byol pytorch
0.8.2
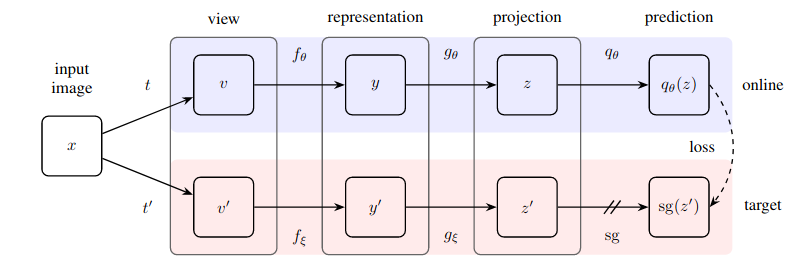
Implementação prática de um método surpreendentemente simples para aprendizagem auto-supervisionada que atinge um novo estado da arte (ultrapassando o SimCLR) sem aprendizagem contrastiva e sem a necessidade de designar pares negativos.
Este repositório oferece um módulo que pode facilmente envolver qualquer rede neural baseada em imagem (rede residual, discriminador, rede de política) para começar imediatamente a se beneficiar de dados de imagem não rotulados.
Atualização 1: agora há novas evidências de que a normalização em lote é fundamental para que essa técnica funcione bem
Atualização 2: Um novo artigo substituiu com sucesso a norma do lote pela norma do grupo + padronização de peso, refutando que as estatísticas do lote são necessárias para que o BYOL funcione
Atualização 3: finalmente, temos algumas análises sobre por que isso funciona
Excelente explicação de Yannic Kilcher
Agora salve sua organização de ter que pagar por etiquetas :)
$ pip install byol-pytorchBasta conectar sua rede neural, especificando (1) as dimensões da imagem, bem como (2) o nome (ou índice) da camada oculta, cuja saída é usada como representação latente usada para treinamento autossupervisionado.
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool'
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
learner . update_moving_average () # update moving average of target encoder
# save your improved network
torch . save ( resnet . state_dict (), './improved-net.pt' )É basicamente isso. Depois de muito treinamento, a rede residual deverá agora ter um desempenho melhor em suas tarefas supervisionadas posteriores.
Um novo artigo de Kaiming He sugere que o BYOL nem precisa que o codificador de destino seja uma média móvel exponencial do codificador online. Decidi incorporar esta opção para que você possa usar facilmente essa variante para treinamento, simplesmente definindo o sinalizador use_momentum como False . Você não precisará mais invocar update_moving_average se seguir esse caminho conforme mostrado no exemplo abaixo.
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
use_momentum = False # turn off momentum in the target encoder
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
# save your improved network
torch . save ( resnet . state_dict (), './improved-net.pt' )Embora os hiperparâmetros já tenham sido definidos de acordo com o que o artigo considerou ideal, você pode alterá-los com argumentos de palavras-chave extras para a classe base do wrapper.
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
projection_size = 256 , # the projection size
projection_hidden_size = 4096 , # the hidden dimension of the MLP for both the projection and prediction
moving_average_decay = 0.99 # the moving average decay factor for the target encoder, already set at what paper recommends
) Por padrão, esta biblioteca usará os acréscimos do documento SimCLR (que também é usado no documento BYOL). No entanto, se desejar especificar seu próprio pipeline de aumento, você pode simplesmente passar sua própria função de aumento personalizada com a palavra-chave augment_fn .
augment_fn = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip ()
)
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = - 2 ,
augment_fn = augment_fn
)No artigo, eles parecem garantir que um dos aumentos tem uma probabilidade de desfoque gaussiano maior que o outro. Você também pode ajustar isso para o deleite do seu coração.
augment_fn = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip ()
)
augment_fn2 = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip (),
kornia . filters . GaussianBlur2d (( 3 , 3 ), ( 1.5 , 1.5 ))
)
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = - 2 ,
augment_fn = augment_fn ,
augment_fn2 = augment_fn2 ,
) Para buscar os embeddings ou as projeções, basta passar um sinalizador return_embeddings = True para a instância do aluno BYOL
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool'
)
imgs = torch . randn ( 2 , 3 , 256 , 256 )
projection , embedding = learner ( imgs , return_embedding = True ) O repositório agora oferece treinamento distribuído com ? Abraçando o rosto Acelere. Você só precisa passar seu próprio Dataset para o BYOLTrainer importado
Primeiro defina a configuração para treinamento distribuído invocando a CLI acelerada
$ accelerate config Em seguida, crie seu script de treinamento conforme mostrado abaixo, digamos em ./train.py
from torchvision import models
from byol_pytorch import (
BYOL ,
BYOLTrainer ,
MockDataset
)
resnet = models . resnet50 ( pretrained = True )
dataset = MockDataset ( 256 , 10000 )
trainer = BYOLTrainer (
resnet ,
dataset = dataset ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
learning_rate = 3e-4 ,
num_train_steps = 100_000 ,
batch_size = 16 ,
checkpoint_every = 1000 # improved model will be saved periodically to ./checkpoints folder
)
trainer ()Em seguida, use a CLI de aceleração novamente para iniciar o script
$ accelerate launch ./train.pySe sua tarefa downstream envolve segmentação, consulte o repositório a seguir, que estende o BYOL para o aprendizado em nível de 'pixel'.
https://github.com/lucidrains/pixel-level-contrastive-learning
@misc { grill2020bootstrap ,
title = { Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning } ,
author = { Jean-Bastien Grill and Florian Strub and Florent Altché and Corentin Tallec and Pierre H. Richemond and Elena Buchatskaya and Carl Doersch and Bernardo Avila Pires and Zhaohan Daniel Guo and Mohammad Gheshlaghi Azar and Bilal Piot and Koray Kavukcuoglu and Rémi Munos and Michal Valko } ,
year = { 2020 } ,
eprint = { 2006.07733 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { chen2020exploring ,
title = { Exploring Simple Siamese Representation Learning } ,
author = { Xinlei Chen and Kaiming He } ,
year = { 2020 } ,
eprint = { 2011.10566 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

