segment anything
1.0.0
Confira nosso novo lançamento no Segment Anything Model 2 (SAM 2) .
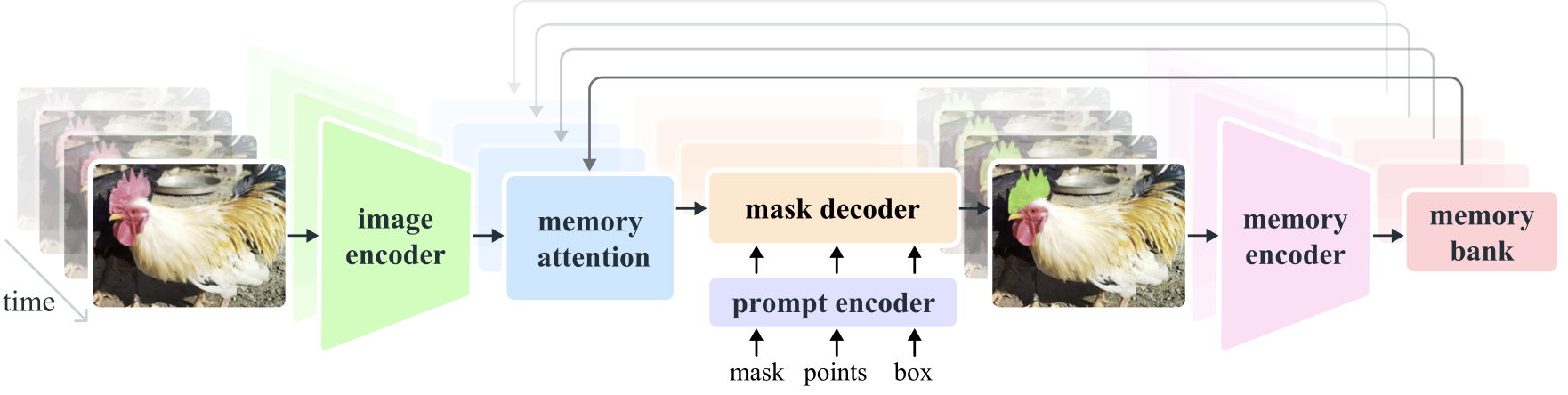
Segment Anything Model 2 (SAM 2) é um modelo básico para resolver a segmentação visual imediata em imagens e vídeos. Estendemos o SAM ao vídeo considerando as imagens como um vídeo com um único quadro. O design do modelo é uma arquitetura simples de transformador com memória de streaming para processamento de vídeo em tempo real. Construímos um mecanismo de dados model-in-the-loop, que melhora o modelo e os dados por meio da interação do usuário, para coletar nosso conjunto de dados SA-V , o maior conjunto de dados de segmentação de vídeo até o momento. O SAM 2 treinado com nossos dados oferece forte desempenho em uma ampla variedade de tarefas e domínios visuais.
Pesquisa Meta AI, FAIR
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick
[ Paper ] [ Project ] [ Demo ] [ Dataset ] [ Blog ] [ BibTeX ]
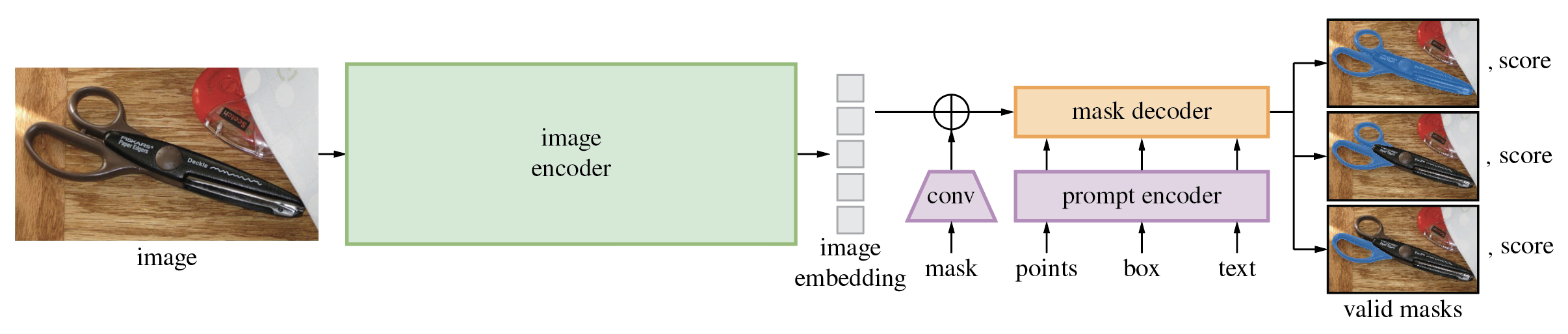
O Segment Anything Model (SAM) produz máscaras de objetos de alta qualidade a partir de prompts de entrada, como pontos ou caixas, e pode ser usado para gerar máscaras para todos os objetos em uma imagem. Ele foi treinado em um conjunto de dados de 11 milhões de imagens e 1,1 bilhão de máscaras e possui forte desempenho de disparo zero em diversas tarefas de segmentação.


O código requer python>=3.8 , bem como pytorch>=1.7 e torchvision>=0.8 . Siga as instruções aqui para instalar as dependências PyTorch e TorchVision. É altamente recomendável instalar PyTorch e TorchVision com suporte CUDA.
Instale qualquer segmento:
pip install git+https://github.com/facebookresearch/segment-anything.git
ou clone o repositório localmente e instale com
git clone [email protected]:facebookresearch/segment-anything.git
cd segment-anything; pip install -e .
As dependências opcionais a seguir são necessárias para o pós-processamento da máscara, salvando as máscaras no formato COCO, os notebooks de exemplo e exportando o modelo no formato ONNX. jupyter também é necessário para executar os notebooks de exemplo.
pip install opencv-python pycocotools matplotlib onnxruntime onnx
Primeiro baixe um ponto de verificação do modelo. Então o modelo pode ser usado em apenas algumas linhas para obter máscaras de um determinado prompt:
from segment_anything import SamPredictor, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
predictor = SamPredictor(sam)
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)
ou gere máscaras para uma imagem inteira:
from segment_anything import SamAutomaticMaskGenerator, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(<your_image>)
Além disso, máscaras podem ser geradas para imagens na linha de comando:
python scripts/amg.py --checkpoint <path/to/checkpoint> --model-type <model_type> --input <image_or_folder> --output <path/to/output>
Veja os cadernos de exemplos sobre como usar o SAM com prompts e gerar máscaras automaticamente para obter mais detalhes.


O decodificador de máscara leve do SAM pode ser exportado para o formato ONNX para que possa ser executado em qualquer ambiente que suporte o tempo de execução ONNX, como no navegador, conforme apresentado na demonstração. Exporte o modelo com
python scripts/export_onnx_model.py --checkpoint <path/to/checkpoint> --model-type <model_type> --output <path/to/output>
Consulte o caderno de exemplo para obter detalhes sobre como combinar o pré-processamento de imagem por meio do backbone do SAM com a previsão de máscara usando o modelo ONNX. Recomenda-se usar a versão estável mais recente do PyTorch para exportação ONNX.
A pasta demo/ possui um aplicativo React simples de uma página que mostra como executar a previsão de máscara com o modelo ONNX exportado em um navegador da web com multithreading. Consulte demo/README.md para obter mais detalhes.
Três versões do modelo estão disponíveis com diferentes tamanhos de backbone. Esses modelos podem ser instanciados executando
from segment_anything import sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
Clique nos links abaixo para baixar o ponto de verificação para o tipo de modelo correspondente.
default ou vit_h : modelo ViT-H SAM.vit_l : modelo ViT-L SAM.vit_b : modelo SAM ViT-B. Veja aqui uma visão geral do datastet. O conjunto de dados pode ser baixado aqui. Ao baixar os conjuntos de dados, você concorda que leu e aceitou os termos da Licença de Pesquisa de Conjunto de Dados SA-1B.
Salvamos máscaras por imagem como um arquivo json. Ele pode ser carregado como um dicionário em python no formato abaixo.
{
"image" : image_info ,
"annotations" : [ annotation ],
}
image_info {
"image_id" : int , # Image id
"width" : int , # Image width
"height" : int , # Image height
"file_name" : str , # Image filename
}
annotation {
"id" : int , # Annotation id
"segmentation" : dict , # Mask saved in COCO RLE format.
"bbox" : [ x , y , w , h ], # The box around the mask, in XYWH format
"area" : int , # The area in pixels of the mask
"predicted_iou" : float , # The model's own prediction of the mask's quality
"stability_score" : float , # A measure of the mask's quality
"crop_box" : [ x , y , w , h ], # The crop of the image used to generate the mask, in XYWH format
"point_coords" : [[ x , y ]], # The point coordinates input to the model to generate the mask
}Os IDs das imagens podem ser encontrados em sa_images_ids.txt, que também pode ser baixado usando o link acima.
Para decodificar uma máscara no formato COCO RLE em binário:
from pycocotools import mask as mask_utils
mask = mask_utils.decode(annotation["segmentation"])
Veja aqui mais instruções para manipular máscaras armazenadas no formato RLE.
O modelo é licenciado sob a licença Apache 2.0.
Veja contribuições e o código de conduta.
O projeto Segment Anything foi possível com a ajuda de vários colaboradores (em ordem alfabética):
Aaron Adcock, Vaibhav Aggarwal, Morteza Behrooz, Cheng-Yang Fu, Ashley Gabriel, Ahuva Goldstand, Allen Goodman, Sumanth Gurram, Jiabo Hu, Somya Jain, Devansh Kukreja, Robert Kuo, Joshua Lane, Yanghao Li, Lilian Luong, Jitendra Malik, Mallika Malhotra, William Ngan, Omkar Parkhi, Nikhil Raina, Dirk Rowe, Neil Sejoor, Vanessa Stark, Bala Varadarajan, Bram Wasti, Zachary Winstrom
Se você usar SAM ou SA-1B em sua pesquisa, use a seguinte entrada do BibTeX.
@article{kirillov2023segany,
title={Segment Anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{'a}r, Piotr and Girshick, Ross},
journal={arXiv:2304.02643},
year={2023}
}


