida com resoluções de 336 pixels a 4K HD
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 09/04 - Hash3D: Aceleração sem treinamento para geração 3D
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 09/04 - Google revela projetos de código aberto para IA generativa
(Notícias), - 09/04 - Os elefantes nunca esquecem: memorização e aprendizagem de dados tabulares em grandes modelos de linguagem
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 09/04 - A Apple acaba de lançar o novo Ferret-UI LLM - esta IA pode ler a tela do seu iPhone
(Notícias), - 09/04 - AEGIS: Moderação de segurança de conteúdo de IA adaptativa on-line com conjunto de especialistas em LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 08/04 - YaART: mais uma tecnologia de renderização ART
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 08/04 - WILBUR: Aprendizagem Adaptativa no Contexto para Agentes Web Robustos e Precisos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 08/04 - UniFL: Melhore a difusão estável por meio do aprendizado de feedback unificado
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 08/04 - Ícaro desenfreado: uma pesquisa sobre os perigos potenciais das entradas de imagens na segurança de modelos multimodais de linguagem grande
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 08/04 - Tabela de classificação de alucinações - um esforço aberto para medir alucinações em grandes modelos de linguagem
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 08/04 - O problema de seleção de fatos no reparo de programas baseados em LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/08 - Swapankthing: Ativando a troca de objetos arbitrários em edição visual personalizada
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Sambalingo: ensinando grandes modelos de idiomas novos idiomas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Otimização de preferência negativa: do colapso catastrófico a desaprendizar eficaz
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - NAVER estreia multilíngue hyperclova x llm que ele usará para construir a IA soberana para a Ásia
(Notícias), - 04/08 - MOMA: Adaptador LLM multimodal para geração de imagem personalizada rápida
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - MEDEXPQA: Benchmarking multilíngue de grandes modelos de linguagem para resposta a perguntas médicas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08- MA-LMM: Modelo multimodal grande com memória para entendimento de vídeo a longo prazo
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Layoutllm: Instruções de layout ajustando com grandes modelos de linguagem para entendimento do documento
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/08 - Ferret -UI: Entendimento de interface do usuário móvel fundamentado com LLMs multimodais
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Avaliando recursos de raciocínio intervencionista de grandes modelos de linguagem
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Eagle e Finch: RWKV com estados com valor de matriz e recorrência dinâmica
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/08 - Codeclm: alinhando modelos de linguagem com dados sintéticos personalizados
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - AutoCoderOver: Melhoria autônoma do programa
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/07 - Timegpt na previsão de carga: uma grande perspectiva de modelo de série temporal
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/07 - OpenAI transcreveu mais de um milhão de horas de vídeos do YouTube para treinar GPT -4
(Notícias), - 04/07 - Magictime: modelos de geração de vídeo com lapso de tempo como simuladores metamórficos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/07 - BYTEEDIT: Boost, cumprir e acelerar a edição de imagens generativas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/06 - A votação majoritária dos médicos melhora a adequação da confiança da IA na patologia
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) - 04/06- Difusão-RWKV: Escalando arquiteturas semelhantes a RWKV para modelos de difusão
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/06- Datanerf: edição baseada em texto de profundidade de NERFS
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/06- Beyondscene: geração de cenas centrada na resolução de alta resolução com difusão pré-traida
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/06 - Alinhando modelos de difusão, otimizando a utilidade humana
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/06 - O caso do desenvolvimento de um modelo de fundação para tarefas de planejamento do zero
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Vulnerabilidades aumentadas de LLM de ajuste fino e quantização
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - SpatialTracker: Rastreando qualquer pixels 2D no espaço 3D
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Treinamento de habilidades sociais com grandes modelos de idiomas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Sigma: Siamese Mamba Network para segmentação semântica multimodal
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/05 - Robusta Gaussian Splating
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Physavatar: Aprendendo a física de avatares 3D vestidos a partir de observações visuais
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05- KOALA: Long Video-Llm com quadros-chave com quadros
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Pista: uma avaliação de entendimento de linguagem clínica para LLMS
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Tiny LLM chinês: Pré -treinamento de um modelo de linguagem grande centrado em chinês
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Ajudando os seres humanos em comparações complexas: comparação de informações automatizadas em escala
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - IA incorporada com dois braços: aprendizado, segurança e modularidade com tiro zero
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) - 04/04 - Evolução do modelo de idioma: uma perspectiva de aprendizagem iterada
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04- A visualização da pensamento provoca raciocínio espacial em modelos de linguagem grandes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) (twitter), - 04/04 - Não "Zero -shot" sem dados exponenciais: a frequência do conceito de pré -treinamento determina o desempenho do modelo multimodal
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/04 - Avaliando LLMs na detecção de erros nas respostas de LLM
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/04 - Avaliando modelos de linguagem generativa na extração de informações como correção subjetiva de perguntas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/04 - Otimização direta de Nash: ensinando modelos de idiomas a se auto -melhorar com preferências gerais
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04- CBR-RAG: Raciocínio baseado em casos para geração aumentada de recuperação no LLMS para resposta a perguntas legais
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - Capacidades de grandes modelos de idiomas em engenharia de controle: um estudo de referência no GPT -4, Claude 3 Opus e Gemini 1.0 Ultra
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - CantAqualdAboutThis: alinhando modelos de linguagem para permanecer no tópico em diálogos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - Autowebglm: Bootstrap e reforça um grande agente de navegação na web baseado em modelo de linguagem
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/04 - Treination LLMs sobre texto compactado neuralmente
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - Reft: Representação Finetuning for Language Models
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/04- Red Teaming GPT-4V: O GPT-4V é seguro contra ataques de jailbreak uni/multimodal?
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04- Rall-e: modelagem robusta de idiomas de codec com cadeia de pensamento solicitando a síntese de texto em fala
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - Pointinfinity: Modelos de difusão de pontos invariantes para resolução
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04- Minigpt4-Video: Avançando LLMs multimodais para entendimento de vídeo com tokens visuais intercalados
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04- COMAT: Alinhando o modelo de difusão de texto à imagem com correspondência de conceito de imagem a texto
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - CodeEditorbench: Avaliando a capacidade de edição de código de modelos de linguagem grande
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - Autowebglm: Bootstrap e reforça um grande agente de navegação na web baseado em modelo de linguagem
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/03 - Modelagem Autorregressiva Visual: Geração de Imagem Escalável por meio de previsão de próxima escala
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/03- Sobre a escalabilidade da geração de texto para imagem baseada em difusão
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/03 - MAIS SHOT JAILSBRAVENTE
() - 04/03- LVLM-INTRREPRREPRET: Uma ferramenta de interpretabilidade para grandes modelos de linguagem de visão
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/03 - Modelos de idiomas como compiladores: simular a execução da pseudocode melhora o raciocínio algorítmico em modelos de linguagem
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/03- InstantStyle: Almoço grátis para preservar o estilo na geração de texto para imagem
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/03 - Freditor: alta fidelidade e edição NERF transferível por decomposição de frequência
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/03- Atenção cruzada torna a inferência complicada em modelos de difusão de texto a imagem
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/03- ChatGlm-Math: Melhorando a solução de problemas de matemática em grandes modelos de idiomas com um pipeline de autocritica
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/02 - Reino Unido e Estados Unidos anunciam a parceria sobre a segurança da ciência da IA
(Notícias), - 04/02 - Modelos de idiomas grandes como geradores de domínio de planejamento
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) - 04/02 - PORO 34B e a bênção da multilíngue
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/02 - Octopus v2: Modelo de idioma no device para super agente
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/02- Mistura-de-Depths: Alocar dinamicamente computação em modelos de linguagem baseados em transformadores
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/02- LLMS LOUT-CONTEXT LUTRA COM LONGA APRENDIZAGEM DE CONTEXTO
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/02 - LLM -ABR: Projetando algoritmos de taxa de bits adaptável por meio de modelos de linguagem grande
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/02 - Modelos de idiomas grandes podem mudar o futuro da assistência médica comportamental: uma proposta de desenvolvimento e avaliação responsáveis
() - 04/02 - Relatório Técnico HyperClova x
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/02- Cameractrl: Ativando o controle da câmera para geração de texto para video
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/02 - Avançando generalistas de raciocínio LLM com árvores de preferência
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - Stream de pesquisa (SOS): Aprendendo a pesquisar na linguagem
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - LLM como mentor: uma pesquisa sobre raciocínio estratégico com grandes modelos de idiomas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/01 - A ascensão e ascensão dos grandes modelos de idiomas da IA (LLMS)
(Blog), - 04/01 - transmissão de densa legenda de vídeo
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - Similaridade do estilo de medição em modelos de difusão
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01- Acreditando: melhorando a consistência espacial em modelos de texto para imagem
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - Para empresas de IA que consomem dados, a Internet é muito pequena
(Notícias), - 04/01- FlexidReamer: Geração de imagem para 3D com Flexicubes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/01 - Evalverse: Biblioteca Unificada e Acessível para Avaliação de Modelo de Língua de Grande Linguagem
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - Otimização direta de preferência de vídeo Grandes modelos multimodais da recompensa do modelo de linguagem
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - DBRX, pré -treinamento contínuo, recompensa, inferência mais rápida e mais
(Blog), - 04/01- Cosmicman: um modelo de base de texto para imagens para humanos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/01 - Rede neural com consciência de condição para geração de imagens controladas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/01 - Bigger nem sempre é melhor: Propriedades de dimensionamento de modelos de difusão latente
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/01 - Os grandes modelos de idiomas são químicos sobre -humanos?
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/03/31 - WAVLLM: Rumo a uma fala robusta e adaptativa Modelo de linguagem grande
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/03 - Cansado de plugins? Modelos de idiomas grandes podem ser recomendadores de ponta a ponta
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/03 - Pesquisa sobre grande aprendizado de reforço aprimorado por modelo de idioma: conceito, taxonomia e métodos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 30/03/30 - ST -LLM: Modelos de idiomas grandes são aprendizes temporais eficazes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) - 30/03- Treinamento com consciência de ruído de modelos de idiomas com reconhecimento de layout
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 30/03 - Magritte: Realização 3D manipulativa e generativa da imagem, Topview e texto
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) - 30/03/30- Aurora-M: o primeiro modelo de linguagem multilíngue de código aberto, time de acordo com a ordem executiva dos EUA
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/03/29 - Detecção de problemas insolúveis: Avaliação de confiabilidade dos modelos de linguagem de visão
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/03/29- Transformer-Lite: implantação de alta eficiência de grandes modelos de idiomas em GPUs de telefone celular
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 29/03/29- Snap-It, Tap-It, Splat-It: Splating Gaussiano de informação tátil para reconstruir superfícies desafiadoras
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/03/29 - Reino: Resolução de referência como modelagem de idiomas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 29/03/29 - NVIDIA H200 GPUS Crush MLPERF LLM de Inferência de Inferência
(Notícias), - 03/03/29 - Mambamixer: modelos de espaço de estado seletivo eficientes com token duplo e seleção de canais
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 29/03/29 - Llava -gemma: Acelerando modelos de fundação multimodal com um modelo de linguagem compacta
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 29/03/29- Instantsplat: Visunha esparsa ilimitada, sem pose Gaussian Splating em 40 segundos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/03/29 - Gecko: textos versáteis incorporados destilados de grandes modelos de linguagem
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/03/29 - Dijiang: modelos de linguagem grandes eficientes através da kernelização compacta
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/03/29- O DeepMind desenvolve seguro, um aplicativo baseado em IA que pode verificar LLMs de verificação de fatos
(Notícias), - 29/03/29 - CTRL -SIM: agentes motrizes reativos e controláveis com aprendizado de reforço offline
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 29/03 - Estamos da maneira certa para avaliar grandes modelos de linguagem de visão?
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/28 - SDPO: não use seus dados de uma só vez
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/03/28 - Mesh2nerf: Supervisão direta de malha para representação e geração de campo de radiação neural
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 28/03 - Localizando a memorização do parágrafo em modelos de idiomas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 28/03/28 - Jamba: um modelo de idioma de transformador híbrido -mamba
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 28/03/28 - Gaussiancube: Estruturação de Splating Gaussian usando o transporte ideal para modelagem generativa em 3D
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 28/03 - Claude 3 ultrapassa o GPT -4 no duelo dos Bots da AI. Veja como entrar na ação
(Notícias), - 28/03 - anunciando Grok -1.5
(Blog), (demonstração), - 03/03/27 - Um caminho para a autonomia legal: uma abordagem interoperável e explicável para extrair, transformar, carregar e compuçar informações legais usando modelos de idiomas grandes, sistemas especializados e redes bayesianas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 27/03/27 - VITAR: Vision Transformer com qualquer resolução
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 27/03- Para um modelo de idioma mundial-inglês para assistentes virtuais no desenvolvimento
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 27/03/27 - TextCraft: Seu codificador de texto pode ser controlador de qualidade de imagem
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 27/03/27 - ObjectDrop: BOOTSTAPPPING contrafactuais para remoção e inserção de objetos fotorrealistas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 27/03/27- Mini-geminini: minerando o potencial de modelos de linguagem de visão multimodalidade
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 27/03/27 - Factualidade longa em grandes modelos de linguagem
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 27/03 - Lita: Assistente de localização temporal instruída em linguagem
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 27/03 - Garment3dgen: estilização de vestuário 3D e geração de textura
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 27/03/27 - Gamba: casar -se com Gaussian Splating com Mamba para uma única vista 3D reconstrução
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 27/03/27- FlexEdit: Edição de imagem com base em objeto flexível e controlável baseada em difusão
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/03/27 - Biomedlm: um modelo de linguagem de parâmetro 2.7b treinado em texto biomédico
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/03/26- Magis: estrutura multi-agente baseada em LLM para resolução de problemas do github
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 26/03 - A ineficácia irracional das camadas mais profundas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 26/03- TC4D: geração de texto para 4D condicionada à trajetória
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 26/03/26- Octree-GS: Rumo a renderização consistente em tempo real com o 3D Gaussians estruturados LOD
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 26/03- Apresentando DBRX: um novo LLM aberto de última geração
(Blog), - 26/03 - Relatório Técnico InternLM2
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 26/03- Melhorando a consistência de texto para imagens via otimização de prompt automático
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/03/26- Perceptrons de várias camadas totalmente fusadas no Intel Data Center GPUs
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 26/03 - Egolifter: Segmentação 3D do mundo aberto para percepção egocêntrica
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/26 - Aniportraito: Síntese de Audio -Ordenada de Audio da Animação de Retrato Fotorealista
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 26/03 - 2D Gaussian Splating para campos de brilho geometricamente precisos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 25/03/25 - Rumo à avaliação automática para as capacidades clínicas da LLMS: métrica, dados e algoritmo
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/03/25 - ReparaGent: um agente autônomo, LLM para reparo do programa
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/03/25- RL para modelos de consistência: geração mais rápida de text-to-mage de recompensa de recompensa
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/03/25- VP3D: Libertar o prompt visual 2D para geração de texto para 3D
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 25/03/25- Trip: Aprendizagem residual temporal com ruído de imagem antes dos modelos de difusão de imagem para video
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/03/25- SDXS: modelos de difusão latente em tempo real com condições de imagem
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 25/03/25 - Sistema operacional do agente LLM
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/03/25 - Flashface: Personalização da imagem humana com preservação de identidade de alta fidelidade
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/03/25- Dreampolisher: Rumo a geração de texto para 3D de alta qualidade via difusão geométrica
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/03/25- Seja você mesmo: atenção limitada para geração de texto para imagem de vários sujeitos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 23/03 - Quando a geração de código baseada em LLM atende ao processo de desenvolvimento de software
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 22/03 - THEMESTATION: Gerando ativos 3D com reconhecimento de tema a partir de poucos exemplos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 22/03/22 - Simba: Arquitetura simplificada baseada em Mamba para visão e série temporal multivariada
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 22/03/22 - LLM2LLM: Boming LLMs com um novo aprimoramento de dados iterativos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/03/22- LATTE3D: Síntese de texto amortizado em larga escala em escala 3D
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 22/03/22 - Internvideo2: Scaling Video Foundation Models para compreensão de vídeo multimodal
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 22/03 - A seguir: Avaliando e ensinando modelos de recuperação de informações para seguir as instruções
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 22/03/22 - Dragapart: Aprendendo um movimento de nível parcial anterior para objetos articulados
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 22/03 - Os grandes modelos de idiomas podem explorar o contexto?
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/03/22 - Allhands: pergunte -me qualquer coisa em feedback literal em larga escala através de grandes modelos de linguagem
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) - 21/03/21 - Peergpt: investigando os papéis dos agentes de pares baseados em LLM como moderadores de equipe e participantes do aprendizado colaborativo infantil
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 21/03/21 - Stylecinegan: Generation cinemagraph da paisagem usando um estilo de estilo pré -treinado
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 21/03/21 - StreamingT2V: Geração de vídeo longa consistente, dinâmica e extensível do texto
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 21/03/21 - Renoise: Inversão de imagem real por meio de ingestão iterativa
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 21/03 - Recurso para recuperação: conversando com modelos de linguagem generativa
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 21/03/21 - Rakutenai -7b: estendendo grandes modelos de idiomas para japonês
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/21 - MYVLM: Personalizando VLMs para consultas específicas do usuário
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 21/03/21 - Mathverse: Seu LLM multimodal realmente vê os diagramas em problemas de matemática visual?
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 21/03/21 - GRM: grande modelo de reconstrução gaussiana para reconstrução e geração eficientes 3D
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 21/03 - A Assembléia Geral adota uma resolução marcante de inteligência artificial
(Notícias), - 21/03/21 - Gaussian Gosping: Campos de brilho complexos editáveis com renderização em tempo real
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 21/03 - EXPLORATIVO EXCLORATIVO DE TEMPO E ESPAÇO
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 21/03- modelos de difusão de vídeo eficientes por meio de decomposição de conteúdo-quadro-quadro-movimento
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 21/03- Dreamreward: Text-to-3D Generation com preferência humana
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 21/03/21 - Cobra: estendendo o Mamba a um modelo de linguagem grande multimodal para inferência eficiente
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 21/03/21 - Campeão: Animação de imagem humana controlável e consistente com orientação paramétrica 3D
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 21/03/21- Anyv2v: uma estrutura plug-and-play para qualquer tarefa de edição de vídeo para vídeo
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 20/03 - Mapping LLM Security Paisagens: uma proposta abrangente de avaliação de risco das partes interessadas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 20/03 - Zigma: Modelo de Difusão Zigzag Mamba
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 20/03 - VSTAR: enfermagem temporal generativa para síntese de vídeo dinâmica mais longa
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 20/03 - Recompensa: Avaliando modelos de recompensa para modelagem de idiomas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 20/03 - Treinamento reverso para amamentar a maldição de reversão
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 20/03- Radsplat: Radiance Informed Gaussian Splating para renderização robusta em tempo real com mais de 900 fps
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 20/03 - Mora: permitindo a geração de vídeos generalistas por meio de uma estrutura multi -agente
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 20/03/ 20Factory: ajuste fino eficiente unificado de mais de 100 modelos de idiomas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 20/03- IDADAPTER: Aprendendo recursos mistos para a personalização sem ajuste de modelos de texto para imagem
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 20/03 - Hyperllava: Tuning Dynamic Visual and Language Perpecial para grandes modelos de linguagem grande
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 20/03 - Avaliando modelos de fronteira para capacidades perigosas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 20/03 - Depthfm: estimativa rápida de profundidade monocular com correspondência de fluxo
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 20/03 - Compress3d: um espaço latente compactado para a geração 3D de uma única imagem
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 20/03- Be-your-Outpainter: Dominando o vídeo de vídeo através de adaptação específica de entrada
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/19 - Quando não precisamos de modelos de visão maiores?
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 19/03/19- Vid2Robot: Aprendizagem de políticas de ponta a ponta com transformadores de Att-Attion Transformers
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 19/03/19 - Rumo a um modelo de fundação de uso geral para patologia computacional
() - 03/19- TexDreamer: em direção à geração de textura humana 3D de alta fidelidade zero-tiro
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - ScenScript: Reconstruindo cenas com um modelo de linguagem estruturada autoregressiva
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 19/03/19- Mplug-Docowl 1.5: Aprendizagem de estrutura unificada para compreensão do documento sem OCR
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/19 - MAGIC FIXUP: simplificando a edição de fotos assistindo a vídeos dinâmicos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 19/03/19- LLMLINGUA-2: Destilação de dados para compactação eficiente e fiel, compressão agnóstica de tarefas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/19- GVGEN: geração de texto para 3D com representação volumétrica
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - Gaussianflow: Dinâmica gaussiana divulgada para criação de conteúdo 4D
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19- Fresco: Correspondência espacial-temporal para tradução de vídeo zero-shot
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 19/03/19- FourisCale: uma perspectiva de frequência sobre a síntese de imagem de alta resolução sem treinamento
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/19 - Otimização evolutiva de receitas de fusão de modelos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), ([: octocat:] (https : //github.com/ sakanaai/evolutório-model-merge)! [Github Repo Stars] (https://img.shields.io/github/stars/ Sakanaai/Modelo evolutivo-Merge? Estilo = Social)) - 19/03/19 - Comberse: criação de ativos 3D composicionais usando orientação de difusão espacialmente consciente
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - Raciocínio baseado em gráficos: Transferindo recursos de LLMS para VLMS
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - MM1 da Apple: um modelo de linguagem grande multimodal capaz de interpretar imagens e dados de texto
(Notícias), - 03/19- Animatediff-Lightning: Destilação de Difusão Cross-Model
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - Agente -Flan: Projetando dados e métodos de ajuste eficaz do agente para grandes modelos de idiomas
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/19 - Um modelo de base visual -linguagem para patologia computacional
(), (✳️) - 03/19 - agentes de IA característicos através de grandes modelos de linguagem
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), (! [Github repo estrelas] ( https://img.shields.io/github/stars/nuaa-nlp/character100? style = social)) - 03/18 - Até onde estamos na tomada de decisão do LLMS? Avaliando a capacidade de jogo da LLMS em ambientes multi-agentes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/18 - VideoAgent: um agente multimodal agitado por memória para entendimento de vídeo
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 18/03/18 - Vfusion3d: Aprendendo modelos generativos 3D escaláveis a partir de modelos de difusão de vídeo
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 18/03/18 - TNT -LLM: Mineração de texto em escala com grandes modelos de linguagem
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 18/03/18 - SV3D: nova síntese de várias visualizações e geração 3D de uma única imagem usando difusão de vídeo latente
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 18/03/18 - Routerbench: uma referência para o sistema de roteamento multi -llm
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), (ss) - 18/03/18- Meta-interpretação para automatizar o reconhecimento visual zero-shot com LLMS
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 18/03/18 - LN3DIFF: Difusão de campos neurais latentes escaláveis para a rápida geração 3D
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 18/03/18- llava-uhd: um LMM percebendo qualquer proporção de aspecto e imagens de alta resolução
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/18 - Larimar: grandes modelos de linguagem com controle de memória episódica
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/18- Infinite-Id: Personalização Preservada por Identidade via ID-semantics Decupling Paradigm
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 18/03/18 - GPT -4 como avaliador: Avaliando grandes modelos de linguagem no gerenciamento de pragas na agricultura
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/18 - Generic 3D Diffusion Adapter Using Controlled Multi-View Editing
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/18 - From Pixels to Insights: A Survey on Automatic Chart Understanding in the Era of Large Foundation Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/18 - Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/18 - Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/18 - Compiler generated feedback for Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/17 - PhD: A Prompted Visual Hallucination Evaluation Dataset
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/17 - MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/16 - VisionCLIP: An Med-AIGC based Ethical Language-Image Foundation Model for Generalizable Retina Image Analysis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/16 - Do Large Language Models understand Medical Codes?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - VideoAgent: Long-form Video Understanding with Large Language Model as Agent
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Uni-SMART: Universal Science Multimodal Analysis and Research Transformer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Trusting the Search: Unraveling Human Trust in Health Information from Google and ChatGPT
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/15 - RAFT: Adapting Language Model to Domain Specific RAG
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/15 - RAFT: Adapting Language Model to Domain Specific RAG
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - PERL: Parameter Efficient Reinforcement Learning from Human Feedback
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - NeuFlow: Real-time, High-accuracy Optical Flow Estimation on Robots Using Edge Devices
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/15 - MusicHiFi: Fast High-Fidelity Stereo Vocoding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/15 - LightIt: Illumination Modeling and Control for Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Isotropic3D: Image-to-3D Generation Based on a Single CLIP Embedding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/15 - FDGaussian: Fast Gaussian Splatting from Single Image via Geometric-aware Diffusion Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Enhancing Human-Centered Dynamic Scene Understanding via Multiple LLMs Collaborated Reasoning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - EfficientVMamba: Atrous Selective Scan for Light Weight Visual Mamba
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - DiPaCo: Distributed Path Composition
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Controllable Text-to-3D Generation via Surface-Aligned Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - WavCraft: Audio Editing and Generation with Natural Language Prompts
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - VisionGPT-3D: A Generalized Multimodal Agent for Enhanced 3D Vision Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Video Mamba Suite: State Space Model as a Versatile Alternative for Video Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Video Editing via Factorized Diffusion Distillation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Unlocking the conversion of Web Screenshots into HTML Code with the WebSight Dataset
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - StreamMultiDiffusion: Real-Time Interactive Generation with Region-Based Semantic Control
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Scaling Instructable Agents Across Many Simulated Worlds
(twitter), (Blog), - 03/14 - Recurrent Drafter for Fast Speculative Decoding in Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - LocalMamba: Visual State Space Model with Windowed Selective Scan
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Large Language Models and Causal Inference in Collaboration: A Comprehensive Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Helpful or Harmful? Exploring the Efficacy of Large Language Models for Online Grooming Prevention
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Griffon v2: Advancing Multimodal Perception with High-Resolution Scaling and Visual-Language Co-Referring
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - GPT on a Quantum Computer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/14 - Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - GiT: Towards Generalist Vision Transformer through Universal Language Interface
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Exploring the Capabilities and Limitations of Large Language Models in the Electric Energy Sector
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - BurstAttention: An Efficient Distributed Attention Framework for Extremely Long Sequences
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - 3D-VLA: A 3D Vision-Language-Action Generative World Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Scaling Instructable Agents Across Many Simulated Worlds
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/13 - VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - The Human Factor in Detecting Errors of Large Language Models: A Systematic Literature Review and Future Research Directions
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - SOTOPIA-π: Interactive Learning of Socially Intelligent Language Agents
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Simple and Scalable Strategies to Continually Pre-train Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Scaling Up Dynamic Human-Scene Interaction Modeling
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Language-based game theory in the age of artificial intelligence
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Language models scale reliably with over-training and on downstream tasks
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Knowledge Conflicts for LLMs: A Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Gemma: Open Models Based on Gemini Research and Technology
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - GaussianImage: 1000 FPS Image Representation and Compression by 2D Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Follow-Your-Click: Open-domain Regional Image Animation via Short Prompts
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Cultural evolution in populations of Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Bugs in Large Language Models Generated Code: An Empirical Study
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/12 - Synth^2: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - Motion Mamba: Efficient and Long Sequence Motion Generation with Hierarchical and Bidirectional Selective SSM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - MoAI: Mixture of All Intelligence for Large Language and Vision Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - Learning Generalizable Feature Fields for Mobile Manipulation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - DragAnything: Motion Control for Anything using Entity Representation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/12 - Chronos: Learning the Language of Time Series
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/12 - Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - Transparent AI Disclosure Obligations: Who, What, When, Where, Why, How
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/11 - HILL: A Hallucination Identifier for Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/11 - FAX: Scalable and Differentiable Federated Primitives in JAX
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - FashionReGen: LLM-Empowered Fashion Report Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/11 - VideoMamba: State Space Model for Efficient Video Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - V3D: Video Diffusion Models are Effective 3D Generators
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - Stealing Part of a Production Language Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/11 - Multistep Consistency Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - FaceChain-SuDe: Building Derived Class to Inherit Category Attributes for One-shot Subject-Driven Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/11 - Chain-of-table: Evolving tables in the reasoning chain for table understanding (Blog),
- 03/11 - An Image is Worth 1/2 Tokens After Layer 2: Plug-and-Play Inference Acceleration for Large Vision-Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - Adding NVMe SSDs to Enable and Accelerate 100B Model Fine-tuning on a Single GPU
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/10 - VidProM: A Million-scale Real Prompt-Gallery Dataset for Text-to-Video Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/09 - Algorithmic progress in language models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Sora as an AGI World Model? A Complete Survey on Text-to-Video Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - On Protecting the Data Privacy of Large Language Models (LLMs): A Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/08 - VideoElevator: Elevating Video Generation Quality with Versatile Text-to-Image Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Personalized Audiobook Recommendations at Spotify Through Graph Neural Networks
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - DeepSeek-VL: Towards Real-World Vision-Language Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/08 - CRM: Single Image to 3D Textured Mesh with Convolutional Reconstruction Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - CogView3: Finer and Faster Text-to-Image Generation via Relay Diffusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Now available on Poe: Claude 3 (Demo),
- 03/08 - Google - Health-specific embedding tools for dermatology and pathology (Blog),
- 03/07 - Yi: Open Foundation Models by 01.AI
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - Teaching Large Language Models to Reason with Reinforcement Learning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - StableDrag: Stable Dragging for Point-based Image Editing
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Radiative Gaussian Splatting for Efficient X-ray Novel View Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Pix2Gif: Motion-Guided Diffusion for GIF Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Meet 'Liberated Qwen', an uncensored LLM that strictly adheres to system prompts (News),
- 03/07 - LLMs in the Imaginarium: Tool Learning through Simulated Trial and Error
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - KAIST develops next-generation ultra-low power LLM accelerator (News),
- 03/07 - Inflection-2.5: meet the world's best personal AI (News),
- 03/07 - How Far Are We from Intelligent Visual Deductive Reasoning?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - Evaluating LLM models at scale (Blog),
- 03/07 - Common 7B Language Models Already Possess Strong Math Capabilities
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - Stop Regressing: Training Value Functions via Classification for Scalable Deep RL
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - ShortGPT: Layers in Large Language Models are More Redundant Than You Expect
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - SaulLM-7B: A pioneering Large Language Model for Law
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - NY hospital exec: Multimodal LLM assistants will create a “paradigm shift” in patient care (News),
- 03/06 - Learning to Decode Collaboratively with Multiple Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/06 - Enhancing Vision-Language Pre-training with Rich Supervisions
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - Backtracing: Retrieving the Cause of the Query
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/06 - AI Prompt Engineering Is Dead (News),
- 03/06 - 3D Diffusion Policy
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/05 - OpenAI and Elon Musk (Blog),
- 03/05 - Caduceus: Bi-Directional Equivariant Long-Range DNA Sequence Modeling
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/05 - WikiTableEdit: A Benchmark for Table Editing by Natural Language Instruction (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Updating the Minimum Information about CLinical Artificial Intelligence (MI-CLAIM) checklist for generative modeling research (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/05 - Tuning-Free Noise Rectification for High Fidelity Image-to-Video Generation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Scaling Rectified Flow Transformers for High-Resolution Image Synthesis (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - RT-Sketch: Goal-Conditioned Imitation Learning from Hand-Drawn Sketches (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - Revisiting Meta-evaluation for Grammatical Error Correction (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Modeling Collaborator: Enabling Subjective Vision Classification With Minimal Human Effort via LLM Tool-Use (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - MathScale: Scaling Instruction Tuning for Mathematical Reasoning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/05 - Interactive Continual Learning: Fast and Slow Thinking (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - In Search of Truth: An Interrogation Approach to Hallucination Detection (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ImgTrojan: Jailbreaking Vision-Language Models with ONE Image (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Generative Software Engineering (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - Finetuned Multimodal Language Models Are High-Quality Image-Text Data Filters (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Feast Your Eyes: Mixture-of-Resolution Adaptation for Multimodal Large Language Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Exploring the Limitations of Large Language Models in Compositional Relation Reasoning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - EasyQuant: An Efficient Data-free Quantization Algorithm for LLMs (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Design2Code: How Far Are We From Automating Front-End Engineering? (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ChatGPT and biometrics: an assessment of face recognition, gender detection, and age estimation capabilities (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ChatCite: LLM Agent with Human Workflow Guidance for Comparative Literature Summary (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Benchmarking the Text-to-SQL Capability of Large Language Models: A Comprehensive Evaluation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - An Empirical Study of LLM-as-a-Judge for LLM Evaluation: Fine-tuned Judge Models are Task-specific Classifiers (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 3/5 - OpenAI - ChatGPT can now read responses to you. (twitter,
- 03/04 - The Claude 3 Model Family: Opus, Sonnet, Haiku
() (twitter), , (✳️) - 03/04 - Wukong: Towards a Scaling Law for Large-Scale Recommendation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - Large language models surpass human experts in predicting neuroscience results
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/04 - NoteLLM: A Retrievable Large Language Model for Note Recommendation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - MagicClay: Sculpting Meshes With Generative Neural Fields (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/04 - Enhancing LLM Safety via Constrained Direct Preference Optimization (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - DACO: Towards Application-Driven and Comprehensive Data Analysis via Code Generation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/04 - CODE-ACCORD: A Corpus of Building Regulatory Data for Rule Generation towards Automatic Compliance Checking (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/04 - Balancing Enhancement, Harmlessness, and General Capabilities: Enhancing Conversational LLMs with Direct RLHF (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - adaptMLLM: Fine-Tuning Multilingual Language Models on Low-Resource Languages with Integrated LLM Playgrounds (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 3/4 - ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - TripoSR: Fast 3D Object Reconstruction from a Single Image (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - RT-H: Action Hierarchies Using Language (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/4 - ResAdapter: Domain Consistent Resolution Adapter for Diffusion Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/4 - OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - Build AI for a Better Future (twitter), (News),
- 3/4 - AtomoVideo: High Fidelity Image-to-Video Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️ )
- 03/03 - Research Papers in February 2024: A LoRA Successor, Small Finetuned LLMs Vs Generalist LLMs, and Transparent LLM Research (Blog),
- 3/3 - Nvidia CEO Jensen Huang says AI could pass most human tests in 5 years (News
- 3/3 - MovieLLM: Enhancing Long Video Understanding with AI-Generated Movies (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/3 - InfiMM-HD: A Leap Forward in High-Resolution Multimodal Understanding (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/3 - Could this be bigger than OpenAI? Microsoft invests billions in French startup — Mistral AI is a multilingual maestro that's almost as good as ChatGPT 4 (News),
- 3/3 - 3DGStream: On-the-Fly Training of 3D Gaussians for Efficient Streaming of Photo-Realistic Free-Viewpoint Videos (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/2 - Nvidia CEO says AI could pass human tests in five years (News
- 3/1 - Elon Musk sues OpenAI and CEO Sam Altman over contract breach (News)
- 3.1 - AtP*: An efficient and scalable method for localizing LLM behaviour to components (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - VisionLLaMA: A Unified LLaMA Interface for Vision Tasks (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Learning and Leveraging World Models in Visual Representation Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - RealCustom: Narrowing Real Text Word for Real-Time Open-Domain Text-to-Image Customization (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Multimodal ArXiv: A Dataset for Improving Scientific Comprehension of Large Vision-Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Resonance RoPE: Improving Context Length Generalization of Large Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/29 - OHTA: One-shot Hand Avatar via Data-driven Implicit Priors
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 02/29 - Retrieval-Augmented Generation for AI-Generated Content: A Survey (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 2.29 - DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Panda-70M: Captioning 70M Videos with Multiple Cross-Modality Teachers (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Humanoid Locomotion as Next Token Prediction (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - StarCoder 2 and The Stack v2: The Next Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Trajectory Consistency Distillation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.29 - Beyond Language Models: Byte Models are Digital World Simulators (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Syntactic Ghost: An Imperceptible General-purpose Backdoor Attacks on Pre-trained Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - ViewFusion: Towards Multi-View Consistency via Interpolated Denoising (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.29 - MOSAIC: A Modular System for Assistive and Interactive Cooking (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 02/28 - Automatic Creative Selection with Cross-Modal Matching
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 2.28 - Priority Sampling of Large Language Models for Compilers (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.28 - Simple linear attention language models balance the recall-throughput tradeoff (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.28 - Approaching Human-Level Forecasting with Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.28 - Datasets for Large Language Models: A Comprehensive Survey (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ( )
- 2.28 - A Survey on Recent Advances in LLM-Based Multi-turn Dialogue Systems (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 02/27 - A High Level Guide to LLM Evaluation Metrics (Blog),
- 2/27 - Users Say Microsoft's AI Has Alternate Personality as Godlike AGI That Demands to Be Worshipped (News)
- 2/27 - Google DeepMind CEO on AGI, OpenAI and Beyond – MWC 2024 (News)
- 2.27 - Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - Towards Optimal Learning of Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Evaluating Very Long-Term Conversational Memory of LLM Agents (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Seeing and Hearing: Open-domain Visual-Audio Generation with Diffusion Latent Aligners (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - OmniACT: A Dataset and Benchmark for Enabling Multimodal Generalist Autonomous Agents for Desktop and Web (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - EMO: Emote Portrait Alive -- Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Training-Free Long-Context Scaling of Large Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - VastGaussian: Vast 3D Gaussians for Large Scene Reconstruction (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - DiffuseKronA: A Parameter Efficient Fine-tuning Method for Personalized Diffusion Model (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Sora Generates Videos with Stunning Geometrical Consistency (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Playground v2.5: Three Insights towards Enhancing Aesthetic Quality in Text-to-Image Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - Video as the New Language for Real-World Decision Making (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 02/27 - On the Societal Impact of Open Foundation Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 02/26 - Set the Clock: Temporal Alignment of Pretrained Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 2/26 - DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models (), ()(?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/26 - Mistral Large is our flagship model, with top-tier reasoning capacities (News)
- 2.26 - Disentangled 3D Scene Generation with Layout Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Multi-LoRA Composition for Image Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - MobiLlama: Towards Accurate and Lightweight Fully Transparent GPT (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ( )
- 2.26 - Do Large Language Models Latently Perform Multi-Hop Reasoning? (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Nemotron-4 15B Technical Report (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - StructLM: Towards Building Generalist Models for Structured Knowledge Grounding (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Towards Open-ended Visual Quality Comparison (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.25 - ChatMusician: Understanding and Generating Music Intrinsically with LLM (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ( )
- 2.25 - FuseChat: Knowledge Fusion of Chat Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/24 - Divide-or-Conquer? Which Part Should You Distill Your LLM?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 02/24 - Perplexity.ai Revamps Google SEO Model For LLM Era (News)
- 02/24 - Data Interpreter: An LLM Agent For Data Science
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 2.24 - Empowering Large Language Model Agents through Action Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️ )
- 2.23 - Seamless Human Motion Composition with Blended Positional Encodings (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.23 - AgentOhana: Design Unified Data and Training Pipeline for Effective Agent Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️ )
- 2.23 - Gen4Gen: Generative Data Pipeline for Generative Multi-Concept Composition (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.23 - API-BLEND: A Comprehensive Corpora for Training and Benchmarking API LLMs (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - Genie: Generative Interactive Environments (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - GPTVQ: The Blessing of Dimensionality for LLM Quantization (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - ChunkAttention: Efficient Self-Attention with Prefix-Aware KV Cache and Two-Phase Partition (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.22 - CLoVe: Encoding Compositional Language in Contrastive Vision-Language Models (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️), ()
- 02/22 - Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 2.22 - Divide-or-Conquer? Which Part Should You Distill Your LLM? (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - Watermarking Makes Language Models Radioactive (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - AutoPrompt - prompt optimization framework ()
- 2.22 - Announcing Stable Diffusion 3 (tweet), (blog)
- 2.22 - DualFocus: Integrating Macro and Micro Perspectives in Multi-modal Large Language Models (), (), (?), (?), (?), (HTML), (✳️) , ()
- 2.22 - RoboScript: Code Generation for Free-Form Manipulation Tasks across Real and Simulation (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - LLMs with Industrial Lens: Deciphering the Challenges and Prospects -- A Survey (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Vision-Language Navigation with Embodied Intelligence: A Survey (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Enhancing Robotic Manipulation with AI Feedback from Multimodal Large Language Models (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Do Machines and Humans Focus on Similar Code? Exploring Explainability of Large Language Models in Code Summarization (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - PALO: A Polyglot Large Multimodal Model for 5B People (), (), (?), (?), (?), (HTML), (✳️) , ()
- 2.22 - GeneOH Diffusion: Towards Generalizable Hand-Object Interaction Denoising via Denoising Diffusion (), (), ([:paperclip:](https://arxiv.org/pdf/2402.148


