YAYI UIE
1.0.0

[README] [?HF Repo] [?Versão web]
Chinês | Inglês
[2024.03.28] Todos os modelos e dados são carregados na Magic Community.
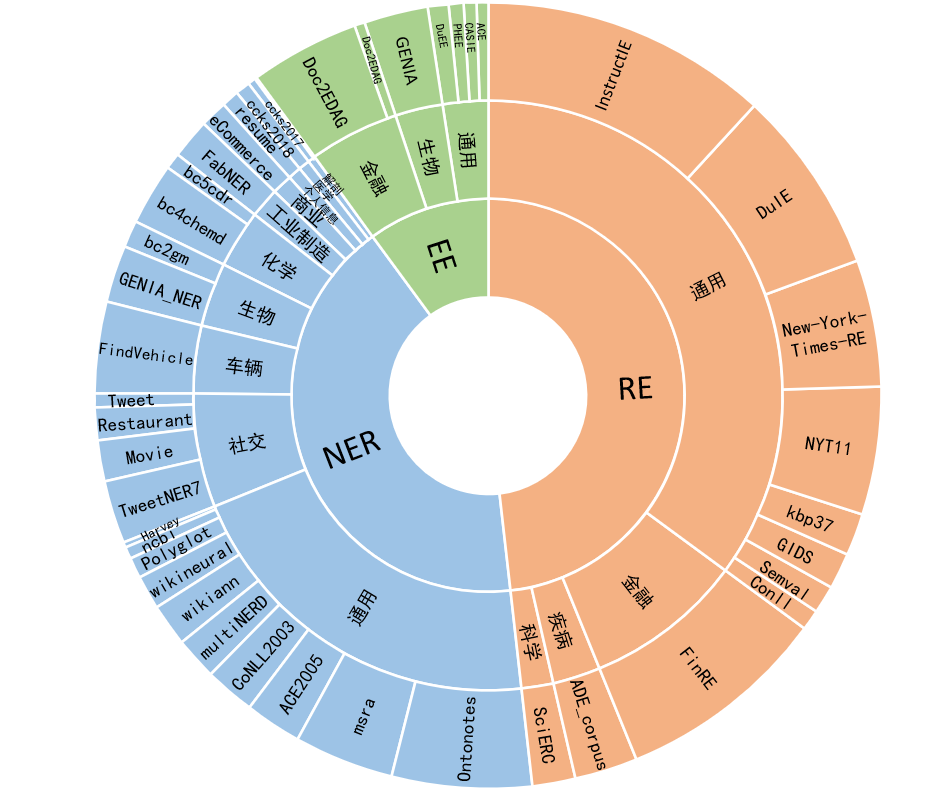
O modelo grande unificado de extração de informações Yayi (YAYI-UIE) ajusta as instruções em milhões de dados de extração de informações de alta qualidade construídos manualmente. As tarefas unificadas de extração de informações de treinamento incluem reconhecimento de entidade nomeada (NER), extração de relacionamento (RE) e extração de eventos (. EE) para alcançar a extração estruturada em cenários gerais, de segurança, financeiros, biológicos, médicos, comerciais, pessoais, veiculares, cinematográficos, industriais, restaurantes, científicos e outros.
Através do código aberto do grande modelo Yayi UIE, contribuiremos com nossos próprios esforços para promover o desenvolvimento da comunidade chinesa de código aberto de grande modelo pré-treinado. Por meio do código aberto, construiremos o ecossistema do grande modelo Yayi com todos os parceiros. Para obter mais detalhes técnicos, leia nosso relatório técnico YAYI-UIE: Uma estrutura de ajuste de instrução aprimorada por bate-papo para extração universal de informações.
| nome | ?Identificação do modelo HF | Endereço de download | Logotipo do modelo mágico | Endereço de download |
|---|---|---|---|---|
| YAYI-UIE | pesquisa wengué/yayi-uie | Baixar modelo | pesquisa wengué/yayi-uie | Baixar modelo |
| Dados YAYI-UIE | wengué-pesquisa/yayi_uie_sft_data | Download do conjunto de dados | wengué-pesquisa/yayi_uie_sft_data | Download do conjunto de dados |
54% do corpus de nível de milhão é chinês e 46% é inglês; o conjunto de dados inclui 12 áreas, incluindo finanças, sociedade, biologia, comércio, produção industrial, química, veículos, ciência, doenças e tratamento médico, vida pessoal, segurança e em geral. Abrange centenas de cenários
git clone https://github.com/wenge-research/yayi-uie.git
cd yayi-uieconda create --name uie python=3.8
conda activate uiepip install -r requirements.txt Não é recomendado que as versões torch e transformers sejam inferiores às versões recomendadas.
O modelo foi de código aberto em nosso repositório de modelos Huggingface e você pode baixá-lo e usá-lo. A seguir está um código de exemplo que simplesmente chama YAYI-UIE para inferência de tarefas downstream. Ele pode ser executado em uma única GPU, como A100/A800. Ele ocupa cerca de 33 GB de memória de vídeo ao usar a inferência de precisão bf16.
> >> import torch
> >> from transformers import AutoModelForCausalLM , AutoTokenizer
> >> from transformers . generation . utils import GenerationConfig
> >> tokenizer = AutoTokenizer . from_pretrained ( "wenge-research/yayi-uie" , use_fast = False , trust_remote_code = True )
> >> model = AutoModelForCausalLM . from_pretrained ( "wenge-research/yayi-uie" , device_map = "auto" , torch_dtype = torch . bfloat16 , trust_remote_code = True )
> >> generation_config = GenerationConfig . from_pretrained ( "wenge-research/yayi-uie" )
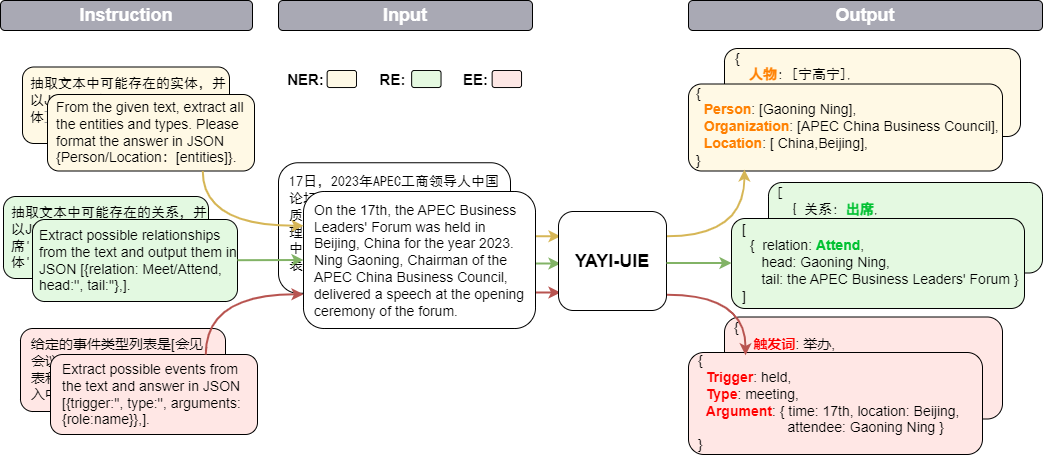
> >> prompt = "文本:氧化锆陶瓷以其卓越的物理和化学特性在多个行业中发挥着关键作用。这种材料因其高强度、高硬度和优异的耐磨性,广泛应用于医疗器械、切削工具、磨具以及高端珠宝制品。在制造这种高性能陶瓷时,必须遵循严格的制造标准,以确保其最终性能。这些标准涵盖了从原材料选择到成品加工的全过程,保障产品的一致性和可靠性。氧化锆的制造过程通常包括粉末合成、成型、烧结和后处理等步骤。原材料通常是高纯度的氧化锆粉末,通过精确控制的烧结工艺,这些粉末被转化成具有特定微观结构的坚硬陶瓷。这种独特的微观结构赋予氧化锆陶瓷其显著的抗断裂韧性和耐腐蚀性。此外,氧化锆陶瓷的热膨胀系数与铁类似,使其在高温应用中展现出良好的热稳定性。因此,氧化锆陶瓷不仅在工业领域,也在日常生活中的应用日益增多,成为现代材料科学中的一个重要分支。 n抽取文本中可能存在的实体,并以json{制造品名称/制造过程/制造材料/工艺参数/应用/生物医学/工程特性:[实体]}格式输出。"
> >> # "<reserved_13>" is a reserved token for human, "<reserved_14>" is a reserved token for assistant
>> > prompt = "<reserved_13>" + prompt + "<reserved_14>"
> >> inputs = tokenizer ( prompt , return_tensors = "pt" ). to ( model . device )
> >> response = model . generate ( ** inputs , max_new_tokens = 512 , temperature = 0 )
> >> print ( tokenizer . decode ( response [ 0 ], skip_special_tokens = True ))Observação:
文本:xx
【实体抽取】抽取文本中可能存在的实体,并以json{人物/机构/地点:[实体]}格式输出。
文本:xx
【关系抽取】已知关系列表是[注资,拥有,纠纷,自己,增持,重组,买资,签约,持股,交易]。根据关系列表抽取关系三元组,按照json[{'relation':'', 'head':'', 'tail':''}, ]的格式输出。
文本:xx
抽取文本中可能存在的关系,并以json[{'关系':'会见/出席', '头实体':'', '尾实体':''}, ]格式输出。
文本:xx
已知论元角色列表是[时间,地点,会见主体,会见对象],请根据论元角色列表从给定的输入中抽取可能的论元,以json{角色:论元}格式输出。
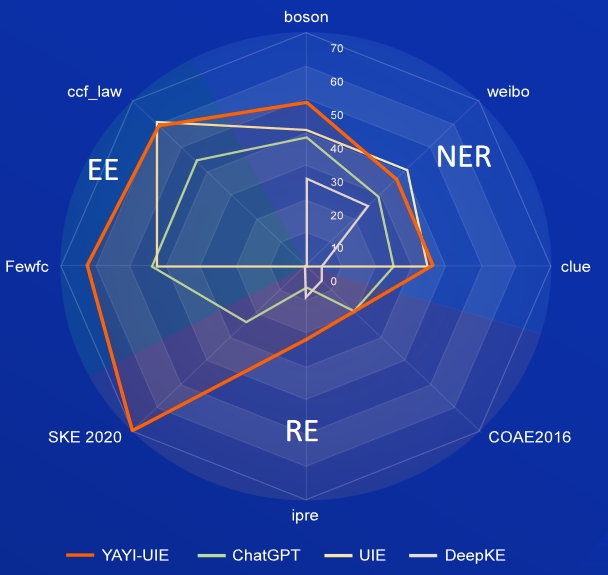
IA, Literatura, Música, Política e Ciência são conjuntos de dados em inglês, e bóson, pista e weibo são conjuntos de dados chineses.
| Modelo | IA | Literatura | Música | Política | Ciência | Média inglesa | bóson | dica | Média chinesa | |
|---|---|---|---|---|---|---|---|---|---|---|
| Davinci | 2,97 | 9,87 | 13,83 | 18h42 | 10.04 | 11.03 | - | - | - | 31.09 |
| Bate-papoGPT 3.5 | 54,4 | 54.07 | 61,24 | 59.12 | 63 | 58,37 | 38,53 | 25.44 | 29,3 | |
| UIE | 31.14 | 38,97 | 33,91 | 46,28 | 41,56 | 38,37 | 40,64 | 34,91 | 40,79 | 38,78 |
| USM | 28.18 | 56 | 44,93 | 36,1 | 44.09 | 41,86 | - | - | - | - |
| InstruirUIE | 49 | 47.21 | 53.16 | 48,15 | 49,3 | 49,36 | - | - | - | - |
| ConhecimentoLM | 13,76 | 20h18 | 14,78 | 33,86 | 9.19 | 18h35 | 25,96 | 4,44 | 25.2 | 18h53 |
| YAYI-UIE | 52,4 | 45,99 | 51.2 | 51,82 | 50,53 | 50,39 | 49,25 | 36,46 | 36,78 | 40,83 |
FewRe, Wiki-ZSL são conjuntos de dados em inglês, SKE 2020, COAE2016, IPRE são conjuntos de dados chineses
| Modelo | PoucosRel | Wiki-ZSL | Média inglesa | SKE 2020 | COAE2016 | IPRE | Média chinesa |
|---|---|---|---|---|---|---|---|
| Bate-papoGPT 3.5 | 9,96 | 13.14 | 11,55 24,47 | 19h31 | 6,73 | 16,84 | |
| ZETT(T5-pequeno) | 30,53 | 31,74 | 31.14 | - | - | - | - |
| ZETT(base T5) | 33,71 | 31.17 | 32,44 | - | - | - | - |
| InstruirUIE | 39,55 | 35,2 | 37,38 | - | - | - | - |
| ConhecimentoLM | 17h46 | 15h33 | 16h40 | 0,4 | 6,56 | 9,75 | 5,57 |
| YAYI-UIE | 36.09 | 41.07 | 38,58 | 70,8 | 19.97 | 22,97 | 37,91 |
notícias de commodities é o conjunto de dados inglês, FewFC, ccf_law é o conjunto de dados chinês
EET (identificação do tipo de evento)
| Modelo | notícias sobre commodities | PoucosFC | ccf_lei | Média chinesa |
|---|---|---|---|---|
| Bate-papoGPT 3.5 | 1,41 | 16h15 | 0 | 8.08 |
| UIE | - | 50,23 | 2.16 | 26h20 |
| InstruirUIE | 23.26 | - | - | - |
| YAYI-UIE | 12h45 | 81,28 | 12,87 | 47.08 |
EEA (extração de argumento de evento)
| Modelo | notícias sobre commodities | PoucosFC | ccf_lei | Média chinesa |
|---|---|---|---|---|
| Bate-papoGPT 3.5 | 8.6 | 44,4 | 44,57 | 44,49 |
| UIE | - | 43.02 | 60,85 | 51,94 |
| InstruirUIE | 21,78 | - | - | - |
| YAYI-UIE | 19,74 | 63.06 | 59,42 | 61,24 |
O modelo SFT treinado com base em dados atuais e modelos básicos ainda apresenta os seguintes problemas em termos de eficácia:
Com base nas limitações do modelo acima, exigimos que os desenvolvedores usem apenas nosso código-fonte aberto, dados, modelos e derivados subsequentes gerados por este projeto para fins de pesquisa e não para fins comerciais ou outros usos que possam causar danos à sociedade. Tenha cuidado ao identificar e usar o conteúdo gerado por Yayi Big Model e não divulgue o conteúdo prejudicial gerado na Internet. Se ocorrer alguma consequência adversa, o comunicador será responsável. Este projeto só pode ser usado para fins de pesquisa, e o desenvolvedor do projeto não é responsável por qualquer dano ou perda causado pelo uso deste projeto (incluindo, mas não se limitando a dados, modelos, códigos, etc.). Consulte o aviso de isenção de responsabilidade para obter detalhes.
O código e os dados deste projeto são de código aberto de acordo com o protocolo Apache-2.0. Quando a comunidade usa o modelo YAYI UIE ou seus derivados, siga o acordo da comunidade e o acordo comercial do Baichuan2.
Se você utiliza nosso modelo em seu trabalho, pode citar nosso artigo:
@article{YAYI-UIE,
author = {Xinglin Xiao, Yijie Wang, Nan Xu, Yuqi Wang, Hanxuan Yang, Minzheng Wang, Yin Luo, Lei Wang, Wenji Mao, Dajun Zeng}},
title = {YAYI-UIE: A Chat-Enhanced Instruction Tuning Framework for Universal Information Extraction},
journal = {arXiv preprint arXiv:2312.15548},
url = {https://arxiv.org/abs/2312.15548},
year = {2023}
}


