disclosure backend static
1.0.0
O repositório disclosure-backend-static é o back-end que alimenta o Open Disclosure California.
Foi criado às pressas antes das eleições de 2016 e, portanto, é concebido em torno de uma filosofia de “fazer acontecer”. Naquela época, já havíamos projetado uma API e construído (a maior parte) um frontend; este repositório foi criado para implementá-los o mais rápido possível.
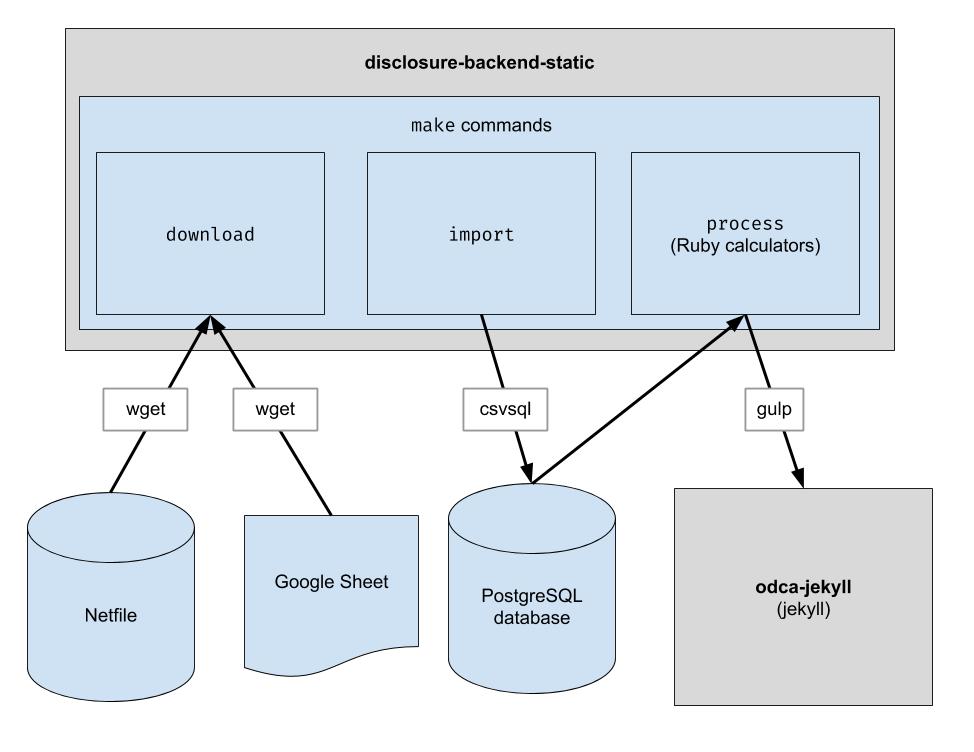
Este projeto implementa um pipeline ETL básico para baixar os dados do netfile de Oakland, baixar os dados CSV com curadoria humana para Oakland e combinar os dois. A saída é um diretório de arquivos JSON que imitam a estrutura da API existente, portanto, nenhuma alteração no código do cliente será necessária.
.ruby-version ) Nota: Você não precisa executar esses comandos para desenvolver no frontend. Tudo que você precisa fazer é clonar o repositório adjacente ao repositório frontend.
Se você planeja modificar o código backend, siga estas etapas para configurar todas as dependências de desenvolvimento necessárias, incluindo um novo banco de dados PostgreSQL e Python 3:
brew update && brew upgrade
brew install postgresql@16
brew services start postgresql@16
python3 -m pip em vez de pip para garantir que o Python 3 seja usado: python3 -m pip install ...
pip do seu sistema apontar para Python 3, você pode usar pip diretamente: pip install ...
sudo -H python -m pip install -r requirements.txt
gem install pg bundler
bundle install
Este repositório está configurado para funcionar em um contêiner em Codespaces. Em outras palavras, você pode iniciar um ambiente que já esteja configurado sem precisar executar nenhuma das etapas de instalação necessárias para configurar um ambiente local. Isso pode ser usado como uma forma de solucionar problemas de código antes que ele seja enviado ao pipeline de produção. As informações a seguir podem ser úteis para começar a usar Codespaces:
Code e clique na guia Codespaces no menu suspenso/workspace seja apresentado na página da web, o que parecerá familiar se você já trabalhou com o VS Code antesmake downloadpsql no terminal para se conectar ao servidormake import preencherá o banco de dados Postgresgit pushEste repositório também está configurado para ser executado em um contêiner Docker. Isso é semelhante aos Codespaces, exceto que você pode usar qualquer IDE e configuração local de sua preferência. Veja como começar a usar o Docker com VSCode:
Baixe os arquivos de dados brutos. Você só precisa executar isso de vez em quando para obter os dados mais recentes.
$ make download
Importe os dados para o banco de dados para facilitar o processamento. Você só precisa executar isso depois de baixar novos dados.
$ make import
Execute as calculadoras. Tudo é enviado para a pasta "build".
$ make process
Opcionalmente, reindexe as saídas do build no Algolia. (A reindexação requer as variáveis de ambiente ALGOLIASEARCH_APPLICATION_ID e ALGOLIASEARCH_API_KEY).
$ make reindex
Se você quiser servir os arquivos JSON estáticos por meio de um servidor web local:
$ make run
Quando make import é executado, várias tabelas postgres são criadas para importar os dados baixados. O esquema dessas tabelas é definido explicitamente no diretório dbschema e pode precisar ser atualizado no futuro para acomodar dados futuros. As colunas que contêm dados de string podem não ter tamanho suficiente para dados futuros. Por exemplo, se uma coluna de nome aceitar nomes com no máximo 20 caracteres e, no futuro, tivermos dados em que o nome tenha 21 caracteres, a importação de dados falhará. Quando isso ocorrer, teremos que atualizar o arquivo de esquema correspondente em dbschema para suportar mais caracteres. Basta fazer a alteração e executar novamente make import para verificar se foi bem-sucedido.
Este repositório é usado para gerar arquivos de dados que são utilizados pelo site. Após a execução make process , um diretório build é gerado contendo os arquivos de dados. Este diretório é verificado no repositório e posteriormente verificado ao gerar o site. Depois de fazer alterações no código, é importante comparar o diretório build gerado com o diretório build gerado antes das alterações no código e verificar se as alterações no código são conforme o esperado.
Como uma comparação estrita de todo o conteúdo do diretório build sempre incluirá alterações que ocorrem independentemente de qualquer alteração no código, todo desenvolvedor precisa saber sobre essas alterações esperadas para realizar essa verificação. Para eliminar a necessidade disso, um arquivo específico, bin/create-digests.py , gera resumos para dados JSON no diretório build após excluir essas alterações esperadas. Para procurar alterações que excluam essas alterações esperadas, basta procurar uma alteração no arquivo build/digests.json .
Atualmente, estas são as alterações esperadas que ocorrem independentemente de qualquer alteração no código:
As alterações esperadas são excluídas antes de gerar resumos de dados no diretório build . A lógica para isso pode ser encontrada na função clean_data , encontrada no arquivo bin/create-digests.py . Depois que o código for modificado de forma que uma alteração esperada não exista mais, a exclusão dessa alteração poderá ser removida de clean_data . Por exemplo, o arredondamento de floats não é consistentemente o mesmo cada vez que make process é executado, devido a diferenças no ambiente. Quando o código é corrigido para que o arredondamento dos pontos flutuantes seja o mesmo, desde que os dados não tenham sido alterados, a chamada round_float em clean_data pode ser removida.
Foi criado um script adicional para gerar um relatório que permite comparar os totais dos candidatos. O script é bin/report-candidates.py e gera build/candidates.csv e build/candidates.xlsx . Os relatórios incluem uma lista de todos os candidatos e totais calculados de várias maneiras que devem somar o mesmo número.
Para garantir que as alterações no esquema do banco de dados sejam visíveis nas solicitações pull, o esquema postgres completo também é salvo em um arquivo schema.sql no diretório build . Como o diretório build é reconstruído automaticamente para cada ramificação em um PR e confirmado no repositório, qualquer alteração no esquema causada por uma alteração de código será mostrada como uma diferença no arquivo schema.sql ao revisar o PR.
Cada métrica sobre um candidato é calculada de forma independente. Uma métrica pode ser algo como “total de contribuições recebidas” ou algo mais complexo como “porcentagem de contribuições inferiores a US$ 100”.
Ao adicionar um novo cálculo, um bom primeiro lugar para começar é o Formulário 460 oficial. Os dados que você procura estão relatados nesse formulário? Se sim, provavelmente você o encontrará em seu banco de dados após o processo de importação. Existem também alguns outros formulários que importamos, como o Formulário 496. (Esses são os nomes dos arquivos no diretório input . Verifique-os.)
Cada programação de cada formulário é importada para uma tabela postgres separada. Por exemplo, o Cronograma A do Formulário 460 é importado para a tabela A-Contributions .
Agora que você tem uma maneira de consultar os dados, você deve criar uma consulta SQL que calcule o valor que você está tentando obter. Depois que você puder expressar seu cálculo como SQL, coloque-o em um arquivo de calculadora assim:
calculators/[your_thing]_calculator.rb # the name of this class _must_ match the filename of this file, i.e. end
# with "Calculator" if the file ends with "_calculator.rb"
class YourThingCalculator
def initialize ( candidates : [ ] , ballot_measures : [ ] , committees : [ ] )
@candidates = candidates
@candidates_by_filer_id = @candidates . where ( '"FPPC" IS NOT NULL' )
. index_by { | candidate | candidate [ 'FPPC' ] }
end
def fetch
@results = ActiveRecord :: Base . connection . execute ( <<-SQL )
-- your sql query here
SQL
@results . each do | row |
# make sure Filer_ID is returned as a column by your query!
candidate = @candidates_by_filer_id [ row [ 'Filer_ID' ] . to_i ]
# change this!
candidate . save_calculation ( :your_thing , row [ column_with_your_desired_data ] )
end
end
endFiler_ID .candidate.save_calculation . Esse método serializará seu segundo argumento como JSON, para que possa armazenar qualquer tipo de dados.candidate.calculation(:your_thing) . Você desejará adicionar isso a uma resposta da API no arquivo process.rb . É assim que os dados fluem pelo back-end. Os dados financeiros são extraídos do Netfile, que é complementado por uma planilha do Google que mapeia IDs de arquivo para informações eleitorais, como nomes de candidatos, cargos, medidas eleitorais, etc. Depois que os dados são filtrados, agregados e transformados, o front-end os consome e cria o HTML estático front-end.
Durante a instalação do pacote
error: use of undeclared identifier 'LZMA_OK'
Tentar:
brew unlink xz
bundle install
brew link xz
Durante make download
wget: command not found
Execute brew install wget .
Durante make import
Parece que há um problema em sistemas Macintosh que usam chips Apple.
ImportError: You don't appear to have the necessary database backend installed for connection string you're trying to use. Available backends include:
PostgreSQL: pip install psycopg2
Experimente o seguinte:
pip uninstall psycopg2-binary
pip install psycopg2-binary --no-cache-dir


