gigagan pytorch
0.2.20

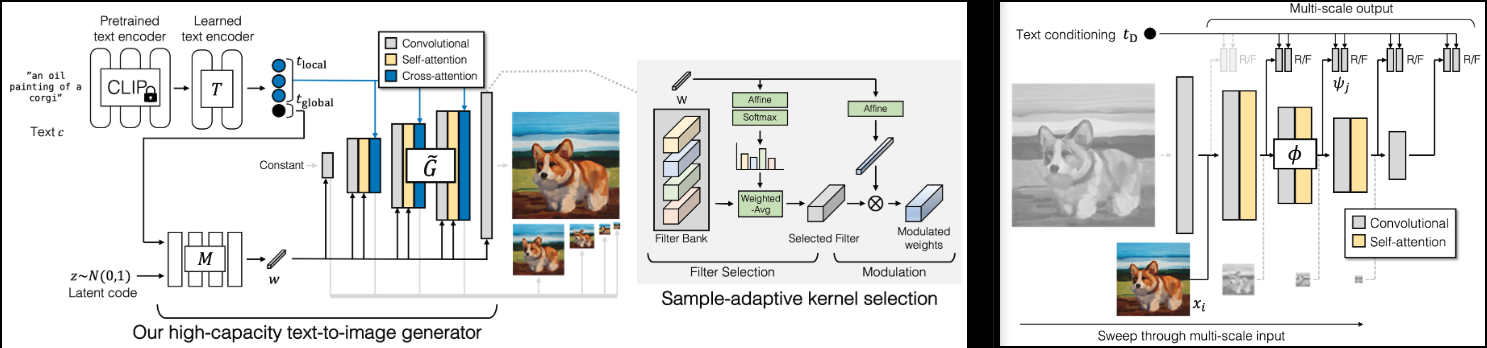
Implementação do GigaGAN (página do projeto), novo SOTA GAN da Adobe.
Também adicionarei algumas descobertas do gan leve, para convergência mais rápida (pular excitação da camada) e melhor estabilidade (perda auxiliar de reconstrução no discriminador)
Ele também conterá o código para os upsamplers de 1k a 4k, que considero o destaque deste artigo.
Por favor, junte-se se estiver interessado em ajudar na replicação com a comunidade LAION
EstabilidadeAI e ? Huggingface pelo generoso patrocínio, assim como aos meus outros patrocinadores, por me proporcionarem independência para inteligência artificial de código aberto.
? Huggingface por sua biblioteca acelerada
Todos os mantenedores do OpenClip, por seus modelos de texto-imagem de aprendizagem contrastiva de código aberto SOTA
Xavier pela revisão de código muito útil e pelas discussões sobre como a invariância de escala no discriminador deve ser construída!
@CerebralSeed para solicitação pull do código de amostragem inicial para o gerador e o upsampler!
Keerth pela revisão do código e apontando algumas discrepâncias com o artigo!
$ pip install gigagan-pytorchGAN incondicional simples, para começar
import torch
from gigagan_pytorch import (
GigaGAN ,
ImageDataset
)
gan = GigaGAN (
generator = dict (
dim_capacity = 8 ,
style_network = dict (
dim = 64 ,
depth = 4
),
image_size = 256 ,
dim_max = 512 ,
num_skip_layers_excite = 4 ,
unconditional = True
),
discriminator = dict (
dim_capacity = 16 ,
dim_max = 512 ,
image_size = 256 ,
num_skip_layers_excite = 4 ,
unconditional = True
),
amp = True
). cuda ()
# dataset
dataset = ImageDataset (
folder = '/path/to/your/data' ,
image_size = 256
)
dataloader = dataset . get_dataloader ( batch_size = 1 )
# you must then set the dataloader for the GAN before training
gan . set_dataloader ( dataloader )
# training the discriminator and generator alternating
# for 100 steps in this example, batch size 1, gradient accumulated 8 times
gan (
steps = 100 ,
grad_accum_every = 8
)
# after much training
images = gan . generate ( batch_size = 4 ) # (4, 3, 256, 256)Para Unet Upsampler incondicional
import torch
from gigagan_pytorch import (
GigaGAN ,
ImageDataset
)
gan = GigaGAN (
train_upsampler = True , # set this to True
generator = dict (
style_network = dict (
dim = 64 ,
depth = 4
),
dim = 32 ,
image_size = 256 ,
input_image_size = 64 ,
unconditional = True
),
discriminator = dict (
dim_capacity = 16 ,
dim_max = 512 ,
image_size = 256 ,
num_skip_layers_excite = 4 ,
multiscale_input_resolutions = ( 128 ,),
unconditional = True
),
amp = True
). cuda ()
dataset = ImageDataset (
folder = '/path/to/your/data' ,
image_size = 256
)
dataloader = dataset . get_dataloader ( batch_size = 1 )
gan . set_dataloader ( dataloader )
# training the discriminator and generator alternating
# for 100 steps in this example, batch size 1, gradient accumulated 8 times
gan (
steps = 100 ,
grad_accum_every = 8
)
# after much training
lowres = torch . randn ( 1 , 3 , 64 , 64 ). cuda ()
images = gan . generate ( lowres ) # (1, 3, 256, 256) G - GeradorMSG - Gerador MultiescalaD - DiscriminadorMSD - Discriminador MultiescalaGP - Penalidade GradienteSSL - Reconstrução Auxiliar no Discriminador (do Lightweight GAN)VD - Discriminador auxiliado pela visãoVG - Gerador auxiliado por visãoCL - Perda Constrastiva do GeradorMAL - Perda Consciente de Correspondência Uma execução saudável teria G , MSG , D , MSD com valores oscilando entre 0 a 10 e geralmente permanecendo bastante constantes. Se a qualquer momento após 1k etapas de treinamento esses valores persistirem em três dígitos, isso significaria que algo está errado. É normal que os valores do gerador e do discriminador ocasionalmente caiam para negativo, mas devem voltar para a faixa acima.
GP e SSL devem ser empurrados para 0 . GP pode ocasionalmente aumentar; Gosto de imaginar isso como as redes passando por alguma epifania
A classe GigaGAN agora está equipada com ? Acelerador. Você pode facilmente fazer treinamento multi-GPU em duas etapas usando seu CLI accelerate
No diretório raiz do projeto, onde está o script de treinamento, execute
$ accelerate configEntão, no mesmo diretório
$ accelerate launch train . py certifique-se de que ele pode ser treinado incondicionalmente
leia os documentos relevantes e elimine todas as 3 perdas auxiliares
upsampler unet
obtenha uma revisão de código para entradas e saídas em várias escalas, pois o artigo era um pouco vago
adicionar arquitetura de rede de upsampling
faça trabalho incondicional tanto para o gerador base quanto para o upsampler
fazer o treinamento condicionado por texto funcionar tanto para base quanto para upsampler
tornar o reconhecimento mais eficiente por meio de amostras aleatórias
certifique-se de que o gerador e o discriminador também possam aceitar codificações de texto CLIP pré-codificadas
faça uma revisão das perdas auxiliares
adicione alguns aumentos diferenciáveis, técnica comprovada dos velhos tempos do GAN
mova todas as projeções de modulação para a classe conv2d adaptativa
adicionar acelerar
o clipe deve ser opcional para todos os módulos e gerenciado por GigaGAN , com texto -> incorporações de texto processadas uma vez
adicionar capacidade de selecionar um subconjunto aleatório da dimensão multiescala, para eficiência
portar sobre CLI de Lightweight | stylegan2-pytorch
conectar conjunto de dados laion para imagem de texto
@misc { https://doi.org/10.48550/arxiv.2303.05511 ,
url = { https://arxiv.org/abs/2303.05511 } ,
author = { Kang, Minguk and Zhu, Jun-Yan and Zhang, Richard and Park, Jaesik and Shechtman, Eli and Paris, Sylvain and Park, Taesung } ,
title = { Scaling up GANs for Text-to-Image Synthesis } ,
publisher = { arXiv } ,
year = { 2023 } ,
copyright = { arXiv.org perpetual, non-exclusive license }
} @article { Liu2021TowardsFA ,
title = { Towards Faster and Stabilized GAN Training for High-fidelity Few-shot Image Synthesis } ,
author = { Bingchen Liu and Yizhe Zhu and Kunpeng Song and A. Elgammal } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2101.04775 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Karras2020ada ,
title = { Training Generative Adversarial Networks with Limited Data } ,
author = { Tero Karras and Miika Aittala and Janne Hellsten and Samuli Laine and Jaakko Lehtinen and Timo Aila } ,
booktitle = { Proc. NeurIPS } ,
year = { 2020 }
} @article { Xu2024VideoGigaGANTD ,
title = { VideoGigaGAN: Towards Detail-rich Video Super-Resolution } ,
author = { Yiran Xu and Taesung Park and Richard Zhang and Yang Zhou and Eli Shechtman and Feng Liu and Jia-Bin Huang and Difan Liu } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2404.12388 } ,
url = { https://api.semanticscholar.org/CorpusID:269214195 }
}

