intelligent trading bot
1.0.0
___ _ _ _ _ _ _____ _ _ ____ _
|_ _|_ __ | |_ ___| | (_) __ _ ___ _ __ | |_ |_ _| __ __ _ __| (_)_ __ __ _ | __ ) ___ | |_
| || '_ | __/ _ | | |/ _` |/ _ '_ | __| | || '__/ _` |/ _` | | '_ / _` | | _ / _ | __|
| || | | | || __/ | | | (_| | __/ | | | |_ | || | | (_| | (_| | | | | | (_| | | |_) | (_) | |_
|___|_| |_|_____|_|_|_|__, |___|_| |_|__| |_||_| __,_|__,_|_|_| |_|__, | |____/ ___/ __|
|___/ |___/
₿ Ξ ₳ ₮ ✕ ◎ ● Ð Ł Ƀ Ⱥ ∞ ξ ◈ ꜩ ɱ ε ɨ Ɓ Μ Đ ⓩ Ο Ӿ Ɍ ȿ
? Sinais de negociação inteligentes ? https://t.me/intelligent_trading_signals
O projeto visa desenvolver um bot de negociação inteligente para negociação automatizada de criptomoedas usando algoritmos de aprendizado de máquina (ML) de última geração e engenharia de recursos. O projeto fornece as seguintes funcionalidades principais:
O serviço de sinalização funciona em nuvem e envia seus sinais para este canal do Telegram:
? Sinais de negociação inteligentes ? https://t.me/intelligent_trading_signals
Todos podem se inscrever no canal para ter uma ideia dos sinais que esse bot gera.
Atualmente, o bot está configurado usando os seguintes parâmetros:
Há períodos de silêncio quando a pontuação é inferior ao limite e nenhuma notificação é enviada ao canal. Se a pontuação for maior que o limite, a cada minuto será enviada uma notificação semelhante a
₿ 24.518 ??? Pontuação: -0,26
O primeiro número é o último preço de fechamento. A pontuação -0,26 significa que é muito provável que o preço seja inferior ao preço de fechamento atual.
Se a pontuação exceder algum limite especificado no modelo, será gerado um sinal de compra ou venda, o que significa que é um bom momento para fazer uma negociação. Essas notificações são as seguintes:
? COMPRAR: ₿ 24.033 Pontuação: +0,34
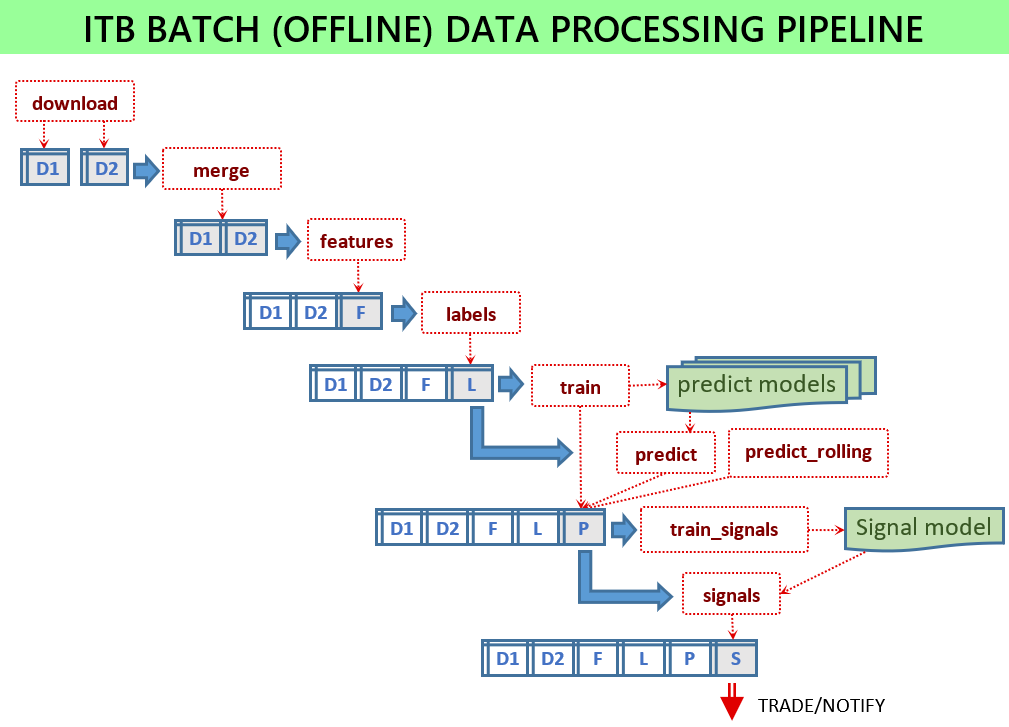
Para que o serviço de sinalização funcione, vários modelos de ML devem ser treinados e os arquivos de modelo devem estar disponíveis para o serviço. Todos os scripts são executados em modo batch, carregando alguns dados de entrada e armazenando alguns arquivos de saída. Os scripts em lote estão localizados no módulo scripts .
Se tudo estiver configurado, os seguintes scripts deverão ser executados:
python -m scripts.download_binance -c config.jsonpython -m scripts.merge -c config.jsonpython -m scripts.features -c config.jsonpython -m scripts.labels -c config.jsonpython -m scripts.train -c config.jsonpython -m scripts.signals -c config.jsonpython -m scripts.train_signals -c config.json Sem um arquivo de configuração, os scripts usarão os parâmetros padrão, úteis para fins de teste e não destinados a mostrar bom desempenho. Use arquivos de configuração de amostra fornecidos para cada versão, como config-sample-v0.6.0.jsonc .
O principal parâmetro de configuração para ambos os scripts é uma lista de fontes em data_sources . Uma entrada nesta lista especifica uma fonte de dados, bem como column_prefix usado para distinguir colunas com o mesmo nome de fontes diferentes.
Baixe os dados históricos mais recentes: python -m scripts.download_binance -c config.json
Mesclar vários conjuntos de dados históricos em um conjunto de dados: python -m scripts.merge -c config.json
Este script destina-se ao cálculo de recursos derivados:
python -m scripts.features -c config.json A lista de funcionalidades a serem geradas é configurada através da lista feature_sets no arquivo de configuração. A forma como os recursos são gerados é definida pelo gerador de recursos, cada um tendo alguns parâmetros especificados em sua seção de configuração.
talib depende da biblioteca de análise técnica TA-lib. Aqui está um exemplo de sua configuração "config": {"columns": ["close"], "functions": ["SMA"], "windows": [5, 10, 15]}itbstats implementa funções que podem ser encontradas em tsfresh como scipy_skew , scipy_kurtosis , lsbm (ataque mais longo abaixo da média), fmax (primeira localização do máximo), mean , std , area , slope . Aqui estão os parâmetros típicos: "config": {"columns": ["close"], "functions": ["skew", "fmax"], "windows": [5, 10, 15]}itblib implementado no ITB, mas a maioria de seus recursos pode ser gerada (muito mais rápido) via talibtsfresh gera funções da biblioteca tsfresh Este script é semelhante à geração de recursos porque adiciona novas colunas ao arquivo de entrada. Porém, essas colunas descrevem algo que queremos prever e o que não é conhecido ao executar no modo online. Por exemplo, poderia ser um aumento de preços no futuro:
python -m scripts.labels -c config.json A lista de rótulos a serem gerados é configurada através da lista label_sets na configuração. Um conjunto de rótulos aponta para a função que gera colunas adicionais. Sua configuração é muito semelhante às configurações de recursos.
highlow retorna True se o preço for superior ao limite especificado em algum horizonte futurohighlow2 Calcula aumentos (diminuições) futuros com a condição de que não haja diminuições (aumentos) significativos antes disso. Aqui está sua configuração típica: "config": {"columns": ["close", "high", "low"], "function": "high", "thresholds": [1.0, 1.5, 2.0], "tolerance": 0.2, "horizon": 10080, "names": ["first_high_10", "first_high_15", "first_high_20"]}topbot obsoletotopbot2 Calcula valores máximos e mínimos (rotulados como True). É garantido que cada máximo (mínimo) rotulado esteja cercado por mínimos (máximos) inferiores (superiores) ao nível especificado. A diferença mínima necessária entre mínimos e máximos adjacentes é especificada através de parâmetros level . O parâmetro tolerância permite incluir também pontos próximos do máximo/mínimo. Aqui está uma configuração típica: "config": {"columns": "close", "function": "bot", "level": 0.02, "tolerances": [0.1, 0.2], "names": ["bot2_1", "bot2_2"]} Este script usa os recursos de entrada e rótulos especificados para treinar vários modelos de ML:
python -m scripts.train -c config.jsonprediction-metrics.txt com as pontuações de previsão para todos os modelosConfiguração:
model_store.pytrain_featureslabelsalgorithms O objetivo desta etapa é agregar as pontuações de predição geradas por diferentes algoritmos para diferentes rótulos. O resultado é uma pontuação que deve ser consumida pelas regras de sinalização na próxima etapa. Os parâmetros de agregação são especificados na seção score_aggregation . Os buy_labels e sell_labels especificam pontuações de previsão de entrada processadas pelo procedimento de agregação. window é o número de etapas anteriores usadas para agregação contínua e combine é uma forma como dois tipos de pontuação (compra e rótulos) são combinados em uma pontuação de saída.
A pontuação gerada pelo procedimento de agregação é um número e o objetivo das regras de sinalização é tomar as decisões de negociação: comprar, vender ou não fazer nada. Os parâmetros das regras de sinalização estão descritos no trade_model .
Este script simula negociações usando muitos parâmetros de sinal de compra e venda e, em seguida, escolhe os parâmetros de sinal de melhor desempenho:
python -m scripts.train_signals -c config.jsonEste script inicia um serviço que executa periodicamente a mesma tarefa: carregar os dados mais recentes, gerar recursos, fazer previsões, gerar sinais, notificar assinantes:
python -m service.server -c config.jsonExistem dois problemas:
python -m scripts.predict_rolling -c config.jsonpython -m scripts.train_signals -c config.jsonOs parâmetros de configuração são especificados em dois arquivos:
service.App.py no campo config da classe App-c config.jsom para os serviços e scripts. Os valores deste arquivo de configuração substituirão aqueles no App.config quando este arquivo for carregado em um script ou serviço Aqui estão alguns campos mais importantes (em App.py e config.json ):
data_folder - localização dos arquivos de dados que são necessários apenas para scripts off-line em lotesymbol é um par de negociação como BTCUSDTlabels Lista de nomes de colunas que são tratados como rótulos. Se você definir um novo rótulo usado para treinamento e depois para previsão, será necessário especificar seu nome aquialgorithms Lista de nomes de algoritmos usados para treinamentotrain_features Lista de todos os nomes de colunas usados como recursos de entrada para treinamento e previsão.buy_labels e sell_labels Listas de colunas previstas usadas para sinaistrade_model Parâmetros do sinalizador (principalmente alguns limites)trader é uma seção para parâmetros do trader. Atualmente, não totalmente testado.collector Esta seção de parâmetros destina-se a serviços de coleta de dados. Existem dois tipos de serviços de coleta de dados: síncronos com solicitações regulares ao provedor de dados e serviço de streaming assíncrono que assina o provedor de dados e recebe notificações assim que novos dados estiverem disponíveis. Eles estão funcionando, mas não foram totalmente testados e integrados ao serviço principal. O principal padrão de uso atual depende de atualizações manuais de dados em lote, geração de recursos e treinamento de modelo. Uma razão para ter esses serviços de coleta de dados é 1) ter atualizações mais rápidas 2) ter dados não disponíveis na API normal, como carteira de pedidos (existem alguns recursos que usam esses dados, mas não estão integrados ao fluxo de trabalho principal).Consulte exemplos de arquivos de configuração e comentários em App.config para obter mais detalhes.
A cada minuto, o sinalizador executa as seguintes etapas para fazer uma previsão sobre a probabilidade de o preço aumentar ou diminuir:
Notas:
Iniciando o serviço: python3 -m service.server -c config.json
O trader está funcionando, mas não está totalmente depurado, principalmente, não foi testado quanto à estabilidade e confiabilidade. Portanto, deve ser considerado um protótipo com funcionalidades básicas. Atualmente está integrado ao Signaler, mas com um design melhor deveria ser um serviço separado.
Backtesting
Integrações externas


