ACM MM'18 Melhor Artigo de Estudante
O projeto Multi-Human Parsing do Grupo de Aprendizagem e Visão (LV), da Universidade Nacional de Cingapura (NUS) é proposto para expandir as fronteiras da compreensão visual refinada dos humanos na cena da multidão.
A análise multi-humana é significativamente diferente das tarefas tradicionais de reconhecimento de objetos bem definidos, como a detecção de objetos, que fornece apenas previsões de nível aproximado da localização dos objetos (caixas delimitadoras); segmentação de instância, que prevê apenas a máscara em nível de instância, sem qualquer informação detalhada sobre partes do corpo e categorias de moda; análise humana, que opera na previsão de pixels em nível de categoria, sem diferenciar identidades diferentes.
No cenário do mundo real, o cenário de múltiplas pessoas com interações é mais realista e usual. Portanto, uma tarefa, conjuntos de dados correspondentes e métodos de linha de base para considerar tanto a informação semântica refinada de cada pessoa individual quanto os relacionamentos e interações de todo o grupo de pessoas são altamente desejados.
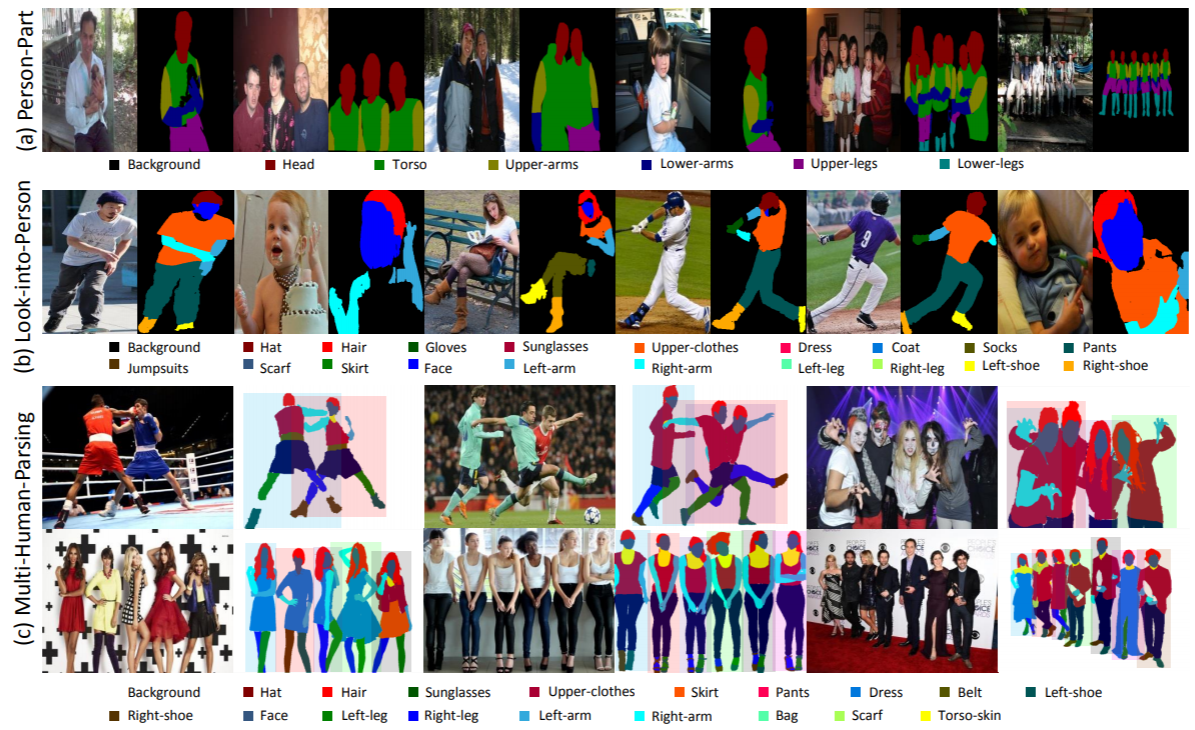
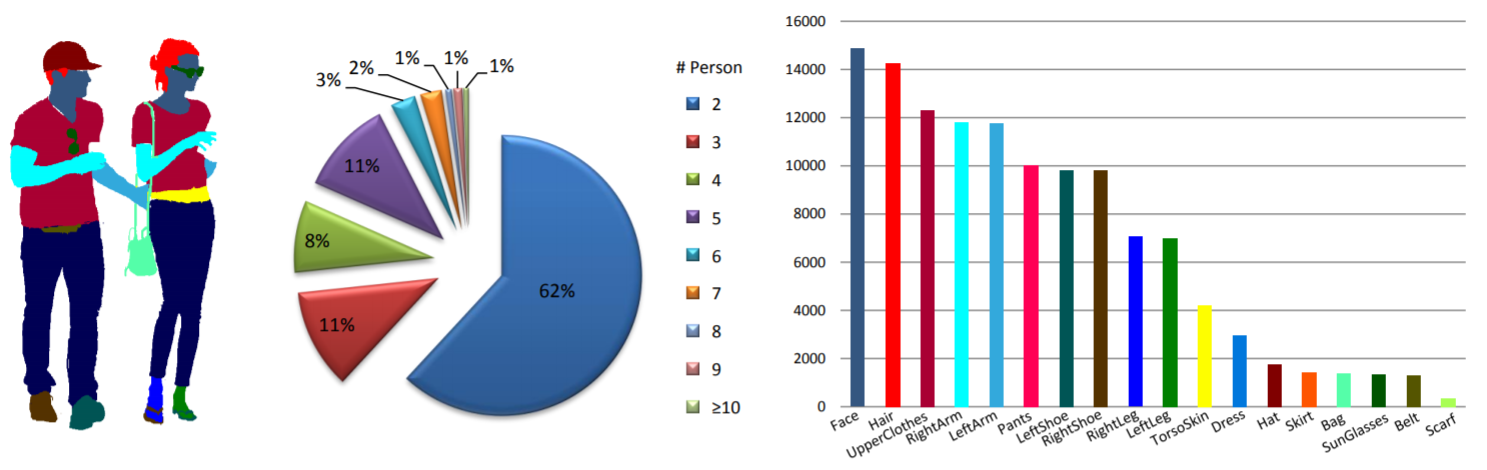
Estatísticas: O conjunto de dados MHP v1.0 contém 4.980 imagens, cada uma com pelo menos duas pessoas (a média é 3). Escolhemos aleatoriamente 980 imagens e suas anotações correspondentes como conjunto de teste. O restante forma um conjunto de treinamento de 3.000 imagens e um conjunto de validação de 1.000 imagens. Para cada instância, 18 categorias semânticas são definidas e anotadas, exceto para a categoria “fundo”, ou seja, “chapéu”, “cabelo”, “óculos de sol”, “roupas superiores”, “saia”, “calças”, “vestido”, “ cinto”, “sapato esquerdo”, “sapato direito”, “rosto”, “perna esquerda”, “perna direita”, “braço esquerdo”, “braço direito”, “bolsa”, “lenço” e “pele do tronco”. Cada instância possui um conjunto completo de anotações sempre que a categoria correspondente aparece na imagem atual.
Notícias do WeChat.
Download: O conjunto de dados MHP v1.0 está disponível em google drive e baidu drive (senha: cmtp).
Consulte nosso documento MHP v1.0 (enviado ao IJCV) para obter mais detalhes.

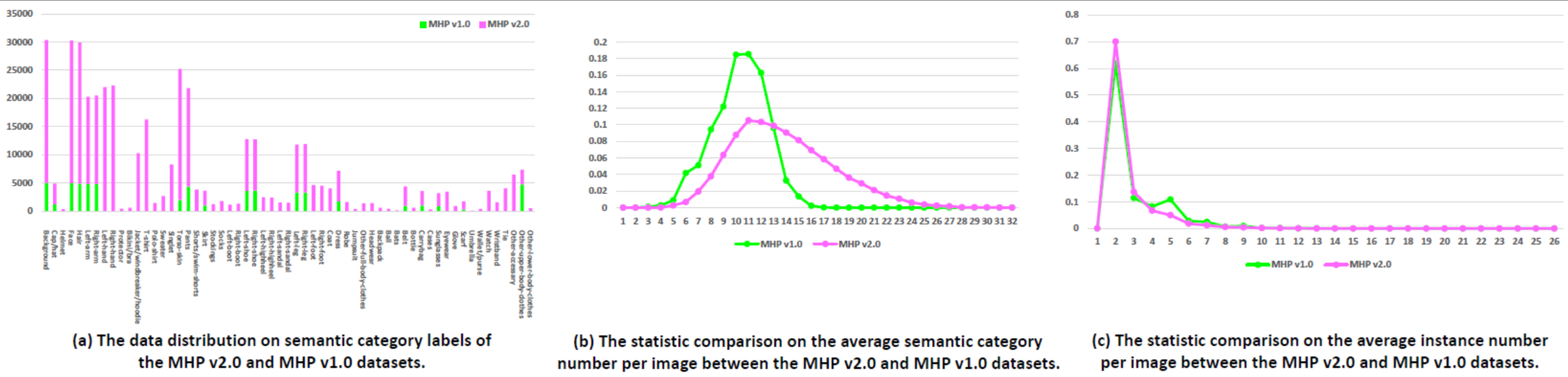

Estatísticas: O conjunto de dados MHP v2.0 contém 25.403 imagens, cada uma com pelo menos duas pessoas (a média é 3). Escolhemos aleatoriamente 5.000 imagens e suas anotações correspondentes como conjunto de teste. O restante forma um conjunto de treinamento de 15.403 imagens e um conjunto de validação de 5.000 imagens. Para cada instância, 58 categorias semânticas são definidas e anotadas, exceto para a categoria "fundo", ou seja, "boné/chapéu", "capacete", "rosto", "cabelo", "braço esquerdo", "braço direito", "mão esquerda", "mão direita", "protetor", "biquíni/sutiã", "jaqueta/corta-vento/moletom com capuz", "camiseta", "camisa pólo", "suéter", "single", "pele do tronco", "calças", "shorts/shorts de banho", "saia", "meias", "meias", "bota esquerda", "bota direita", "sapato esquerdo", "sapato direito", "salto alto esquerdo", "salto alto direito", "sandália esquerda", "sandália direita", "perna esquerda", "perna direita", "pé esquerdo", "pé direito", "casaco", "vestido", "roupão", "macacão", "outras roupas de corpo inteiro", "chapéus", "mochila", "bola", "morcegos", "cinto", "garrafa", "bolsa de transporte", "estojos", "óculos de sol", "óculos", "luva", "lenço", "guarda-chuva", "carteira/bolsa", "relógio", "pulseira", "gravata", "outros acessórios", "outras roupas da parte superior do corpo" e "outras roupas da parte inferior -roupas corporais". Cada instância possui um conjunto completo de anotações sempre que a categoria correspondente aparece na imagem atual. Além disso, poses humanas 2D com 16 pontos-chave densos ("ombro direito", "cotovelo direito", "pulso direito", "ombro esquerdo", "cotovelo esquerdo", "pulso esquerdo", "direito- quadril", "joelho direito", "tornozelo direito", "quadril esquerdo", "joelho esquerdo", "tornozelo esquerdo", "cabeça", "pescoço", "coluna" e "pelve". Cada ponto-chave tem um sinalizador indicando se é visível-0/occluded-1/out-of-image-2) e caixas delimitadoras de cabeça e instância também são fornecidas para facilitar a pesquisa de estimativa de pose multi-humana.
Download: O conjunto de dados MHP v2.0 está disponível em google drive e baidu drive (senha: uxrb).
Consulte nosso artigo MHP v2.0 (ACM MM'18 Best Student Paper) para obter mais detalhes.
Análise Multi-Humana: Usamos duas métricas centradas em humanos para avaliação de análise multi-humana, que são inicialmente relatadas em nosso artigo MHP v1.0. As duas métricas são precisão média baseada na parte (AP p ) (%) e porcentagem de partes semânticas analisadas corretamente (PCP) (%). Para o código de avaliação, consulte a pasta "Avaliação" em nosso repositório "Multi-Human-Parsing_MHP".
Estimativa de pose multi-humana: Seguido MPII, usamos a medida de avaliação mAP (%).
Organizamos o Workshop CVPR 2018 sobre Compreensão Visual de Humanos em Cena de Multidão (VUHCS 2018). Este workshop conta com a colaboração de NUS, CMU e SYSU. Com base no VUHCS 2017, fortalecemos ainda mais este Workshop, ampliando-o com 5 faixas de competição: a análise humana de uma única pessoa, a análise humana de várias pessoas, a estimativa de pose de uma pessoa, a estimativa de pose multi-humana e a precisão. análise multi-humana granulada.
Envio de resultados e tabela de classificação.
Notícias do WeChat.
Consulte e considere citar os seguintes artigos:
@article{zhao2018understanding,
title={Understanding Humans in Crowded Scenes: Deep Nested Adversarial Learning and A New Benchmark for Multi-Human Parsing},
author={Zhao, Jian and Li, Jianshu and Cheng, Yu and Zhou, Li and Sim, Terence and Yan, Shuicheng and Feng, Jiashi},
journal={arXiv preprint arXiv:1804.03287},
year={2018}
}
@article{li2017towards,
title={Multi-Human Parsing in the Wild},
author={Li, Jianshu and Zhao, Jian and Wei, Yunchao and Lang, Congyan and Li, Yidong and Sim, Terence and Yan, Shuicheng and Feng, Jiashi},
journal={arXiv preprint arXiv:1705.07206},
year={2017}
}


