Por Buqian Zheng(buqianz) e Yongkang Huang(yongkan1)
Poster
Implementamos o Corgy, um framework de deep learning em Swift e Metal. Corgy pode ser incorporado em aplicativos macOS e iOS e usado para construir redes neurais treinadas e avaliá-las com facilidade. Alcançamos uma aceleração de mais de 60x em diferentes dispositivos com diferentes GPUs.

A estrutura Metal 2 é uma interface fornecida pela Apple que fornece acesso quase direto à unidade de processamento gráfico (GPU) no iPhone/iPad e Mac. Além dos gráficos, o Metal 2 incorporou um conjunto de bibliotecas que fornecem excelente suporte paralelizado para as operações de álgebra linear necessárias e funções de processamento de sinal que podem ser executadas em vários tipos de dispositivos Apple. Essas bibliotecas nos possibilitaram construir modelos de aprendizado profundo acelerados por GPU bem implementados nos dispositivos iOS com base no modelo treinado fornecido por outras estruturas. 1
De modo geral, a etapa de inferência de uma rede neural treinada é muito intensiva em computação, principalmente para aqueles modelos que possuem um número consideravelmente grande de camadas ou aplicados nos cenários necessários para processar imagens de alta resolução. Vale a pena notar que existe uma enorme quantidade de computação matricial (por exemplo, camada convolucional) que é apropriada para aplicar operações paralelizadas para otimizar o desempenho.
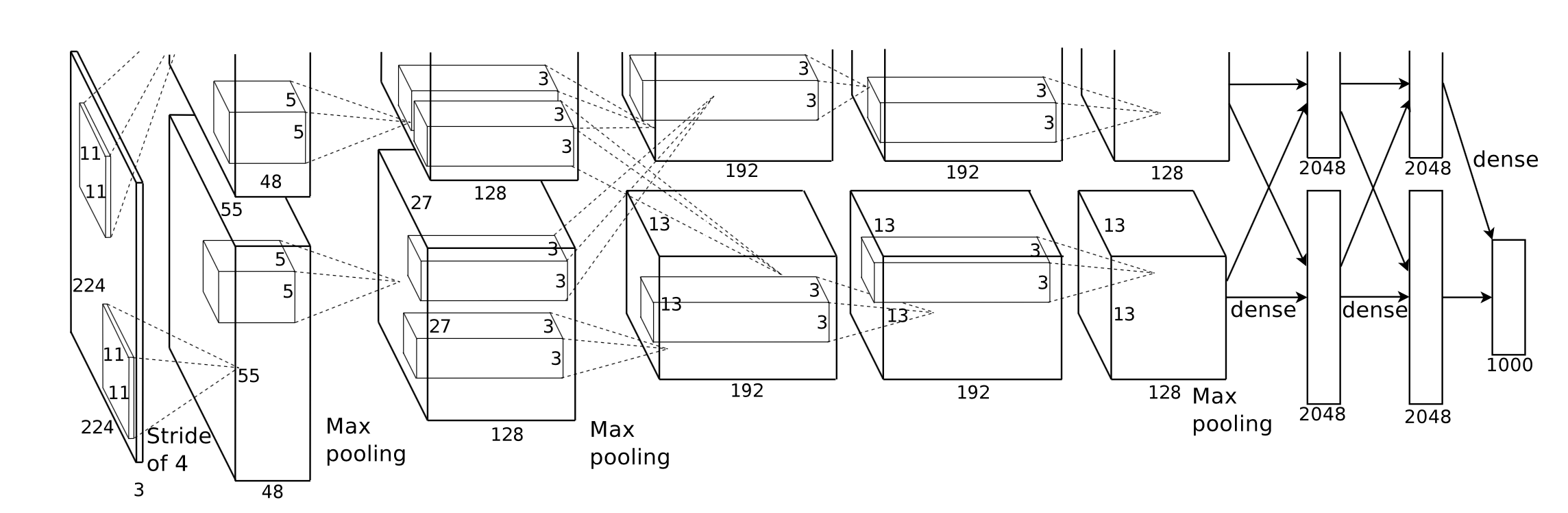
O primeiro desafio que enfrentamos é projetar uma boa abstração de interface de programação de aplicativos que seja expressiva, fácil de usar com baixa curva de aprendizado e fácil de usar para nossos usuários.
Durante todo o processo de desenvolvimento, tentamos ao máximo manter a API pública o mais simples possível, mas com todas as propriedades necessárias para criar todos os componentes exigidos, aproveitando o mecanismo de programação funcional fornecido pelo Swift. Também ocultamos deliberadamente a abstração desnecessária de hardware fornecida pelo Metal para suavizar a curva de aprendizado.
Embora o modelo treinado das diversas redes seja fácil de obter na Internet, a heterogeneidade entre elas, causada pelas diferentes implementações e aplicação de vários tipos de ferramentas, facilitou o trabalho de criação de um importador de modelo universal.
Parte da computação é fácil de entender pela sua concepção, mas requer reflexão cuidadosa quando você deseja criar uma implementação eficaz abstraindo-a. A convolução é um exemplo representativo.
A propriedade intrínseca da operação de convolução não tem uma boa localidade, a implementação vanilla é difícil de entender e ineficaz com loops for complicados. Além disso, precisamos considerar a abstração fornecida pelo Metal 2 e criar uma maneira conveniente de compartilhar as informações e estruturas de dados necessárias entre o host e o dispositivo, considerando cuidadosamente a representação dos dados e o layout da memória.
Durante a fase de desenvolvimento, somos cuidadosos ao lidar com a capacidade de nosso código rodar normalmente em macOS e iOS sem comprometer o desempenho em ambas as plataformas. Tentamos ao máximo manter uma biblioteca de códigos capaz de compilar e executar em ambas as plataformas. Somos cautelosos para maximizar o código compartilhado entre os diferentes alvos e reutilizar o código tanto quanto possível.
Como um componente totalmente implementado da camada de rede neural deve fornecer suporte com uma quantidade razoável de parâmetros que tornem o componente suficientemente utilizável, a complexidade dos componentes é realmente bastante impressionante. Por exemplo, a camada convolucional deve suportar os parâmetros que incorporam preenchimento, passo de dilatação, etc. e todos eles devem ser considerados com cautela ao fazer a paralelização que atinge um desempenho razoável. Construímos algumas redes simples para fazer o teste de regressão. Os casos de teste são criados em outras estruturas (principalmente PyTorch e Keras) para garantir que toda a implementação funcione corretamente.
Swift foi desenvolvido pela primeira vez em julho de 2010 e publicado e de código aberto em 2014. Embora já tenham se passado quase 4 anos desde sua publicação, a falta de uma biblioteca impactante ainda é um problema inignorável. Alguma razão causou esta situação, o papel dominante da Apple e a rápida iteração natural do Swift podem ser a razão para este fenômeno. Algumas bibliotecas que são cruciais para nós não são poderosas ou funcionais o suficiente para nossas necessidades, ou nem são bem mantidas pelo desenvolvedor individual que as inventou. Gastamos muito tempo para implementar uma Variable de classe de tensor que funcionasse bem para nossas demandas.
Além disso, este é outro motivo para impedir o desenvolvimento de um analisador de modelo universal, pois a função de manipulação de arquivos e strings tem capacidade muito limitada.
Além disso, as ferramentas de desenvolvimento e depuração são basicamente restritas ao Xcode, embora existam outras opções que são mais gerais para nós, o Xcode ainda é a ferramenta padrão de fato para o nosso desenvolvimento.
Para o ajuste de desempenho dos dispositivos móveis, a Apple não fornece especificações detalhadas de hardware para seu SoC, o nome de marketing é amplamente utilizado pela mídia e é difícil deduzir qual é o impacto exato de um recurso de hardware específico e ajustar o desempenho da implementação .
Estamos usando a linguagem de programação Swift, especificamente Swift 4.2, que é a mais recente até agora; Estrutura Metal 2 e algumas funções de biblioteca fornecidas pelo Metal Performance Shader (basicamente funções de álgebra linear). Embora a Apple tenha lançado o CoreML SDK na primavera de 2017, que incorporou algum suporte para redes neurais convolucionais, não os estamos usando no Corgy para obter uma experiência inestimável no desenvolvimento de implementação paralelizada das camadas de rede e fornecer APIs sucintas e intuitivas com boa usabilidade e curva de aprendizado suave. para que os usuários migrem um modelo de outras estruturas sem esforço.
Nossas máquinas-alvo são todos dispositivos que executam macOS e iOS, como iMac, MacBook, iPhone e iPad. Especificamente, o dispositivo com a plataforma que suporta a biblioteca de álgebra linear MPS (ou seja, após iOS 10.0 e macOS 10.13), o que significa que o iPhone foi lançado após o iPhone 5, o iPad foi lançado após o iPad (4ª geração) e o iPod Touch (6ª geração) são suportados como a plataforma iOS. A linha de produtos Mac obtém uma cobertura ainda mais ampla, incluindo o iMac produzido após o final de 2009 ou mais recente, todas as séries MacBook lançadas após meados de 2010 e o iMac Pro.
A abstração paralela do Metal 2 é muito parecida com CUDA: ao despachar a passagem do computador para a GPU os programadores primeiro escreverão funções do kernel que serão executadas por cada thread e então especificarão o número do grupo de threads(também conhecido como bloco em CUDA) na grade e número de threads em cada grupo de threads, o Metal executará kernels nesta grade, o kernel é implementado em um dialeto C++ 14 chamado linguagem de sombreamento Metal. Dentro de cada grupo de threads, existe uma unidade menor chamada grupo SIMD, que significa um grupo de threads que compartilham as mesmas instruções SIMD. Mas na nossa implementação, não há necessidade de considerar isso.
Metal fornece uma API chamada MTLCommandBuffer que armazena comandos codificados que são confirmados e executados pela GPU. Cada vez que quisermos iniciar uma tarefa a ser executada pela GPU, as funções pré-compiladas do kernel serão codificadas em instruções da GPU, incorporadas no pipeline de sombreamento Metal e enviadas para MTLCommandBuffer. O buffer Metal usado para armazenar o parâmetro de cálculo que precisa ser passado para o dispositivo também é definido nesta fase. Então, com um número especificado de grupos de threads e threads por grupo, o comando manipulado pelo buffer de comando seria completamente codificado e pronto para ser confirmado no dispositivo. A GPU irá agendar a tarefa e notificar o thread da CPU que envia o trabalho após o término da execução.
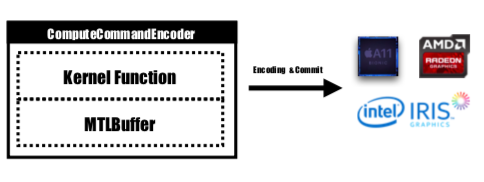
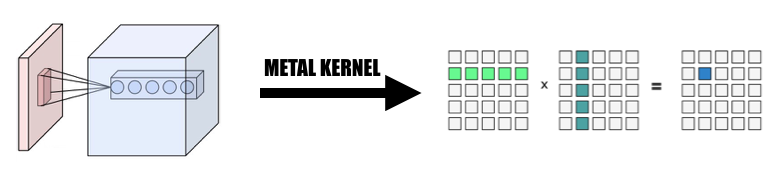
A função do kernel seria codificada por MTLComputeCommandEncoder e a tarefa seria criada para todas as plataformas suportadas.
Em nossa implementação, utilizamos amplamente uma maneira intuitiva de mapear o elemento em threads de GPU: mapeamos cada elemento no tensor de saída da camada atual para um thread de GPU: cada thread calcula e atualiza exatamente um elemento da saída, e a entrada será somente leitura, portanto não precisamos nos preocupar com a sincronização entre threads. Nesse mapeamento, threads com IDs contínuos podem ler dados de entrada de diferentes locais de memória, mas sempre gravarão em locais de memória contínua. Portanto, não haverá operações de dispersão quando um grupo SIMD estiver gravando na memória.
Projetamos uma classe tensora Variable como a base de toda a implementação, utilizamos e encapsulamos a operação de álgebra linear na classe Variable em vez de escrever um kernel adicional para nos aprofundarmos na operação que não é nosso foco principal para reduzir a complexidade da implementação e economizando nosso tempo para nos concentrarmos na aceleração das camadas de rede.
1. Mude a convolução para multiplicação de matrizes gigantes
Coletamos os dados da entrada de maneira paralelizada para formar uma matriz gigante da variável de entrada e do peso. Armazenamos em cache o peso de cada camada convolucional para evitar o recálculo. O preenchimento da camada convolucional seria gerado durante a transformação de paralelização durante o cálculo, então invocamos o MPSMatrixMultiply para a matriz gigante e transformamos os dados da matriz gigante de volta na classe de tensor normal que criamos. O método é descrito nos slides da aula.
2. O design e implementação da classe Variável
A classe variável é a base de nossa implementação como representação tensorial. Encapsulamos o MPSMatrixMultiplication para a variável (definimos o sinal de multiplicação Unicode (×) como um operador infixo para representá-lo com elegância :-)).
A estrutura de dados subjacente da variável é um UnsafemutableBufferPointer que aponta para o tipo de dados. Escolhemos Float de 32 bits para simplificar. A classe Variable manteve dois tamanhos de dados, a count continha o número do elemento que realmente armazenou, o actualCount é o tamanho de todos os elementos arredondado para o tamanho da página da plataforma obtido usando getpagesize() .
Mantemos esses dois valores para garantir que makeBuffer(bytesNoCopy:) crie o buffer diretamente na região da VM especificada e evite realocação redundante que reduz a sobrecarga. Se a memória a ser passada para o Metal não estiver alinhada à página, o Metal não poderá usar essa memória como buffer de entrada ou saída. Teremos que usar o método makeBuffer(bytes:) , que criará um novo buffer e copiará os dados do local da memória de entrada. Portanto, sempre precisamos alocar mais memória do que o necessário para garantir que todas as memórias em Variable estejam alinhadas às páginas. Portanto, precisamos de dois valores para controlar o tamanho exato desse pedaço de memória e o tamanho que devemos usar.
3. Número de elementos processados por um único thread
Tentamos mapear uma thread para vários elementos, de 2 a 16 elementos por thread, o desempenho é quase o mesmo, mas muita complexidade é adicionada ao nosso projeto, então descartamos essa abordagem.
Todas as versões de CPU mencionadas abaixo são códigos de CPU ingênuos de thread único sem otimização SIMD. A otimização do compilador no nível -Ofast é aplicada.
O desempenho da nossa implementação é bom, mas não o suficiente.
Aplicamos o iPhone 6s e um MacBook Pro de 15 polegadas como plataforma de referência. O hardware é especificado abaixo:
MacBook Pro (Retina de 15 polegadas, meados de 2015)
iPhone 6S
Comparando com a implementação ingênua da versão CPU sem paralelismo, nossa versão GPU é mais de 60x mais rápida .
Como o modelo MNIST é muito pequeno, seu resultado pode não refletir a aceleração precisa. E não temos uma versão single-thread bem implementada, não podemos fornecer um número preciso de aceleração. Como a versão da CPU é muito lenta, a aceleração do Tiny YOLO é grande demais para acreditar.
Atributo de rede experimental:
MNIST:
YOLO:
Resultado da medição:
| iPhone 6s | MNIST | YOLO minúsculo |
|---|---|---|
| CPU | 1500ms | 753 |
| GPU | 0,025s | 0,5s |
| acelerar | ~60x | ~1500x |
| MacBook Pro | MNIST | YOLO minúsculo |
|---|---|---|
| CPU | 650ms | 729 |
| GPU | 10ms | 0,028s |
| acelerar | ~65x | ~26.000x |
Com base no benchmark acima, podemos ver que à medida que o tamanho do problema aumenta,
Por que dizemos que nossa aceleração não é boa o suficiente? Porque quando comparamos com a implementação oficial do MPSCNNConvolution da Apple, somos apenas cerca de um terço mais rápidos, o que significa que ainda há muito espaço de otimização. Esta comparação é baseada em uma implementação de código aberto do YOLO no iPhone usando MPSCNNConvolution oficial, que pode reconhecer aproximadamente 5 imagens por segundo, enquanto nossa implementação só pode atingir aproximadamente 2 imagens por segundo.
E devido ao tempo limitado, não conseguimos criar uma versão de linha de base melhor e uma versão paralelizada de CPU para fazer o benchmark, o que torna o número de aceleração muito grande.
Também vale a pena relatar o ganho de desempenho em diferentes tamanhos de problemas. Como podemos ver, o MNIST tem apenas 0,1 milhão de pesos, enquanto o Tiny YOLO tem 17 milhões. O Tiny YOLO é muito mais complexo que o MNIST, mas o tempo de execução da versão GPU não aumentou muito. Novamente, isso se deve à lei de Amdahl. Cada tarefa de GPU é iniciada, os comandos de GPU correspondentes precisam ser codificados no buffer de comando. Este processo é inerentemente serial. Quando o tamanho do problema é pequeno, esse processo contribui muito para o tempo total de execução, portanto, ao paralelizar o estágio de inferência da rede neural no MINST, pode não obter a mesma velocidade que no Tiny YOLO, onde a sobrecarga do tempo de execução é negligenciável.
O que limitou sua aceleração?
if se for s que podem causar divergência, levando a uma utilização deficiente do SIMD.Análise mais aprofundada: detalhamento do tempo de execução das diferentes fases.
Tomemos como exemplo o Tiny YOLO, em uma execução de amostra com tempo total de execução de 227 ms no Macbook, as camadas convolucionais usaram 207 ms, 92% do tempo total de execução. As camadas Pooling usaram 14ms(6%) e ReLU usou 6ms(2%). De acordo com a lei de Amdahl, se quisermos melhorar ainda mais o desempenho, devemos definitivamente continuar trabalhando na camada convolucional.
No geral, acreditamos que nossa escolha da estrutura Metal para acelerar a rede neural em dispositivos iOS e macOS é acertada, especialmente para dispositivos iOS. Como possui menos núcleos, mesmo com instruções SIMD, uma versão de CPU bem ajustada tem menos probabilidade de obter desempenho semelhante à versão de GPU.
Trabalhos iguais são realizados por ambos os membros da equipe.
1 https://developer.apple.com/metal/ ↩
2 https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf ↩
3 http://pytorch.org ↩
4 https://github.com/BVLC/caffe ↩
5 https://developer.apple.com/documentation/metal/compute_processing/about_threads_and_threadgroups ↩
6 https://developer.apple.com/library/content/documentation/Miscellaneous/Conceptual/MetalProgrammingGuide/Render-Ctx/Render-Ctx.html ↩


