Dropout NeuralNetworks
1.0.0
Neste projecto de investigação, concentrar-me-ei nos efeitos da alteração das taxas de abandono escolar no conjunto de dados do MNIST. Meu objetivo é reproduzir a figura abaixo com os dados utilizados no trabalho de pesquisa. O objetivo deste projeto é aprender como a figura do aprendizado de máquina foi produzida. Especificamente, aprender sobre os efeitos do erro de classificação ao alterar/não alterar a probabilidade de abandono.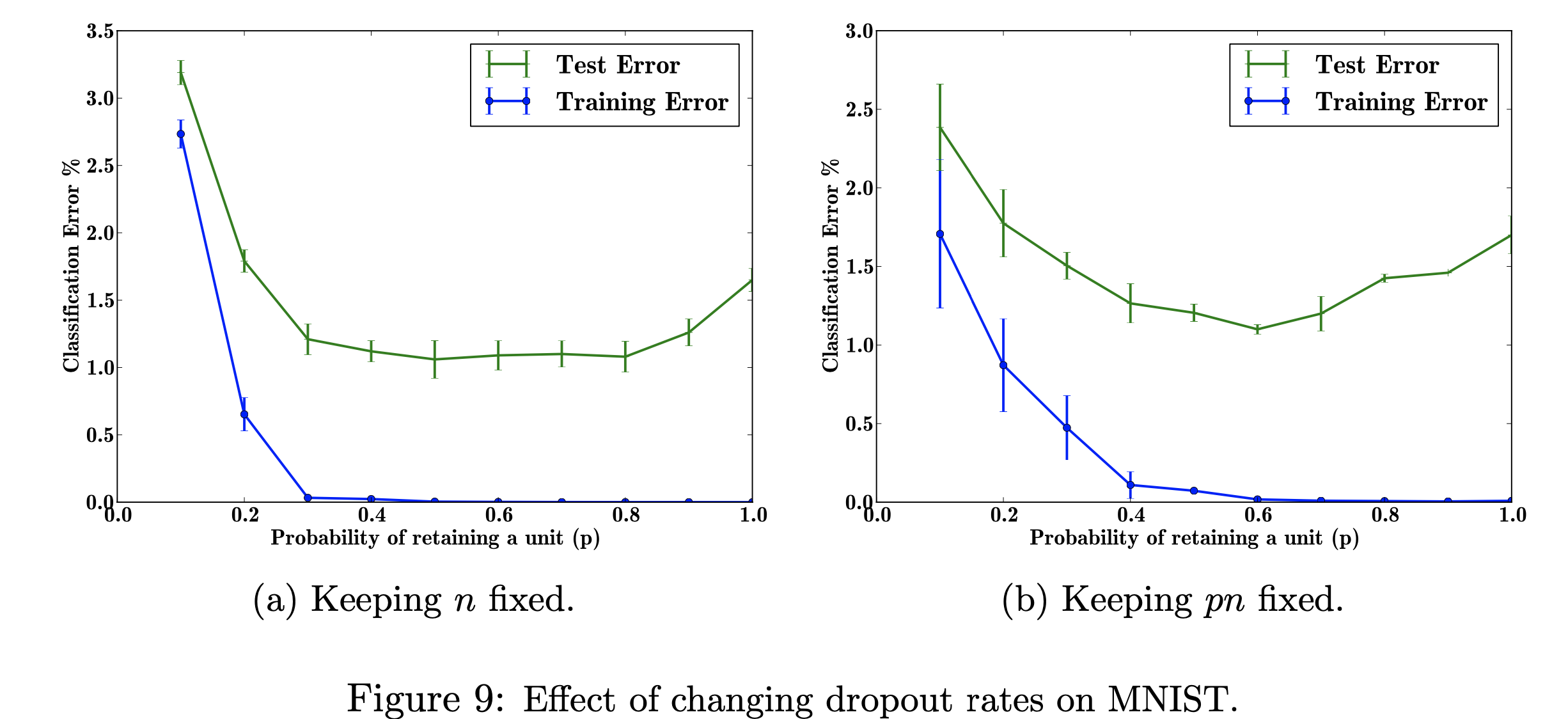 Figura referenciada em: Srivastava, N., Hinton, G., Krizhevsky, A., Krizhevsky, I., Salakhutdinov, R., Dropout: A Simple Way to Prevent Neural Networks from Overfitting, Figura 9
Figura referenciada em: Srivastava, N., Hinton, G., Krizhevsky, A., Krizhevsky, I., Salakhutdinov, R., Dropout: A Simple Way to Prevent Neural Networks from Overfitting, Figura 9
Usei o TensorFlow para executar o dropout no conjunto de dados MNIST, Matplotlib para ajudar na recriação da figura no artigo. Também usei uma biblioteca Decimal integrada para calcular os diferentes valores de p, de 0,0 a 1,0. A biblioteca "csv" foi importada para adicionar dados previamente executados em um arquivo CSV, para economizar tempo no cálculo dos valores já calculados de p. Numpy foi importado para fazer com que a plotagem tivesse o mesmo tamanho de passo nos eixos xey. Por último, importei "os" para poder me livrar de um erro devido ao uso de uma CPU em vez de uma GPU.
Explorar os efeitos dos valores variados do hiperparâmetro ajustável 'p' (a probabilidade de reter uma unidade na rede) e do número de camadas ocultas, 'n', que afetam as taxas de erro. Quando o produto de p e n é fixo, podemos ver que a magnitude do erro para pequenos valores de p foi reduzida (fig. 9a) em comparação com a manutenção constante do número de camadas ocultas (fig. 9b).
Com dados de treinamento limitados, muitas relações complicadas entre entradas/saídas serão resultado do ruído de amostragem. Eles existirão no conjunto de treinamento, mas não em dados de teste reais, mesmo que sejam extraídos da mesma distribuição. Essa complicação leva ao overfitting, este é um dos algoritmos que ajuda a evitar que isso ocorra. A entrada para esta figura é um conjunto de dados de dígitos manuscritos, e a saída após adicionar o abandono são valores diferentes que descrevem o resultado da aplicação do método de abandono. Em suma, o resultado é menos erro após adicionar o abandono.
Um problema do mundo real ao qual isso pode se aplicar é a pesquisa no Google. Alguém pode estar procurando o título de um filme, mas pode estar procurando apenas imagens porque aprende mais visualmente. Portanto, eliminar as partes textuais ou breves explicações ajudará você a se concentrar nos recursos da imagem. O artigo indica de onde eles recuperam os dados (http://yann.lecun.com/exdb/mnist/). Cada imagem é uma representação de 28x28 dígitos. Os rótulos y parecem ser as colunas de dados da imagem.
Meu objetivo ao reproduzir esta figura é testar/treinar os dados e calcular o erro de classificação para cada probabilidade de p (probabilidade de reter uma unidade na rede). Meu objetivo é fazer com que p aumente à medida que o erro diminui para mostrar que minha implementação é válida, e ajustarei esse hiperparâmetro para obter o mesmo resultado. Farei isso percorrendo todos os dados de treinamento e teste usando uma arquitetura 784-2048-2048-2048-10 e manterei n fixo e depois alterarei pn para ser corrigido. Em seguida, reunirei/gravarei os dados em um arquivo csv. Este arquivo csv conterá todos os dados necessários para gerar os números. Neste projeto, aprenderei como a taxa de abandono pode beneficiar o erro geral em uma rede neural.
Clique para visualizar


