Megatron LM
NVIDIA Megatron Core 0.9.0
Este repositório compreende dois componentes essenciais: Megatron-LM e Megatron-Core . Megatron-LM serve como uma estrutura orientada para pesquisa que aproveita o Megatron-Core para treinamento de modelo de linguagem grande (LLM). Megatron-Core, por outro lado, é uma biblioteca de técnicas de treinamento otimizadas para GPU que vem com suporte formal ao produto, incluindo APIs versionadas e lançamentos regulares. Você pode usar Megatron-Core junto com Megatron-LM ou Nvidia NeMo Framework para uma solução ponta a ponta e nativa da nuvem. Alternativamente, você pode integrar os blocos de construção do Megatron-Core em sua estrutura de treinamento preferida.
Introduzido pela primeira vez em 2019, Megatron (1, 2 e 3) desencadeou uma onda de inovação na comunidade de IA, permitindo que pesquisadores e desenvolvedores utilizassem os fundamentos desta biblioteca para promover avanços no LLM. Hoje, muitas das estruturas de desenvolvedor LLM mais populares foram inspiradas e construídas diretamente aproveitando a biblioteca Megatron-LM de código aberto, estimulando uma onda de modelos básicos e startups de IA. Algumas das estruturas LLM mais populares construídas sobre Megatron-LM incluem Colossal-AI, HuggingFace Accelerate e NVIDIA NeMo Framework. Uma lista de projetos que usaram Megatron diretamente pode ser encontrada aqui.
Megatron-Core é uma biblioteca de código aberto baseada em PyTorch que contém técnicas otimizadas para GPU e otimizações de última geração em nível de sistema. Ele os abstrai em APIs combináveis e modulares, permitindo total flexibilidade para desenvolvedores e pesquisadores de modelos treinarem transformadores personalizados em escala na infraestrutura de computação acelerada da NVIDIA. Esta biblioteca é compatível com todas as GPUs NVIDIA Tensor Core, incluindo suporte de aceleração FP8 para arquiteturas NVIDIA Hopper.
Megatron-Core oferece blocos de construção básicos, como mecanismos de atenção, blocos e camadas transformadoras, camadas de normalização e técnicas de incorporação. Funcionalidades adicionais, como recálculo de ativação e pontos de verificação distribuídos, também estão nativamente integradas à biblioteca. Os blocos de construção e a funcionalidade são todos otimizados para GPU e podem ser desenvolvidos com estratégias avançadas de paralelização para velocidade e estabilidade de treinamento ideais na infraestrutura de computação acelerada da NVIDIA. Outro componente chave da biblioteca Megatron-Core inclui técnicas avançadas de paralelismo de modelo (tensor, sequência, pipeline, contexto e paralelismo especializado em MoE).
Megatron-Core pode ser usado com NVIDIA NeMo, uma plataforma de IA de nível empresarial. Alternativamente, você pode explorar o Megatron-Core com o loop de treinamento PyTorch nativo aqui. Visite a documentação do Megatron-Core para saber mais.
Nossa base de código é capaz de treinar com eficiência grandes modelos de linguagem (ou seja, modelos com centenas de bilhões de parâmetros) com paralelismo de modelo e de dados. Para demonstrar como nosso software é dimensionado com diversas GPUs e tamanhos de modelo, consideramos modelos GPT que variam de 2 bilhões a 462 bilhões de parâmetros. Todos os modelos usam um tamanho de vocabulário de 131.072 e um comprimento de sequência de 4.096. Variamos o tamanho oculto, o número de cabeças de atenção e o número de camadas para chegar a um tamanho de modelo específico. À medida que o tamanho do modelo aumenta, também aumentamos modestamente o tamanho do lote. Nossos experimentos usam até 6.144 GPUs H100. Realizamos sobreposição refinada de dados paralelos ( --overlap-grad-reduce --overlap-param-gather ), tensor-paralelo ( --tp-comm-overlap ) e comunicação paralela de pipeline (habilitada por padrão) com computação para melhorar a escalabilidade. Os rendimentos relatados são medidos para treinamento completo e incluem todas as operações, incluindo carregamento de dados, etapas do otimizador, comunicação e até mesmo registro. Observe que não treinamos esses modelos para convergência.
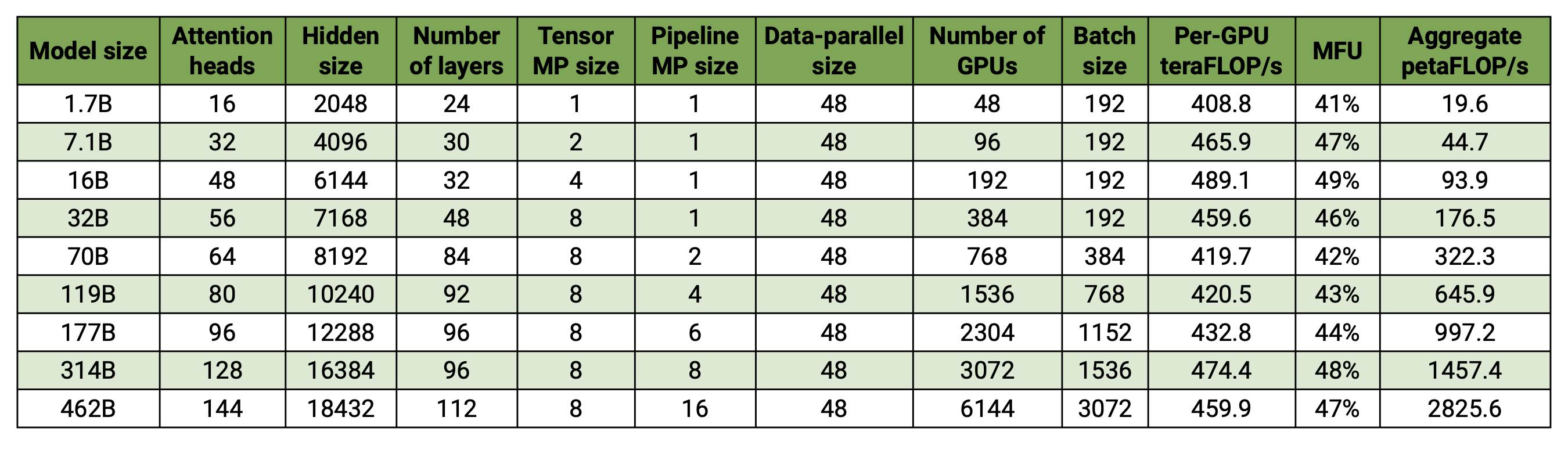
Nossos resultados em escala fraca mostram escala superlinear (MFU aumenta de 41% para o modelo menor considerado para 47-48% para os modelos maiores); isso ocorre porque GEMMs maiores têm maior intensidade aritmética e são, conseqüentemente, mais eficientes de executar.
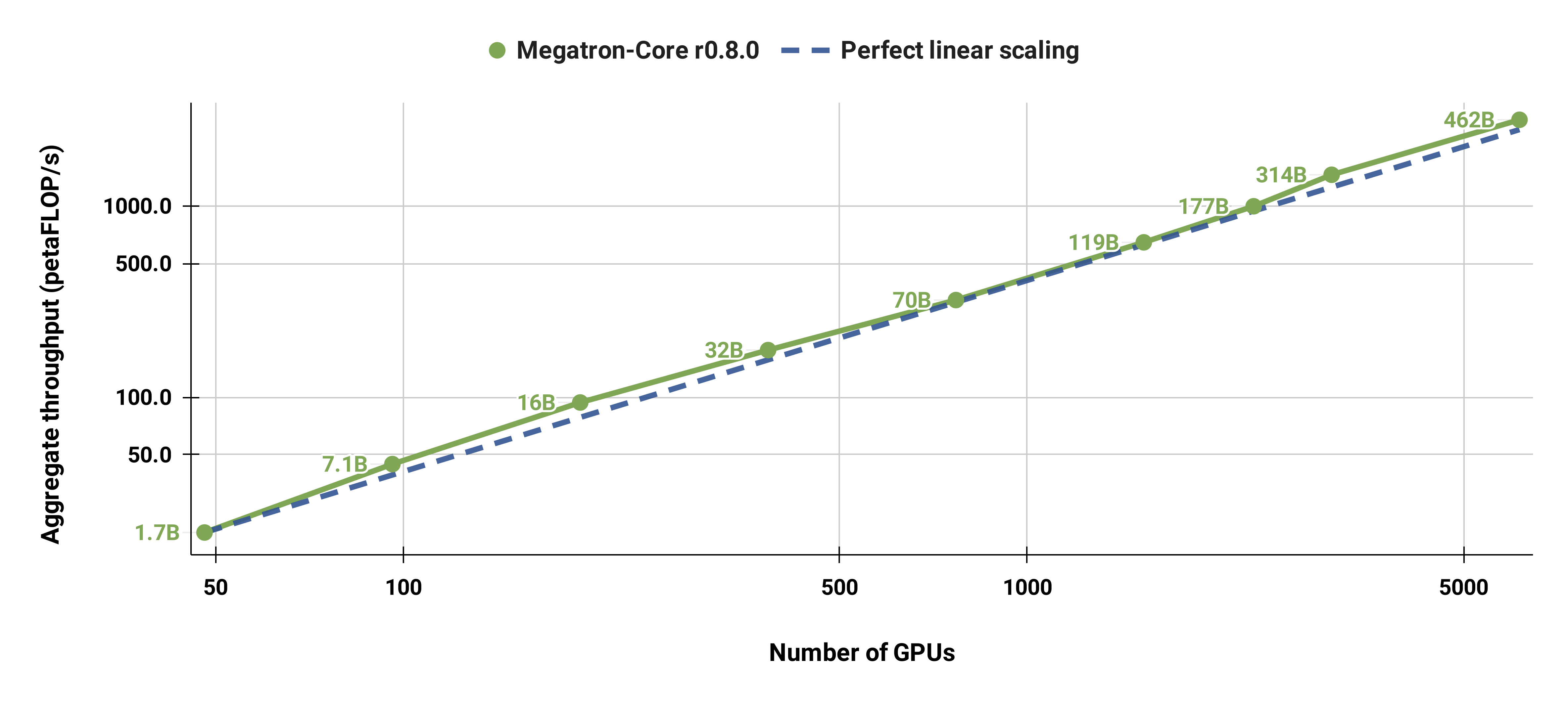
Também dimensionamos fortemente o modelo GPT-3 padrão (nossa versão tem pouco mais de 175 bilhões de parâmetros devido ao tamanho maior do vocabulário) de 96 GPUs H100 para 4.608 GPUs, usando o mesmo tamanho de lote de 1.152 sequências. A comunicação fica mais exposta em maior escala, levando a uma redução na MFU de 47% para 42%.
Recomendamos fortemente o uso da versão mais recente do contêiner PyTorch do NGC com nós DGX. Se você não puder usar isso por algum motivo, use as versões mais recentes do pytorch, cuda, nccl e NVIDIA APEX. O pré-processamento de dados requer NLTK, embora isso não seja necessário para treinamento, avaliação ou tarefas posteriores.
Você pode iniciar uma instância do contêiner PyTorch e montar o Megatron, seu conjunto de dados e pontos de verificação com os seguintes comandos do Docker:
docker pull nvcr.io/nvidia/pytorch:xx.xx-py3
docker run --gpus all -it --rm -v /path/to/megatron:/workspace/megatron -v /path/to/dataset:/workspace/dataset -v /path/to/checkpoints:/workspace/checkpoints nvcr.io/nvidia/pytorch:xx.xx-py3
Fornecemos pontos de verificação pré-treinados BERT-345M e GPT-345M para avaliar ou ajustar tarefas downstream. Para acessar esses pontos de verificação, primeiro inscreva-se e configure a CLI do registro NVIDIA GPU Cloud (NGC). Documentação adicional para download de modelos pode ser encontrada na documentação do NGC.
Alternativamente, você pode baixar diretamente os pontos de verificação usando:
BERT-345M-uncased: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_uncased/zip -O megatron_bert_345m_v0.1_uncased.zip BERT-345M-cased: wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_cased/zip -O megatron_bert_345m_v0.1_cased.zip GPT-345M: wget --disposição de conteúdo https://api.ngc.nvidia.com/v2/models/nvidia/megatron_lm_345m/versions/v0.0/zip -O megatron_lm_345m_v0.0.zip
Os modelos requerem arquivos de vocabulário para serem executados. O arquivo de vocabulário BERT WordPiece pode ser extraído dos modelos BERT pré-treinados do Google: uncased, cased. O arquivo de vocabulário GPT e a tabela de mesclagem podem ser baixados diretamente.
Após a instalação, existem vários fluxos de trabalho possíveis. O mais abrangente é:
No entanto, as etapas 1 e 2 podem ser substituídas pelo uso de um dos modelos pré-treinados mencionados acima.
Fornecemos vários scripts para pré-treinamento de BERT e GPT no diretório examples , bem como scripts para tarefas downstream de tiro zero e de ajuste fino, incluindo avaliação de MNLI, RACE, WikiText103 e LAMBADA. Há também um script para geração de texto interativo GPT.
Os dados de treinamento requerem pré-processamento. Primeiro, coloque seus dados de treinamento em um formato json flexível, com um json contendo uma amostra de texto por linha. Por exemplo:
{"src": "www.nvidia.com", "text": "A rápida raposa marrom", "type": "Eng", "id": "0", "title": "Primeira parte"}
{"src": "A Internet", "text": "pula sobre o cachorro preguiçoso", "type": "Eng", "id": "42", "title": "Segunda parte"}
O nome do campo text do json pode ser alterado usando o sinalizador --json-key em preprocess_data.py Os outros metadados são opcionais e não são usados no treinamento.
O json solto é então processado em um formato binário para treinamento. Para converter o json para o formato mmap, use preprocess_data.py . Um exemplo de script para preparar dados para treinamento de BERT é:
ferramentas python/preprocess_data.py
--input meu-corpus.json
--output-prefix meu-bert
--arquivo vocab bert-vocab.txt
--tokenizer-type BertWordPieceLowerCase
--frases divididas
A saída serão dois arquivos nomeados, neste caso, my-bert_text_sentence.bin e my-bert_text_sentence.idx . O --data-path especificado no treinamento posterior do BERT é o caminho completo e o novo nome do arquivo, mas sem a extensão do arquivo.
Para T5 use o mesmo pré-processamento do BERT, talvez renomeando-o para:
--prefixo de saída meu-t5
Algumas pequenas modificações são necessárias para o pré-processamento de dados GPT, nomeadamente, a adição de uma tabela de mesclagem, um token de final de documento, remoção da divisão de frase e uma alteração no tipo de tokenizador:
ferramentas python/preprocess_data.py
--input meu-corpus.json
--prefixo de saída meu-gpt2
--arquivo vocab gpt2-vocab.json
--tokenizer-type GPT2BPETokenizer
--merge-file gpt2-merges.txt
--append-eod
Aqui, os arquivos de saída são denominados my-gpt2_text_document.bin e my-gpt2_text_document.idx . Como antes, no treinamento GPT, use o nome mais longo sem a extensão como --data-path .
Outros argumentos de linha de comando são descritos no arquivo de origem preprocess_data.py .
O script examples/bert/train_bert_340m_distributed.sh executa o pré-treinamento de BERT de parâmetro único da GPU 345M. A depuração é o principal uso para treinamento de GPU única, pois a base de código e os argumentos da linha de comando são otimizados para treinamento altamente distribuído. A maioria dos argumentos é bastante autoexplicativa. Por padrão, a taxa de aprendizado decai linearmente ao longo das iterações de treinamento começando em --lr até um mínimo definido por --min-lr sobre --lr-decay-iters iterações. A fração de iterações de treinamento usadas para aquecimento é definida por --lr-warmup-fraction . Embora este seja um treinamento de GPU único, o tamanho do lote especificado por --micro-batch-size é um tamanho de lote de caminho único para frente e para trás e o código executará etapas de acumulação de gradiente até atingir o global-batch-size que é o tamanho do lote por iteração. Os dados são particionados em uma proporção de 949:50:1 para conjuntos de treinamento/validação/teste (o padrão é 969:30:1). Esse particionamento acontece dinamicamente, mas é consistente em execuções com a mesma semente aleatória (1234 por padrão ou especificada manualmente com --seed ). Usamos train-iters conforme as iterações de treinamento solicitadas. Alternativamente, pode-se fornecer --train-samples que é o número total de amostras para treinar. Se esta opção estiver presente, em vez de fornecer --lr-decay-iters , será necessário fornecer --lr-decay-samples .
As opções de registro em log, salvamento de pontos de verificação e intervalo de avaliação são especificadas. Observe que --data-path agora inclui o sufixo _text_sentence adicional adicionado no pré-processamento, mas não inclui as extensões de arquivo.
Outros argumentos de linha de comando são descritos no arquivo de origem arguments.py .
Para executar train_bert_340m_distributed.sh , faça as modificações desejadas, incluindo a configuração das variáveis de ambiente para CHECKPOINT_PATH , VOCAB_FILE e DATA_PATH . Certifique-se de definir essas variáveis para seus caminhos no contêiner. Em seguida, inicie o contêiner com Megatron e os caminhos necessários montados (conforme explicado em Configuração) e execute o script de exemplo.
O script examples/gpt3/train_gpt3_175b_distributed.sh executa o pré-treinamento GPT de parâmetro único da GPU 345M. Conforme mencionado acima, o treinamento de GPU única destina-se principalmente a fins de depuração, pois o código é otimizado para treinamento distribuído.
Ele segue basicamente o mesmo formato do script BERT anterior com algumas diferenças notáveis: o esquema de tokenização usado é BPE (que requer uma tabela de mesclagem e um arquivo de vocabulário json ) em vez de WordPiece, a arquitetura do modelo permite sequências mais longas (observe que o a incorporação da posição máxima deve ser maior ou igual ao comprimento máximo da sequência) e o --lr-decay-style foi definido para decaimento de cosseno. Observe que --data-path agora inclui o sufixo _text_document adicional adicionado no pré-processamento, mas não inclui as extensões de arquivo.
Outros argumentos de linha de comando são descritos no arquivo de origem arguments.py .
train_gpt3_175b_distributed.sh pode ser iniciado da mesma forma descrita para o BERT. Defina os env vars e faça quaisquer outras modificações, inicie o contêiner com montagens apropriadas e execute o script. Mais detalhes em examples/gpt3/README.md
Muito semelhante ao BERT e GPT, o script examples/t5/train_t5_220m_distributed.sh executa o pré-treinamento T5 de "base" de GPU única (parâmetro ~ 220M). A principal diferença do BERT e do GPT é a adição dos seguintes argumentos para acomodar a arquitetura T5:
--kv-channels define a dimensão interna das matrizes "chave" e "valor" de todos os mecanismos de atenção no modelo. Para BERT e GPT, o padrão é o tamanho oculto dividido pelo número de cabeças de atenção, mas pode ser configurado para T5.
--ffn-hidden-size define o tamanho oculto nas redes feed-forward dentro de uma camada de transformador. Para BERT e GPT o padrão é 4 vezes o tamanho oculto do transformador, mas pode ser configurado para T5.
--encoder-seq-length e --decoder-seq-length definem o comprimento da sequência para o codificador e o decodificador separadamente.
Todos os outros argumentos permanecem os mesmos para o pré-treinamento de BERT e GPT. Execute este exemplo com as mesmas etapas descritas acima para os outros scripts.
Mais detalhes em examples/t5/README.md
Os scripts pretrain_{bert,gpt,t5}_distributed.sh usam o iniciador distribuído PyTorch para treinamento distribuído. Como tal, o treinamento de vários nós pode ser alcançado definindo adequadamente as variáveis de ambiente. Consulte a documentação oficial do PyTorch para uma descrição mais detalhada dessas variáveis de ambiente. Por padrão, o treinamento de vários nós usa o back-end distribuído nccl. Um conjunto simples de argumentos adicionais e o uso do módulo distribuído PyTorch com o lançador elástico torchrun (equivalente a python -m torch.distributed.run ) são os únicos requisitos adicionais para adotar o treinamento distribuído. Consulte qualquer um dos pretrain_{bert,gpt,t5}_distributed.sh para obter mais detalhes.
Usamos dois tipos de paralelismo: paralelismo de dados e de modelo. Nossa implementação de paralelismo de dados está em megatron/core/distributed e suporta a sobreposição da redução de gradiente com a passagem para trás quando a opção de linha de comando --overlap-grad-reduce é usada.
Em segundo lugar, desenvolvemos uma abordagem paralela de modelo bidimensional simples e eficiente. Para usar a primeira dimensão, paralelismo do modelo tensor (dividindo a execução de um único módulo transformador em várias GPUs, consulte a Seção 3 do nosso artigo), adicione o sinalizador --tensor-model-parallel-size para especificar o número de GPUs entre as quais dividir o modelo, juntamente com os argumentos passados para o lançador distribuído conforme mencionado acima. Para usar a segunda dimensão, paralelismo de sequência, especifique --sequence-parallel , que também requer que o paralelismo do modelo tensor esteja habilitado porque ele se divide nas mesmas GPUs (mais detalhes na Seção 4.2.2 do nosso artigo).
Para usar o paralelismo do modelo de pipeline (fragmentar os módulos transformadores em estágios com um número igual de módulos transformadores em cada estágio e, em seguida, canalizar a execução dividindo o lote em microlotes menores, consulte a Seção 2.2 do nosso artigo), use o --pipeline-model-parallel-size -sinalizador --pipeline-model-parallel-size para especificar o número de estágios nos quais dividir o modelo (por exemplo, dividir um modelo com 24 camadas de transformador em 4 estágios significaria que cada estágio teria 6 camadas de transformador cada).
Temos exemplos de como usar essas duas formas diferentes de paralelismo de modelo, os scripts de exemplo que terminam em distributed_with_mp.sh .
Tirando essas pequenas alterações, o treinamento distribuído é idêntico ao treinamento em uma única GPU.
O cronograma de pipeline intercalado (mais detalhes na Seção 2.2.2 do nosso artigo) pode ser habilitado usando o argumento --num-layers-per-virtual-pipeline-stage , que controla o número de camadas do transformador em um estágio virtual (por padrão com o agendamento não intercalado, cada GPU executará um único estágio virtual com NUM_LAYERS / PIPELINE_MP_SIZE camadas de transformador). O número total de camadas no modelo do transformador deve ser divisível pelo valor deste argumento. Além disso, o número de microlotes no pipeline (calculado como GLOBAL_BATCH_SIZE / (DATA_PARALLEL_SIZE * MICRO_BATCH_SIZE) ) deve ser divisível pelo PIPELINE_MP_SIZE ao usar esse agendamento (essa condição é verificada em uma asserção no código). A programação intercalada não é compatível com pipelines com 2 estágios ( PIPELINE_MP_SIZE=2 ).
Para reduzir o uso de memória da GPU ao treinar um modelo grande, oferecemos suporte a várias formas de verificação de ativação e recomputação. Em vez de todas as ativações serem armazenadas na memória para serem usadas durante o backprop, como era tradicionalmente o caso em modelos de aprendizagem profunda, apenas as ativações em determinados "pontos de verificação" no modelo são retidas (ou armazenadas) na memória, e as outras ativações são recalculadas. -the-fly quando necessário para backprop. Observe que esse tipo de ponto de verificação, ponto de verificação de ativação , é muito diferente do ponto de verificação dos parâmetros do modelo e do estado do otimizador, mencionado em outro lugar.
Oferecemos suporte a dois níveis de granularidade de recálculo: selective e full . A recomputação seletiva é o padrão e é recomendada em quase todos os casos. Este modo retém na memória as ativações que ocupam menos espaço de armazenamento de memória e são mais caras para recalcular e recomputa as ativações que ocupam mais espaço de armazenamento de memória, mas são relativamente baratas para recalcular. Veja nosso artigo para obter detalhes. Você descobrirá que este modo maximiza o desempenho enquanto minimiza a memória necessária para armazenar ativações. Para ativar o recálculo de ativação seletiva, basta usar --recompute-activations .
Para casos em que a memória é muito limitada, a recomputação full salva apenas as entradas em uma camada de transformador, ou um grupo, ou bloco, de camadas de transformador e recalcula todo o resto. Para ativar a recomputação de ativação completa, use --recompute-granularity full . Ao usar a recomputação de ativação full , existem dois métodos: uniform e block , escolhidos usando o argumento --recompute-method .
O método uniform divide uniformemente as camadas do transformador em grupos de camadas (cada grupo de tamanho --recompute-num-layers ) e armazena as ativações de entrada de cada grupo na memória. O tamanho do grupo de linha de base é 1 e, neste caso, a ativação de entrada de cada camada do transformador é armazenada. Quando a memória da GPU é insuficiente, aumentar o número de camadas por grupo reduz o uso de memória, permitindo o treinamento de um modelo maior. Por exemplo, quando --recompute-num-layers é definido como 4, apenas a ativação de entrada de cada grupo de 4 camadas do transformador é armazenada.
O método block recalcula as ativações de entrada de um número específico (dado por --recompute-num-layers ) de camadas individuais do transformador por estágio de pipeline e armazena as ativações de entrada das camadas restantes no estágio de pipeline. A redução de --recompute-num-layers resulta no armazenamento das ativações de entrada em mais camadas do transformador, o que reduz a recomputação de ativação necessária no backprop, melhorando assim o desempenho do treinamento e aumentando o uso de memória. Por exemplo, quando especificamos 5 camadas para recomputar 8 camadas por estágio de pipeline, as ativações de entrada apenas das 5 primeiras camadas do transformador são recalculadas na etapa backprop enquanto as ativações de entrada para as 3 camadas finais são armazenadas. --recompute-num-layers pode ser aumentado gradativamente até que a quantidade de espaço de armazenamento de memória necessária seja pequena o suficiente para caber na memória disponível, utilizando ao máximo a memória e maximizando o desempenho.
Uso: --use-distributed-optimizer . Compatível com todos os modelos e tipos de dados.
O otimizador distribuído é uma técnica de economia de memória, por meio da qual o estado do otimizador é distribuído uniformemente entre as classificações paralelas de dados (em comparação ao método tradicional de replicar o estado do otimizador entre as classificações paralelas de dados). Conforme descrito em ZeRO: Otimizações de memória para o treinamento de modelos de trilhões de parâmetros, nossa implementação distribui todo o estado do otimizador que não se sobrepõe ao estado do modelo. Por exemplo, ao usar parâmetros do modelo fp16, o otimizador distribuído mantém sua própria cópia separada dos parâmetros e graduados principais do fp32, que são distribuídos entre as classificações DP. Ao usar os parâmetros do modelo bf16, no entanto, os grads principais fp32 do otimizador distribuído são os mesmos que os grads fp32 do modelo e, portanto, os grads neste caso não são distribuídos (embora os parâmetros principais fp32 ainda sejam distribuídos, pois são separados do bf16 parâmetros do modelo).
A economia teórica de memória varia dependendo da combinação do param dtype e grad dtype do modelo. Em nossa implementação, o número teórico de bytes por parâmetro é (onde 'd' é o tamanho paralelo dos dados):
| Otimização não distribuída | Otimização distribuída | |
|---|---|---|
| parâmetro fp16, graduados fp16 | 20 | 4 + 16/d |
| parâmetro bf16, graduados fp32 | 18 | 6 + 12/d |
| parâmetro fp32, graduados fp32 | 16 | 8 + 8/d |
Tal como acontece com o paralelismo de dados regular, a sobreposição da redução do gradiente (neste caso, uma redução-dispersão) com a passagem para trás pode ser facilitada usando o sinalizador --overlap-grad-reduce . Além disso, a sobreposição do parâmetro all-gather pode ser sobreposta à passagem direta usando --overlap-param-gather .
Uso: --use-flash-attn . Suporta dimensões da cabeça de atenção no máximo 128.
FlashAttention é um algoritmo rápido e com uso eficiente de memória para calcular a atenção exata. Ele acelera o treinamento do modelo e reduz os requisitos de memória.
Para instalar o FlashAttention:
pip install flash-attn Em examples/gpt3/train_gpt3_175b_distributed.sh fornecemos um exemplo de como configurar o Megatron para treinar GPT-3 com 175 bilhões de parâmetros em 1024 GPUs. O script foi projetado para slurm com plugin pyxis, mas pode ser facilmente adotado para qualquer outro agendador. Ele usa paralelismo de tensor de 8 vias e paralelismo de pipeline de 16 vias. Com as opções global-batch-size 1536 e rampup-batch-size 16 16 5859375 , o treinamento começará com o tamanho do lote global 16 e aumentará linearmente o tamanho do lote global para 1536 em 5.859.375 amostras com etapas incrementais 16. O conjunto de dados de treinamento pode ser um único conjunto ou vários conjuntos de dados combinados com um conjunto de pesos.
Com tamanho de lote global total de 1.536 em 1.024 GPUs A100, cada iteração leva cerca de 32 segundos, resultando em 138 teraFLOPs por GPU, o que representa 44% do pico teórico de FLOPs.
Retro (Borgeaud et al., 2022) é um modelo de linguagem somente decodificador (LM) autoregressivo pré-treinado com aumento de recuperação. Retro apresenta escalabilidade prática para oferecer suporte ao pré-treinamento em larga escala do zero, recuperando trilhões de tokens. O pré-treinamento com recuperação fornece um mecanismo de armazenamento de conhecimento factual mais eficiente, quando comparado ao armazenamento de conhecimento factual implicitamente dentro dos parâmetros da rede, reduzindo assim amplamente os parâmetros do modelo e, ao mesmo tempo, obtendo menor perplexidade do que o GPT padrão. Retro também fornece flexibilidade para atualizar o conhecimento armazenado em LMs (Wang et al., 2023a), atualizando o banco de dados de recuperação sem treinar novamente os LMs.
InstructRetro (Wang et al., 2023b) aumenta ainda mais o tamanho do Retro para 48B, apresentando o maior LLM pré-treinado com recuperação (em dezembro de 2023). O modelo de base obtido, Retro 48B, supera em grande parte o equivalente do GPT em termos de perplexidade. Com o ajuste de instrução no Retro, o InstructRetro demonstra uma melhoria significativa em relação ao GPT ajustado por instrução em tarefas downstream na configuração de disparo zero. Especificamente, a melhoria média do InstructRetro é de 7% em relação ao seu equivalente GPT em 8 tarefas de controle de qualidade de formato curto e 10% em relação ao GPT em 4 tarefas desafiadoras de controle de qualidade de formato longo. Também descobrimos que é possível remover o codificador da arquitetura InstructRetro e usar diretamente o backbone do decodificador InstructRetro como GPT, obtendo resultados comparáveis.
Neste repositório, fornecemos um guia de reprodução ponta a ponta para implementar Retro e InstructRetro, cobrindo
Consulte tools/retro/README.md para uma visão geral detalhada.
Veja exemplos/mamba para detalhes.
Fornecemos vários argumentos de linha de comando, detalhados nos scripts listados abaixo, para lidar com várias tarefas downstream de tiro zero e ajuste fino. No entanto, você também pode ajustar seu modelo a partir de um ponto de verificação pré-treinado em outros corpora, conforme desejado. Para fazer isso, basta adicionar o sinalizador --finetune e ajustar os arquivos de entrada e os parâmetros de treinamento dentro do script de treinamento original. A contagem de iterações será zerada e o otimizador e o estado interno serão reinicializados. Se o ajuste fino for interrompido por qualquer motivo, certifique-se de remover o sinalizador --finetune antes de continuar, caso contrário o treinamento será reiniciado desde o início.
Como a avaliação requer substancialmente menos memória do que o treinamento, pode ser vantajoso mesclar um modelo treinado em paralelo para uso em menos GPUs em tarefas posteriores. O script a seguir faz isso. Este exemplo lê um modelo GPT com tensor de 4 vias e paralelismo de modelo de pipeline de 4 vias e escreve um modelo com tensor de 2 vias e paralelismo de modelo de pipeline de 2 vias.
ferramentas python/ponto de verificação/convert.py
--modelo tipo GPT
--load-dir pontos de verificação/gpt3_tp4_pp4
--save-dir pontos de verificação/gpt3_tp2_pp2
--target-tensor-tamanho paralelo 2
--target-pipeline-parallel-size 2
Várias tarefas downstream são descritas abaixo para os modelos GPT e BERT. Eles podem ser executados em modos paralelos distribuídos e de modelo com as mesmas alterações usadas nos scripts de treinamento.
Incluímos um servidor REST simples para usar na geração de texto em tools/run_text_generation_server.py . Você o executa da mesma forma que iniciaria um trabalho de pré-treinamento, especificando um ponto de verificação pré-treinado apropriado. Existem também alguns parâmetros opcionais: temperature , top-k e top-p . Consulte --help ou o arquivo de origem para obter mais informações. Consulte exemplos/inferência/run_text_generation_server_345M.sh para obter um exemplo de como executar o servidor.
Quando o servidor estiver em execução, você pode usar tools/text_generation_cli.py para consultá-lo, é necessário um argumento que é o host no qual o servidor está sendo executado.
ferramentas/text_generação_cli.py localhost:5000
Você também pode usar CURL ou qualquer outra ferramenta para consultar diretamente o servidor:
curl 'http://localhost:5000/api' -X 'PUT' -H 'Tipo de conteúdo: aplicação/json; charset=UTF-8' -d '{"prompts":["Olá mundo"], "tokens_to_generate":1}'
Consulte megatron/inference/text_generation_server.py para obter mais opções de API.
Incluímos um exemplo em examples/academic_paper_scripts/detxoify_lm/ para desintoxicar modelos de linguagem, aproveitando o poder generativo dos modelos de linguagem.
Veja exemplos/academic_paper_scripts/detxoify_lm/README.md para tutoriais passo a passo sobre como realizar treinamento adaptativo de domínio e desintoxicar LM usando corpus autogerado.
Incluímos scripts de exemplo para avaliação GPT na avaliação de perplexidade do WikiText e precisão do LAMBADA Cloze.
Para uma comparação uniforme com trabalhos anteriores, avaliamos a perplexidade no conjunto de dados de teste WikiText-103 em nível de palavra e calculamos adequadamente a perplexidade dada a mudança nos tokens ao usar nosso tokenizer de subpalavra.
Usamos o seguinte comando para executar a avaliação do WikiText-103 em um modelo de parâmetro de 345M.
TAREFA="WIKITEXT103"
VALID_DATA=<caminho do wikitexto>.txt
VOCAB_FILE=gpt2-vocab.json
MERGE_FILE=gpt2-merges.txt
CHECKPOINT_PATH=pontos de verificação/gpt2_345m
COMMON_TASK_ARGS="--num-camadas 24
--tamanho oculto 1024
--num-atenção-cabeças 16
--seq-comprimento 1024
--max-position-embeddings 1024
--fp16
--arquivo vocab $VOCAB_FILE"
tarefas python/main.py
--tarefa $TAREFA
$COMMON_TASK_ARGS
--dados válidos $VALID_DATA
--tokenizer-type GPT2BPETokenizer
--merge-arquivo $MERGE_FILE
--carregar$CHECKPOINT_PATH
--tamanho do microlote 8
--log-intervalo 10
--no-load-optim
--no-load-rng
Para calcular a precisão do cloze LAMBADA (a precisão de prever o último token dados os tokens anteriores), utilizamos uma versão processada e destokenizada do conjunto de dados LAMBADA.
Usamos o seguinte comando para executar a avaliação LAMBADA em um modelo de parâmetro 345M. Observe que o sinalizador --strict-lambada deve ser usado para exigir a correspondência de palavras inteiras. Certifique-se de que lambada faça parte do caminho do arquivo.
TAREFA = "LAMBADA"
VALID_DATA=<caminho lambada>.json
VOCAB_FILE=gpt2-vocab.json
MERGE_FILE=gpt2-merges.txt
CHECKPOINT_PATH=pontos de verificação/gpt2_345m
COMMON_TASK_ARGS=<iguais aos da avaliação de perplexidade do WikiText acima>
tarefas python/main.py
--tarefa $TAREFA
$COMMON_TASK_ARGS
--dados válidos $VALID_DATA
--tokenizer-type GPT2BPETokenizer
--strict-lambada
--merge-arquivo $MERGE_FILE
--carregar$CHECKPOINT_PATH
--tamanho do microlote 8
--log-intervalo 10
--no-load-optim
--no-load-rng
Outros argumentos de linha de comando são descritos no arquivo fonte main.py
O script a seguir ajusta o modelo BERT para avaliação no conjunto de dados RACE. Os diretórios TRAIN_DATA e VALID_DATA contêm o conjunto de dados RACE como arquivos .txt separados. Observe que para RACE, o tamanho do lote é o número de consultas RACE a serem avaliadas. Como cada consulta RACE possui quatro amostras, o tamanho efetivo do lote passado pelo modelo será quatro vezes o tamanho do lote especificado na linha de comando.
TRAIN_DATA="dados/RACE/trem/meio"
VALID_DATA="dados/RACE/dev/meio
dados/RACE/dev/alta"
VOCAB_FILE=bert-vocab.txt
PRETRAINED_CHECKPOINT=pontos de verificação/bert_345m
CHECKPOINT_PATH=pontos de verificação/bert_345m_race
COMMON_TASK_ARGS="--num-camadas 24
--tamanho oculto 1024
--num-atenção-cabeças 16
--seq-comprimento 512
--max-position-embeddings 512
--fp16
--arquivo vocab $VOCAB_FILE"
COMMON_TASK_ARGS_EXT="--treinar-dados $TRAIN_DATA
--dados válidos $VALID_DATA
--ponto de verificação pré-treinado $PRETRAINED_CHECKPOINT
--save-intervalo 10000
--save $CHECKPOINT_PATH
--log-intervalo 100
--eval-intervalo 1000
--eval-iters 10
--decadência de peso 1.0e-1"
tarefas python/main.py
--tarefa CORRIDA
$COMMON_TASK_ARGS
$COMMON_TASK_ARGS_EXT
--tokenizer-type BertWordPieceLowerCase
--épocas 3
--micro-batch-tamanho 4
--lr 1.0e-5
--lr-fração de aquecimento 0,06
O script a seguir ajusta o modelo BERT para avaliação com o corpus de pares de frases MultiNLI. Como as tarefas de correspondência são bastante semelhantes, o script pode ser rapidamente ajustado para funcionar também com o conjunto de dados Quora Question Pairs (QQP).
Trens_data = "Data/glue_data/mnli/trens.tsv"
Valid_data = "Data/glue_data/mnli/dev_matched.tsv
dados/glue_data/mnli/dev_mismatched.tsv "
Pré -tereado_checkpoint = pontos de verificação/bert_345m
Vocab_file = bert-vocab.txt
Checkpoint_path = ponto de verificação/bert_345m_mnli
Common_task_args = <o mesmo que aqueles na avaliação de raça acima>
Common_task_args_ext = <o mesmo que aqueles em avaliação de raça acima>
Python Tasks/main.py
-Task mnli
$ Common_task_args
$ Common_task_args_ext
-Tokenizer-Type BertWordECELOWERCase
--epochs 5
-Micro-size 8
--LR 5.0E-5
--LR-Warmup-fraction 0,065
A família de modelos LLAMA-2 é um conjunto de código aberto de modelos pré-treinados e finetunados (para bate-papo) que alcançaram fortes resultados em um amplo conjunto de benchmarks. No momento da liberação, os modelos LLAMA-2 obtidos entre os melhores resultados para modelos de código aberto e eram competitivos com o modelo GPT-3.5 de código fechado (consulte https://arxiv.org/pdf/2307.09288.pdf).
Os postos de controle da llama-2 podem ser carregados no Megatron para inferência e finetuning. Veja a documentação aqui.
A família GPTModel da Megatron-Core (MCORE) apóia algoritmos de quantização avançada e inferência de alto desempenho através de Tensorrt-llm.
Consulte Otimização e implantação do modelo Megatron para exemplos de llama2 e nemotron3 .
Não hospedamos nenhum conjunto de dados para treinamento GPT ou BERT, no entanto, detalhamos sua coleção para que nossos resultados possam ser reproduzidos.
Recomendamos seguir o processo de extração de dados da Wikipedia especificado pelo Google Research: "O pré-processamento recomendado é baixar o dump mais recente, extrair o texto com wikiextractor.py e depois aplicar qualquer limpeza necessária para convertê-lo em texto simples".
Recomendamos o uso do argumento --json ao usar o Wikiextractor, que despejará os dados da Wikipedia no formato JSON solto (um objeto JSON por linha), tornando -o mais gerenciável no sistema de arquivos e também prontamente consumível por nossa base de código. Recomendamos um pré -processamento adicional deste conjunto de dados JSON com padronização de pontuação NLTK. Para o treinamento de Bert, use o sinalizador --split-sentences para preprocess_data.py conforme descrito acima, para incluir quebras de sentença no índice produzido. Se você deseja usar dados da Wikipedia para treinamento GPT, ainda deve limpá-los com NLTK/SPACY/FTFY, mas não use o sinalizador --split-sentences .
Utilizamos a biblioteca OpenWebtext disponível ao público da JCPeterson e do Eukaryote31, para baixar URLs. Em seguida, filtramos, limpamos e deduzimos todo o conteúdo baixado de acordo com o procedimento descrito em nosso diretório OpenWebText. Para URLs do Reddit, correspondentes ao conteúdo até outubro de 2018, chegamos a aproximadamente 37 GB de conteúdo.
O treinamento de megatron pode ser reproduzível bit; Para ativar esse modo, use --deterministic-mode . Isso significa que a mesma configuração de treinamento é executada duas vezes no mesmo ambiente HW e SW, deve produzir pontos de verificação de modelos idênticos, perdas e valores métricos de precisão (as métricas de tempo de iteração podem variar).
Atualmente, existem três otimizações conhecidas de megatron que quebram a reprodutibilidade enquanto ainda produzem treinamento quase idêntico:
NCCL_ALGO ) é importante. Testamos o seguinte: ^NVLS , Tree , Ring , CollnetDirect , CollnetChain . O código admite o uso de ^NVLS , que permite a NCCL a escolha dos algoritmos não-NVLS; Sua escolha parece ser estável.--use-flash-attn .NVTE_ALLOW_NONDETERMINISTIC_ALGO=0 .Além disso, o determinisim foi verificado apenas em contêineres NGC Pytorch até e mais recente que 23.12. Se você observar o não determinismo no treinamento de megatron sob outras circunstâncias, abra um problema.
Abaixo estão alguns dos projetos em que usamos diretamente o Megatron:


