atari
1.0.0

Research Playground construído sobre o Atari Gym da OpenAI, preparado para implementar vários algoritmos de Aprendizado por Reforço.
Ele pode emular qualquer um dos seguintes jogos:
['Asterix', 'Asteróides', 'MsPacman', 'Kaboom', 'BankHeist', 'Canguru', 'Esqui', 'FishingDerby', 'Krull', 'Berzerk', 'Tutankham', 'Zaxxon', ' Venture', 'Riverraid', 'Centipede', 'Aventura', 'BeamRider', 'CrazyClimber', 'TimePilot', 'Carnaval', 'Tênis', 'Seaquest', 'Bowling', 'SpaceInvaders', 'Freeway', 'YarsRevenge', 'RoadRunner', 'JourneyEscape', 'WizardOfWor', 'Gopher ', 'Breakout', 'StarGunner', 'Atlântida', 'DoubleDunk', 'Hero', 'BattleZone', 'Solaris', 'UpNDown', 'Frostbite', 'KungFuMaster', 'Pooyan', 'Pitfall', 'MontezumaRevenge', 'PrivateEye', 'AirRaid', 'Amidar ', 'Robotank', 'DemonAttack', 'Defender', 'NameThisGame', 'Phoenix', 'Gravitar', 'ElevatorAction', 'Pong', 'VideoPinball', 'IceHockey', 'Boxe', 'Assault', 'Alien', 'Qbert', 'Enduro', 'ChopperCommand', 'Jamesbond ']
Confira o artigo correspondente do Medium: Atari - Aprendizado por Reforço em profundidade? (Parte 1: DDQN)
O objetivo final deste projeto é implementar e comparar várias abordagens de RL com jogos de atari como denominador comum.
pip install -r requirements.txt .python atari.py --help . * GAMMA = 0.99
* MEMORY_SIZE = 900000
* BATCH_SIZE = 32
* TRAINING_FREQUENCY = 4
* TARGET_NETWORK_UPDATE_FREQUENCY = 40000
* MODEL_PERSISTENCE_UPDATE_FREQUENCY = 10000
* REPLAY_START_SIZE = 50000
* EXPLORATION_MAX = 1.0
* EXPLORATION_MIN = 0.1
* EXPLORATION_TEST = 0.02
* EXPLORATION_STEPS = 850000
Rede Neural Convolucional Profunda da DeepMind
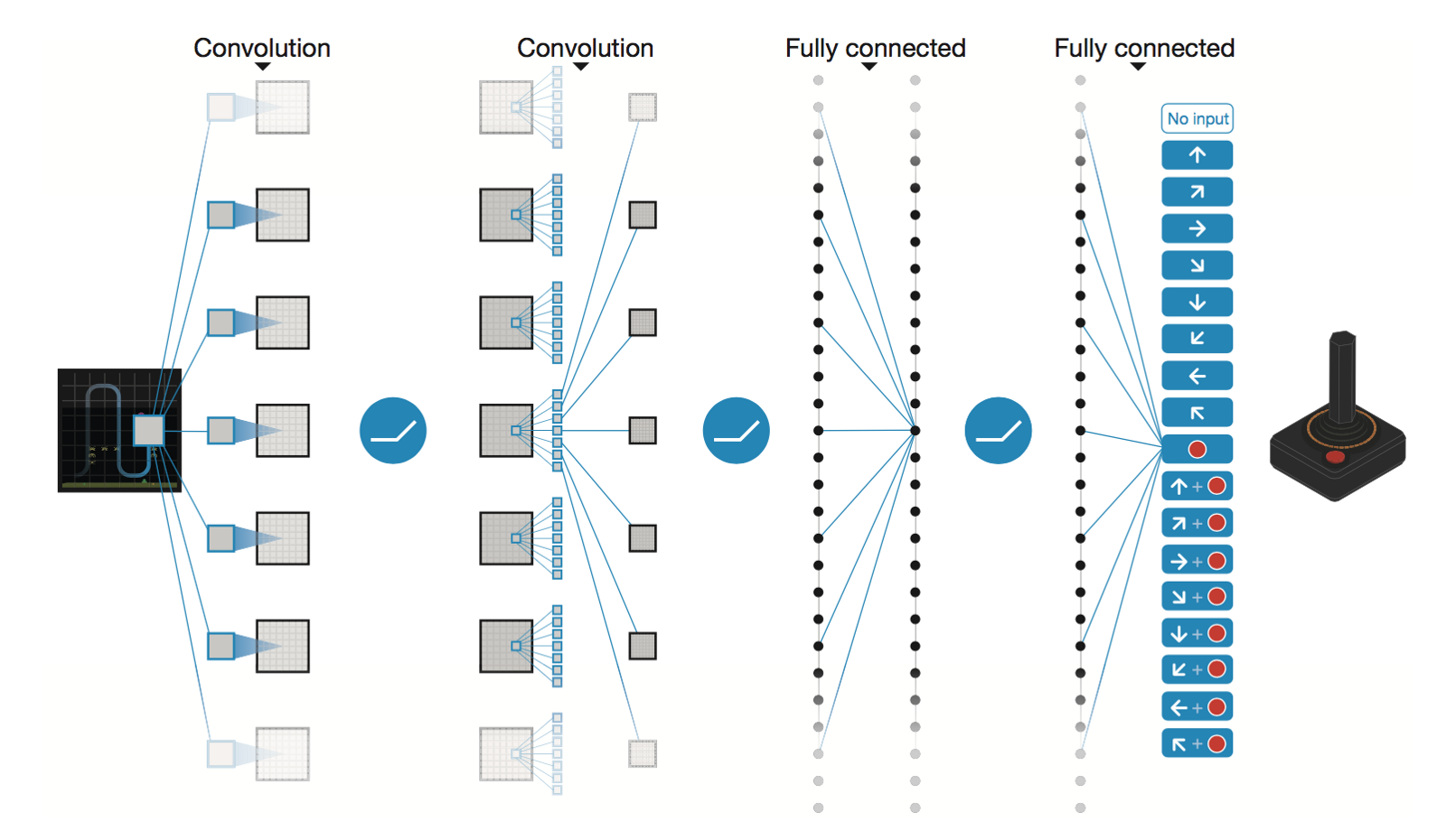
* Conv2D (None, 32, 20, 20)
* Conv2D (None, 64, 9, 9)
* Conv2D (None, 64, 7, 7)
* Flatten (None, 3136)
* Dense (None, 512)
* Dense (None, 4)
Trainable params: 1,686,180
Após 5M de etapas ( ~40h na GPU Tesla K80 ou ~90h na CPU Intel i7 Quad-Core de 2,9 GHz):
Treinamento:
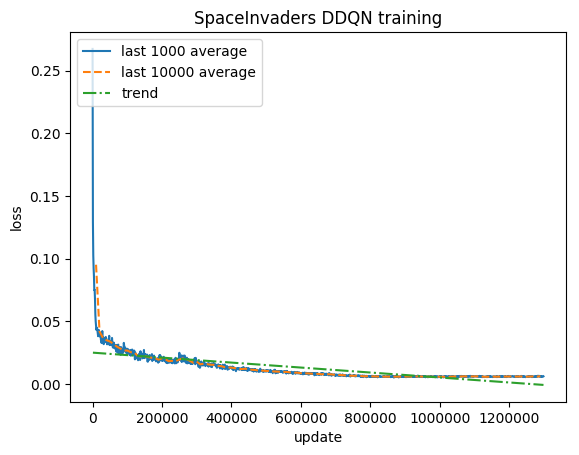
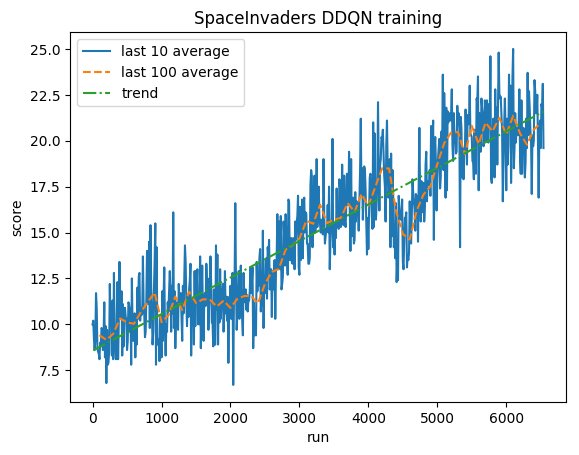
Pontuação normalizada - cada recompensa reduzida para (-1, 1)
Teste:
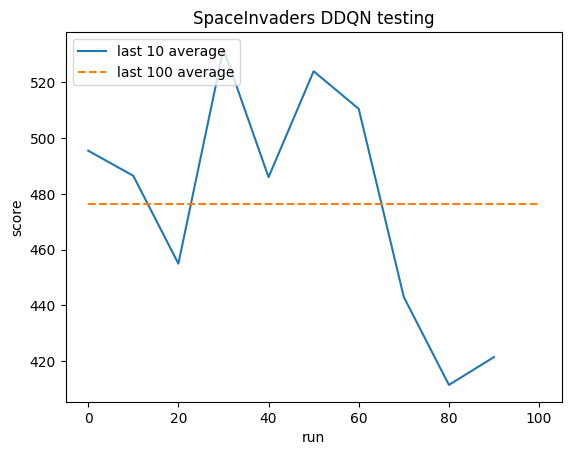
Média humana: ~372
Média DDQN: ~479 (128%)
Treinamento:
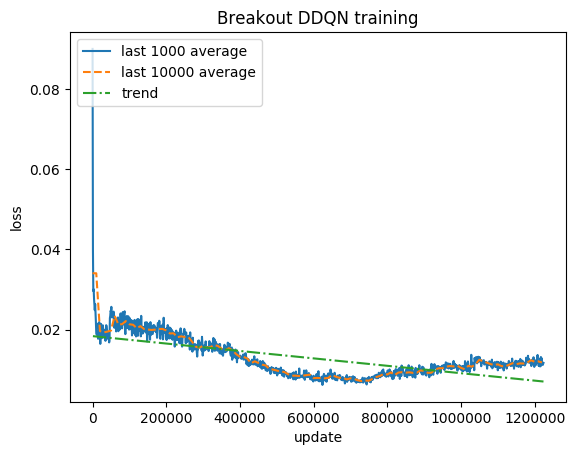
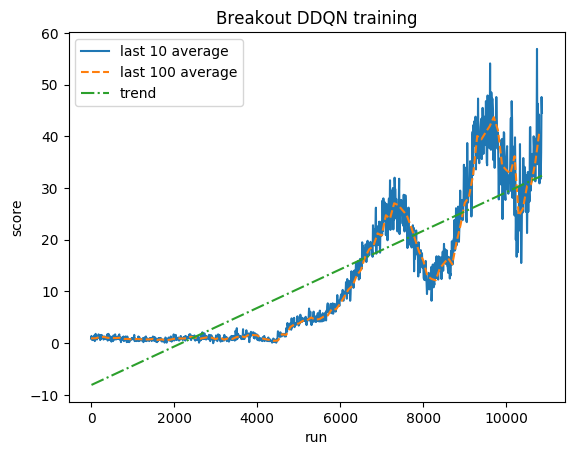
Pontuação normalizada - cada recompensa reduzida para (-1, 1)
Teste:
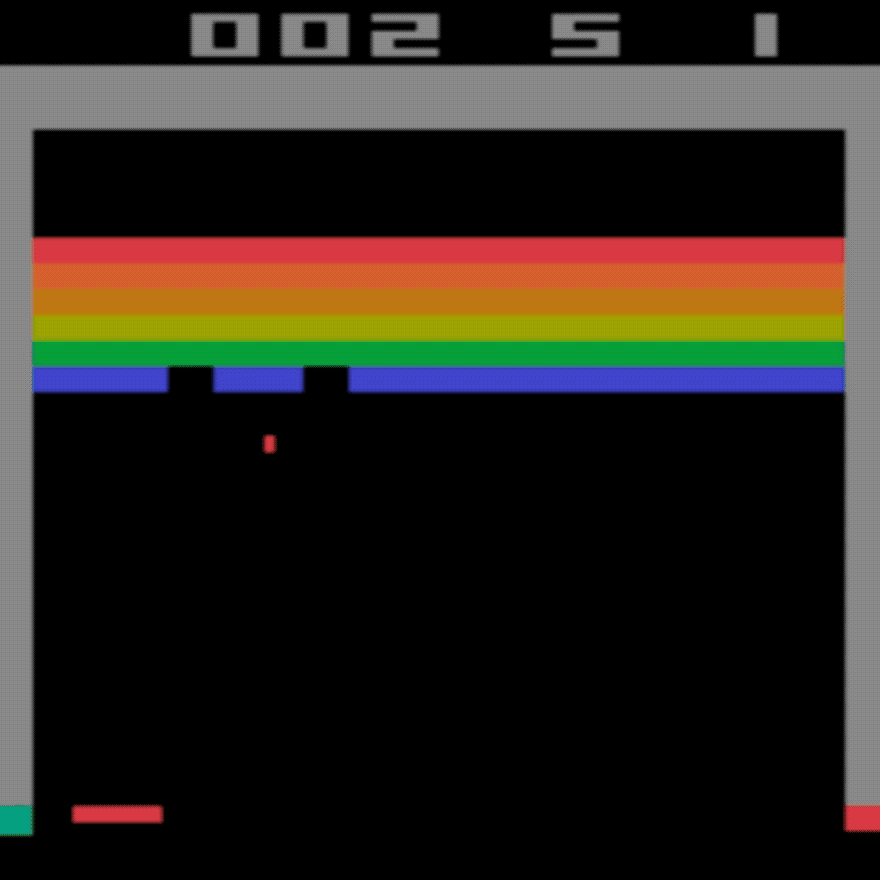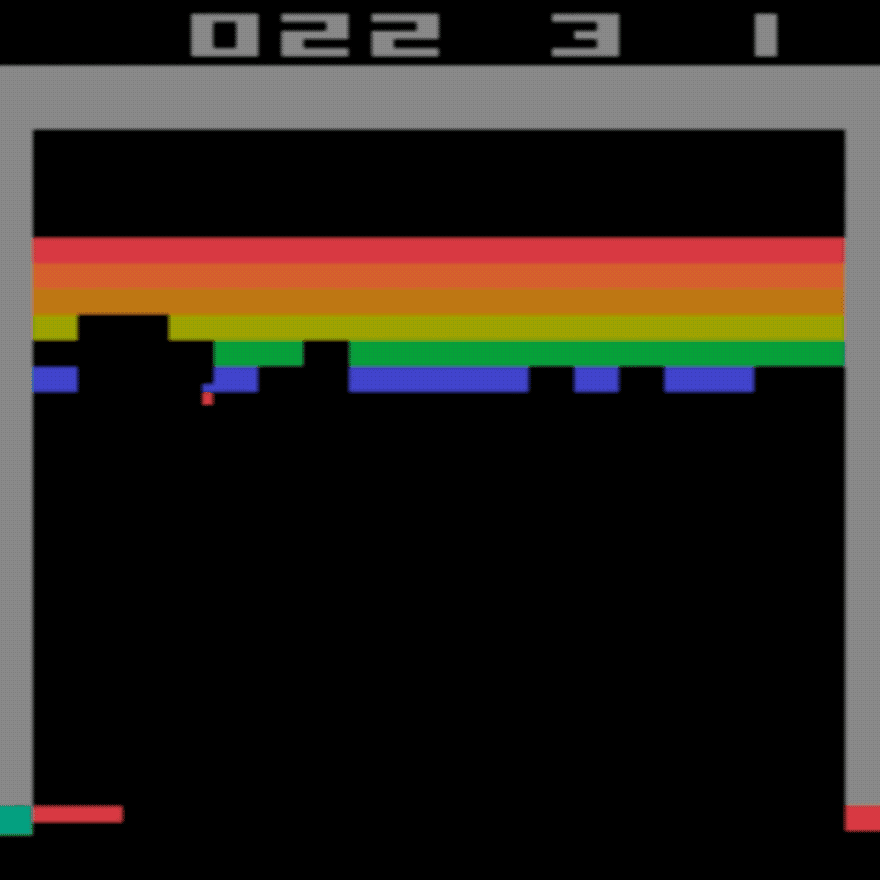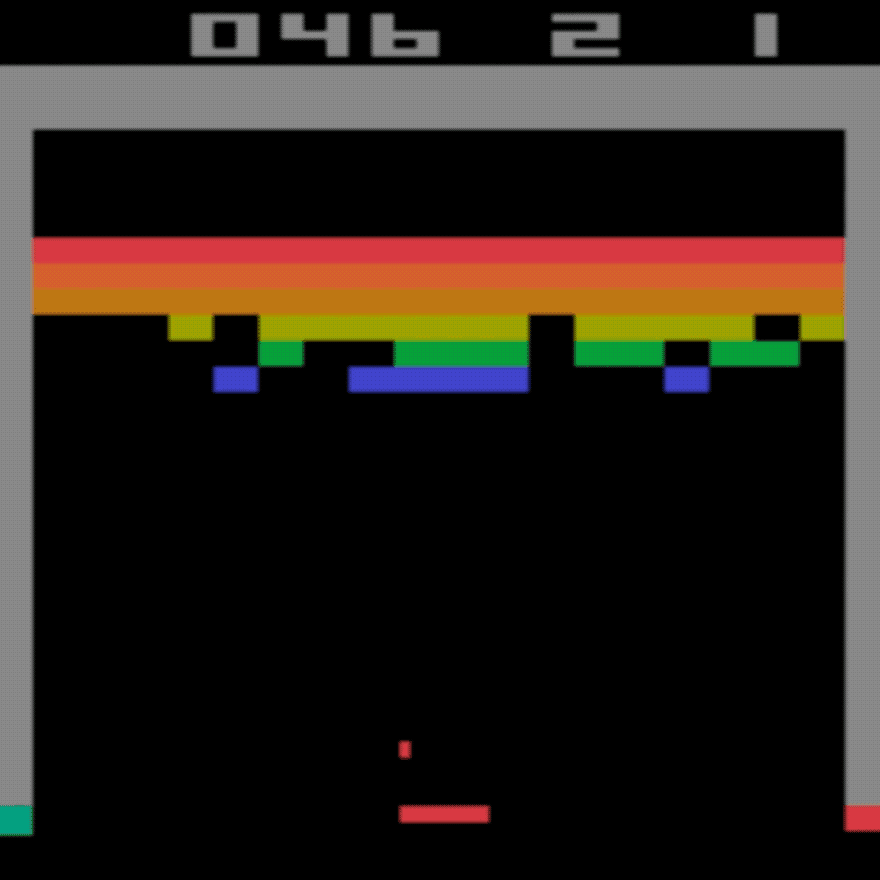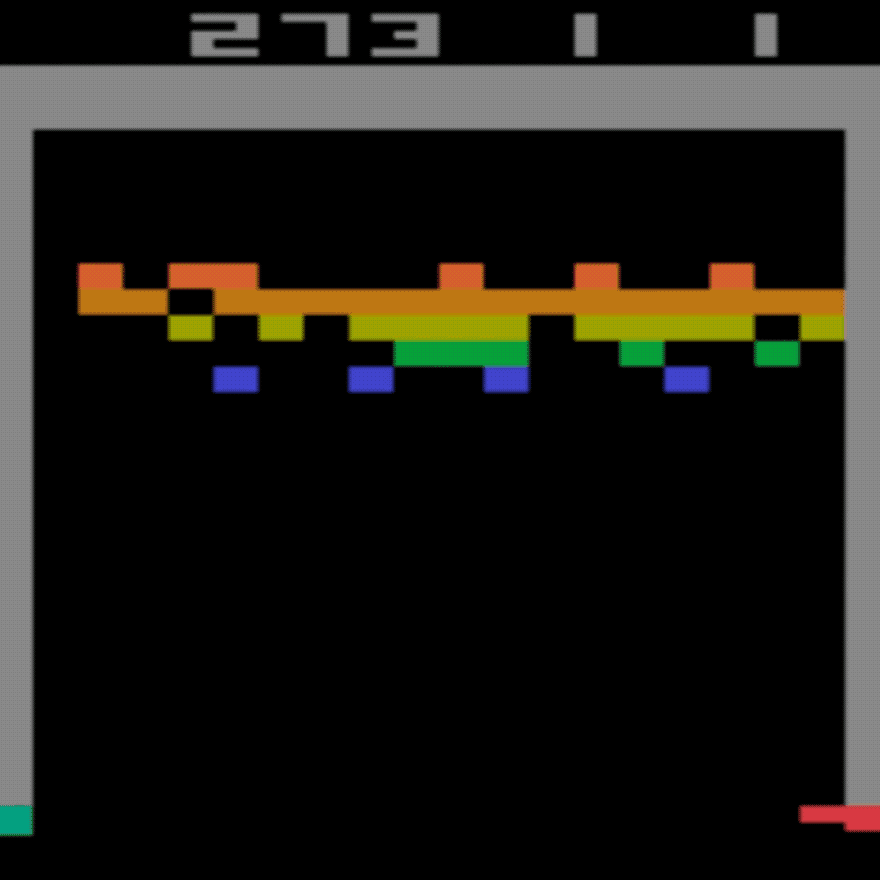
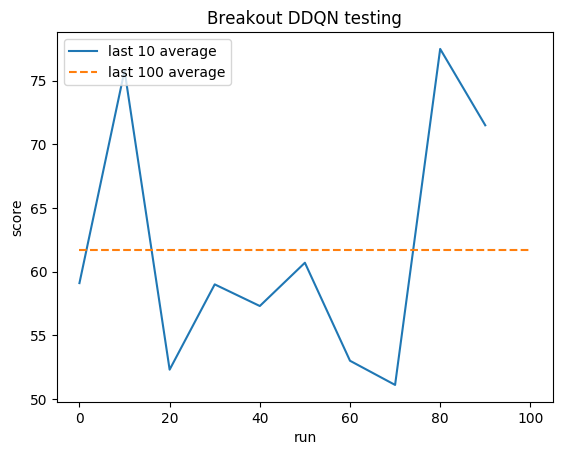
Média humana: ~28
Média DDQN: ~62 (221%)
Treinamento:
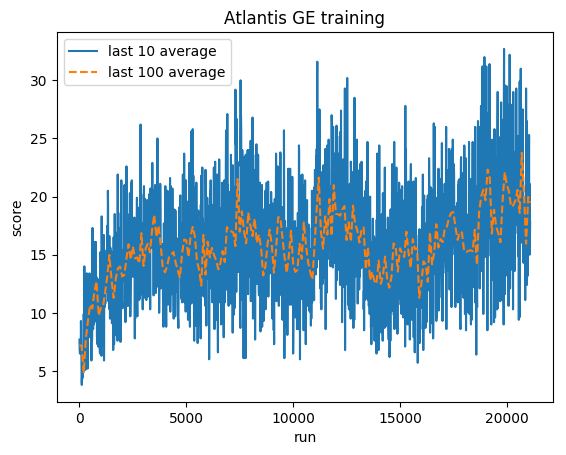
Pontuação normalizada - cada recompensa reduzida para (-1, 1)
Teste:

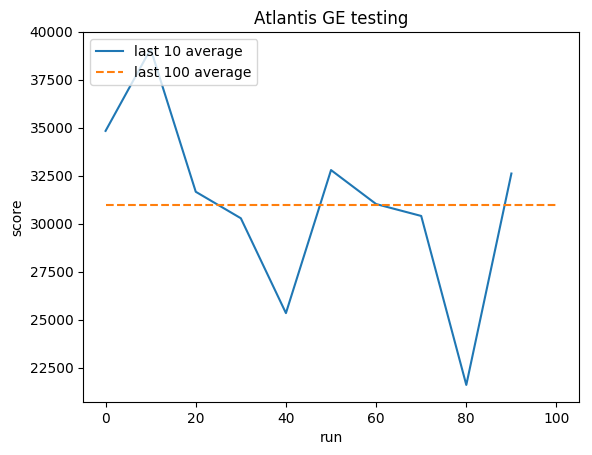
Média humana: ~29.000
Média GE: 31.000 (106%)
Greg (Grzegorz) Surma
PORTFÓLIO
github
BLOGUE


