imagen pytorch
2.1.0
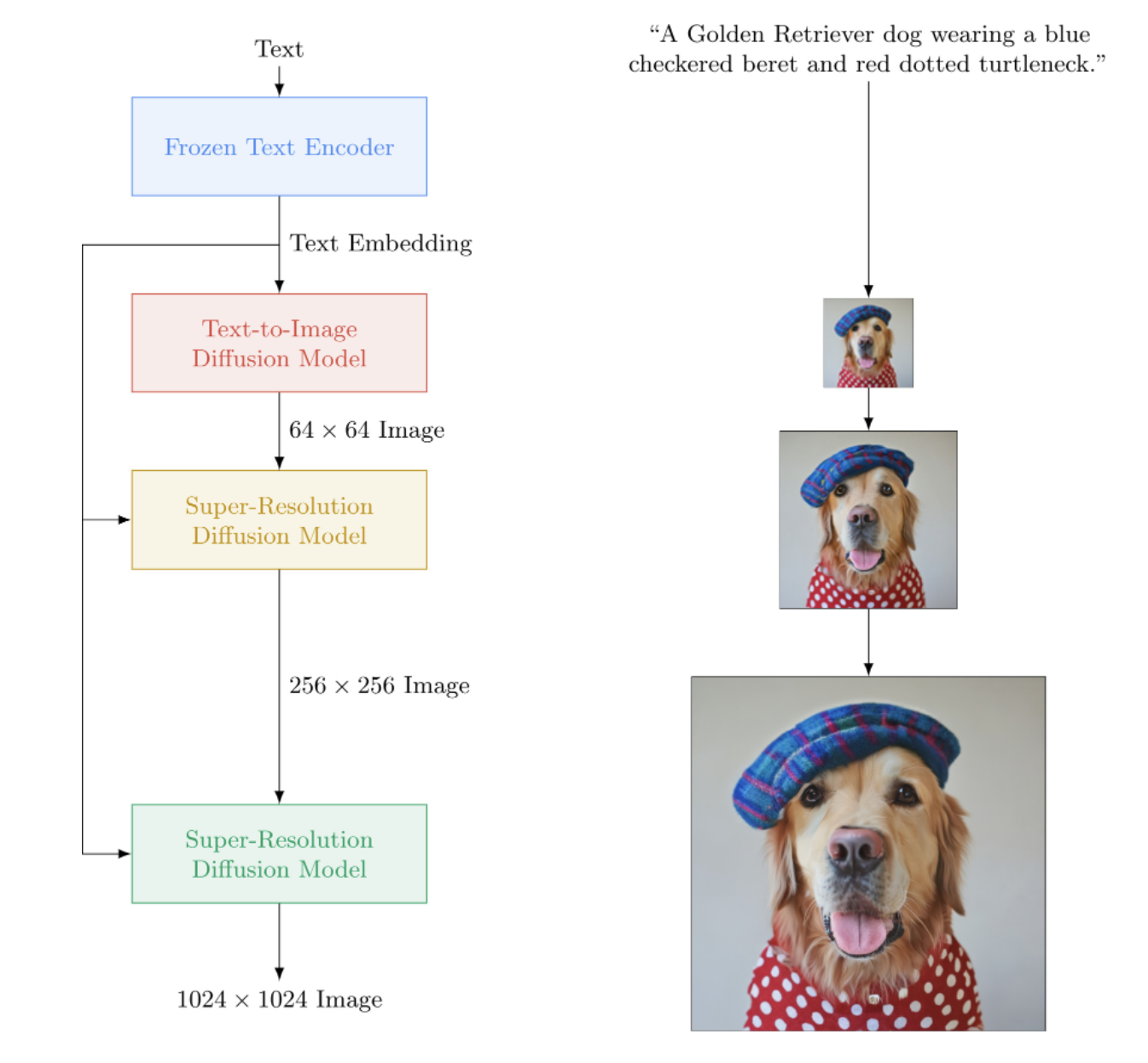
Implementação do Imagen, rede neural de texto para imagem do Google que supera o DALL-E2, em Pytorch. É o novo SOTA para síntese de texto para imagem.
Arquitetonicamente, é na verdade muito mais simples que o DALL-E2. Consiste em um DDPM em cascata condicionado à incorporação de texto de um grande modelo T5 pré-treinado (rede de atenção). Ele também contém recorte dinâmico para melhor orientação livre do classificador, condicionamento de nível de ruído e um design unet com eficiência de memória.
Parece que nem o CLIP nem a rede anterior são necessários, afinal. E assim a pesquisa continua.
AI Coffee Break com Letitia | IA de montagem | Yannic Kilcher
Por favor, junte-se se estiver interessado em ajudar na replicação com a comunidade LAION
StabilityAI pelo patrocínio generoso, assim como meus outros patrocinadores por aí
? Huggingface por sua incrível biblioteca de transformadores. A parte do codificador de texto é praticamente cuidada por causa deles
Jonathan Ho por trazer uma revolução na inteligência artificial generativa através de seu artigo seminal
Sylvain e Zachary pela biblioteca Accelerate, que este repositório usa para treinamento distribuído
Alex for einops, ferramenta indispensável para manipulação de tensores
Jorge Gomes pela ajuda com o código de carregamento do T5 e conselhos sobre a versão correta do T5
Katherine Crowson, por seu belo código, que me ajudou a entender a versão em tempo contínuo da difusão gaussiana
Marunine e Netruk44, pela revisão do código, compartilhamento de resultados experimentais e ajuda na depuração
Marunine por fornecer uma solução potencial para um problema de mudança de cor nas u-nets com eficiência de memória. Obrigado a Jacob por compartilhar comparações experimentais entre as unidades básicas e com uso eficiente de memória
Marunine por encontrar vários bugs, resolver um problema com redimensionamento correto e por compartilhar suas configurações experimentais e resultados
MalumaDev por propor o uso de upsampler de pixel shuffle para corrigir artefatos de checkboard
Valentin por apontar conexões de salto insuficientes no unet, bem como o método específico de condicionamento de atenção na base-unet no apêndice
BIGJUN para detectar um grande bug com condicionamento de nível de ruído de difusão gaussiana em tempo contínuo em tempo de inferência
Bingbing para identificar um bug com amostragem e ordem de normalização e ruído com imagem condicionada de baixa resolução
Kay por contribuir com o treinamento de comando de uma linha do Imagen!
Hadrien Reynaud por testar a conversão de texto em vídeo em um conjunto de dados médicos, compartilhar seus resultados e identificar problemas!
$ pip install imagen-pytorch import torch
from imagen_pytorch import Unet , Imagen
# unet for imagen
unet1 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True , True ),
layer_cross_attns = ( False , True , True , True )
)
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 256 ),
timesteps = 1000 ,
cond_drop_prob = 0.1
). cuda ()
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 4 , 256 , 768 ). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
for i in ( 1 , 2 ):
loss = imagen ( images , text_embeds = text_embeds , unet_number = i )
loss . backward ()
# do the above for many many many many steps
# now you can sample an image based on the text embeddings from the cascading ddpm
images = imagen . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
], cond_scale = 3. )
images . shape # (3, 3, 256, 256)Para um treinamento mais simples, você pode fornecer cadeias de texto diretamente em vez de pré-computar codificações de texto. (Embora para fins de dimensionamento, você definitivamente desejará pré-calcular os embeddings textuais + máscara)
O número de legendas textuais deve corresponder ao tamanho do lote das imagens se você seguir esse caminho.
# mock images and text (get a lot of this)
texts = [
'a child screaming at finding a worm within a half-eaten apple' ,
'lizard running across the desert on two feet' ,
'waking up to a psychedelic landscape' ,
'seashells sparkling in the shallow waters'
]
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
for i in ( 1 , 2 ):
loss = imagen ( images , texts = texts , unet_number = i )
loss . backward () Com a classe wrapper ImagenTrainer , as médias móveis exponenciais para todas as redes U no DDPM em cascata serão atendidas automaticamente ao chamar update
import torch
from imagen_pytorch import Unet , Imagen , ImagenTrainer
# unet for imagen
unet1 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True , True ),
)
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
text_encoder_name = 't5-large' ,
image_sizes = ( 64 , 256 ),
timesteps = 1000 ,
cond_drop_prob = 0.1
). cuda ()
# wrap imagen with the trainer class
trainer = ImagenTrainer ( imagen )
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 64 , 256 , 1024 ). cuda ()
images = torch . randn ( 64 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
loss = trainer (
images ,
text_embeds = text_embeds ,
unet_number = 1 , # training on unet number 1 in this example, but you will have to also save checkpoints and then reload and continue training on unet number 2
max_batch_size = 4 # auto divide the batch of 64 up into batch size of 4 and accumulate gradients, so it all fits in memory
)
trainer . update ( unet_number = 1 )
# do the above for many many many many steps
# now you can sample an image based on the text embeddings from the cascading ddpm
images = trainer . sample ( texts = [
'a puppy looking anxiously at a giant donut on the table' ,
'the milky way galaxy in the style of monet'
], cond_scale = 3. )
images . shape # (2, 3, 256, 256)Você também pode treinar Imagen sem texto (geração de imagem incondicional) da seguinte maneira
import torch
from imagen_pytorch import Unet , Imagen , SRUnet256 , ImagenTrainer
# unets for unconditional imagen
unet1 = Unet (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True ),
layer_cross_attns = False ,
use_linear_attn = True
)
unet2 = SRUnet256 (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 ),
num_resnet_blocks = ( 2 , 4 , 8 ),
layer_attns = ( False , False , True ),
layer_cross_attns = False
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
condition_on_text = False , # this must be set to False for unconditional Imagen
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 128 ),
timesteps = 1000
)
trainer = ImagenTrainer ( imagen ). cuda ()
# now get a ton of images and feed it through the Imagen trainer
training_images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# train each unet separately
# in this example, only training on unet number 1
loss = trainer ( training_images , unet_number = 1 )
trainer . update ( unet_number = 1 )
# do the above for many many many many steps
# now you can sample images unconditionally from the cascading unet(s)
images = trainer . sample ( batch_size = 16 ) # (16, 3, 128, 128)Ou treine apenas unets super-resolutivos
import torch
from imagen_pytorch import Unet , NullUnet , Imagen
# unet for imagen
unet1 = NullUnet () # add a placeholder "null" unet for the base unet
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 256 ),
timesteps = 250 ,
cond_drop_prob = 0.1
). cuda ()
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 4 , 256 , 768 ). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
loss = imagen ( images , text_embeds = text_embeds , unet_number = 2 )
loss . backward ()
# do the above for many many many many steps
# now you can sample an image based on the text embeddings as well as low resolution images
lowres_images = torch . randn ( 3 , 3 , 64 , 64 ). cuda () # starting un-resoluted images
images = imagen . sample (
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
],
start_at_unet_number = 2 , # start at unet number 2
start_image_or_video = lowres_images , # pass in low resolution images to be resoluted
cond_scale = 3. )
images . shape # (3, 3, 256, 256) A qualquer momento você pode salvar e carregar o treinador e todos os estados associados com os métodos save e load . É recomendado que você use esses métodos em vez de salvar manualmente com uma chamada state_dict , pois há algum gerenciamento de memória do dispositivo sendo feito nos bastidores do treinador.
ex.
trainer . save ( './path/to/checkpoint.pt' )
trainer . load ( './path/to/checkpoint.pt' )
trainer . steps # (2,) step number for each of the unets, in this case 2 Você também pode contar com o ImagenTrainer para treinar automaticamente as instâncias DataLoader . Você simplesmente precisa criar seu DataLoader para retornar images (para casos incondicionais) ou ('images', 'text_embeds') para geração guiada por texto.
ex. treinamento incondicional
from imagen_pytorch import Unet , Imagen , ImagenTrainer
from imagen_pytorch . data import Dataset
# unets for unconditional imagen
unet = Unet (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 1 ,
layer_attns = ( False , False , False , True ),
layer_cross_attns = False
)
# imagen, which contains the unet above
imagen = Imagen (
condition_on_text = False , # this must be set to False for unconditional Imagen
unets = unet ,
image_sizes = 128 ,
timesteps = 1000
)
trainer = ImagenTrainer (
imagen = imagen ,
split_valid_from_train = True # whether to split the validation dataset from the training
). cuda ()
# instantiate your dataloader, which returns the necessary inputs to the DDPM as tuple in the order of images, text embeddings, then text masks. in this case, only images is returned as it is unconditional training
dataset = Dataset ( '/path/to/training/images' , image_size = 128 )
trainer . add_train_dataset ( dataset , batch_size = 16 )
# working training loop
for i in range ( 200000 ):
loss = trainer . train_step ( unet_number = 1 , max_batch_size = 4 )
print ( f'loss: { loss } ' )
if not ( i % 50 ):
valid_loss = trainer . valid_step ( unet_number = 1 , max_batch_size = 4 )
print ( f'valid loss: { valid_loss } ' )
if not ( i % 100 ) and trainer . is_main : # is_main makes sure this can run in distributed
images = trainer . sample ( batch_size = 1 , return_pil_images = True ) # returns List[Image]
images [ 0 ]. save ( f'./sample- { i // 100 } .png' )Graças a? Acelere, você pode fazer treinamento multi GPU facilmente em duas etapas.
Primeiro você precisa invocar accelerate config no mesmo diretório do seu script de treinamento (digamos que se chama train.py )
$ accelerate config Em seguida, em vez de chamar python train.py como faria para uma GPU única, você usaria a CLI de aceleração da mesma forma
$ accelerate launch train.pyÉ isso!
Imagen também pode ser usado diretamente via CLI.
ex.
$ imagen configou
$ imagen config --path ./configs/config.jsonNa configuração você pode alterar as configurações do treinador, do conjunto de dados e da configuração da imagem.
Os parâmetros de configuração do Imagen podem ser encontrados aqui
Os parâmetros de configuração do Elucidated Imagen podem ser encontrados aqui
Os parâmetros de configuração do Imagen Trainer podem ser encontrados aqui
Para os parâmetros do conjunto de dados, todos os parâmetros do dataloader podem ser usados.
Este comando permite treinar ou retomar o treinamento do seu modelo
ex.
$ imagen trainou
$ imagen train --unet 2 --epoches 10Você pode passar os seguintes argumentos para o comando de treinamento.
--config especifica o arquivo de configuração a ser usado para treinamento [padrão: ./imagen_config.json]--unet o índice do unet a ser treinado [padrão: 1]--epoches para quantas épocas treinar [padrão: 50]Esteja ciente de que ao coletar amostras, seu ponto de verificação deve ter treinado todos os unets para obter um resultado utilizável.
ex.
$ imagen sample --model ./path/to/model/checkpoint.pt " a squirrel raiding the birdfeeder "
# image is saved to ./a_squirrel_raiding_the_birdfeeder.pngVocê pode passar os seguintes argumentos para o comando de amostra.
--model especifica o arquivo de modelo a ser usado para amostragem--cond_scale escala de condicionamento (orientação livre do classificador) no decodificador--load_ema carrega a versão EMA dos unets, se disponível Para usar um ponto de verificação salvo com este recurso, você deve instanciar sua instância Imagen usando as classes de configuração, ImagenConfig e ElucidatedImagenConfig ou criar um ponto de verificação diretamente através da CLI
Para um treinamento adequado, você provavelmente desejará configurar o treinamento baseado em configuração de qualquer maneira.
ex.
import torch
from imagen_pytorch import ImagenConfig , ElucidatedImagenConfig , ImagenTrainer
# in this example, using elucidated imagen
imagen = ElucidatedImagenConfig (
unets = [
dict ( dim = 32 , dim_mults = ( 1 , 2 , 4 , 8 )),
dict ( dim = 32 , dim_mults = ( 1 , 2 , 4 , 8 ))
],
image_sizes = ( 64 , 128 ),
cond_drop_prob = 0.5 ,
num_sample_steps = 32
). create ()
trainer = ImagenTrainer ( imagen )
# do your training ...
# then save it
trainer . save ( './checkpoint.pt' )
# you should see a message informing you that ./checkpoint.pt is commandable from the terminalRealmente deveria ser tão simples assim
Você também pode passar esse arquivo de ponto de verificação e qualquer pessoa pode continuar o ajuste fino de seus próprios dados
from imagen_pytorch import load_imagen_from_checkpoint , ImagenTrainer
imagen = load_imagen_from_checkpoint ( './checkpoint.pt' )
trainer = ImagenTrainer ( imagen )
# continue training / fine-tuning A pintura segue a formulação estabelecida pelo recente artigo Repaint. Basta passar inpaint_images e inpaint_masks para a função sample em Imagen ou ElucidatedImagen
inpaint_images = torch . randn ( 4 , 3 , 512 , 512 ). cuda () # (batch, channels, height, width)
inpaint_masks = torch . ones (( 4 , 512 , 512 )). bool (). cuda () # (batch, height, width)
inpainted_images = trainer . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
], inpaint_images = inpaint_images , inpaint_masks = inpaint_masks , cond_scale = 5. )
inpainted_images # (4, 3, 512, 512) Para vídeo, passe seus vídeos da mesma forma para a palavra-chave inpaint_videos em .sample . A máscara de pintura pode ser igual em todos os quadros (batch, height, width) ou diferente (batch, frames, height, width)
inpaint_videos = torch . randn ( 4 , 3 , 8 , 512 , 512 ). cuda () # (batch, channels, frames, height, width)
inpaint_masks = torch . ones (( 4 , 8 , 512 , 512 )). bool (). cuda () # (batch, frames, height, width)
inpainted_videos = trainer . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
], inpaint_videos = inpaint_videos , inpaint_masks = inpaint_masks , cond_scale = 5. )
inpainted_videos # (4, 3, 8, 512, 512) Tero Karras, famoso pelo StyleGAN, escreveu um novo artigo com resultados que foram corroborados por vários pesquisadores independentes, bem como em minha própria máquina. Decidi criar uma versão do Imagen , o ElucidatedImagen , para que se possa usar o novo DDPM elucidado para geração em cascata guiada por texto.
Simplesmente importe ElucidatedImagen e instancie a instância como fez antes. Os hiperparâmetros são diferentes dos usuais para difusão gaussiana em tempo discreto e contínuo, e podem ser individualizados para cada unidade da cascata.
Ex.
from imagen_pytorch import ElucidatedImagen
# instantiate your unets ...
imagen = ElucidatedImagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 128 ),
cond_drop_prob = 0.1 ,
num_sample_steps = ( 64 , 32 ), # number of sample steps - 64 for base unet, 32 for upsampler (just an example, have no clue what the optimal values are)
sigma_min = 0.002 , # min noise level
sigma_max = ( 80 , 160 ), # max noise level, @crowsonkb recommends double the max noise level for upsampler
sigma_data = 0.5 , # standard deviation of data distribution
rho = 7 , # controls the sampling schedule
P_mean = - 1.2 , # mean of log-normal distribution from which noise is drawn for training
P_std = 1.2 , # standard deviation of log-normal distribution from which noise is drawn for training
S_churn = 80 , # parameters for stochastic sampling - depends on dataset, Table 5 in apper
S_tmin = 0.05 ,
S_tmax = 50 ,
S_noise = 1.003 ,
). cuda ()
# rest is the same as above Este repositório também começará a acumular novas pesquisas em torno da síntese de vídeo guiada por texto. Para começar, ele adotará a arquitetura unet 3D descrita por Jonathan Ho em Video Diffusion Models
Atualização: funcionamento verificado por Hadrien Reynaud!
Ex.
import torch
from imagen_pytorch import Unet3D , ElucidatedImagen , ImagenTrainer
unet1 = Unet3D ( dim = 64 , dim_mults = ( 1 , 2 , 4 , 8 )). cuda ()
unet2 = Unet3D ( dim = 64 , dim_mults = ( 1 , 2 , 4 , 8 )). cuda ()
# elucidated imagen, which contains the unets above (base unet and super resoluting ones)
imagen = ElucidatedImagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 16 , 32 ),
random_crop_sizes = ( None , 16 ),
temporal_downsample_factor = ( 2 , 1 ), # in this example, the first unet would receive the video temporally downsampled by 2x
num_sample_steps = 10 ,
cond_drop_prob = 0.1 ,
sigma_min = 0.002 , # min noise level
sigma_max = ( 80 , 160 ), # max noise level, double the max noise level for upsampler
sigma_data = 0.5 , # standard deviation of data distribution
rho = 7 , # controls the sampling schedule
P_mean = - 1.2 , # mean of log-normal distribution from which noise is drawn for training
P_std = 1.2 , # standard deviation of log-normal distribution from which noise is drawn for training
S_churn = 80 , # parameters for stochastic sampling - depends on dataset, Table 5 in apper
S_tmin = 0.05 ,
S_tmax = 50 ,
S_noise = 1.003 ,
). cuda ()
# mock videos (get a lot of this) and text encodings from large T5
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
]
videos = torch . randn ( 4 , 3 , 10 , 32 , 32 ). cuda () # (batch, channels, time / video frames, height, width)
# feed images into imagen, training each unet in the cascade
# for this example, only training unet 1
trainer = ImagenTrainer ( imagen )
# you can also ignore time when training on video initially, shown to improve results in video-ddpm paper. eventually will make the 3d unet trainable with either images or video. research shows it is essential (with current data regimes) to train first on text-to-image. probably won't be true in another decade. all big data becomes small data
trainer ( videos , texts = texts , unet_number = 1 , ignore_time = False )
trainer . update ( unet_number = 1 )
videos = trainer . sample ( texts = texts , video_frames = 20 ) # extrapolating to 20 frames from training on 10 frames
videos . shape # (4, 3, 20, 32, 32) Você também pode treinar primeiro em pares texto-imagem. O Unet3D irá convertê-lo automaticamente em vídeos de quadro único e aprender sem os componentes temporais (definindo automaticamente ignore_time = True ), sejam convoluções 1d ou atenção causal ao longo do tempo.
Esta é a abordagem atual adotada por todos os grandes laboratórios de inteligência artificial (Brain, MetaAI, Bytedance)
Imagen usa um algoritmo chamado Classifier Free Guidance. Ao amostrar, você aplica uma escala ao condicionamento (texto neste caso) superior a 1.0 .
O pesquisador Netruk44 relatou que 5-10 é o ideal, mas qualquer coisa maior que 10 pode ser quebrada.
trainer . sample ( texts = [
'a cloud in the shape of a roman gladiator'
], cond_scale = 5. ) # <-- cond_scale is the conditioning scale, needs to be greater than 1.0 to be better than averageNão no momento, mas provavelmente alguém será treinado e terá código aberto dentro de um ano, se não antes. Se quiser participar, você pode ingressar na comunidade de treinadores de redes neurais artificiais em Laion (o link do discord está no Leiame acima) e começar a colaborar.
Mais uma razão pela qual você deve começar a treinar seu próprio modelo, a partir de hoje! A última coisa de que precisamos é que esta tecnologia esteja nas mãos de uma elite. Esperamos que este repositório reduza o trabalho a apenas encontrar a computação necessária e aumentá-lo com seu próprio conjunto de dados selecionado.
Qualquer coisa! É licenciado pelo MIT. Ou seja, você pode copiar/colar livremente para sua própria pesquisa, remixado para qualquer modalidade que imaginar. Vá treinar modelos incríveis para obter lucro, para a ciência ou simplesmente para saciar seu prazer pessoal ao testemunhar algo divino se desenrolar diante de você.
Síntese de ecocardiograma [Código]
Síntese de matriz de contato SOTA Hi-C [Código]
Geração de planta baixa
Slides de histopatologia de ultra alta resolução
Imagens Laparoscópicas Sintéticas
Projetando MetaMaterials
Difusão de áudio de Flavio Schneider
Mini imagem de Ryan O. | Redação do AssemblyAI
use transformadores huggingface para incorporações de texto pequeno T5
adicionar limite dinâmico
adicione limite dinâmico DALLE2 e repositório de difusão de vídeo também
permitir definir T5-grande (e talvez pequeno método de fábrica para aceitar qualquer transformador huggingface)
adicione o nível de ruído de baixa resolução ao pseudocódigo no apêndice e descubra o que é essa varredura que eles fazem no momento da inferência
portar algum código de treinamento do DALLE2
precisa ser capaz de usar uma programação de ruído diferente por unidade (o cosseno foi usado para base, mas linear para SR)
basta fazer uma unet configurável pelo mestre
bloco resnet completo (inspirado em biggan? mas com groupnorm) - autoatenção completa
bloco de incorporação de condicionamento completo (e torná-lo completamente configurável, seja atenção, filme, etc.)
considere usar o percepr-resampler de https://github.com/lucidrains/flamingo-pytorch no lugar do pool de atenção
adicionar opção de agrupamento de atenção, além de atenção cruzada e filme
adicione cronograma opcional de decaimento de cosseno com aquecimento, para cada unet, ao treinador
mude para intervalos de tempo contínuos em vez de discretizados, pois parece que foi isso que eles usaram para todos os estágios - primeiro descubra o caso do cronograma de ruído linear no artigo variacional do ddpm https://openreview.net/forum?id=2LdBqxc1Yv
descubra log (snr) para programação de ruído alfa cosseno.
suprime o aviso dos transformadores porque apenas o T5encoder é usado
permitir a configuração do uso de atenção linear em camadas onde a atenção total não pode ser usada
forçar unets em caso de tempo contínuo a usar condições não-fouriered (basta passar o log (snr) através de um MLP com normas de camada opcionais), pois é isso que tenho trabalhando localmente
variância aprendida removida
adicione ponderação de perda p2 para tempo contínuo
certifique-se de que o ddpm em cascata possa ser treinado sem condição de texto e certifique-se de que a difusão gaussiana em tempo contínuo e discreto funcione
use as conversões profundas do primer nas projeções qkv na atenção linear (ou use a mudança de token antes das projeções) - use também o novo dropout proposto pelo bayesformer, pois parece funcionar bem com a atenção linear
explore a excitação da camada de salto no decodificador unet
acelerar a integração
construir ferramenta CLI e geração de imagem em uma linha
elimine quaisquer problemas que surjam da aceleração
adicione capacidade de pintura usando reamostrador de papel repintado https://arxiv.org/abs/2201.09865
construir um sistema de checkpoint simples, apoiado por uma pasta
adicionar conexão de salto das saídas de todos os blocos de upsample, usado em papel quadrado unet e alguns trabalhos anteriores do unet
adicione fsspec, recomendado por Romain @ rom1504, para persistência independente de pontos de verificação do sistema de arquivos local/nuvem
teste a persistência no gcs com https://github.com/fsspec/gcsfs
estender para geração de vídeo, usando atenção de tempo axial como no artigo ddpm de vídeo de Ho
permitir que a imagem elucidada generalize para qualquer forma
permitir que a imagem generalize para qualquer forma
adicione polarização posicional dinâmica para o melhor tipo de extrapolação de duração ao longo do tempo do vídeo
mover quadros de vídeo para a função de amostra, pois tentaremos extrapolação de tempo
o viés de atenção para chaves/valores nulos deve ser um escalar aprendido da dimensão principal
adicione autocondicionamento de papel de difusão de bits, já codificado em ddpm-pytorch
adicione v-parametrização (https://arxiv.org/abs/2202.00512) do papel de vídeo imagen, a única coisa nova
incorpore todos os aprendizados do make-a-video (https://makeavideo.studio/)
construir uma ferramenta CLI para treinamento, retomando o treinamento no arquivo de configuração
permitir interpolação temporal em estágios específicos
certifique-se de que a interpolação temporal funcione com pintura interna
certifique-se de personalizar todos os modos de interpolação (alguns pesquisadores estão encontrando melhores resultados com trilinear)
imagen-video : permite o condicionamento em quadros de vídeos anteriores (e possivelmente futuros). ignorar o tempo não deve ser permitido nesse cenário
certifique-se de cuidar automaticamente da redução/aumento da resolução temporal para condicionar quadros de vídeo, mas permita uma opção para desligá-lo
certifique-se de que a pintura funciona com vídeo
certifique-se de que a máscara de pintura para vídeo possa ser personalizada por quadro
adicione atenção instantânea
releia o cogvideo e descubra como o condicionamento da taxa de quadros pode ser usado
trazer experiência em atenção para camadas de autoatenção em unet3d
considere trazer a atenção convolucional 3D da NUWA
considere memórias transformer-xl nos blocos de atenção temporal
considere a abordagem do percebedor para atender ao tempo passado
interrupções de quadro durante a atenção para obter efeito regularizador e também redução do tempo de treinamento
investigue as afirmações de Frank Wood https://github.com/lucidrains/flexible-diffusion-modeling-videos-pytorch e adicione a técnica de amostragem hierárquica ou informe as pessoas sobre suas deficiências
oferecem movimentos desafiadores (com objetos distratores) como uma linha de base treinável de uma linha para os pesquisadores ramificarem para texto em vídeo
pré-codificação de texto para embeddings mapeados em mem
ser capaz de criar iteradores de dataloader com base no estilo da época antiga, também configurar embaralhamento, etc.
ser capaz de também passar argumentos (em vez de exigir que forward sejam todos argumentos de palavras-chave no modelo)
trazer blocos reversíveis de revnets para unet 3D, para diminuir a carga de memória
adicionar capacidade de treinar apenas redes de super-resolução
leia dpm-solver e veja se é aplicável à difusão gaussiana em tempo contínuo
permitir o condicionamento de quadros de vídeo com tempos absolutos arbitrários (calcular RPE durante a atenção temporal)
acomodar o ajuste fino do estande dos sonhos
adicionar inversão textual
autocondicionamento de limpeza a ser extraído na instanciação da imagem
certifique-se de que eventual dreambooth funcione com imagen-video
adicione condicionamento de taxa de quadros para difusão de vídeo
certifique-se de que é possível condicionar simultaneamente os quadros de vídeo como um prompt, bem como algum condicionamento de imagem em todos os quadros
testar e adicionar técnica de destilação a partir de modelos de consistência
@inproceedings { Saharia2022PhotorealisticTD ,
title = { Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding } ,
author = { Chitwan Saharia and William Chan and Saurabh Saxena and Lala Li and Jay Whang and Emily L. Denton and Seyed Kamyar Seyed Ghasemipour and Burcu Karagol Ayan and Seyedeh Sara Mahdavi and Raphael Gontijo Lopes and Tim Salimans and Jonathan Ho and David Fleet and Mohammad Norouzi } ,
year = { 2022 }
} @article { Alayrac2022Flamingo ,
title = { Flamingo: a Visual Language Model for Few-Shot Learning } ,
author = { Jean-Baptiste Alayrac et al } ,
year = { 2022 }
} @inproceedings { Sankararaman2022BayesFormerTW ,
title = { BayesFormer: Transformer with Uncertainty Estimation } ,
author = { Karthik Abinav Sankararaman and Sinong Wang and Han Fang } ,
year = { 2022 }
} @article { So2021PrimerSF ,
title = { Primer: Searching for Efficient Transformers for Language Modeling } ,
author = { David R. So and Wojciech Ma'nke and Hanxiao Liu and Zihang Dai and Noam M. Shazeer and Quoc V. Le } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2109.08668 }
} @misc { cao2020global ,
title = { Global Context Networks } ,
author = { Yue Cao and Jiarui Xu and Stephen Lin and Fangyun Wei and Han Hu } ,
year = { 2020 } ,
eprint = { 2012.13375 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Karras2022ElucidatingTD ,
title = { Elucidating the Design Space of Diffusion-Based Generative Models } ,
author = { Tero Karras and Miika Aittala and Timo Aila and Samuli Laine } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2206.00364 }
} @inproceedings { NEURIPS2020_4c5bcfec ,
author = { Ho, Jonathan and Jain, Ajay and Abbeel, Pieter } ,
booktitle = { Advances in Neural Information Processing Systems } ,
editor = { H. Larochelle and M. Ranzato and R. Hadsell and M.F. Balcan and H. Lin } ,
pages = { 6840--6851 } ,
publisher = { Curran Associates, Inc. } ,
title = { Denoising Diffusion Probabilistic Models } ,
url = { https://proceedings.neurips.cc/paper/2020/file/4c5bcfec8584af0d967f1ab10179ca4b-Paper.pdf } ,
volume = { 33 } ,
year = { 2020 }
} @article { Lugmayr2022RePaintIU ,
title = { RePaint: Inpainting using Denoising Diffusion Probabilistic Models } ,
author = { Andreas Lugmayr and Martin Danelljan and Andr{'e}s Romero and Fisher Yu and Radu Timofte and Luc Van Gool } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2201.09865 }
} @misc { ho2022video ,
title = { Video Diffusion Models } ,
author = { Jonathan Ho and Tim Salimans and Alexey Gritsenko and William Chan and Mohammad Norouzi and David J. Fleet } ,
year = { 2022 } ,
eprint = { 2204.03458 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { chen2022analog ,
title = { Analog Bits: Generating Discrete Data using Diffusion Models with Self-Conditioning } ,
author = { Ting Chen and Ruixiang Zhang and Geoffrey Hinton } ,
year = { 2022 } ,
eprint = { 2208.04202 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { Singer2022 ,
author = { Uriel Singer } ,
url = { https://makeavideo.studio/Make-A-Video.pdf }
} @article { Sunkara2022NoMS ,
title = { No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution Images and Small Objects } ,
author = { Raja Sunkara and Tie Luo } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2208.03641 }
} @article { Salimans2022ProgressiveDF ,
title = { Progressive Distillation for Fast Sampling of Diffusion Models } ,
author = { Tim Salimans and Jonathan Ho } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2202.00512 }
} @article { Ho2022ImagenVH ,
title = { Imagen Video: High Definition Video Generation with Diffusion Models } ,
author = { Jonathan Ho and William Chan and Chitwan Saharia and Jay Whang and Ruiqi Gao and Alexey A. Gritsenko and Diederik P. Kingma and Ben Poole and Mohammad Norouzi and David J. Fleet and Tim Salimans } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.02303 }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @inproceedings { Hang2023EfficientDT ,
title = { Efficient Diffusion Training via Min-SNR Weighting Strategy } ,
author = { Tiankai Hang and Shuyang Gu and Chen Li and Jianmin Bao and Dong Chen and Han Hu and Xin Geng and Baining Guo } ,
year = { 2023 }
} @article { Zhang2021TokenST ,
title = { Token Shift Transformer for Video Classification } ,
author = { Hao Zhang and Y. Hao and Chong-Wah Ngo } ,
journal = { Proceedings of the 29th ACM International Conference on Multimedia } ,
year = { 2021 }
} @inproceedings { anonymous2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
note = { under review }
} @inproceedings { Sadat2024EliminatingOA ,
title = { Eliminating Oversaturation and Artifacts of High Guidance Scales in Diffusion Models } ,
author = { Seyedmorteza Sadat and Otmar Hilliges and Romann M. Weber } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273098845 }
}

