LaTeX OCR
1.0.0
O objetivo deste projeto é criar um sistema baseado em aprendizagem que pegue uma imagem de uma fórmula matemática e retorne o código LaTeX correspondente.
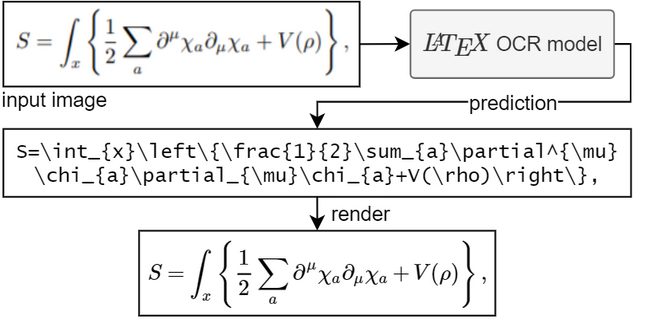
Para executar o modelo você precisa do Python 3.7+
Se você não tiver o PyTorch instalado. Siga as instruções aqui.
Instale o pacote pix2tex :
pip install "pix2tex[gui]"
Os pontos de verificação do modelo serão baixados automaticamente.
Existem três maneiras de obter uma previsão de uma imagem.
Você pode usar a ferramenta de linha de comando chamando pix2tex . Aqui você pode analisar imagens já existentes no disco e imagens na sua área de transferência.
Graças a @katie-lim, você pode usar uma interface de usuário agradável como uma maneira rápida de obter a previsão do modelo. Basta chamar a GUI com latexocr . A partir daqui você pode fazer uma captura de tela e o código de látex previsto é renderizado usando MathJax e copiado para sua área de transferência.
No Linux, é possível usar a GUI com gnome-screenshot (que vem com suporte para vários monitores) se gnome-screenshot tiver sido instalado anteriormente. Para Wayland, grim e slurp serão usados quando ambos estiverem disponíveis. Observe que gnome-screenshot não é compatível com compositores Wayland baseados em wlroots. Como gnome-screenshot será preferido quando disponível, talvez seja necessário definir a variável de ambiente SCREENSHOT_TOOL como grim neste caso (outros valores disponíveis são gnome-screenshot e pil ).
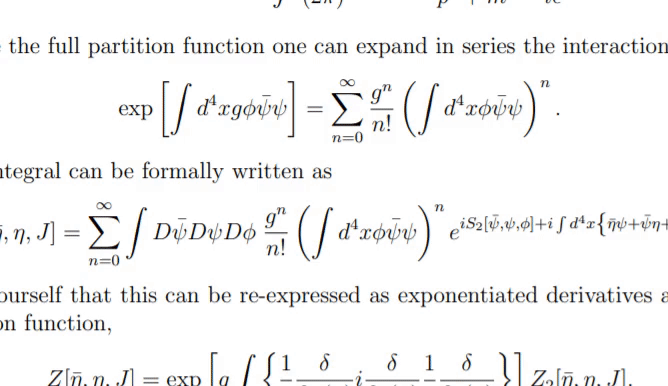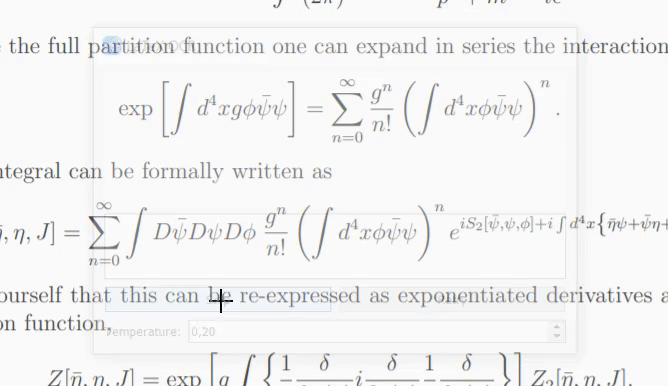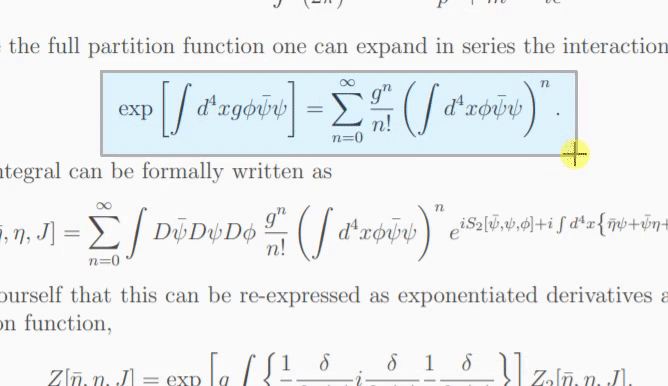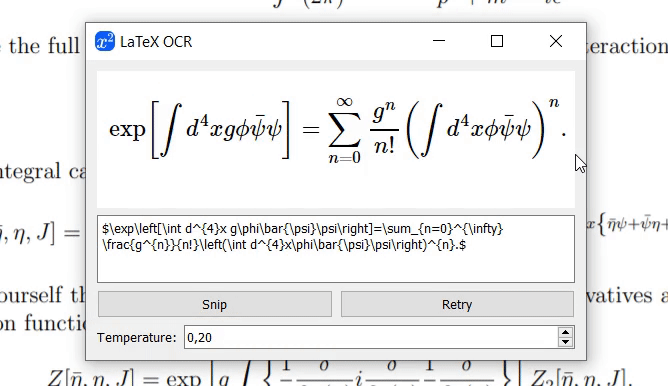
Se o modelo não tiver certeza sobre o que está na imagem, ele poderá gerar uma previsão diferente toda vez que você clicar em "Tentar novamente". Com o parâmetro temperature você pode controlar esse comportamento (baixa temperatura produzirá o mesmo resultado).
Você pode usar uma API. Isso tem dependências adicionais. Instale via pip install -U "pix2tex[api]" e execute
python -m pix2tex.api.run
para iniciar uma demonstração Streamlit que se conecta à API na porta 8502. Há também uma imagem docker disponível para a API: https://hub.docker.com/r/lukasblecher/pix2tex
docker pull lukasblecher/pix2tex:api docker run --rm -p 8502:8502 lukasblecher/pix2tex:api
Para executar também a demonstração streamlit, execute
docker run --rm -it -p 8501:8501 --entrypoint python lukasblecher/pix2tex:api pix2tex/api/run.py
e navegue até http://localhost:8501/
Use de dentro do Python
de PIL importar imagem de pix2tex.cli importar LatexOCRimg = Image.open('caminho/para/image.png')model = LatexOCR()print(model(img))O modelo funciona melhor com imagens de resolução menor. É por isso que adicionei uma etapa de pré-processamento onde outra rede neural prevê a resolução ideal da imagem de entrada. Este modelo redimensionará automaticamente a imagem personalizada para melhor se assemelhar aos dados de treinamento e, assim, aumentar o desempenho das imagens encontradas em estado selvagem. Ainda assim, não é perfeito e pode não ser capaz de lidar com imagens enormes de maneira ideal, portanto, não aumente totalmente o zoom antes de tirar uma foto.
Sempre verifique o resultado com cuidado. Você pode tentar refazer a previsão com outra resolução se a resposta estiver errada.
Quer usar o pacote?
Estou tentando compilar uma documentação agora.
Acesse aqui: https://pix2tex.readthedocs.io/
Instale algumas dependências pip install "pix2tex[train]" .
Primeiro, precisamos combinar as imagens com seus rótulos verdadeiros. Eu escrevi uma classe de conjunto de dados (que precisa ser melhorada ainda mais) que salva os caminhos relativos às imagens com o código LaTeX com o qual foram renderizadas. Para gerar o arquivo pickle do conjunto de dados, execute
python -m pix2tex.dataset.dataset --equations path_to_textfile --images path_to_images --out dataset.pkl
Para usar seu próprio tokenizer, passe-o via --tokenizer (veja abaixo).
Você também pode encontrar meus dados de treinamento gerados no Google Drive (formulae.zip - imagens, math.txt - rótulos). Repita a etapa para os dados de validação e teste. Todos usam o mesmo arquivo de texto de etiqueta.
Edite a entrada data (e valdata ) no arquivo de configuração para o arquivo .pkl recém-gerado. Altere outros hiperparâmetros se desejar. Consulte pix2tex/model/settings/config.yaml para obter um modelo.
Agora, para o treinamento real
python -m pix2tex.train --config path_to_config_file
Se quiser usar seus próprios dados, você pode estar interessado em criar seu próprio tokenizer com
python -m pix2tex.dataset.dataset --equations path_to_textfile --vocab-size 8000 --out tokenizer.json
Não se esqueça de atualizar o caminho para o tokenizer no arquivo de configuração e definir num_tokens para o tamanho do seu vocabulário.
O modelo consiste em um codificador ViT [1] com um backbone ResNet e um decodificador Transformer [2].
| Pontuação BLEU | distância de edição normada | precisão do token |
|---|---|---|
| 0,88 | 0,10 | 0,60 |
Precisamos de dados emparelhados para que a rede aprenda. Felizmente há muito código LaTeX na internet, por exemplo, wikipedia, arXiv. Também usamos as fórmulas do conjunto de dados im2latex-100k [3]. Tudo isso você encontra aqui
Para renderizar a matemática em muitas fontes diferentes, usamos XeLaTeX, geramos um PDF e finalmente o convertemos para PNG. Para a última etapa, precisamos usar algumas ferramentas de terceiros:
XeLaTeX
ImageMagick com Ghostscript. (para converter pdf em png)
Node.js para executar KaTeX (para normalizar o código Latex)
Python 3.7+ e dependências (especificadas em setup.py )
Matemática Moderna Latina, GFSNeohellenicMath.otf, Asana Math, XITS Math, Cambria Math
adicione mais métricas de avaliação
criar uma interface gráfica
adicionar pesquisa de feixe
suporta fórmulas manuscritas (mais ou menos concluídas, consulte o caderno de treinamento colab)
reduzir o tamanho do modelo (destilação)
encontrar hiperparâmetros ideais
ajustar a estrutura do modelo
corrigir a raspagem de dados e extrair mais dados
trace o modelo (#2)
Contribuições de qualquer tipo são bem-vindas.
Código retirado e modificado de lucidrains, rwightman, im2markup, arxiv_leaks, pkra: Mathjax, harupy: ferramenta de recorte
[1] Uma imagem vale 16x16 palavras
[2] Atenção é tudo que você precisa
[3] Geração de imagem para marcação com atenção grosseira a fina


