Scraping Dynamic JavaScript Ajax Websites With BeautifulSoup
1.0.0

JavaScript ?Browser sem cabeçaWeb scraping na maioria dos sites pode ser comparativamente fácil. Este tópico já foi abordado detalhadamente neste tutorial. Existem muitos sites, entretanto, que não podem ser copiados usando o mesmo método. A razão é que esses sites carregam o conteúdo dinamicamente usando JavaScript.
Essa técnica também é conhecida como AJAX (Asynchronous JavaScript and XML). Historicamente, esse padrão foi incluído na criação de um objeto XMLHttpRequest para recuperar XML de um servidor web sem recarregar a página inteira. Hoje em dia, esse objeto raramente é usado diretamente. Normalmente, um wrapper como jQuery é usado para recuperar conteúdo como JSON, HTML parcial ou até mesmo imagens.
Para copiar uma página da web normal, são necessárias pelo menos duas bibliotecas. A biblioteca requests baixa a página. Assim que esta página estiver disponível como uma string HTML, a próxima etapa é analisá-la como um objeto BeautifulSoup. Este objeto BeautifulSoup pode então ser usado para localizar dados específicos.
Aqui está um exemplo de script simples que imprime o texto dentro do elemento h1 com id definido como firstHeading .
import requests
from bs4 import BeautifulSoup
response = requests . get ( "https://quotes.toscrape.com/" )
bs = BeautifulSoup ( response . text , "lxml" )
author = bs . find ( "small" , class_ = "author" )
if author :
print ( author . text )
## OUTPUT
# Albert EinsteinObserve que estamos trabalhando com a versão 4 da biblioteca Beautiful Soup. Versões anteriores foram descontinuadas. Você pode ver a bela sopa 4 sendo escrita apenas como Beautiful Soup, BeautifulSoup ou mesmo bs4. Todos eles se referem à mesma bela biblioteca de sopa 4.
O mesmo código não funcionará se o site for dinâmico. Por exemplo, o mesmo site possui uma versão dinâmica em https://quotes.toscrape.com/js/ (observe js no final desta URL).
response = requests . get ( "https://quotes.toscrape.com/js" ) # dynamic web page
bs = BeautifulSoup ( response . text , "lxml" )
author = bs . find ( "small" , class_ = "author" )
if author :
print ( author . text )
## No output A razão é que o segundo site é dinâmico onde os dados estão sendo gerados usando JavaScript .
Existem duas maneiras de lidar com sites como este.
Essas duas abordagens são abordadas detalhadamente neste tutorial.
Porém, primeiro precisamos entender como determinar se um site é dinâmico.
Esta é a maneira mais fácil de determinar se um site é dinâmico usando o Chrome ou Edge. (Ambos os navegadores usam o Chromium nos bastidores).
Abra as Ferramentas do Desenvolvedor pressionando a tecla F12 . Certifique-se de que o foco esteja nas ferramentas do desenvolvedor e pressione a combinação de teclas CTRL+SHIFT+P para abrir o Menu de Comando.
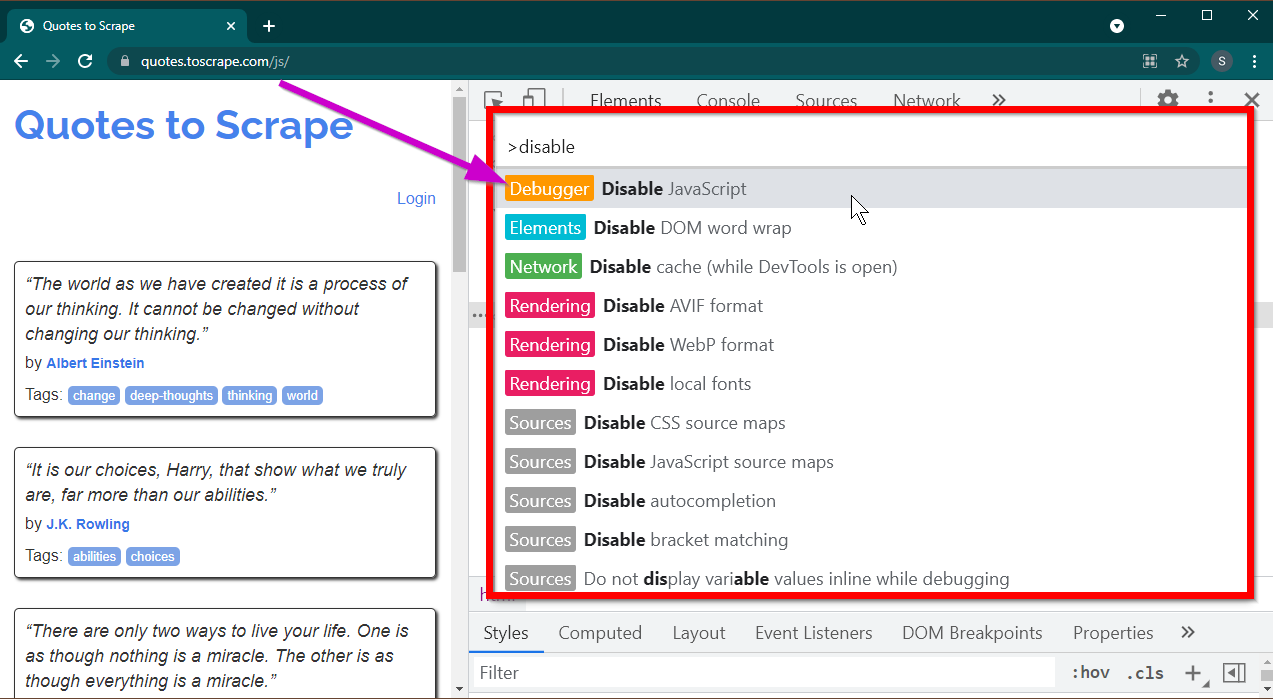
Ele mostrará muitos comandos. Comece a digitar disable e os comandos serão filtrados para mostrar Disable JavaScript . Selecione esta opção para desativar JavaScript .
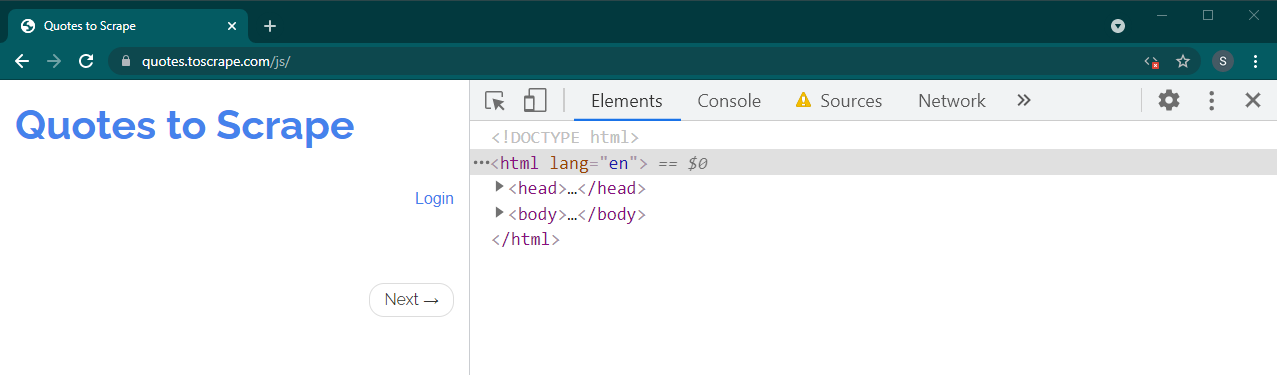
Agora recarregue esta página pressionando Ctrl+R ou F5 . A página será recarregada.
Se este for um site dinâmico, muito conteúdo desaparecerá:
Em alguns casos, os sites ainda mostrarão os dados, mas voltarão à funcionalidade básica. Por exemplo, este site tem uma rolagem infinita. Se o JavaScript estiver desabilitado, ele mostra a paginação regular.
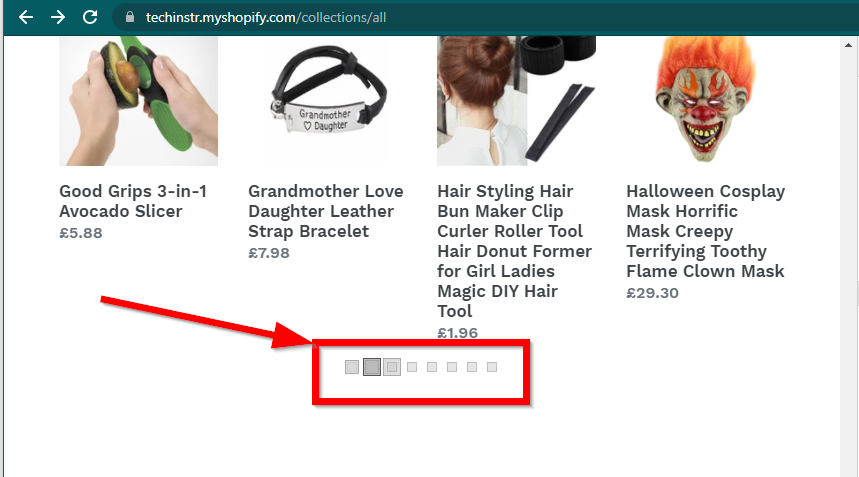 | 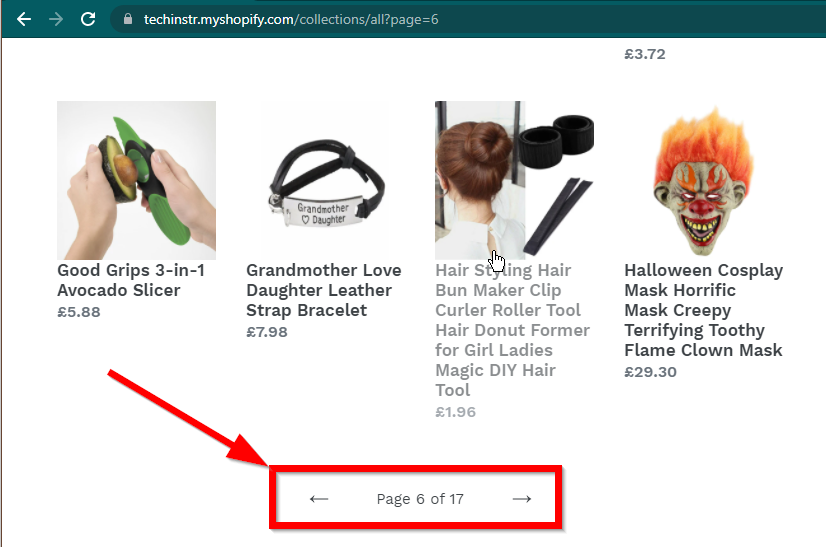 |
|---|---|
| JavaScript ativado | JavaScript desativado |
A próxima pergunta que precisa ser respondida são os recursos do BeautifulSoup.
JavaScript ?A resposta curta é não.
É importante entender palavras como análise e renderização. A análise é simplesmente converter uma representação de string de um objeto Python em um objeto real.
Então, o que é renderização? Renderizar é essencialmente interpretar HTML, JavaScript, CSS e imagens em algo que vemos no navegador.
Beautiful Soup é uma biblioteca Python para extrair dados de arquivos HTML. Isso envolve a análise da string HTML no objeto BeautifulSoup. Para análise, primeiro precisamos do HTML como string, para começar. Sites dinâmicos não possuem os dados diretamente no HTML. Isso significa que o BeautifulSoup não pode funcionar com sites dinâmicos.
A biblioteca Selenium pode automatizar o carregamento e renderização de sites em um navegador como Chrome ou Firefox. Embora o Selenium suporte a extração de dados do HTML, é possível extrair o HTML completo e usar o Beautiful Soup para extrair os dados.
Vamos começar primeiro o web scraping dinâmico com Python usando Selenium.
A instalação do Selenium envolve a instalação de três coisas:
O navegador de sua preferência (que você já possui):
O driver para o seu navegador:
Pacote Python Selênio:
pip install seleniumconda-forge . conda install -c conda-forge selenium O esqueleto básico do script Python para iniciar um navegador, carregar a página e fechar o navegador é simples:
from selenium . webdriver import Chrome
from webdriver_manager . chrome import ChromeDriverManager
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )
#
# Code to read data from HTML here
#
driver . quit ()Agora que podemos carregar a página no navegador, vamos extrair elementos específicos. Existem duas maneiras de extrair elementos – Selênio e Beautiful Soup.
Nosso objetivo neste exemplo é encontrar o elemento autor.
Carregue o site https://quotes.toscrape.com/js/ no Chrome, clique com o botão direito no nome do autor e clique em Inspecionar. Isso deve carregar as Ferramentas do Desenvolvedor com o elemento autor destacado da seguinte forma:
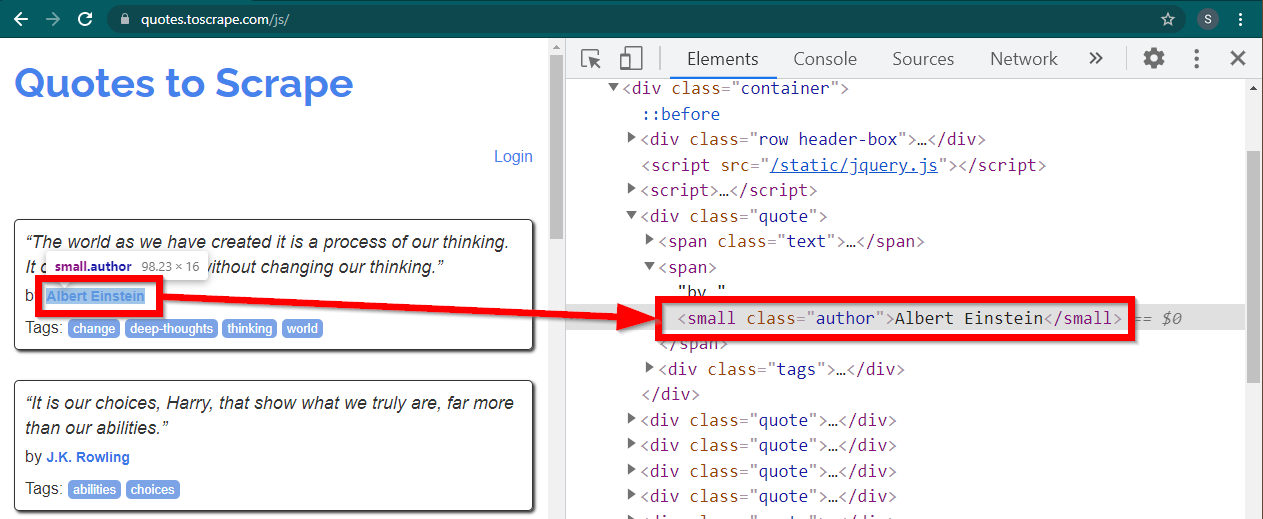
Este é um small elemento com seu atributo class definido como author .
< small class =" author " > Albert Einstein </ small >O Selenium permite vários métodos para localizar os elementos HTML. Esses métodos fazem parte do objeto driver. Alguns dos métodos que podem ser úteis aqui são os seguintes:
element = driver . find_element ( By . CLASS_NAME , "author" )
element = driver . find_element ( By . TAG_NAME , "small" )Existem alguns outros métodos que podem ser úteis para outros cenários. Esses métodos são os seguintes:
element = driver . find_element ( By . ID , "abc" )
element = driver . find_element ( By . LINK_TEXT , "abc" )
element = driver . find_element ( By . XPATH , "//abc" )
element = driver . find_element ( By . CSS_SELECTOR , ".abc" ) Talvez os métodos mais úteis sejam find_element(By.CSS_SELECTOR) e find_element(By.XPATH) . Qualquer um desses dois métodos deverá ser capaz de selecionar a maioria dos cenários.
Vamos modificar o código para que o primeiro autor possa ser impresso.
from selenium . webdriver import Chrome
from selenium . webdriver . common . by import By
from webdriver_manager . chrome import ChromeDriverManager
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )
element = driver . find_element ( By . CLASS_NAME , "author" )
print ( element . text )
driver . quit ()E se você quiser imprimir todos os autores?
Todos os métodos find_element possuem uma contraparte - find_elements . Observe a pluralização. Para encontrar todos os autores, basta alterar uma linha:
elements = driver . find_elements ( By . CLASS_NAME , "author" )Isso retorna uma lista de elementos. Podemos simplesmente executar um loop para imprimir todos os autores:
for element in elements :
print ( element . text )Nota: O código completo está no arquivo de código selenium_example.py.
No entanto, se você já estiver familiarizado com BeautifulSoup, poderá criar o objeto Beautiful Soup.
Como vimos no primeiro exemplo, o objeto Beautiful Soup precisa de HTML. Para sites estáticos de web scraping, o HTML pode ser recuperado usando a biblioteca requests . A próxima etapa é analisar essa string HTML no objeto BeautifulSoup.
response = requests . get ( "https://quotes.toscrape.com/" )
bs = BeautifulSoup ( response . text , "lxml" )Vamos descobrir como criar um site dinâmico com BeautifulSoup.
A parte a seguir permanece inalterada em relação ao exemplo anterior.
from selenium . webdriver import Chrome
from webdriver_manager . chrome import ChromeDriverManager
from bs4 import BeautifulSoup
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' ) O HTML renderizado da página está disponível no atributo page_source .
soup = BeautifulSoup ( driver . page_source , "lxml" )Assim que o objeto sopa estiver disponível, todos os métodos Beautiful Soup poderão ser usados normalmente.
author_element = soup . find ( "small" , class_ = "author" )
print ( author_element . text )Nota: O código fonte completo está em selenium_bs4.py
Browser sem cabeçaDepois que o script estiver pronto, não será necessário que o navegador fique visível quando o script estiver em execução. O navegador pode estar oculto e o script ainda funcionará bem. Esse comportamento de um navegador também é conhecido como navegador sem cabeça.
Para deixar o navegador sem cabeça, importe ChromeOptions . Para outros navegadores, suas próprias classes Options estão disponíveis.
from selenium . webdriver import ChromeOptions Agora, crie um objeto desta classe e defina o atributo headless como True.
options = ChromeOptions ()
options . headless = TruePor fim, envie este objeto ao criar a instância do Chrome.
driver = Chrome ( ChromeDriverManager (). install (), options = options )Agora, quando você executar o script, o navegador não estará visível. Consulte o arquivo selenium_bs4_headless.py para a implementação completa.
Carregar o navegador é caro – consome CPU, RAM e largura de banda que não são realmente necessárias. Quando um site está sendo copiado, são os dados que são importantes. Todos aqueles CSS, imagens e renderização não são realmente necessários.
A maneira mais rápida e eficiente de extrair páginas da web dinâmicas com Python é localizar o local real onde os dados estão localizados.
Existem dois locais onde esses dados podem ser localizados:
<script>Vejamos alguns exemplos.
Abra https://quotes.toscrape.com/js no Chrome. Assim que a página for carregada, pressione Ctrl+U para visualizar a fonte. Pressione Ctrl+F para abrir a caixa de pesquisa, procure Albert.
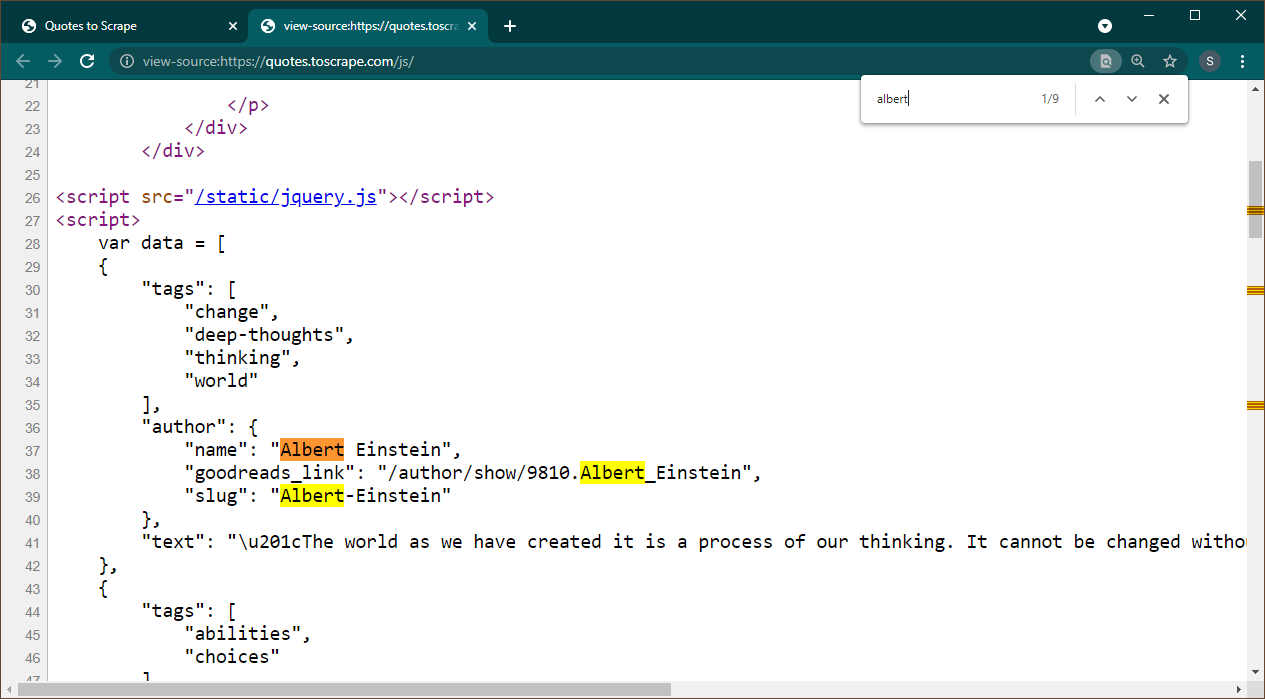
Podemos ver imediatamente que os dados estão incorporados como um objeto JSON na página. Além disso, observe que isso faz parte de um script onde esses dados estão sendo atribuídos a uma variável data .
Nesse caso, podemos usar a biblioteca Requests para obter a página e usar Beautiful Soup para analisar a página e obter o elemento do script.
response = requests . get ( 'https://quotes.toscrape.com/js/' )
soup = BeautifulSoup ( response . text , "lxml" ) Observe que existem vários elementos <script> . Aquele que contém os dados que precisamos não possui o atributo src . Vamos usar isso para extrair o elemento script.
script_tag = soup . find ( "script" , src = None )Lembre-se que este script contém outro código JavaScript além dos dados que nos interessam. Por isso, usaremos uma expressão regular para extrair esses dados.
import re
pattern = "var data =(.+?); n "
raw_data = re . findall ( pattern , script_tag . string , re . S )A variável de dados é uma lista contendo um item. Agora podemos usar a biblioteca JSON para converter esses dados de string em um objeto python.
if raw_data :
data = json . loads ( raw_data [ 0 ])
print ( data )A saída será o objeto python:
[{ 'tags' : [ 'change' , 'deep-thoughts' , 'thinking' , 'world' ], 'author' : { 'name' : 'Albert Einstein' , 'goodreads_link' : '/author/show/9810.Albert_Einstein' , 'slug' : 'Albert-Einstein' }, 'text' : '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”' }, { 'tags' : [ 'abilities' , 'choices' ], 'author' : { 'name' : 'J.K. Rowling' , .....................Esta lista não pode ser convertida para nenhum formato conforme necessário. Além disso, observe que cada item contém um link para a página do autor. Isso significa que você pode ler esses links e criar um spider para obter dados de todas essas páginas.
Este código completo está incluído em data_in_same_page.py.
Sites dinâmicos de web scraping podem seguir um caminho completamente diferente. Às vezes, os dados são carregados em uma página separada. Um exemplo é o Librivox.
Abra as Ferramentas do Desenvolvedor, vá para a guia Rede e filtre por XHR. Agora abra este link ou pesquise qualquer livro. Você verá que os dados são um HTML incorporado em JSON.
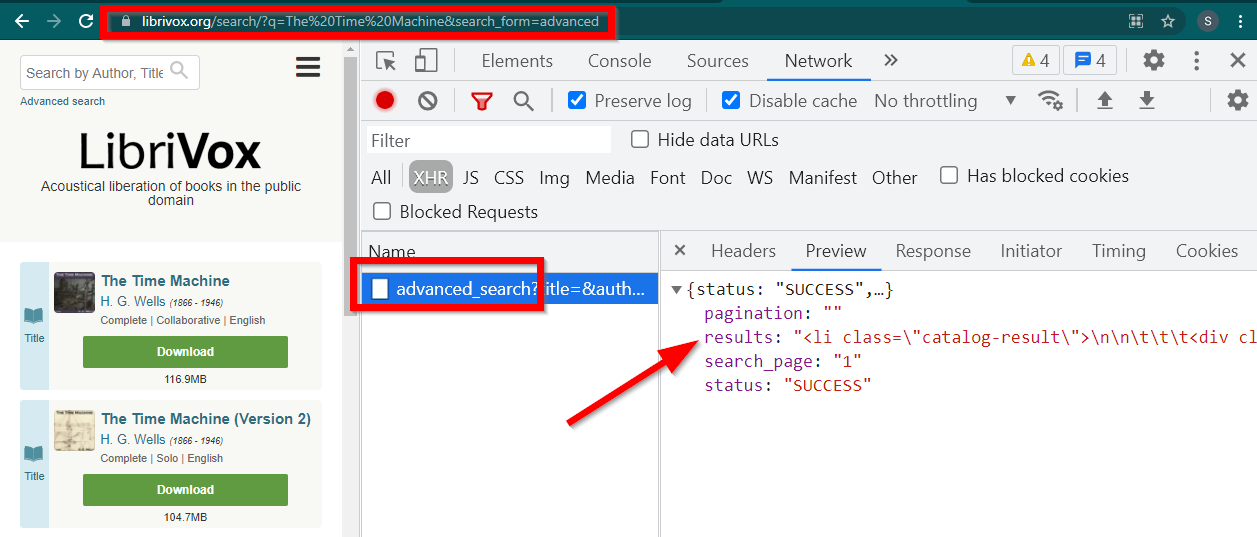
Observe algumas coisas:
A URL exibida pelo navegador é https://librivox.org/search/?q=...
Os dados estão em https://librivox.org/advanced_search?....
Se você observar os cabeçalhos, descobrirá que a página advanced_search recebe um cabeçalho especial X-Requested-With: XMLHttpRequest
Aqui está um trecho para extrair esses dados:
headers = {
'X-Requested-With' : 'XMLHttpRequest'
}
url = 'https://librivox.org/advanced_search?title=&author=&reader=&keywords=&genre_id=0&status=all&project_type=either&recorded_language=&sort_order=alpha&search_page=1&search_form=advanced&q=The%20Time%20Machine'
response = requests . get ( url , headers = headers )
data = response . json ()
soup = BeautifulSoup ( data [ 'results' ], 'lxml' )
book_titles = soup . select ( 'h3 > a' )
for item in book_titles :
print ( item . text )O código completo está incluído no arquivo librivox.py.


