obfuscated gradients
v1.0.0
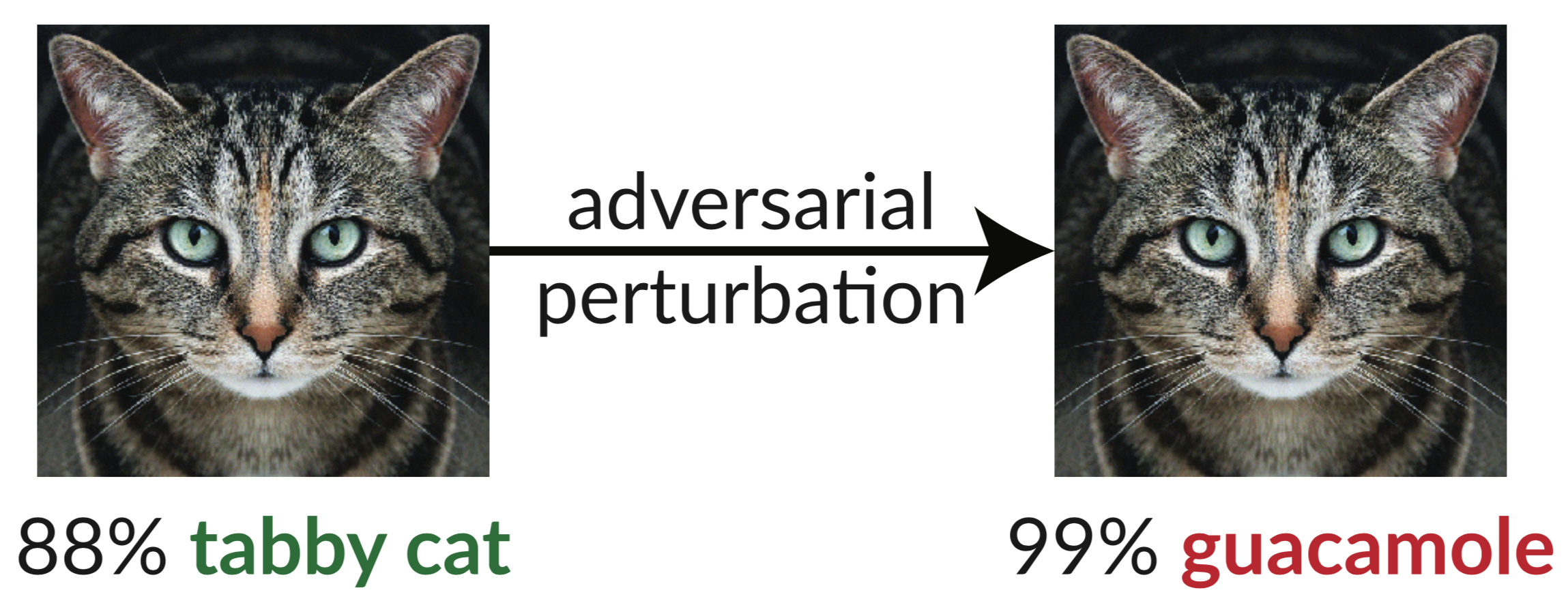
Acima está um exemplo contraditório: a imagem ligeiramente perturbada do gato engana um classificador InceptionV3 fazendo-o classificá-lo como "guacamole". Essas "imagens enganosas" são fáceis de sintetizar usando gradiente descendente (Szegedy et al. 2013).
Em nosso artigo recente, avaliamos a robustez de nove artigos aceitos no ICLR 2018 como defesas seguras de caixa branca não certificadas para exemplos adversários. Descobrimos que sete das nove defesas proporcionam um aumento limitado na robustez e podem ser quebradas por técnicas de ataque melhoradas que desenvolvemos.
Abaixo está a Tabela 1 do nosso artigo, onde mostramos a robustez de cada defesa aceita para os exemplos adversários que podemos construir:
| Defesa | Conjunto de dados | Distância | Precisão |
|---|---|---|---|
| Buckman et al. (2018) | CIFAR | 0,031 (linf) | 0%* |
| Ma et al. (2018) | CIFAR | 0,031 (linf) | 5% |
| Guo et al. (2018) | ImageNet | 0,05 (l2) | 0%* |
| Dhillon et al. (2018) | CIFAR | 0,031 (linf) | 0% |
| Xie et al. (2018) | ImageNet | 0,031 (linf) | 0%* |
| Canção et al. (2018) | CIFAR | 0,031 (linf) | 9%* |
| Samangoei et al. (2018) | MNIST | 0,005 (l2) | 55%** |
| Madry et al. (2018) | CIFAR | 0,031 (linf) | 47% |
| Na et al. (2018) | CIFAR | 0,015 (linf) | 15% |
(As defesas indicadas com * também propõem combinar o treinamento adversário; relatamos aqui apenas a defesa. Veja nosso artigo, Seção 5, para obter os números completos. O princípio fundamental por trás da defesa indicada com ** tem 0% de precisão; na prática, as imperfeições da defesa causam o teoricamente ataque ideal falhe, consulte a Seção 5.4.2 para obter detalhes.)
A única defesa que observamos que aumenta significativamente a robustez a exemplos adversários dentro do modelo de ameaça proposto é "Rumo a modelos de aprendizagem profunda resistentes a ataques adversários" (Madry et al. 2018), e não fomos capazes de derrotar esta defesa sem sair do modelo de ameaça . Mesmo assim, esta técnica demonstrou ser difícil de escalar para a escala ImageNet (Kurakin et al. 2016). O restante dos artigos (além do artigo de Na et al., que fornece robustez limitada) baseia-se inadvertidamente ou intencionalmente no que chamamos de gradientes ofuscados . Os ataques padrão aplicam gradiente descendente para maximizar a perda da rede em uma determinada imagem para gerar um exemplo adversário em uma rede neural. Tais métodos de otimização requerem um sinal de gradiente útil para serem bem-sucedidos. Quando uma defesa ofusca gradientes, ela quebra esse sinal de gradiente e faz com que os métodos baseados em otimização falhem.
Identificamos três maneiras pelas quais as defesas causam gradientes ofuscados e construímos ataques para contornar cada um desses casos. Nossos ataques são geralmente aplicáveis a qualquer defesa que inclua, intencionalmente ou não, uma operação não diferenciável ou que de outra forma impeça o fluxo do sinal gradiente através da rede. Esperamos que trabalhos futuros possam usar nossas abordagens para realizar uma avaliação de segurança mais completa.
Resumo:
Identificamos gradientes ofuscados, uma espécie de mascaramento de gradiente, como um fenômeno que leva a uma falsa sensação de segurança nas defesas contra exemplos adversários. Embora as defesas que causam gradientes ofuscados pareçam derrotar os ataques iterativos baseados em otimização, descobrimos que as defesas que dependem desse efeito podem ser contornadas. Descrevemos comportamentos característicos de defesas que exibem o efeito e, para cada um dos três tipos de gradientes ofuscados que descobrimos, desenvolvemos técnicas de ataque para superá-los. Em um estudo de caso, examinando defesas seguras de caixa branca não certificadas no ICLR 2018, descobrimos que gradientes ofuscados são uma ocorrência comum, com 7 de 9 defesas contando com gradientes ofuscados. Nossos novos ataques contornam com sucesso 6 completamente e 1 parcialmente no modelo de ameaça original que cada artigo considera.
Para obter detalhes, leia nosso artigo.
Este repositório contém nossas instanciações das técnicas gerais de ataque descritas em nosso artigo, quebrando 7 das defesas do ICLR 2018. Algumas das defesas não liberavam código-fonte (na época em que fizemos este trabalho), então tivemos que reimplementá-las.
@inproceedings{gradientes ofuscados, autor = {Anish Athalye e Nicholas Carlini e David Wagner}, título = {gradientes ofuscados dão uma falsa sensação de segurança: contornando defesas para exemplos adversários}, booktitle = {Proceedings of the 35th International Conference on Machine Aprendizagem, {ICML} 2018}, ano = {2018}, mês = julho, url = {https://arxiv.org/abs/1802.00420},
} 

