A Difusão Estável foi possível graças a uma colaboração com Stability AI e Runway e se baseia em nosso trabalho anterior:
Síntese de imagens de alta resolução com modelos de difusão latente
Robin Rombach*, Andreas Blattmann*, Dominik Lorenz, Patrick Esser, Björn Ommer
CVPR '22 Oral | GitHub | arXiv | Página do projeto
 Difusão Estável é um modelo de difusão latente de texto para imagem. Graças a uma generosa doação computacional da Stability AI e ao apoio do LAION, conseguimos treinar um modelo de difusão latente em imagens 512x512 de um subconjunto do banco de dados LAION-5B. Semelhante ao Imagen do Google, este modelo usa um codificador de texto CLIP ViT-L/14 congelado para condicionar o modelo em prompts de texto. Com seu codificador de texto UNet de 860M e 123M, o modelo é relativamente leve e roda em uma GPU com pelo menos 10GB de VRAM. Consulte esta seção abaixo e o cartão do modelo.
Difusão Estável é um modelo de difusão latente de texto para imagem. Graças a uma generosa doação computacional da Stability AI e ao apoio do LAION, conseguimos treinar um modelo de difusão latente em imagens 512x512 de um subconjunto do banco de dados LAION-5B. Semelhante ao Imagen do Google, este modelo usa um codificador de texto CLIP ViT-L/14 congelado para condicionar o modelo em prompts de texto. Com seu codificador de texto UNet de 860M e 123M, o modelo é relativamente leve e roda em uma GPU com pelo menos 10GB de VRAM. Consulte esta seção abaixo e o cartão do modelo.
Um ambiente conda adequado chamado ldm pode ser criado e ativado com:
conda env create -f environment.yaml
conda activate ldm
Você também pode atualizar um ambiente de difusão latente existente executando
conda install pytorch torchvision -c pytorch
pip install transformers==4.19.2 diffusers invisible-watermark
pip install -e .
Stable Diffusion v1 refere-se a uma configuração específica da arquitetura do modelo que usa um autoencoder de fator de redução de amostragem 8 com um codificador de texto UNet 860M e CLIP ViT-L/14 para o modelo de difusão. O modelo foi pré-treinado em imagens de 256x256 e depois ajustado em imagens de 512x512.
Nota: Stable Diffusion v1 é um modelo geral de difusão de texto para imagem e, portanto, reflete preconceitos e (errôneos) conceitos que estão presentes em seus dados de treinamento. Detalhes sobre o procedimento e dados de treinamento, bem como o uso pretendido do modelo podem ser encontrados no cartão do modelo correspondente.
Os pesos estão disponíveis através da organização CompVis em Hugging Face sob uma licença que contém restrições específicas baseadas no uso para evitar uso indevido e danos conforme informado no modelo do cartão, mas de outra forma permanece permissiva. Embora o uso comercial seja permitido sob os termos da licença, não recomendamos o uso dos pesos fornecidos para serviços ou produtos sem mecanismos e considerações de segurança adicionais , uma vez que existem limitações e preconceitos conhecidos dos pesos e pesquisas sobre a implantação segura e ética de modelos gerais de texto para imagem é um esforço contínuo. Os pesos são artefatos de pesquisa e devem ser tratados como tal.
A licença CreativeML OpenRAIL M é uma licença Open RAIL M, adaptada do trabalho que a BigScience e a RAIL Initiative estão realizando conjuntamente na área de licenciamento responsável de IA. Veja também o artigo sobre a licença BLOOM Open RAIL na qual nossa licença se baseia.
Atualmente fornecemos os seguintes pontos de verificação:
sd-v1-1.ckpt : 237k passos na resolução 256x256 em laion2B-en. 194k passos na resolução 512x512 em laion-alta resolução (170M exemplos de LAION-5B com resolução >= 1024x1024 ).sd-v1-2.ckpt : retomado de sd-v1-1.ckpt . 515k passos com resolução 512x512 em laion-aesthetics v2 5+ (um subconjunto de laion2B-en com pontuação estética estimada > 5.0 e adicionalmente filtrada para imagens com tamanho original >= 512x512 e uma probabilidade estimada de marca d'água < 0.5 . A estimativa da marca d'água é dos metadados LAION-5B, a pontuação estética é estimada usando o LAION-Aesthetics Preditor V2).sd-v1-3.ckpt : retomado de sd-v1-2.ckpt . 195k passos na resolução 512x512 em "laion-aesthetics v2 5+" e redução de 10% no condicionamento de texto para melhorar a amostragem de orientação sem classificador.sd-v1-4.ckpt : retomado de sd-v1-2.ckpt . 225k passos na resolução 512x512 em "laion-aesthetics v2 5+" e redução de 10% no condicionamento de texto para melhorar a amostragem de orientação sem classificador. Avaliações com diferentes escalas de orientação sem classificador (1,5, 2,0, 3,0, 4,0, 5,0, 6,0, 7,0, 8,0) e 50 etapas de amostragem PLMS mostram as melhorias relativas dos pontos de verificação: 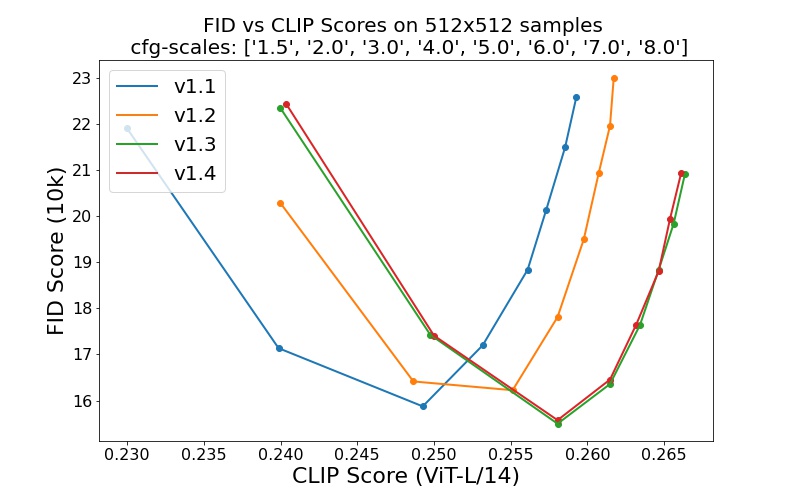


Difusão Estável é um modelo de difusão latente condicionado aos embeddings de texto (não agrupados) de um codificador de texto CLIP ViT-L/14. Fornecemos um roteiro de referência para amostragem, mas também existe uma integração de difusores, que esperamos ver um desenvolvimento comunitário mais ativo.
Fornecemos um roteiro de amostragem de referência, que incorpora
Depois de obter os pesos stable-diffusion-v1-*-original , vincule-os
mkdir -p models/ldm/stable-diffusion-v1/
ln -s <path/to/model.ckpt> models/ldm/stable-diffusion-v1/model.ckpt
e amostra com
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
Por padrão, isso usa uma escala de orientação de --scale 7.5 , a implementação do amostrador PLMS de Katherine Crowson, e renderiza imagens de tamanho 512x512 (nas quais foi treinado) em 50 etapas. Todos os argumentos suportados estão listados abaixo (digite python scripts/txt2img.py --help ).
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA]
[--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS] [--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT]
[--seed SEED] [--precision {full,autocast}]
optional arguments:
-h, --help show this help message and exit
--prompt [PROMPT] the prompt to render
--outdir [OUTDIR] dir to write results to
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
--skip_save do not save individual samples. For speed measurements.
--ddim_steps DDIM_STEPS
number of ddim sampling steps
--plms use plms sampling
--laion400m uses the LAION400M model
--fixed_code if enabled, uses the same starting code across samples
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
--n_iter N_ITER sample this often
--H H image height, in pixel space
--W W image width, in pixel space
--C C latent channels
--f F downsampling factor
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a. batch size
--n_rows N_ROWS rows in the grid (default: n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--from-file FROM_FILE
if specified, load prompts from this file
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--precision {full,autocast}
evaluate at this precision
Observação: a configuração de inferência para todas as versões v1 foi projetada para ser usada apenas com pontos de verificação EMA. Por esse motivo, use_ema=False está definido na configuração, caso contrário, o código tentará mudar de pesos não EMA para EMA. Se você quiser examinar o efeito da EMA versus nenhuma EMA, fornecemos pontos de verificação "completos" que contêm ambos os tipos de pesos. Para estes, use_ema=False carregará e usará os pesos não EMA.
Uma maneira simples de baixar e experimentar o Stable Diffusion é usar a biblioteca de difusores:
# make sure you're logged in with `huggingface-cli login`
from torch import autocast
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline . from_pretrained (
"CompVis/stable-diffusion-v1-4" ,
use_auth_token = True
). to ( "cuda" )
prompt = "a photo of an astronaut riding a horse on mars"
with autocast ( "cuda" ):
image = pipe ( prompt )[ "sample" ][ 0 ]
image . save ( "astronaut_rides_horse.png" )Ao usar um mecanismo de eliminação de ruído de difusão, conforme proposto pela primeira vez pelo SDEdit, o modelo pode ser usado para diferentes tarefas, como tradução e aumento de escala de imagem para imagem guiada por texto. Semelhante ao script de amostragem txt2img, fornecemos um script para realizar modificação de imagem com Difusão Estável.
A seguir descreve-se um exemplo onde um esboço feito no Pinta é convertido em uma obra de arte detalhada.
python scripts/img2img.py --prompt "A fantasy landscape, trending on artstation" --init-img <path-to-img.jpg> --strength 0.8
Aqui, intensidade é um valor entre 0,0 e 1,0, que controla a quantidade de ruído adicionado à imagem de entrada. Valores que se aproximam de 1,0 permitem muitas variações, mas também produzirão imagens que não são semanticamente consistentes com a entrada. Veja o exemplo a seguir.
Entrada

Resultados


Este procedimento também pode ser usado, por exemplo, para aprimorar amostras do modelo base.
Nossa base de código para os modelos de difusão baseia-se fortemente na base de código ADM da OpenAI e em https://github.com/lucidrains/denoising-diffusion-pytorch. Obrigado pelo código aberto!
A implementação do codificador do transformador é dos transformadores x da Lucidrains.
@misc{rombach2021highresolution,
title={High-Resolution Image Synthesis with Latent Diffusion Models},
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
year={2021},
eprint={2112.10752},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


