tabled
1.0.0
Tabled é uma pequena biblioteca para detectar e extrair tabelas. Ele usa surya para encontrar todas as tabelas em um PDF, identifica as linhas/colunas e formata as células em markdown, csv ou html.
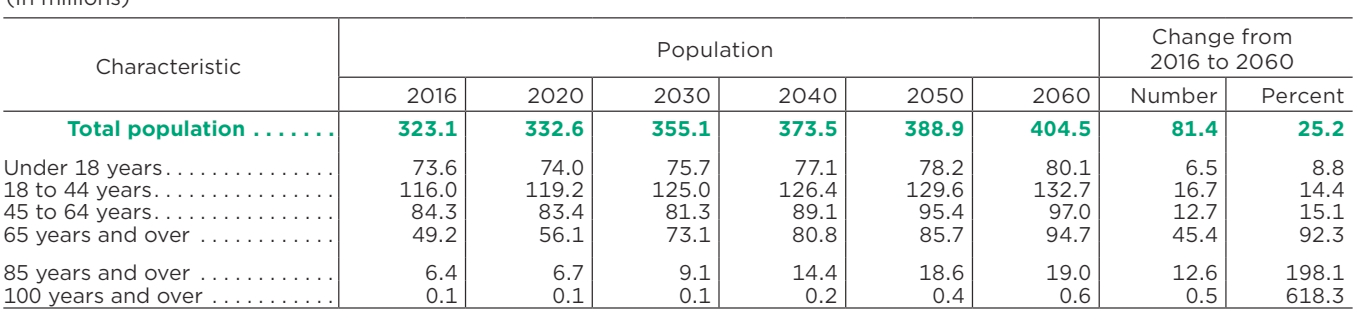
| Característica | População | Mudança de 2016 para 2060 | ||||||
|---|---|---|---|---|---|---|---|---|
| 2016 | 2020 | 2030 | 2040 | 2050 | 2060 | Número | Por cento | |
| População total | 323,1 | 332,6 | 355,1 | 373,5 | 388,9 | 404,5 | 81,4 | 25.2 |
| Menores de 18 anos | 73,6 | 74,0 | 75,7 | 77,1 | 78,2 | 80,1 | 6,5 | 8.8 |
| 18 a 44 anos | 116,0 | 119,2 | 125,0 | 126,4 | 129,6 | 132,7 | 16,7 | 14.4 |
| 45 a 64 anos | 84,3 | 83,4 | 81,3 | 89,1 | 95,4 | 97,0 | 12,7 | 15.1 |
| 65 anos ou mais | 49,2 | 56,1 | 73,1 | 80,8 | 85,7 | 94,7 | 45,4 | 92,3 |
| 85 anos ou mais | 6.4 | 6.7 | 9.1 | 14.4 | 18,6 | 19,0 | 12.6 | 198,1 |
| 100 anos ou mais | 0,1 | 0,1 | 0,1 | 0,2 | 0,4 | 0,6 | 0,5 | 618,3 |
Discord é onde discutimos o desenvolvimento futuro.
Há uma API hospedada para tabela disponível aqui:
Funciona com PDF, imagens, documentos do Word e PowerPoint
Velocidade consistente, sem picos de latência
Alta confiabilidade e tempo de atividade
Quero que a tabela seja tão amplamente acessível quanto possível, ao mesmo tempo que financio os meus custos de desenvolvimento/formação. Pesquisa e uso pessoal são sempre permitidos, mas existem algumas restrições ao uso comercial.
Os pesos para os modelos são licenciados cc-by-nc-sa-4.0 , mas renunciarei a isso para qualquer organização com menos de US$ 5 milhões em receita bruta no período mais recente de 12 meses E menos de US$ 5 milhões em financiamento vitalício de VC/anjo criado. Você também não deve ser competitivo com a API do Datalab. Se você deseja remover os requisitos de licença GPL (licença dupla) e/ou usar comercialmente os pesos acima do limite de receita, confira as opções aqui.
Você precisará do python 3.10+ e do PyTorch. Pode ser necessário instalar primeiro a versão CPU do torch se não estiver usando um Mac ou uma máquina GPU. Veja aqui para mais detalhes.
Instale com:
pip install tabelado-pdf
Pós-instalação:
Inspecione as configurações em tabled/settings.py . Você pode substituir quaisquer configurações por variáveis de ambiente.
Seu dispositivo de tocha será detectado automaticamente, mas você pode ignorar isso. Por exemplo, TORCH_DEVICE=cuda .
Os pesos do modelo serão baixados automaticamente na primeira vez que você executar a tabela.
tabelado DATA_PATH
DATA_PATH pode ser uma imagem, pdf ou pasta de imagens/pdfs
--format especifica o formato de saída para cada tabela ( markdown , html ou csv )
--save_json salva informações adicionais de linha e coluna em um arquivo json
--save_debug_images salva imagens mostrando as linhas e colunas detectadas
--skip_detection significa que as imagens que você passa são todas tabelas cortadas e não precisam de nenhuma detecção de tabela.
--detect_cell_boxes por padrão, tabled tentará extrair informações da célula do pdf. Se você quiser que as células sejam detectadas por um modelo de detecção, especifique isso (normalmente você só precisa disso com PDFs que possuem texto incorporado incorreto).
--save_images especifica que imagens de linhas/colunas e células detectadas devem ser salvas.
Depois de executar o script, o diretório de saída conterá pastas com os mesmos nomes de base dos nomes de arquivo de entrada. Dentro dessas pastas estarão os arquivos markdown para cada tabela nos documentos de origem. Opcionalmente também haverá imagens das tabelas.
Também haverá um arquivo results.json na raiz do diretório de saída. O arquivo conterá um dicionário JSON onde as chaves são os nomes dos arquivos de entrada sem extensões. Cada valor será uma lista de dicionários, um por tabela do documento. Cada dicionário de tabela contém:
cells - o texto detectado e as caixas delimitadoras para cada célula da tabela.
bbox - bbox da célula dentro da tabela bbox
text - o texto da célula
row_ids - ids das linhas às quais a célula pertence
col_ids - ids das colunas às quais a célula pertence
order - ordem desta célula dentro de sua célula de linha/coluna atribuída. (classificar por linha, depois coluna e depois ordenar)
rows - bboxes das linhas detectadas
bbox - bbox da linha no formato (x1, x2, y1, y2)
row_id - id exclusivo da linha
cols - bboxes de colunas detectadas
bbox - bbox da coluna no formato (x1, x2, y1, y2)
col_id - id exclusivo da coluna
image_bbox - o bbox da imagem no formato (x1, y1, x2, y2). (x1, y1) é o canto superior esquerdo e (x2, y2) é o canto inferior direito. A tabela bbox é relativa a isso.
bbox - a caixa delimitadora da tabela dentro da imagem bbox.
pnum - número da página do documento
tnum - índice da tabela na página
Incluí um aplicativo streamlit que permite que você experimente tabelas interativamente em imagens ou arquivos PDF. Execute-o com:
pip instalar streamlit tabelado_gui
de tabled.extract importar extract_tablesfrom tabled.fileinput importar load_pdfs_imagesfrom tabled.inference.models importar load_detection_models, load_recognition_modelsdet_models, rec_models = load_detection_models(), load_recognition_models()images, highres_images, nomes, text_lines = load_pdfs_images(IN_PATH)page_results = extract_tables(imagens, highres_images, text_lines, det_models, rec_models)
| Pontuação média | Tempo por mesa | Total de tabelas |
|---|---|---|
| 0,847 | 0,029 | 688 |
Obter bons dados reais para tabelas é difícil, pois você está limitado a layouts simples que podem ser analisados e renderizados heuristicamente ou precisa usar LLMs, que cometem erros. Optei por usar as previsões da tabela GPT-4 como uma pseudo-verdade.
Tabled obtém uma pontuação de alinhamento .847 quando comparado ao GPT-4, o que indica alinhamento entre o texto nas linhas/células da tabela. Alguns dos desalinhamentos são devidos a erros do GPT-4 ou pequenas inconsistências no que o GPT-4 considerava os limites da tabela. Em geral, a qualidade da extração é bastante elevada.
Executando em um A10G com 10 GB de uso de VRAM e tamanho de lote 64 , a tabela leva .029 segundos por tabela.
Execute o benchmark com:
benchmarks python/benchmark.py out.json
Obrigado a Peter Jansen pelo conjunto de dados de benchmarking e pela discussão sobre análise de tabelas.
Huggingface para código de inferência e hospedagem de modelo
PyTorch para treinamento/inferência


