baker example page template
1.0.0
Uma demonstração de como construir e publicar páginas com a ferramenta Baker Build.
O Los Angeles Times usa o Baker para criar as páginas estáticas publicadas em latimes.com/projects. O sistema do Times depende de uma versão privada de um repositório muito parecido com este. Este exemplo simplificado publica versões de preparação e produção em buckets públicos no Amazon S3.
Servidor de teste local com atualização ao vivo
Modelagem HTML com Nunjucks
CSS estendido com Sass
Pacote JavaScript com Rollup e Babel
Importações de dados com quaff
Geração dinâmica de páginas com base em entradas estruturadas
Implantação automática de cada branch em um ambiente de teste em cada evento push por meio do GitHub Action
Implantação de botão no ambiente de produção em cada evento release por meio do GitHub Action
Mensagens do Slack que retransmitem o status de cada implantação via datadesk/notify-slack-on-build Github Action
Node.js versão 12, 14 ou 16, embora no mínimo 12.20, 14.14 ou 16.0.
Gerenciador de pacotes de nós
idiota
Com um pouco de configuração, você pode usar este modelo para publicar uma página facilmente. Com um pouco de personalização, você pode fazer com que fique da maneira que desejar. Este guia apresentará o básico.
Criando uma nova página
Explorando o repositório
Acessando ativos
Acessando dados
Páginas dinâmicas
Implantação
Variáveis globais
padeiro.config.js
A primeira etapa é clicar no botão “usar este modelo” do GitHub para fazer uma cópia do repositório para você.
Você será solicitado a fornecer um slug para o seu projeto. Feito isso, um novo repositório estará disponível em https://github.com/your-username/your-slug .
Em seguida, você precisará cloná-lo em seu computador para trabalhar com o código.
Abra seu terminal e faça cd para sua pasta de código. Clone o projeto em sua pasta. Isso copiará o projeto para o seu computador.
clone do git https://github.com/seu-nomedeusuário/seu-slug
Se esse comando não funcionar para você, pode ser porque seu computador foi configurado de forma diferente e você precisa clonar para o repositório usando SSH. Tente executar isso no seu terminal:
git clone [email protected]:seu-nome de usuário/seu-slug.git
Assim que o download do repositório terminar, faça cd em seu slug e instale as dependências do Node.js.
instalação npm
Depois que as dependências forem instaladas, você estará pronto para visualizar o projeto. Execute o seguinte para iniciar o servidor de teste.
npm início
Agora vá para localhost:3000 no seu navegador. Você deverá ver uma página padrão pronta para suas personalizações.
Um caminho alternativo é criar uma nova página com blprint, a ferramenta de estrutura de linha de comando desenvolvida pelo departamento gráfico da Reuters.
modelo adicionar https://github.com/datadesk/baker-example-page-template mkdir minha-nova-páginacd minha-nova-página projeto iniciar página de exemplo de padeiro
Aqui estão os arquivos e pastas padrão que você encontrará ao clonar um novo projeto a partir de nosso modelo de página. Você gastará mais tempo trabalhando com alguns arquivos do que com outros, mas é bom ter uma noção geral do que todos eles fazem.
A pasta de dados contém dados relevantes para o projeto. Usamos esta pasta para armazenar as informações necessárias sobre cada projeto - como em qual URL ele deve estar. Você também pode armazenar vários outros tipos de dados aqui, incluindo .aml , .csv e .json .
O arquivo meta.aml contém informações importantes sobre a página, como título, assinatura, slug, data de publicação e outros campos. O preenchimento garante que sua página seja exibida corretamente e possa ser indexada pelos mecanismos de busca. Uma lista completa de todos os atributos pode ser encontrada em nossos materiais de referência. Você pode expandir isso para incluir quantas opções desejar.
Esta pasta que armazena o modelo base do nosso site e trechos de código reutilizáveis. Quando você está começando, é improvável que você mude alguma coisa aqui. Em casos de uso mais avançados, é onde você pode armazenar código que é reutilizado em diversas páginas.
base.htmlO arquivo base.html contém todo o HTML fundamental encontrado em cada página que criamos. O exemplo aqui é rudimentar por design. Você provavelmente desejaria incluir muito mais em uma implementação no mundo real.
O espaço de trabalho é um local para você colocar qualquer coisa relevante ao projeto que não precise ser publicada na web. Arquivos AI, pedaços de código, escrita, etc.
Isso é usado para armazenar mídia e outros ativos, como imagens, vídeos, áudio, fontes, etc. Eles podem ser colocados na página por meio de tags de modelo static .
Os arquivos JavaScript são armazenados nesta pasta. O arquivo principal do JavaScript é chamado app.js , no qual você pode escrever seu código diretamente. Os pacotes instalados via npm podem ser importados e executados como qualquer outro script Node.js. Você pode criar outros arquivos para escrever seu código JavaScript nesta pasta, mas deve certificar-se de que o arquivo seja inicializado a partir de app.js .
Nossas folhas de estilo são escritas em SASS, uma poderosa linguagem de folhas de estilo que oferece aos desenvolvedores mais controle sobre CSS. Se você não se sentir confortável com o SASS, poderá escrever CSS simples nas folhas de estilo.
A pasta de estilos consiste em uma folha de estilo ( app.scss ) onde você pode adicionar todos os seus estilos personalizados ao seu projeto, embora às vezes você possa querer criar folhas de estilo adicionais e importá-las para app.scss . Este projeto de exemplo inclui apenas o mínimo necessário para simular um site simples. Você provavelmente gostaria de começar com muito mais em uma implementação no mundo real.
O arquivo baker.config.js é onde colocamos as opções que o Baker usa para servir e construir o projeto. Foi totalmente documentado em outras partes deste arquivo. Com exceção da configuração domain , apenas usuários avançados precisarão alterar este arquivo.
O modelo padrão para sua página. É aqui que você criará o layout de sua página. Ele usa o sistema de templates Nujucks para criar HTML.
Esses arquivos rastreiam as dependências do Node usadas em nossos projetos. Quando você executa npm install as bibliotecas adicionadas serão rastreadas automaticamente aqui para você.
Este é um diretório especial para armazenar arquivos que o GitHub usa para interagir com nossos projetos e códigos. O diretório .github/workflows contém o GitHub Action que lida com nossas implantações de desenvolvimento. Você não precisa editar nada aqui.
Os arquivos armazenados no diretório de ativos são otimizados e com hash como parte do processo de implantação. Para garantir que suas referências a imagens e outros arquivos estáticos, você deve usar a tag {% static %} . Isso garante que o arquivo seja fortemente armazenado em cache quando for publicado e que o link para a imagem funcione em todos os ambientes. Você vai querer usá-lo para todas as fotos e vídeos.
<figura>
<img src="{% static 'assets/images/baker.jpg' %}" alt="Logotipo Baker" width=200>
</figura> Arquivos de dados estruturados armazenados em sua pasta _data podem ser acessados via templatetags ou JavaScript. Nesta demonstração, um arquivo chamado example.json foi incluído para ilustrar o que é possível. Outros formatos de arquivo como CSV, YAML e AML são suportados.
Os arquivos na pasta _data estão disponíveis por nome nos seus modelos. Então, com _data/example.json , você pode escrever algo como:
{% para obj no exemplo %}
{{ obj.ano }}: {{ obj.wheat }}{% endfor %}Uma necessidade comum para qualquer pessoa que esteja construindo um projeto no Baker é acessar dados brutos dentro de um arquivo JavaScript. Freqüentemente, esses dados são repassados para o código escrito usando d3 ou Svelte para desenhar gráficos ou criar tabelas HTML na página.
Se os dados que você está acessando já estiverem disponíveis em um URL que você confia que permanecerá ativo, isso é fácil. Mas e se não for e forem dados que você mesmo preparou?
É possível acessar registros na sua pasta _data. A única ressalva é que o trabalho de converter este arquivo em um estado utilizável é de sua responsabilidade. Uma boa biblioteca para isso é d3-fetch .
Para construir a URL para este arquivo de uma forma que o Baker entenda, use este formato:
import { json } from 'd3-fetch';// o primeiro parâmetro deve ser o caminho para o arquivo // o segundo parâmetro *deve* ser “import.meta.url”const url = new URL('../_data /example.json', import.meta.url);// Chame-o de inconst data = await json(url); Outra abordagem é imprimir os dados em seu modelo como uma tag script . O filtro jsonScript pega a variável passada para ele, executa JSON.stringify nela e gera o JSON no HTML dentro de uma tag <script> com o ID definido que você passa como parâmetro.
{{exemplo|jsonScript('exemplo-dados') }}Uma vez feito isso, você pode recuperar o JSON armazenado na página por ID em seu JavaScript.
// pegue o elemento jsonScript criado usando o mesmo ID que você passou emconst dataElement = document.getElementById('example-data');// converta o conteúdo desse elemento em JSON// faça o que você precisa fazer com “dados” !const dados = JSON.parse(dataElement.textContent); Embora o método URL seja recomendado, esse método ainda pode ser preferido quando você está tentando evitar solicitações extras de rede. Ele também tem o benefício adicional de não exigir uma biblioteca especial para converter dados .csv em JSON.
Você pode gerar um número ilimitado de páginas estáticas alimentando uma fonte de dados estruturada para a opção createPages no arquivo baker.config.js . Por exemplo, este snippet irá gerar uma página para cada registro no arquivo example.json .
padrão de exportação {
// ... todas as outras opções acima desta foram excluídas para deixar claro
createPages: createPages(createPage, data) {// Pegue os dados da pasta _dataconst pageList = data.example;// Faça um loop através de recordsfor (const d of pageList) { // Defina o modelo base que será usado para cada objeto . Está na pasta _layouts const template = 'year-detail.html'; // Defina a URL da página const url = `${d.year}`; // Define as variáveis que serão passadas para o contexto do template const context = { obj: d }; // Use a função fornecida para renderizar a página createPage(template, url, context);}
},}; Isso poderia ser usado para criar URLs como /baker-example-page-template/1775/ e /baker-example-page-template/1780/] com um único modelo.
Antes de implantar uma página criada por este repositório, você precisará configurar sua conta Amazon AWS e adicionar um conjunto de credenciais à sua conta GitHub.
Primeiro, você precisará criar dois buckets no serviço de armazenamento S3 da Amazon. Um é para o seu site de teste. O outro é para o seu site de produção. Para este exemplo simples, cada um deve permitir acesso público e ser configurado para servir um site estático. Em um arranjo mais sofisticado, como o que administramos no Los Angeles Times, os buckets poderiam ser vinculados a nomes de domínio registrados e o site de teste protegido da visão pública por meio de um esquema de autenticação.
Os nomes desses buckets devem então ser armazenados como "segredos" do GitHub acessíveis às ações que implantam o site. Você deve visitar o painel de configurações da sua conta ou organização. Comece adicionando esses dois segredos.
| Nome | Valor |
|---|---|
BAKER_AWS_S3_STAGING_BUCKET | O nome do seu bucket de preparação |
BAKER_AWS_S3_STAGING_REGION | A região S3 onde seu bucket de preparo foi criado |
BAKER_AWS_S3_PRODUCTION_BUCKET | O nome do seu bucket de produção |
BAKER_AWS_S3_PRODUCTION_REGION | A região S3 onde seu bucket de produção foi criado |
Em seguida, você deve garantir que possui um par de chaves da AWS que tenha a capacidade de fazer upload de arquivos públicos para seus dois buckets. Os valores também devem ser adicionados aos seus segredos.
| Nome | Valor |
|---|---|
BAKER_AWS_ACCESS_KEY_ID | A chave de acesso da AWS |
BAKER_AWS_SECRET_ACCESS_KEY | A chave secreta da AWS |
Uma ação GitHub incluída neste repositório publicará automaticamente uma versão de teste para cada branch. Por exemplo, o código enviado para o branch main padrão aparecerá em https://your-staging-bucket-url/your-repo/main/ .
Se você criasse uma nova ramificação git chamada bugfix e enviasse seu código, logo veria uma nova versão de teste em https://your-staging-bucket-url/your-repo/bugfix/ .
Antes de enviar sua página ao ar, você deve definir um slug final para o URL. Isso definirá o subdiretório em seu intervalo onde a página será publicada. Este recurso permite que o The Times publique várias páginas dentro do mesmo intervalo, com cada página gerenciada por um repositório diferente.
A primeira etapa é inserir o slug do seu URL no arquivo de configuração _data/meta.aml .
slug: sua-página-slug
Nunca é uma má ideia ter certeza de que sua bala ainda não foi tomada. Você pode fazer isso visitando https://your-production-bucket-url/your-slug/ e garantindo que ele retorne um erro de página não encontrada.
Se quiser publicar sua página na raiz do seu bucket, você pode deixar o slug nulo.
lesma:
Em seguida, você confirma sua alteração no arquivo de configuração e certifica-se de que ela seja enviada para o branch principal no GitHub.
git add_data/meta.aml git commit -m “Definir slug de página” git push origem principal
Visite a seção de lançamentos da página do seu repositório no GitHub. Você pode encontrá-lo na página inicial do repositório.
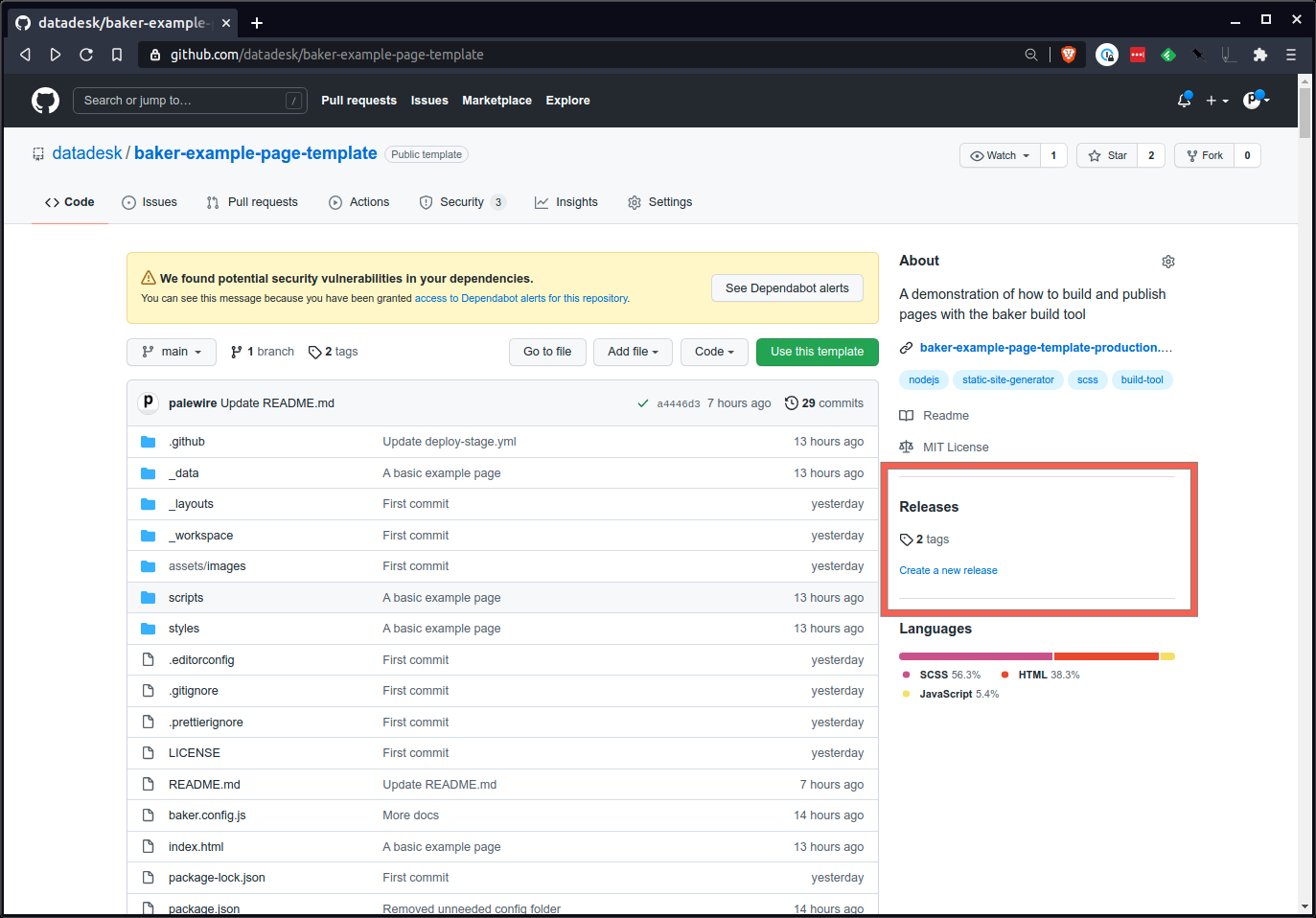
Elabore um novo lançamento.
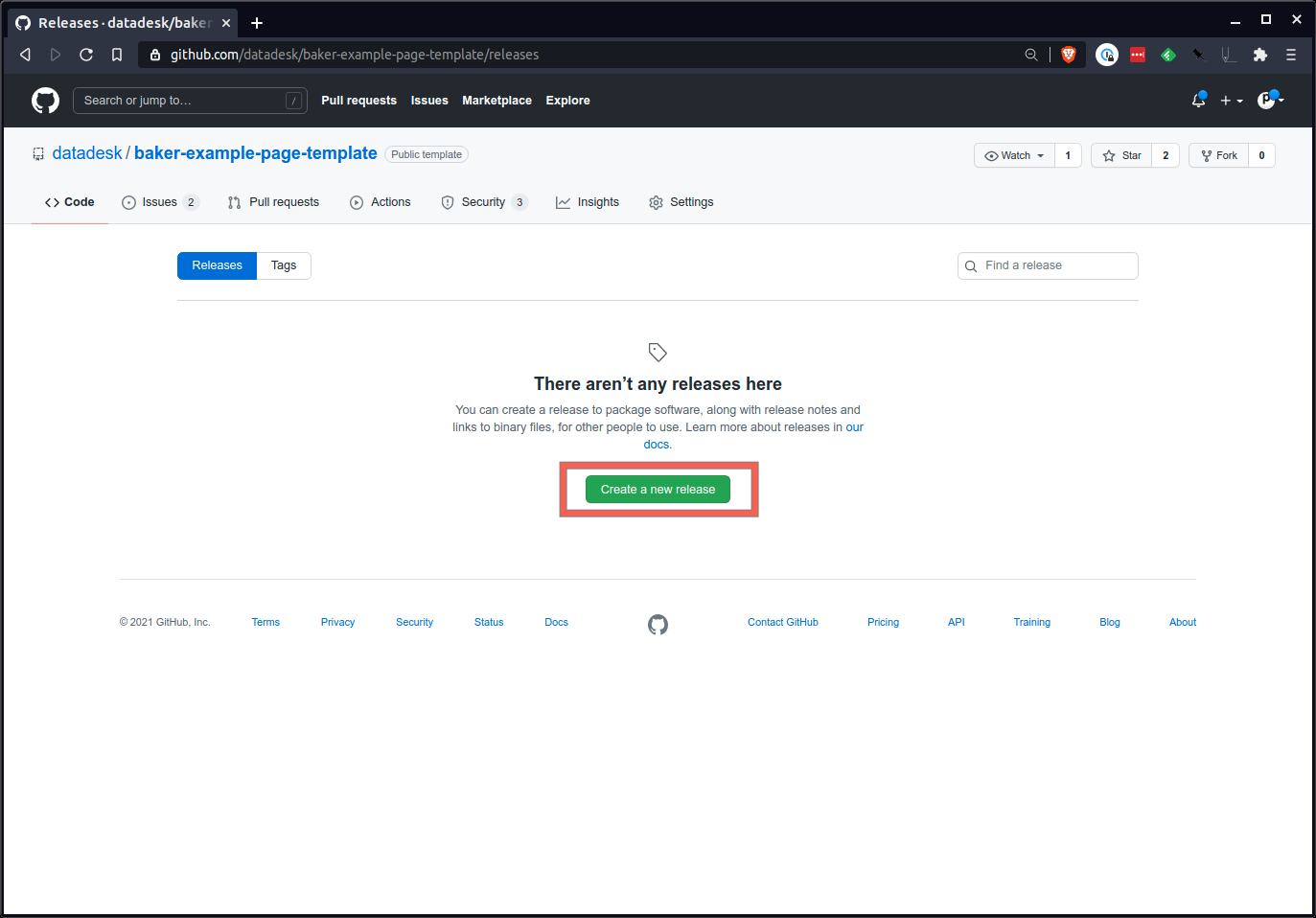
Lá você criará um novo número de tag. Uma boa abordagem é começar com um número no formato xxx que siga os padrões de controle de versão semântico. 1.0.0 é um bom começo.
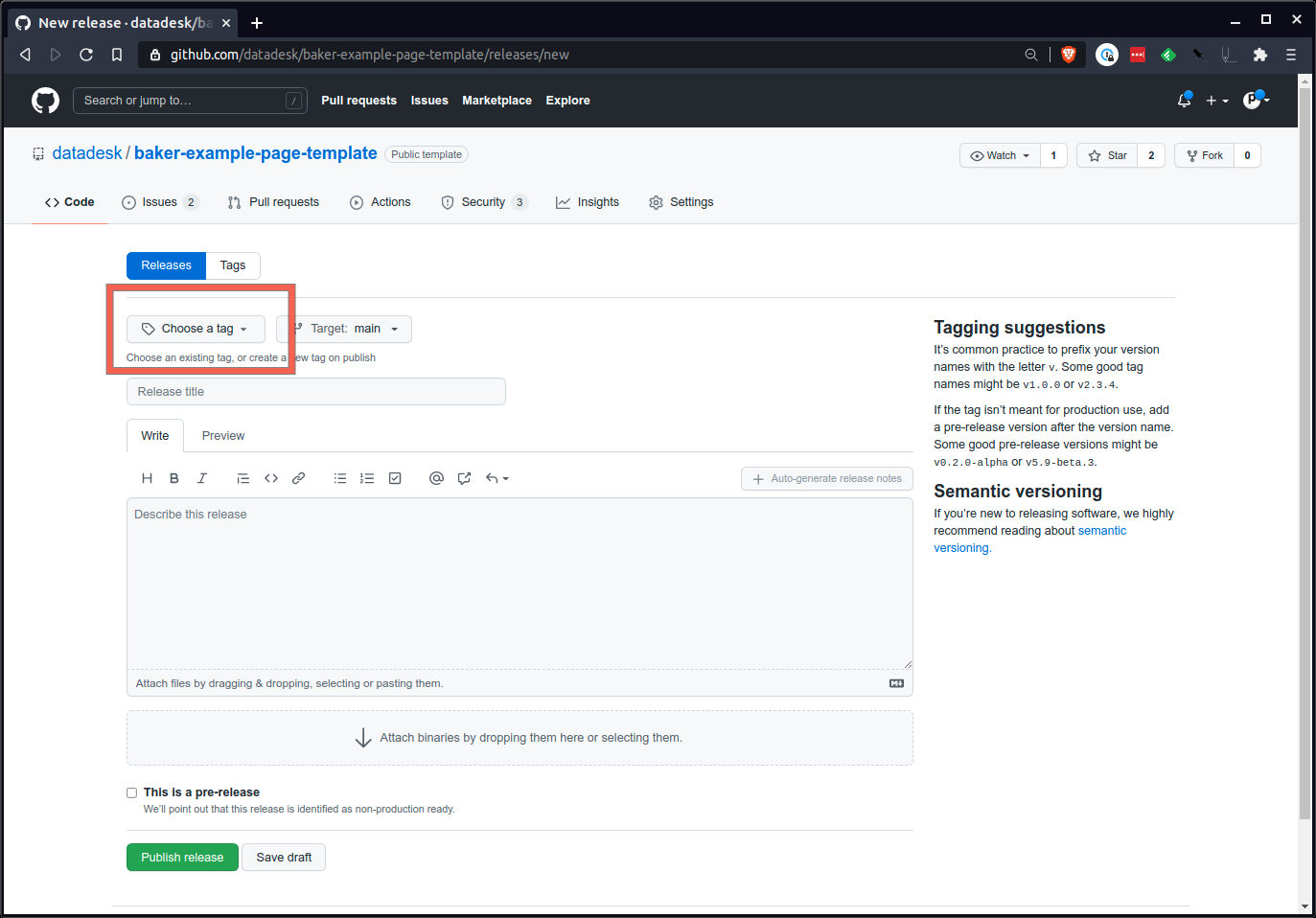
Por fim, aperte o grande botão verde na parte inferior e envie o comunicado.
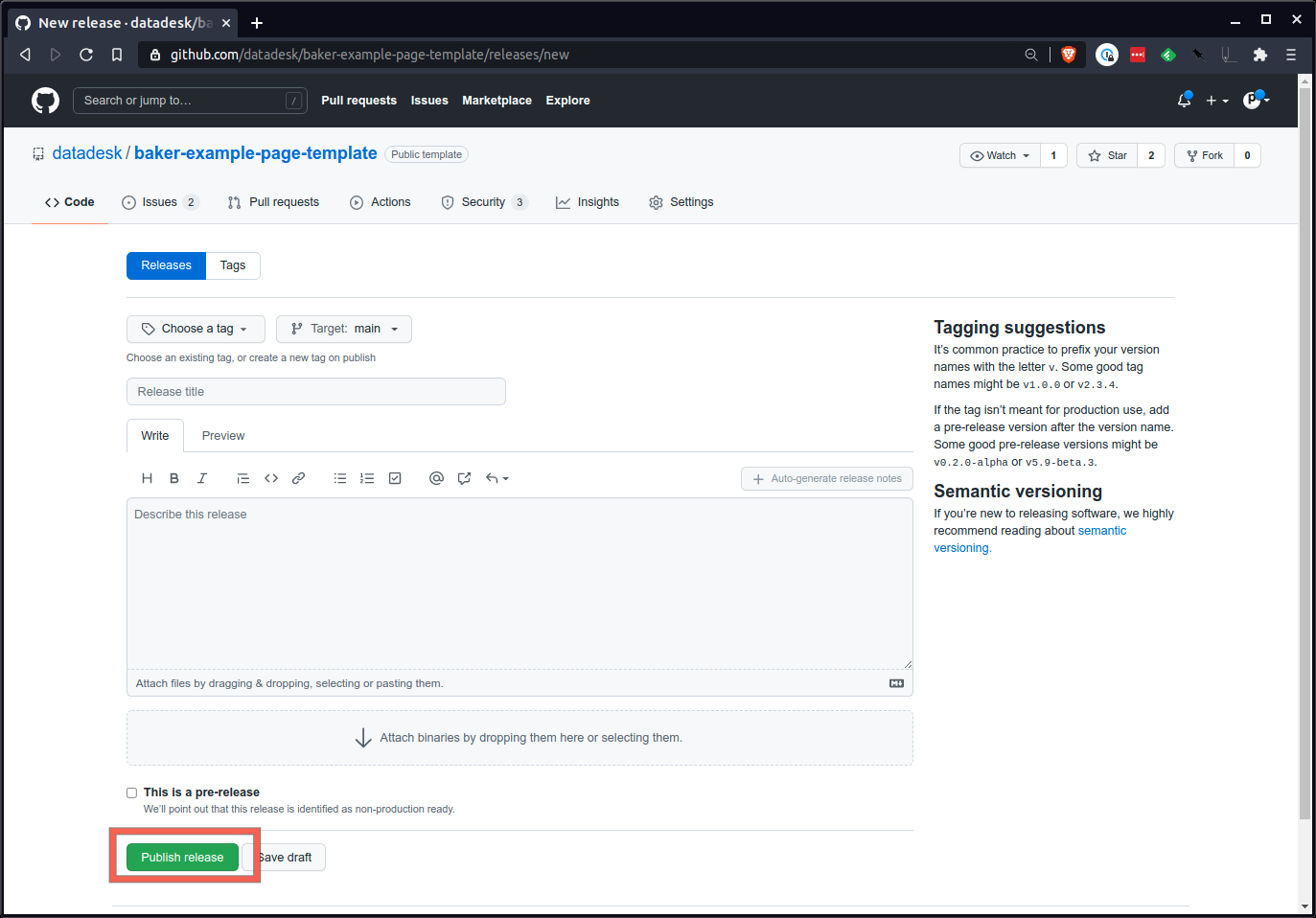
Aguarde alguns minutos e sua página deverá aparecer em https://your-production-bucket-url/your-slug/ .
O servidor de teste Baker pode registrar com mais detalhes começando com a opção a seguir.
DEBUG = início de 1 npm
Para limitar os logs à execução do Baker:
DEBUG=padeiro:* início npm
Se sua construção não for bem-sucedida, você pode tentar criar o site estático localmente por meio de seu terminal. Se houver erros na construção da página, eles serão impressos no seu terminal.
npm executar compilação
Baker vem com um conjunto de variáveis globais que são iguais em todas as páginas que ele cria e outro conjunto de variáveis específicas da página que são definidas com base na página atual que está sendo criada. Você pode usar essas variáveis para adicionar conteúdo condicionalmente às páginas ou filtrar dados não relacionados com base na página atual.
NODE_ENV A variável NODE_ENV sempre terá um de dois valores: development ou production . Corresponde ao tipo de construção que está sendo executada na página.
Ao executar npm start , você está no modo de development . Ao executar npm run build , você está no modo production .
Isso é mais útil para adicionar itens às páginas somente quando você estiver no modo de development .
{% if NODE_ENV == 'development' %}<p>Você nunca verá isso no site ativo!</p>{% endif %}DOMAIN A variável DOMAIN será sempre igual à opção domain passada em baker.config.js ou uma string vazia se nenhuma tiver sido passada.
PATH_PREFIX A variável PATH_PREFIX será sempre a mesma que a opção pathPrefix passada em baker.config.js ou uma única barra ( / ) se não tiver sido passada.
page.url A URL relativa ao projeto para a página atual. Incluirá o pathPrefix se um tiver sido fornecido no arquivo baker.config.js - em outras palavras, ele contabilizará qualquer caminho do projeto que está sendo feito e apontará para a página correta no projeto.
page.absoluteUrl O URL absoluto da página atual. Isso combina domain , pathPrefix e caminho atual em um URL completo. Atualmente, isso é usado para gerar o URL canônico e todos os URLs para tags sociais <meta> .
<link rel="canonical" href="{{ page.absoluteUrl }}">page.inputUrl Este é o caminho para o modelo original usado para criar esta página em relação ao diretório do projeto atual. Se você tiver um arquivo HTML localizado em page-two/index.html , page.inputUrl seria page-two/index.html .
page.outputUrl Este é o caminho para o arquivo HTML gerado para criar esta página relativa à pasta _dist . Se você tiver um arquivo HTML localizado em page-two.html , page.outputUrl seria page-two/index.html .
Cada projeto Baker em que trabalhamos inclui um arquivo baker.config.js no diretório raiz. Este arquivo é responsável por passar informações ao Baker para que ele possa construir corretamente o seu projeto.
padrão de exportação {
// o diretório onde os ativos estão
ativos: 'ativos',
//criaPáginas
createPages: indefinido,
//o diretório de dados
dados: '_dados',
// um domínio personalizado opcional para ser usado na construção de caminhos
domínio: indefinido,
// um caminho ou conjunto de caminhos de cada ponto de entrada JavaScript
pontos de entrada: 'scripts/app.js',
// o diretório de entrada geral, normalmente a pasta atual
entrada: process.cwd(),
// onde estão localizados os layouts, macros e inclusões do template
layouts: '_layouts',
// um objeto com as chaves e valores das variáveis globais a serem
// passado para todos os templates Nunjucks
nunjucksVariáveis: indefinidas,
// um objeto de chave (nome) + valor (função) para adicionar personalizado
//filtra para Nunjucks
nunjucksFilters: indefinido,
// um objeto de chave (nome) + valor (função) para adicionar personalizado
// tags para Nunjucks
nunjucksTags: indefinido,
//onde exibir os arquivos compilados
saída: '_dist',
// um prefixo para adicionar ao início de cada caminho resolvido, como
//lesmas funcionam
caminhoPrefixo: '/',
// um diretório opcional para colocar todos os ativos, raramente usado
raiz estática: '',}; padrão: ”assets”
Isso informa ao Baker qual pasta tratar como diretório de ativos. Você provavelmente não precisa mudar isso.
padrão: undefined
createPages é um parâmetro opcional que permite criar páginas dinamicamente usando dados e templates do projeto.
padrão de exportação {
//…
// createPage - passa um modelo, um nome de saída e o contexto de dados
//data - os dados preparados na pasta `_data`
createPages(createPage, data) {for (const title of data.titles) { createPage('template.html', `${title}.html`, {contexto: { title }, });}
},}; padrão: ”_data”
A opção data informa ao Baker qual pasta tratar como fonte de dados. Você provavelmente não precisará alterar isso.
padrão: undefined
A opção domain informa ao Baker o que usar ao construir URLs absolutos. O bakery-template predefini-lo para https://www.latimes.com .
padrão: ”scripts/app.js”
A opção entrypoints informa ao Baker quais arquivos JavaScript devem ser tratados como pontos de partida para pacotes de scripts. Pode ser um caminho para um arquivo ou um arquivo glob, possibilitando a criação de vários pacotes ao mesmo tempo.
padrão: process.cwd()
A opção input informa ao Baker qual pasta tratar como diretório principal de todo o projeto. Por padrão, esta é a pasta onde o arquivo baker.config.js está. Você provavelmente não precisará definir isso.
padrão: ”_layouts”
A opção layouts informa ao Baker onde os modelos, inclusões e macros estão localizados. Por padrão, esta é a pasta _layouts . Você provavelmente não precisará definir isso.
padrão: undefined
Você pode usar nunjucksFilters para passar seus próprios filtros personalizados. No objeto, cada chave é o nome do filtro, e o valor da função é o que é chamado quando você usa o filtro.
padrão de exportação {
// ...
//passa um objeto de filtros para adicionar ao Nunjucks
nunjucksFiltros: {quadrado(n) { n = +n; retornar n*n;}
},} {{ valor | quadrado }} padrão: undefined
Você pode usar nunjucksTags para passar suas próprias tags personalizadas. Eles diferem dos filtros porque facilitam a saída de blocos de texto ou HTML.
padrão de exportação {
// ...
//passa um objeto de filtros para adicionar ao Nunjucks
nunjucksTags: {doubler(n) { return `<p>${n} dobrado é ${n * 2}</p>`;}
},}; {% valor duplicador %} padrão: ”_dist”
A opção output informa ao Baker onde colocar os arquivos quando npm run build for executado. Por padrão, esta é a pasta _dist . Você provavelmente não precisará definir isso.
padrão: ”/”
pathPrefix informa ao Baker qual prefixo de caminho adicionar a qualquer URL que ele construir. Se domain também for passado, ele será combinado com pathPrefix ao construir URLs absolutos. Normalmente você não definirá isso manualmente — ele é usado durante implantações para construir URLs com slugs de projeto.
padrão: ””
A opção staticRoot instrui Baker a colocar todos os ativos em um diretório adicional. Isso é útil para projetos que precisam ter slugs exclusivos em cada página sem aninhamento, permitindo que todos compartilhem ativos estáticos. No entanto, este é um caso especial e requer uma configuração personalizada para implantações. Não tente usar isso sem um bom motivo.


