feathr
v1.0.0

Featherr é uma plataforma de engenharia de dados e IA que é amplamente utilizada na produção no LinkedIn há muitos anos e foi de código aberto em 2022. Atualmente é um projeto da LF AI & Data Foundation.
Leia nosso anúncio sobre Open Sourcing Feathr e Feathr no Azure, bem como o anúncio da LF AI & Data Foundation.
Featherr permite que você:
Featherr é particularmente útil na modelagem de IA, onde calcula automaticamente as transformações de seus recursos e as une aos seus dados de treinamento, usando semântica correta no momento certo para evitar vazamento de dados e oferece suporte à materialização e implantação de seus recursos para uso on-line na produção.
A maneira mais fácil de experimentar o Feathr é usar o Feathr Sandbox, que é um contêiner independente com a maioria dos recursos do Feathr e você deve estar produtivo em 5 minutos. Para usá-lo, basta executar este comando:
# 80: Feathr UI, 8888: Jupyter, 7080: Interpret
docker run -it --rm -p 8888:8888 -p 8081:80 -p 7080:7080 -e GRANT_SUDO=yes feathrfeaturestore/feathr-sandbox:releases-v1.0.0E você pode visualizar o notebook jupyter de início rápido do Featherr:
http://localhost:8888/lab/workspaces/auto-w/tree/local_quickstart_notebook.ipynbApós executar o notebook, todos os recursos serão registrados na UI, e você pode visitar a UI do Featherr em:
http://localhost:8081Se você deseja instalar o cliente Featherr em um ambiente python, use isto:
pip install feathrOu use o código mais recente do GitHub:
pip install git+https://github.com/feathr-ai/feathr.git#subdirectory=feathr_projectFeatherr tem integrações nativas com Databricks e Azure Synapse:
Siga o guia de implantação do Feathr ARM para executar o Feathr no Azure. Isto permite-lhe começar rapidamente com a implementação automatizada utilizando o modelo do Azure Resource Manager.
Se quiser configurar tudo manualmente, você pode verificar o guia de implantação do Feathr CLI para executar o Feathr no Azure. Isso permite que você entenda o que está acontecendo e configure um recurso por vez.
| Nome | Descrição | Plataforma |
|---|---|---|
| Demonstração de táxi em Nova York | Caderno de início rápido que mostra como definir, materializar e registrar recursos com dados de amostra de previsão de tarifas de táxi de Nova York. | Azure Synapse, Databricks, Local Spark |
| Demonstração de táxi de início rápido do Databricks em Nova York | Notebook Databricks de início rápido com dados de amostra de previsão de tarifas de táxi em Nova York. | Blocos de dados |
| Incorporação de recursos | Exemplo de Feathr UDF mostrando como definir e usar a incorporação de recursos com um modelo Transformer pré-treinado e dados de amostra de avaliação de hotel. | Blocos de dados |
| Demonstração de detecção de fraude | Um exemplo para demonstrar o Feature Store usando várias fontes de dados, como conta de usuário e dados de transação. | Azure Synapse, Databricks, Local Spark |
| Demonstração de recomendação de produto | Notebook de exemplo da Featherr Feature Store com um cenário de recomendação de produto | Azure Synapse, Databricks, Local Spark |
Por favor, leia Featherr Full Capabilities para mais exemplos. Abaixo estão alguns selecionados:
Featherr fornece uma interface de usuário intuitiva para que você possa pesquisar e explorar todos os recursos disponíveis e suas linhagens correspondentes.
Você pode usar a UI do Feathr para pesquisar recursos, identificar fontes de dados, rastrear linhagens de recursos e gerenciar controles de acesso. Confira a última demonstração ao vivo aqui para ver o que a UI do Feathr pode fazer por você. Use uma das seguintes contas quando for solicitado a fazer login:
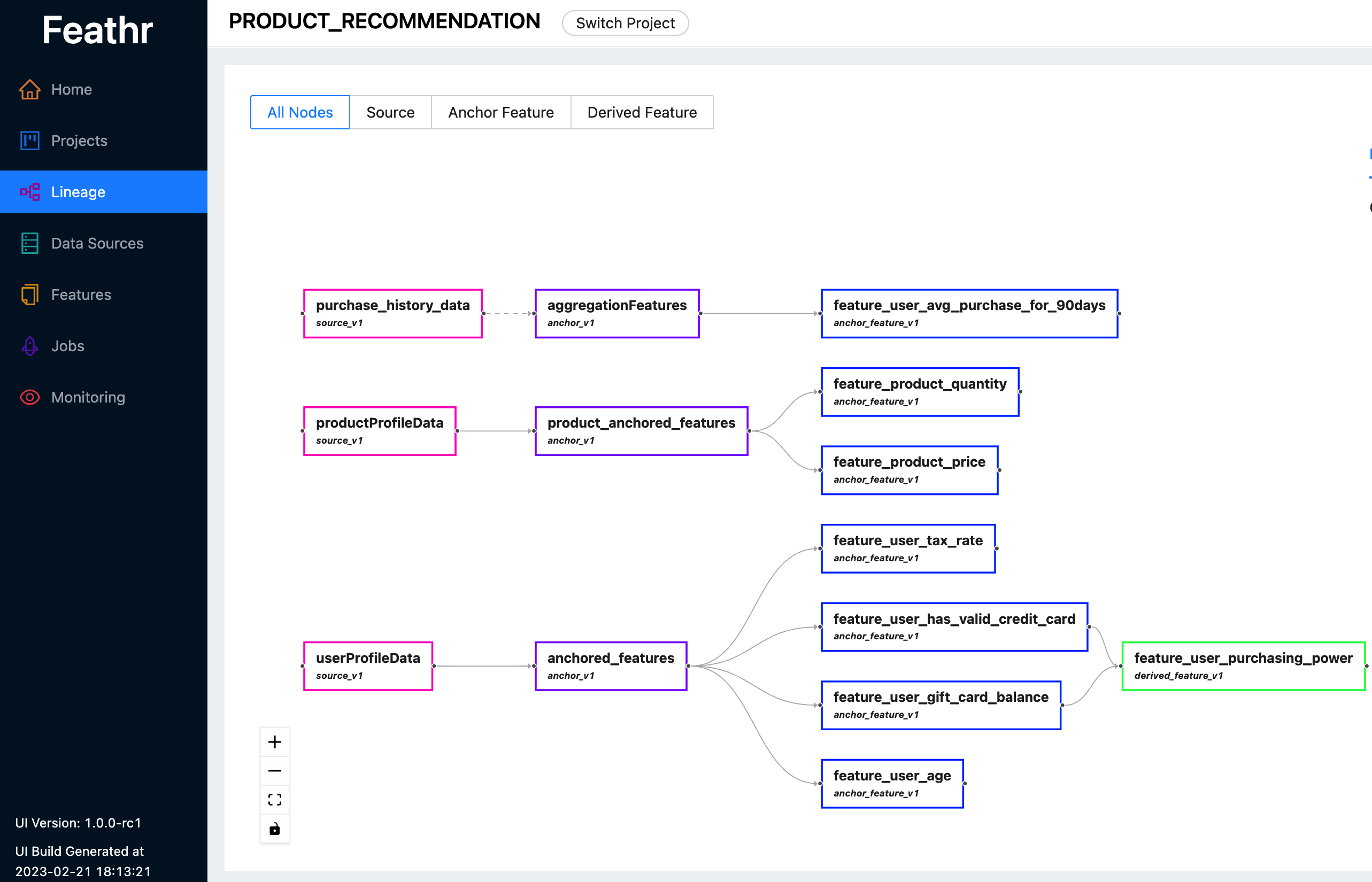
Para obter mais informações sobre a UI do Feathr e o registro por trás dela, consulte Feathr Feature Registry
Featherr tem UDFs altamente personalizáveis com integração nativa PySpark e Spark SQL para reduzir a curva de aprendizado para cientistas de dados:
def add_new_dropoff_and_fare_amount_column ( df : DataFrame ):
df = df . withColumn ( "f_day_of_week" , dayofweek ( "lpep_dropoff_datetime" ))
df = df . withColumn ( "fare_amount_cents" , df . fare_amount . cast ( 'double' ) * 100 )
return df
batch_source = HdfsSource ( name = "nycTaxiBatchSource" ,
path = "abfss://[email protected]/demo_data/green_tripdata_2020-04.csv" ,
preprocessing = add_new_dropoff_and_fare_amount_column ,
event_timestamp_column = "new_lpep_dropoff_datetime" ,
timestamp_format = "yyyy-MM-dd HH:mm:ss" ) agg_features = [ Feature ( name = "f_location_avg_fare" ,
key = location_id , # Query/join key of the feature(group)
feature_type = FLOAT ,
transform = WindowAggTransformation ( # Window Aggregation transformation
agg_expr = "cast_float(fare_amount)" ,
agg_func = "AVG" , # Apply average aggregation over the window
window = "90d" )), # Over a 90-day window
]
agg_anchor = FeatureAnchor ( name = "aggregationFeatures" ,
source = batch_source ,
features = agg_features ) # Compute a new feature(a.k.a. derived feature) on top of an existing feature
derived_feature = DerivedFeature ( name = "f_trip_time_distance" ,
feature_type = FLOAT ,
key = trip_key ,
input_features = [ f_trip_distance , f_trip_time_duration ],
transform = "f_trip_distance * f_trip_time_duration" )
# Another example to compute embedding similarity
user_embedding = Feature ( name = "user_embedding" , feature_type = DENSE_VECTOR , key = user_key )
item_embedding = Feature ( name = "item_embedding" , feature_type = DENSE_VECTOR , key = item_key )
user_item_similarity = DerivedFeature ( name = "user_item_similarity" ,
feature_type = FLOAT ,
key = [ user_key , item_key ],
input_features = [ user_embedding , item_embedding ],
transform = "cosine_similarity(user_embedding, item_embedding)" )Leia o Guia de ingestão de fontes de streaming para obter mais detalhes.
Leia Correção pontual e Junção pontual no Featherr para obter mais detalhes.
Siga o início rápido do Jupyter Notebook para testá-lo. Há também um guia de início rápido que contém um pouco mais de explicação sobre o notebook.
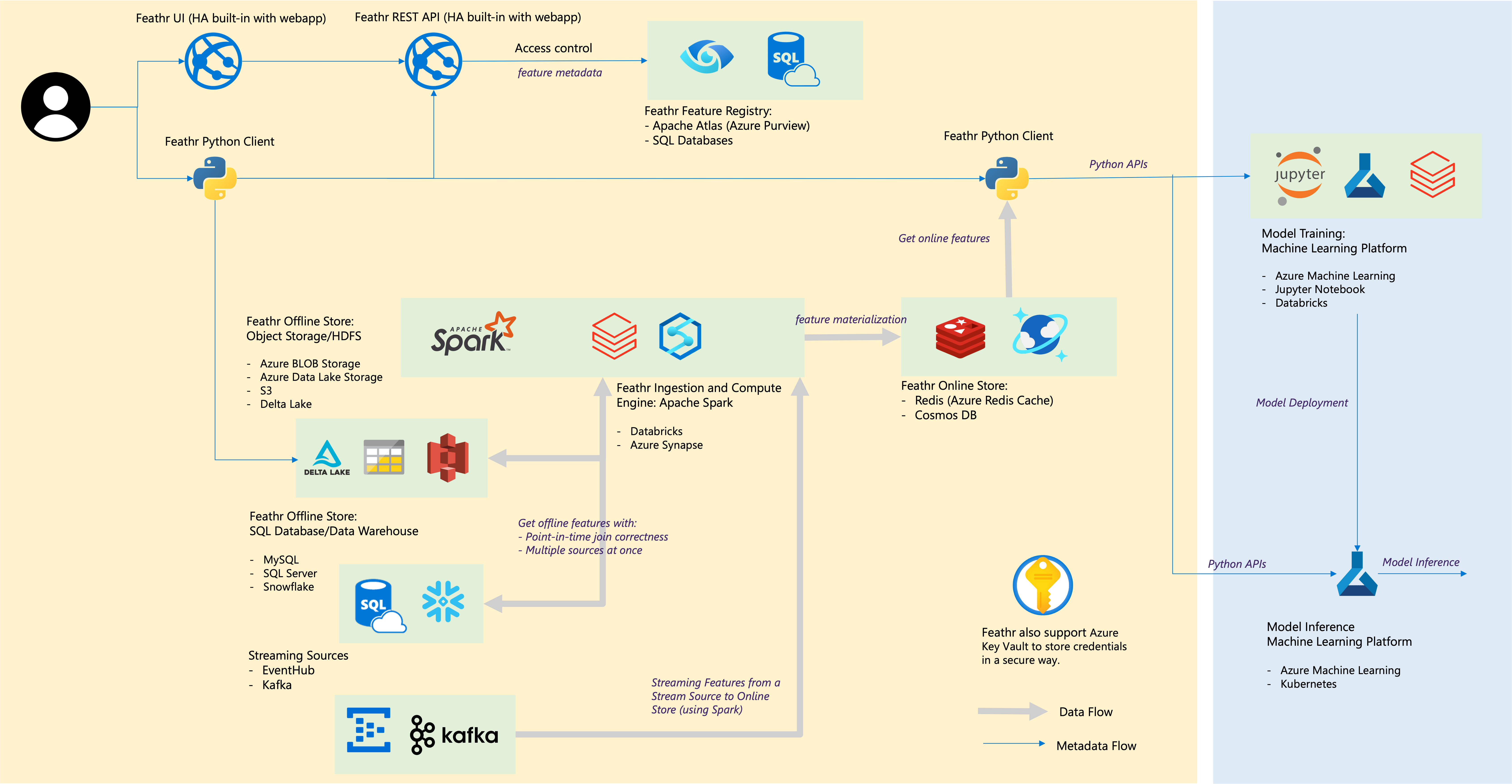
| Componente pena | Integrações em nuvem |
|---|---|
| Loja offline – Loja de objetos | Armazenamento de Blobs do Azure, Azure ADLS Gen2, AWS S3 |
| Loja offline – SQL | Banco de dados SQL do Azure, pools de SQL dedicados do Azure Synapse, SQL do Azure em VM, Snowflake |
| Fonte de streaming | Kafka, EventHub |
| Loja on-line | Redis, Azure Cosmos DB |
| Registro e governança de recursos | Azure Purview, ANSI SQL como Azure SQL Server |
| Mecanismo de computação | Piscinas do Azure Synapse Spark, blocos de dados |
| Plataforma de aprendizado de máquina | Azure Machine Learning, Caderno Jupyter, Caderno Databricks |
| Formato de arquivo | Parquet, ORC, Avro, JSON, Delta Lake, CSV |
| Credenciais | Cofre de Chaves Azure |
Construir para a comunidade e construir pela comunidade. Confira as diretrizes da comunidade.
Junte-se ao nosso canal Slack para perguntas e discussões (ou clique no link do convite).


