eye in the sky
1.0.0
Classificação de imagens de satélite, InterIIT Techmeet 2018, IIT Bombay.
Equipe: Manideep Kolla, Aniket Mandle, Apoorva Kumar
Este repositório contém a implementação de dois algoritmos, nomeadamente U-Net: Redes Convolucionais para Segmentação de Imagens Biomédicas e Rede de Análise de Cena em Pirâmide modificada para o problema de classificação de imagens de satélite.
main_unet.py : código Python para treinar o algoritmo com arquitetura U-Net incluindo a codificação das verdades básicas.unet.py : Contém nossa implementação de camadas U-Net.test_unet.py : Código para teste, cálculo de precisões, cálculo de matrizes de confusão para treinamento e validação e salvamento de previsões pelo modelo U-Net em imagens de treinamento, validação e teste.Inter-IIT-CSRE : contém todos os dados de treinamento, validação e teste.Comparison_Test.pdf : comparação lado a lado dos dados de teste com as previsões do modelo U-Net nos dados.train_predictions : previsões do modelo U-Net em imagens de treinamento e validação.plots : Gráficos de precisão e perda para treinamento e validação para arquitetura U-Net.Test_images , Test_outputs : contém imagens de teste e suas previsões no modelo U-Net.class_masks , compare_pred_to_gt , images_for_doc : Contém diversas imagens para documentação.PSPNet : Contém arquivos de treinamento para implementação do algoritmo PSPNet para classificação de imagens de satélite. Clone o repositório, mude seu diretório de trabalho atual para o diretório clonado. Crie pastas com nomes train_predictions e test_outputs para salvar as saídas previstas do modelo em imagens de treinamento e teste (não é necessário agora, pois o repositório já contém essas pastas)
$ git clone https://github.com/manideep2510/eye-in-the-sky.git
$ cd eye-in-the-sky
$ mkdir train_predictions
$ mkdir test_outputs
Para treinar o modelo U-Net e economizar pesos, execute o comando abaixo
$ python3 main_unet.py
Para testar o modelo U-Net, calculando precisões, calculando matrizes de confusão para treinamento e validação e salvando previsões do modelo em imagens de treinamento, validação e teste.
$ python3 test_unet.py
Você pode receber um erro xrange is not defined ao executar nosso código. Este erro não se deve a erros em nosso código, mas sim ao pacote python desatualizado chamado libtiff (algumas partes do código-fonte do pacote estão em python2 e outras em python3) que usamos para ler o conjunto de dados em que as imagens estão no formato .tif. Não pudemos usar outras bibliotecas como openCV ou PIL para ler as imagens, pois elas não suportam adequadamente a leitura de imagens .tif de 4 canais.
Este erro pode ser resolvido editando o código fonte da biblioteca libtiff .
Vá até o arquivo no código-fonte da biblioteca de onde surge o erro (o nome do arquivo será exibido no terminal quando estiver mostrando o erro) e substitua todas as funções xrange() (python2) no arquivo por range() (python3).
Estamos fornecendo aqui alguns pesos pré-treinados razoavelmente bons para que os usuários não precisem treinar do zero.
| Descrição | Tarefa | Conjunto de dados | Modelo |
|---|---|---|---|
| Arquitetura UNet | Classificação de imagens de satélite | Conjunto de dados IITB (consulte a pasta Inter-IIT-CSRE ) | baixar (.h5) |
Para usar os pesos pré-treinados, altere o nome do arquivo .h5 (arquivo de pesos) mencionado em test_unet.py para corresponder ao nome do arquivo de pesos que você baixou sempre que necessário.
Vamos agora discutir
1. Do que se trata este projeto,
2. Arquiteturas que usamos e experimentamos e
3. Algumas novas estratégias de treinamento que usamos no projeto
Sensoriamento remoto é a ciência de obter informações sobre objetos ou áreas à distância, normalmente de aeronaves ou satélites.
Percebemos o problema de classificação de imagens de satélite como um problema de segmentação semântica e construímos algoritmos de segmentação semântica em aprendizagem profunda para resolver isso.
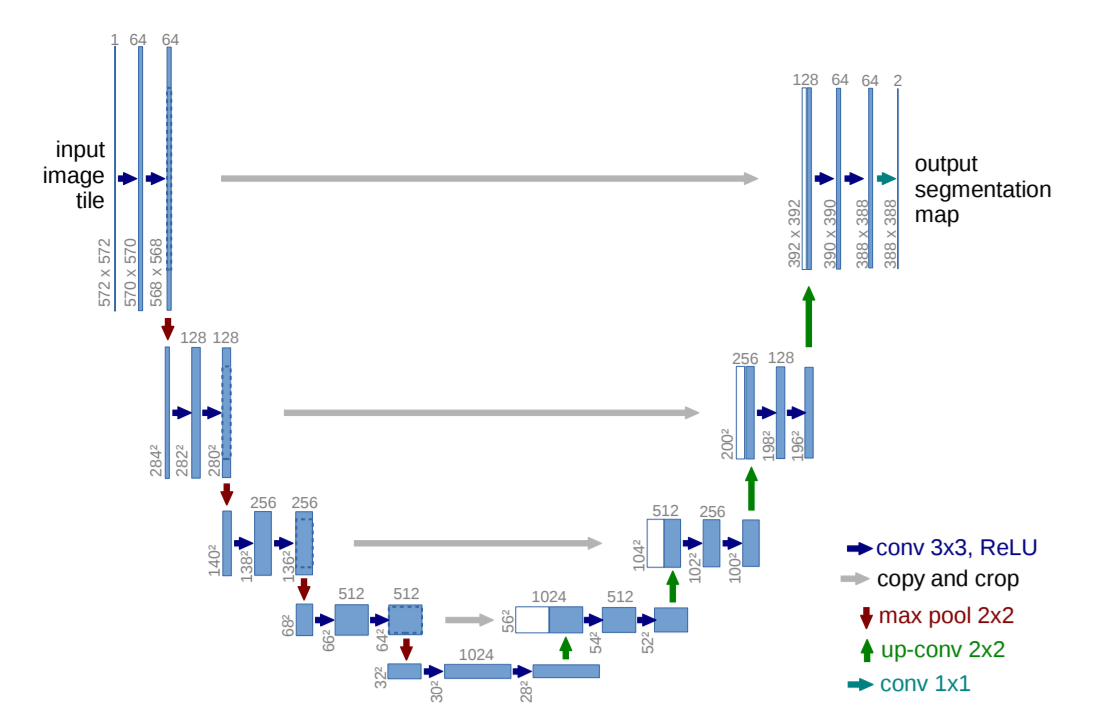
U-Net: Redes Convolucionais para Segmentação de Imagens Biomédicas
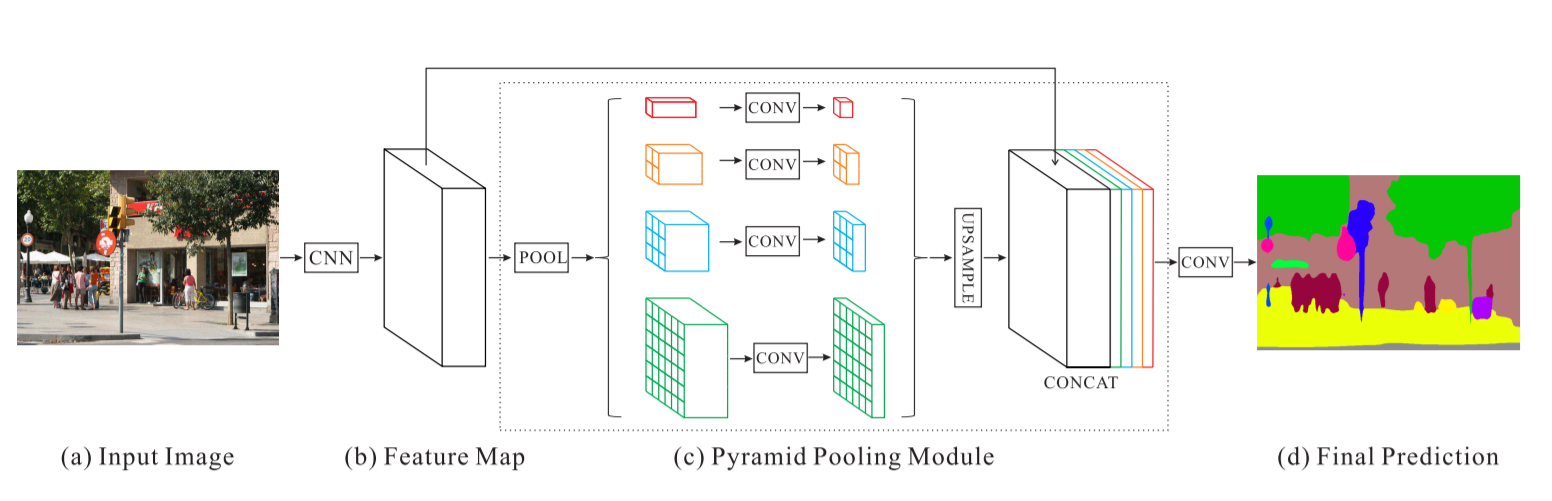
Rede de análise de cena em pirâmide - PSPNet
As informações básicas fornecidas são imagens RGB de 3 canais. No conjunto de dados atual, existem apenas 9 valores RGB exclusivos nas verdades básicas, pois há 9 classes que devem ser classificadas. Esses 9 valores RGB diferentes são codificados one-hot para gerar uma verdade fundamental codificada em 9 canais, com cada canal representando uma classe específica.
Abaixo está o esquema de codificação
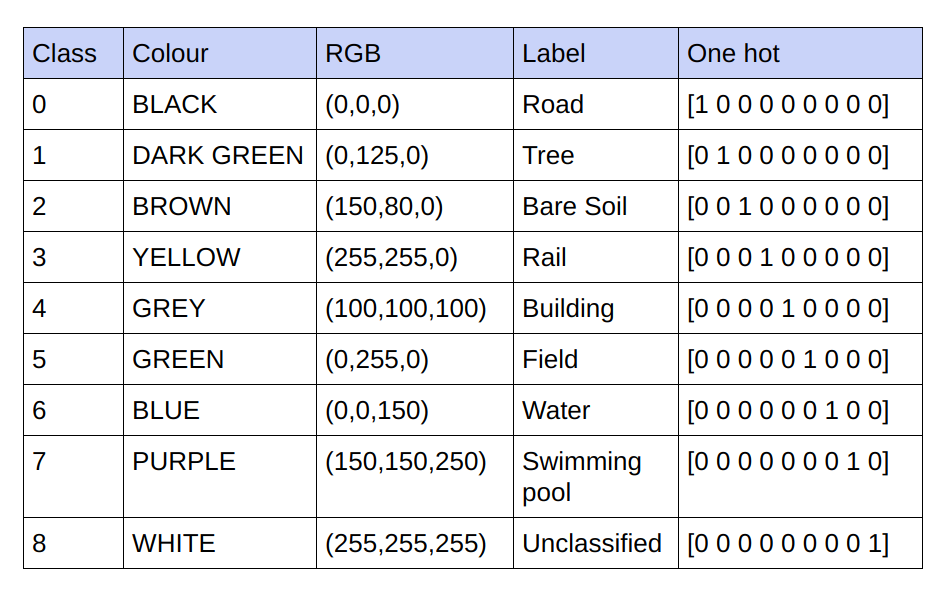
Realização de cada canal na verdade básica codificada como uma classe

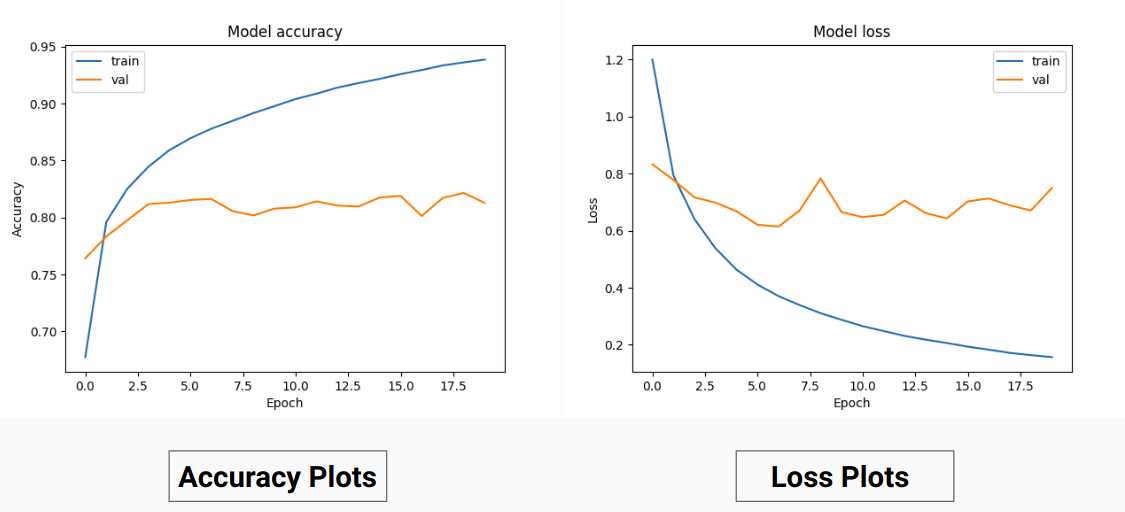
Portanto, em vez de treinar nos valores RGB da verdade básica, nós os convertemos em valores one-hot de diferentes classes. Essa abordagem nos rendeu uma precisão de validação de 85% e uma precisão de treinamento de 92% em comparação com 71% de precisão de validação e 65% de precisão de treinamento quando estávamos usando os valores reais RGB para treinamento.
Isso pode ser devido à diminuição da variância e da média da verdade básica dos dados de treinamento, uma vez que atua como uma técnica de normalização eficaz. O melhor desempenho desta técnica de treinamento também se deve ao fato de o modelo fornecer uma saída com 9 mapas de características, cada mapa indicando uma classe, ou seja, esta técnica de treinamento está agindo como se o modelo fosse treinado em cada uma das 9 classes separadamente até certo ponto( mas aqui definitivamente a previsão em um canal que corresponde a uma classe específica depende de outros) .
Nossos resultados no PSPNet para classificação de imagens de satélite:
Precisão de treinamento - 49% Precisão de validação - 60%
Razões:
U-Net:
Rede U modificada:
Para treinamento e validação usamos as 14 imagens '.tif' na pasta Inter-IIT-CSRE/The-Eye-in-the-Sky-dataset .
Para treinamento usamos as primeiras 13 imagens do conjunto de dados e para validação, a 14ª imagem é usada .
Cada imagem de satélite na pasta sat contém 4 canais, nomeadamente R (Banda 1), G (Banda 2), B (Banda 3) e NIR (Banda 4).
As imagens reais no diretório gt são imagens RGB e representam 8 classes - estradas, edifícios, árvores, grama, solo descoberto, água, ferrovias e piscinas
A razão pela qual consideramos apenas uma imagem (14ª imagem) como conjunto de validação é porque ela é uma das menores imagens no conjunto de dados e não queremos deixar menos dados para treinamento, pois o conjunto de dados é muito pequeno. O conjunto de validação (14ª imagem) que consideramos não contém 3 classes (solo descoberto, trilho, enquete Swimmimg) que possuem precisões de treinamento bastante altas. A precisão da validação teria sido melhor se tivéssemos considerado uma imagem com todas as classes nela (nenhuma imagem no conjunto de dados contém todas as classes, há pelo menos uma classe faltando em todas as imagens).
O corte strided:
Para ter dados de treinamento suficientes das imagens de alta definição fornecidas, é necessário treinar o classificador que possui cerca de 31 milhões de parâmetros de nossa implementação U-Net. No tamanho de corte de 64x64 encontramos sub-representação das classes individuais e a geometria e continuidade dos objetos são perdidas, diminuindo o campo de visão das convoluções.
Usando uma janela de corte de 128x128 pixels com um passo de 32 resultante de 15.887 imagens de validação de treinamento 414.
Dimensões da imagem:
Antes do corte, as dimensões das imagens de treinamento são convertidas em múltiplos de passada por conveniência durante o corte de passada.
Para os casos em que o não. de cortes não é o múltiplo das dimensões da imagem. Tentamos inicialmente o preenchimento zero, percebemos que adicionar preenchimento adicionará artefatos indesejados na forma de pixels pretos nas imagens de treinamento e teste, levando ao treinamento em dados falsos e limites da imagem.
Alternativamente, alteramos corretamente as dimensões da imagem adicionando pixels extras no lado direito e na parte inferior da imagem. Então, preenchemos a diferença da parte esquerda da imagem até o final do déficit direito e da mesma forma para a parte superior e inferior da imagem.
Exemplo de treinamento 1: imagem '2.tif' de dados de treinamento
Exemplo de treinamento 2: imagem '4.tif' de dados de treinamento
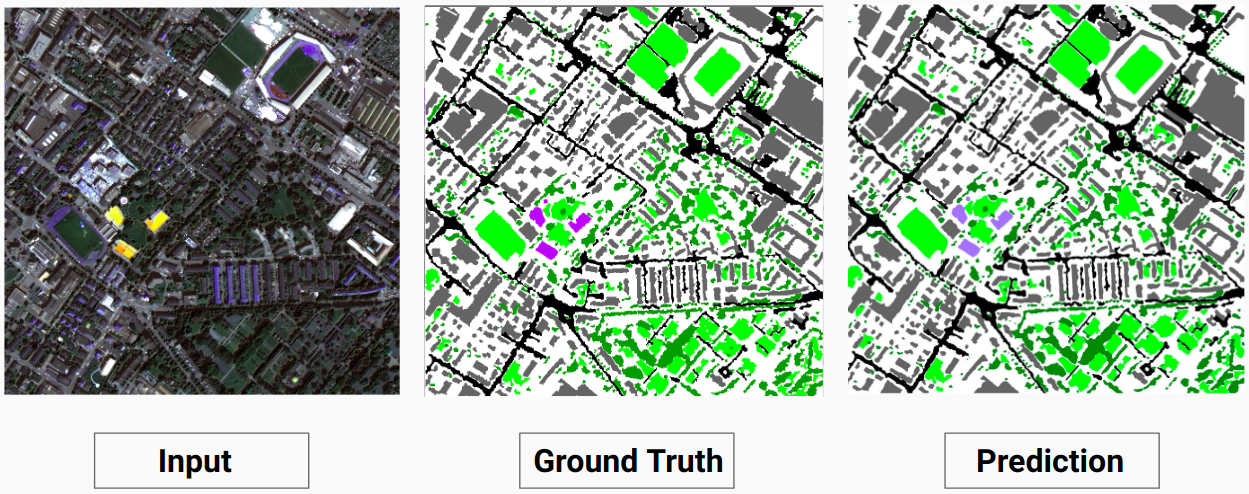
Exemplo de validação: imagem '14.tif' do conjunto de dados

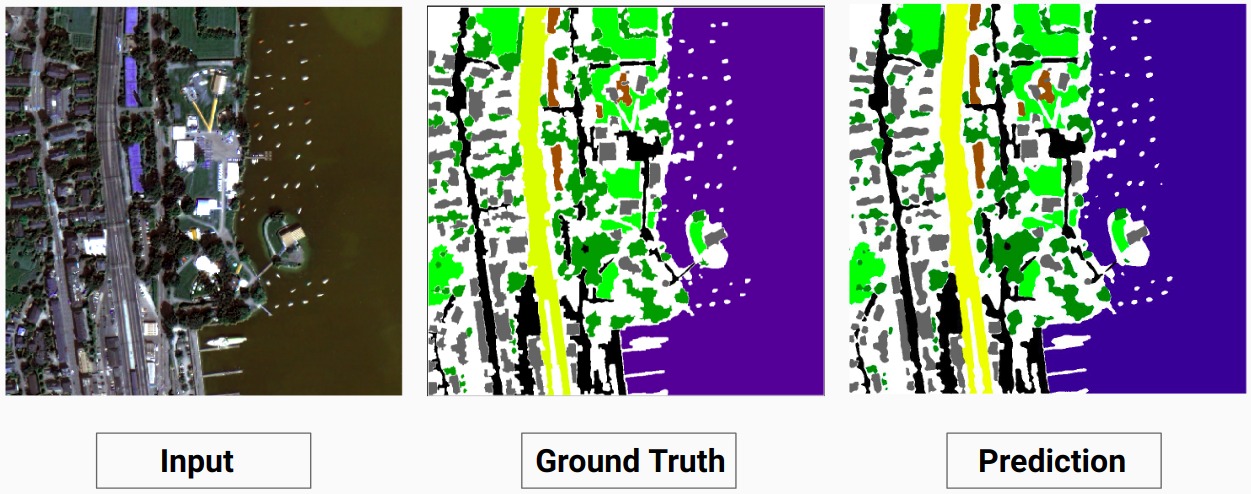
Nosso modelo é capaz de prever algumas classes que um anotador humano não conseguiu. As classes não identificáveis nas imagens são rotuladas como pixels brancos pelo anotador humano. Nosso modelo é capaz de prever alguns desses pixels brancos corretamente como alguma classe, mas isso causou uma diminuição na precisão geral, pois os pixels brancos são considerados uma classe separada pelo modelo.
Aqui o modelo é capaz de prever os pixels brancos como um edifício que está correto e pode ser visto claramente na imagem de entrada
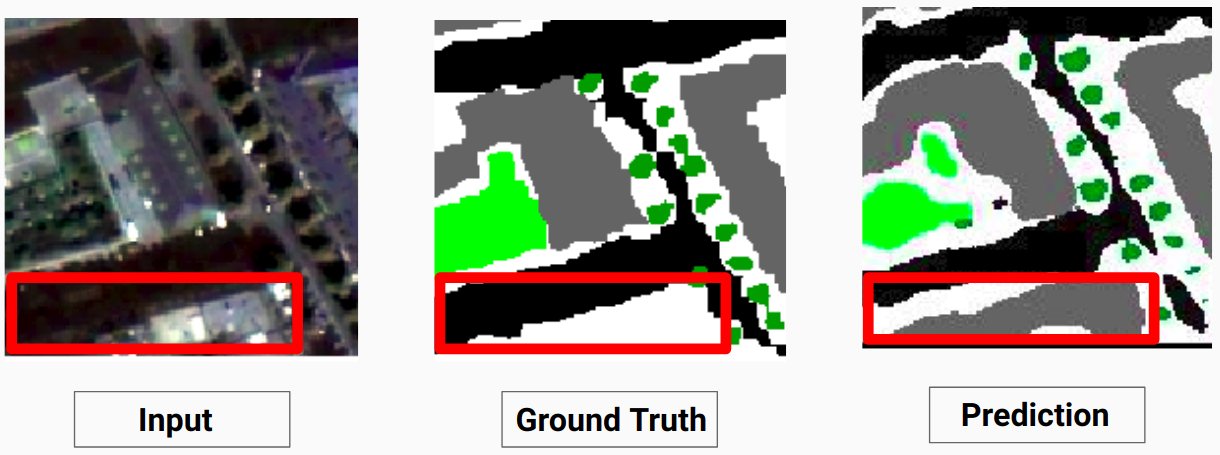
Confira Comparison_Test.pdf para comparação entre imagens de teste e seus resultados previstos pelo modelo
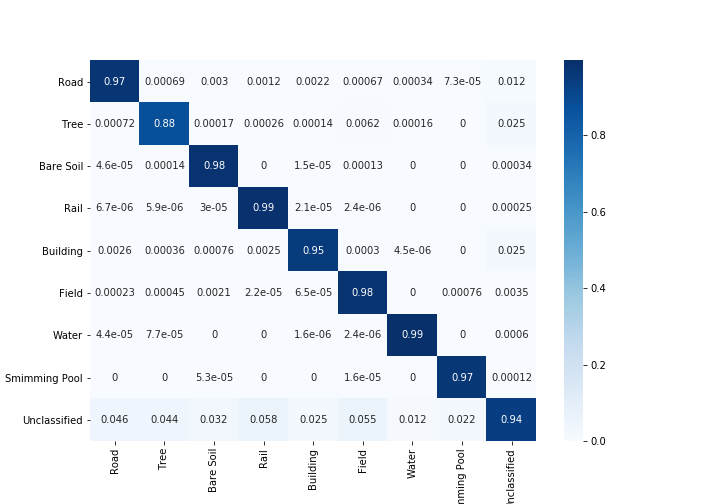
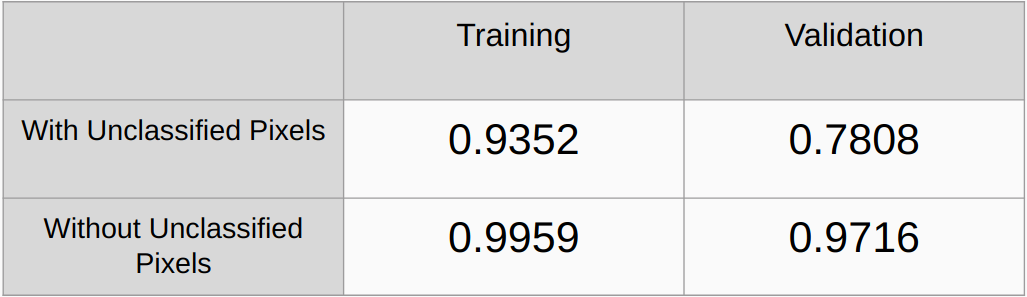
Coeficientes Kappa Com e Sem considerando os pixels não classificados
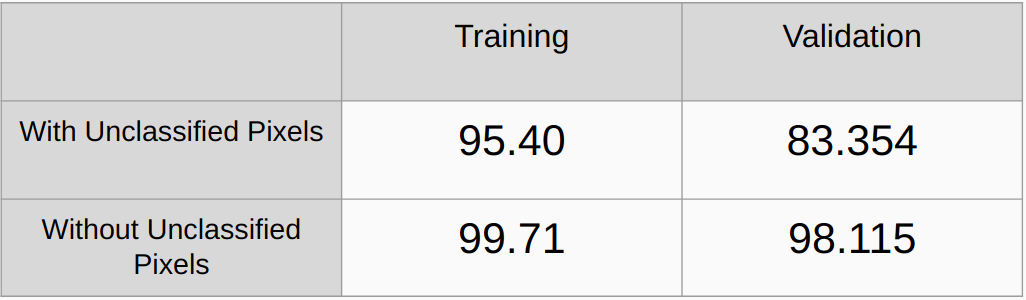
Precisão geral com e sem considerar os pixels não classificados
Precisa adicionar métodos de regularização como regularização L2 e abandono e verificar o desempenho
Implemente um algoritmo para detectar automaticamente todos os valores RGB exclusivos nas verdades básicas e codificá-los onehot em vez de encontrar manualmente os valores RGB.
[1] U-Net: Redes Convolucionais para Segmentação de Imagens Biomédicas, Olaf Ronneberger, Philipp Fischer e Thomas Brox
[2] Rede de análise de cena em pirâmide, Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, Jiaya Jia
[3] Um guia de 2017 para segmentação semântica com aprendizado profundo, Sasank Chilamkurthy


