linformer pytorch
version
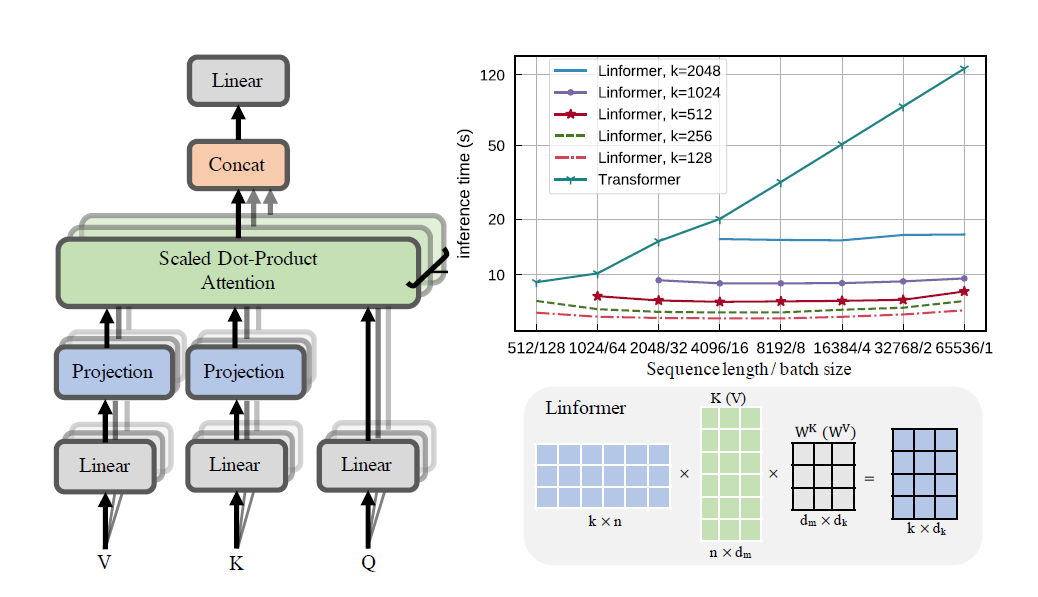
Uma implementação prática do artigo Linformer. Esta é uma atenção com complexidade apenas linear em n, permitindo que comprimentos de sequência muito longos (1mil+) sejam atendidos em hardware moderno.
Este repositório é um transformador do estilo Attention Is All You Need, completo com um módulo codificador e decodificador. A novidade aqui é que agora é possível tornar lineares as cabeças de atenção. Confira abaixo como usá-lo.
Isso está em processo de validação no wikitext-2. Atualmente, ele funciona no mesmo nível de outros mecanismos de atenção esparsa, como o Transformador Sinkhorn, mas os melhores hiperparâmetros ainda precisam ser encontrados.
A visualização das cabeças também é possível. Para ver mais informações, verifique a seção Visualização abaixo.
Eu não sou o autor do artigo.
1,23 milhões de fichas
pip install linformer-pytorch
Alternativamente,
git clone https://github.com/tatp22/linformer-pytorch.git
cd linformer-pytorch
Modelo de linguagem Linformer
from linformer_pytorch import LinformerLM
import torch
model = LinformerLM (
num_tokens = 10000 , # Number of tokens in the LM
input_size = 512 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim_d = None , # Overwrites the inner dim of the attention heads. If None, sticks with the recommended channels // nhead, as in the "Attention is all you need" paper
dim_k = 128 , # The second dimension of the P_bar matrix from the paper
dim_ff = 128 , # Dimension in the feed forward network
dropout_ff = 0.15 , # Dropout for feed forward network
nhead = 4 , # Number of attention heads
depth = 2 , # How many times to run the model
dropout = 0.1 , # How much dropout to apply to P_bar after softmax
activation = "gelu" , # What activation to use. Currently, only gelu and relu supported, and only on ff network.
use_pos_emb = True , # Whether or not to use positional embeddings
checkpoint_level = "C0" , # What checkpoint level to use. For more information, see below.
parameter_sharing = "layerwise" , # What level of parameter sharing to use. For more information, see below.
k_reduce_by_layer = 0 , # Going down `depth`, how much to reduce `dim_k` by, for the `E` and `F` matrices. Will have a minimum value of 1.
full_attention = False , # Use full attention instead, for O(n^2) time and space complexity. Included here just for comparison
include_ff = True , # Whether or not to include the Feed Forward layer
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
emb_dim = 128 , # If you want the embedding dimension to be different than the channels for the Linformer
causal = False , # If you want this to be a causal Linformer, where the upper right of the P_bar matrix is masked out.
method = "learnable" , # The method of how to perform the projection. Supported methods are 'convolution', 'learnable', and 'no_params'
ff_intermediate = None , # See the section below for more information
). cuda ()
x = torch . randint ( 1 , 10000 ,( 1 , 512 )). cuda ()
y = model ( x )
print ( y ) # (1, 512, 10000) Autoatenção do Linformer, pilhas de MHAttention e FeedForward s
from linformer_pytorch import Linformer
import torch
model = Linformer (
input_size = 262144 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim_d = None , # Overwrites the inner dim of the attention heads. If None, sticks with the recommended channels // nhead, as in the "Attention is all you need" paper
dim_k = 128 , # The second dimension of the P_bar matrix from the paper
dim_ff = 128 , # Dimension in the feed forward network
dropout_ff = 0.15 , # Dropout for feed forward network
nhead = 4 , # Number of attention heads
depth = 2 , # How many times to run the model
dropout = 0.1 , # How much dropout to apply to P_bar after softmax
activation = "gelu" , # What activation to use. Currently, only gelu and relu supported, and only on ff network.
checkpoint_level = "C0" , # What checkpoint level to use. For more information, see below.
parameter_sharing = "layerwise" , # What level of parameter sharing to use. For more information, see below.
k_reduce_by_layer = 0 , # Going down `depth`, how much to reduce `dim_k` by, for the `E` and `F` matrices. Will have a minimum value of 1.
full_attention = False , # Use full attention instead, for O(n^2) time and space complexity. Included here just for comparison
include_ff = True , # Whether or not to include the Feed Forward layer
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
). cuda ()
x = torch . randn ( 1 , 262144 , 64 ). cuda ()
y = model ( x )
print ( y ) # (1, 262144, 64)Atenção Linformer Multihead
from linformer_pytorch import MHAttention
import torch
model = MHAttention (
input_size = 512 , # Dimension 1 of the input
channels = 64 , # Dimension 2 of the input
dim = 8 , # Dim of each attn head
dim_k = 128 , # What to sample the input length down to
nhead = 8 , # Number of heads
dropout = 0 , # Dropout for each of the heads
activation = "gelu" , # Activation after attention has been concat'd
checkpoint_level = "C2" , # If C2, checkpoint each of the heads
parameter_sharing = "layerwise" , # What level of parameter sharing to do
E_proj , F_proj , # The E and F projection matrices
full_attention = False , # Use full attention instead
w_o_intermediate_dim = None , # If not None, have 2 w_o matrices, such that instead of `dim*nead,channels`, you have `dim*nhead,w_o_int`, and `w_o_int,channels`
)
x = torch . randn ( 1 , 512 , 64 )
y = model ( x )
print ( y ) # (1, 512, 64)A cabeça de atenção linear, a novidade do artigo
from linformer_pytorch import LinearAttentionHead
import torch
model = LinearAttentionHead (
dim = 64 , # Dim 2 of the input
dropout = 0.1 , # Dropout of the P matrix
E_proj , F_proj , # The E and F layers
full_attention = False , # Use Full Attention instead
)
x = torch . randn ( 1 , 512 , 64 )
y = model ( x , x , x )
print ( y ) # (1, 512, 64)Um módulo codificador/decodificador.
Nota: Para sequências causais, pode-se definir o sinalizador causal=True no LinformerLM para mascarar o canto superior direito na matriz de atenção (n,k) .
import torch
from linformer_pytorch import LinformerLM
encoder = LinformerLM (
num_tokens = 10000 ,
input_size = 512 ,
channels = 16 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
k_reduce_by_layer = 1 ,
return_emb = True ,
)
decoder = LinformerLM (
num_tokens = 10000 ,
input_size = 512 ,
channels = 16 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
decoder_mode = True ,
)
x = torch . randint ( 1 , 10000 ,( 1 , 512 ))
y = torch . randint ( 1 , 10000 ,( 1 , 512 ))
x_mask = torch . ones_like ( x ). bool ()
y_mask = torch . ones_like ( y ). bool ()
enc_output = encoder ( x , input_mask = x_mask )
print ( enc_output . shape ) # (1, 512, 128)
dec_output = decoder ( y , embeddings = enc_output , input_mask = y_mask , embeddings_mask = x_mask )
print ( dec_output . shape ) # (1, 512, 10000) Uma maneira fácil de obter as matrizes E e F pode ser feita chamando a função get_EF . Por exemplo, para um n de 1000 e um k de 100 :
from linfromer_pytorch import get_EF
import torch
E = get_EF ( 1000 , 100 ) Com o sinalizador method , pode-se definir o método pelo qual o linformer executa a redução da resolução. Atualmente, três métodos são suportados:
learnable : este método de redução da resolução cria um módulo n,k nn.Linear que pode ser aprendido.convolution : Este método de redução da resolução cria uma convolução 1d, com comprimento da passada e tamanho do kernel n/k .no_params : Isso cria uma matriz n,k fixa com valores de N(0,1/k)No futuro, posso incluir pooling ou outra coisa. Mas por enquanto, essas são as opções que existem.
Como uma tentativa de introduzir ainda mais economia de memória, foi introduzido o conceito de níveis de checkpoint. Os três níveis atuais de pontos de verificação são C0 , C1 e C2 . Ao subir os níveis dos pontos de verificação, sacrifica-se a velocidade para economizar memória. Ou seja, o nível de checkpoint C0 é o mais rápido, mas ocupa mais espaço na GPU, enquanto C2 é o mais lento, mas ocupa menos espaço na GPU. Os detalhes de cada nível de ponto de verificação são os seguintes:
C0 : Sem ponto de verificação. Os modelos funcionam enquanto mantêm todas as cabeças de atenção e camadas ff na memória da GPU.C1 : Verifique cada atenção do MultiHead, bem como cada camada ff. Com isso, aumentar depth deverá ter impacto mínimo na memória.C2 : Junto com as otimizações no nível C1 , verifique cada cabeçote em cada camada MultiHead Attention. Com isso, aumentar nhead deve ter menos impacto na memória. No entanto, concatenar as cabeças com torch.cat ainda ocupa muita memória e esperamos que isso seja otimizado no futuro.Os detalhes de desempenho ainda são desconhecidos, mas a opção existe para usuários que desejam experimentar.
Outra tentativa de introduzir economia de memória no artigo foi introduzir o compartilhamento de parâmetros entre as projeções. Isto é mencionado na seção 4 do artigo; em particular, houve 4 tipos diferentes de compartilhamento de parâmetros que os autores discutiram, e todos foram implementados neste repositório. A primeira opção ocupa mais memória e cada opção adicional reduz os requisitos de memória necessários.
none : não há compartilhamento de parâmetros. Para cada cabeça e para cada camada, uma nova matriz E e uma nova matriz F são calculadas para cada cabeça em cada camada.headwise : cada camada possui uma matriz E e F exclusiva. Todas as cabeças da camada compartilham esta matriz.kv : Cada camada possui uma matriz de projeção única P e E = F = P para cada camada. Todas as cabeças compartilham esta matriz de projeção P .layerwise : Existe uma matriz de projeção P , e cada cabeça em cada camada usa E = F = P Conforme iniciado no artigo, isso significa que para uma rede de 12 camadas e 12 cabeças, haveria 288 , 24 , 12 e 1 matrizes de projeção diferentes, respectivamente.
Observe que com a opção k_reduce_by_layer , a opção layerwise não terá efeito, pois utilizará a dimensão k para a primeira camada. Portanto, se o valor de k_reduce_by_layer for maior que 0 , provavelmente não se deve usar a opção de compartilhamento layerwise .
Além disso, observe que, segundo os autores, na figura 3, esse compartilhamento de parâmetros não afeta muito o resultado final. Portanto, pode ser melhor manter o compartilhamento layerwise para tudo, mas existe a opção para os usuários experimentarem.
Um pequeno problema com a implementação atual do Linformer é que o comprimento da sua sequência deve corresponder ao sinalizador input_size do modelo. O Padder preenche o tamanho da entrada de forma que o tensor possa ser alimentado na rede. Um exemplo:
from linformer_pytorch import Linformer , Padder
import torch
model = Linformer (
input_size = 512 ,
channels = 16 ,
dim_d = 32 ,
dim_k = 16 ,
dim_ff = 32 ,
nhead = 6 ,
depth = 3 ,
checkpoint_level = "C1" ,
)
model = Padder ( model )
x = torch . randn ( 1 , 500 , 16 ) # This does not match the input size!
y = model ( x )
print ( y ) # (1, 500, 16) 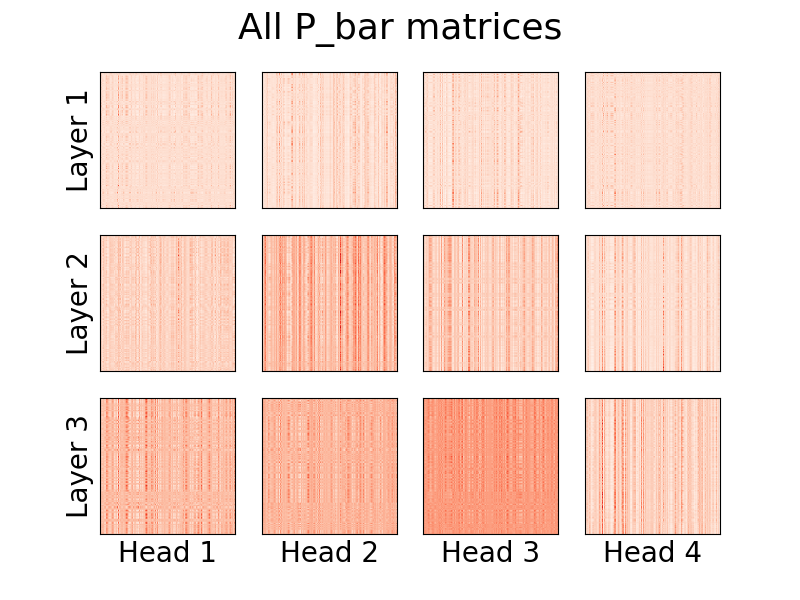
A partir da versão 0.8.0 , agora é possível visualizar as cabeças de atenção do linformer! Para ver isso em ação, basta importar a classe Visualizer e executar a função plot_all_heads() para ver uma imagem de todas as cabeças de atenção em cada nível, de tamanho (n,k). Certifique-se de especificar visualize=True na passagem direta, pois isso salva a matriz P_bar para que a classe Visualizer possa visualizar corretamente o cabeçalho.
Um exemplo funcional do código pode ser encontrado abaixo, e o mesmo código pode ser encontrado em ./examples/example_vis.py :
import torch
from linformer_pytorch import Linformer , Visualizer
model = Linformer (
input_size = 512 ,
channels = 16 ,
dim_k = 128 ,
dim_ff = 32 ,
nhead = 4 ,
depth = 3 ,
activation = "relu" ,
checkpoint_level = "C0" ,
parameter_sharing = "layerwise" ,
k_reduce_by_layer = 1 ,
)
# One can load the model weights here
x = torch . randn ( 1 , 512 , 16 ) # What input you want to visualize
y = model ( x , visualize = True )
vis = Visualizer ( model )
vis . plot_all_heads ( title = "All P_bar matrices" , # Change the title if you'd like
show = True , # Show the picture
save_file = "./heads.png" , # If not None, save the picture to a file
figsize = ( 8 , 6 ), # How big the figure should be
n_limit = None # If not None, limit how much from the `n` dimension to show
)Uma explicação detalhada do que essas cabeças significam pode ser encontrada no item 15.
Semelhante ao Reformer, tentarei fazer um Módulo Codificador/Decodificador, para que o treinamento possa ser simplificado. Isso funciona como 2 classes LinformerLM . Os parâmetros podem ser ajustados individualmente para cada um, com o codificador tendo o prefixo enc_ para todos os hiperparâmetros e o decodificador tendo o prefixo dec_ de maneira semelhante. Até agora, o que está implementado é:
import torch
from linformer_pytorch import LinformerEncDec
encdec = LinformerEncDec (
enc_num_tokens = 10000 ,
enc_input_size = 512 ,
enc_channels = 16 ,
dec_num_tokens = 10000 ,
dec_input_size = 512 ,
dec_channels = 16 ,
)
x = torch . randint ( 1 , 10000 ,( 1 , 512 ))
y = torch . randint ( 1 , 10000 ,( 1 , 512 ))
output = encdec ( x , y )Estou planejando uma maneira de gerar uma sequência de texto para isso.
ff_intermediate Agora, a dimensão do modelo pode ser diferente nas camadas intermediárias. Esta alteração se aplica ao módulo ff e somente ao codificador. Agora, se a flag ff_intermediate não for None, as camadas ficarão assim:
channels -> ff_dim -> ff_intermediate (For layer 1)
ff_intermediate -> ff_dim -> ff_intermediate (For layers 2 to depth-1)
ff_intermediate -> ff_dim -> channels (For layer depth)
Ao contrário de
channels -> ff_dim -> channels (For all layers)
input_size e dim_k , respectivamente.apex deveriam funcionar com isso, porém, na prática, não foi testado.input_size , k= dim_k e d= dim_d . LinformerEncDec Esta é a primeira vez que reproduzo o resultado de um artigo, então algumas coisas podem estar erradas. Se você encontrar um problema, abra-o e tentarei resolver isso.
Obrigado a lucidrains, cujos outros repositórios de atenção esparsa me ajudaram a projetar este Linformer Repo.
@misc { wang2020linformer ,
title = { Linformer: Self-Attention with Linear Complexity } ,
author = { Sinong Wang and Belinda Z. Li and Madian Khabsa and Han Fang and Hao Ma } ,
year = { 2020 } ,
eprint = { 2006.04768 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @inproceedings { vaswani2017attention ,
title = { Attention is all you need } ,
author = { Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, {L}ukasz and Polosukhin, Illia } ,
booktitle = { Advances in neural information processing systems } ,
pages = { 5998--6008 } ,
year = { 2017 }
}"Ouça com atenção..."


