Image to text chrome extension
1.0.0
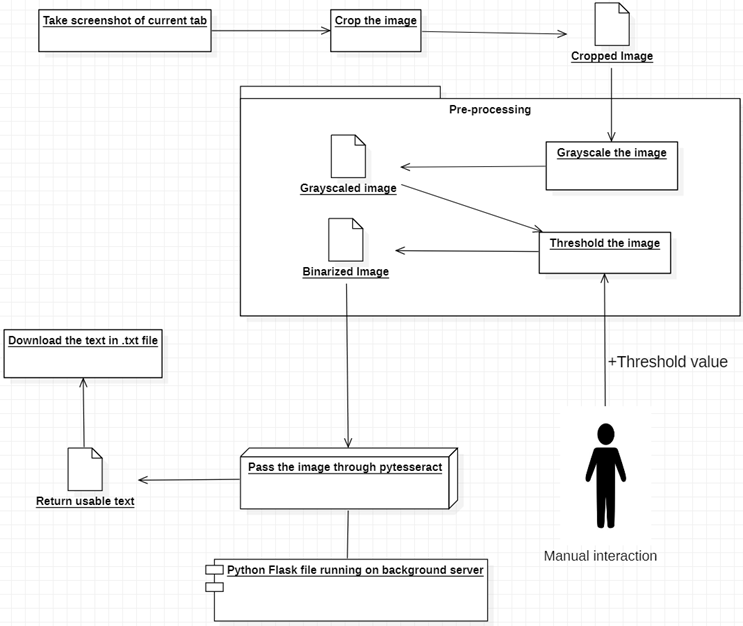
Uma extensão do Chrome que pode reconhecer qualquer tipo de texto em seu navegador a partir de qualquer vídeo ou imagem usando o conceito de OCR. OCR é a forma abreviada de reconhecimento óptico de caracteres ou outro texto de localização de palavras em imagens. O Google já havia lançado um mecanismo chamado Tesseract OCR, isso significa que o Google fornece um programa que já possui reconhecimento de texto treinado, para que eu não precise fazer coisas complicadas, como treinar os dados em OCR sozinho. Mas para sermos mais precisos, temos que pré-processar a imagem antes de passá-la pelo Tesseract, pois o Tesseract tem algumas circunstâncias predefinidas que precisam ser seguidas para obter um resultado preciso. Portanto, para a funcionalidade de nossa extensão, primeiro ela tira uma captura de tela da guia aberta no momento, depois recorta a parte desejada usando a tela e ajusta-a usando binarização de limite para que possa preencher os requisitos de OCR para fornecer resultados mais precisos. Em seguida, envie-o para o pytesseract (versão Python do Tesseract) para que ele possa convertê-lo. Ao final pegue o texto e baixe-o em formato de arquivo .txt. Assim o usuário pode abri-lo no bloco de notas ou qualquer outro editor de texto e comparar e modificar o texto se necessário.
Muitas vezes encontro trechos de código no YouTube ou em qualquer outro site, mas aprecio muito o esforço que os criadores de tutoriais colocam em seus vídeos sempre que encontro um trecho de código que não fornece um link para baixá-lo ou copiá-lo. Então, para obter os códigos desses vídeos, fiz este projeto com a ajuda do plugin tesseract para poder extrair o texto desses vídeos ou imagens.
A implementação e demonstração dos módulos podem ser encontradas no ppt.
pip install pytesseract
npm i flask
O arquivo jQuery min está anexado aos arquivos, caso você queira alterá-lo ou usar a abordagem cdn, você pode alterá-lo.


