LongNet
0.4.8

Esta é uma implementação de código aberto para o artigo LongNet: Scaling Transformers to 1.000.000.000 Tokens de Jiayu Ding, Shuming Ma, Li Dong, Xingxing Zhang, Shaohan Huang, Wenhui Wang, Furu Wei. O LongNet é uma variante do Transformer projetada para dimensionar o comprimento da sequência em até mais de 1 bilhão de tokens sem sacrificar o desempenho em sequências mais curtas.
pip install longnet Depois de instalar o LongNet, você pode usar a classe DilatedAttention da seguinte maneira:
import torch
from long_net import DilatedAttention
# model config
dim = 512
heads = 8
dilation_rate = 2
segment_size = 64
# input data
batch_size = 32
seq_len = 8192
# create model and data
model = DilatedAttention ( dim , heads , dilation_rate , segment_size , qk_norm = True )
x = torch . randn (( batch_size , seq_len , dim ))
output = model ( x )
print ( output )
LongNetTransformerUm modelo de transformador totalmente pronto para treinar com blocos transformadores dilatados com Feedforwards com layernorm, SWIGLU e um bloco transformador paralelo
import torch
from long_net . model import LongNetTransformer
longnet = LongNetTransformer (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8 ,
ff_mult = 4 ,
)
tokens = torch . randint ( 0 , 20000 , ( 1 , 512 ))
logits = longnet ( tokens )
print ( logits )
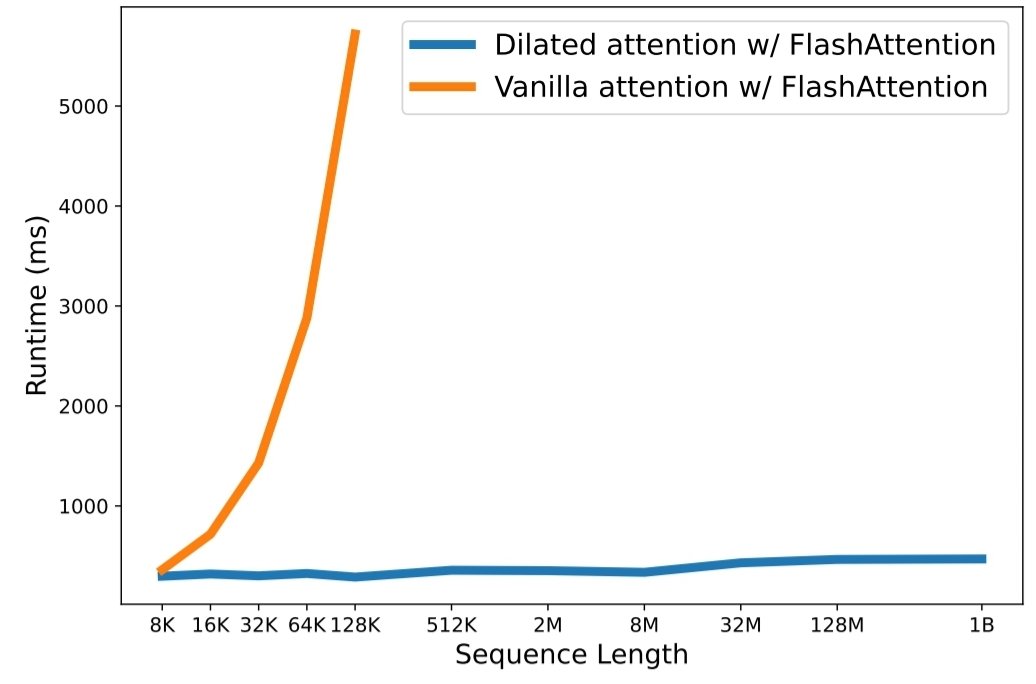
python3 train.py O dimensionamento do comprimento da sequência tornou-se um gargalo crítico na era dos grandes modelos de linguagem. No entanto, os métodos existentes lutam com a complexidade computacional ou com a expressividade do modelo, tornando o comprimento máximo da sequência restrito. Neste artigo, eles apresentam o LongNet, uma variante do Transformer que pode dimensionar o comprimento da sequência para mais de 1 bilhão de tokens, sem sacrificar o desempenho em sequências mais curtas. Especificamente, propõem atenção dilatada, que expande exponencialmente o campo atento à medida que a distância aumenta.
LongNet tem vantagens significativas:
Os resultados do experimento demonstram que o LongNet produz um forte desempenho tanto na modelagem de sequência longa quanto em tarefas gerais de linguagem. O seu trabalho abre novas possibilidades para modelar sequências muito longas, por exemplo, tratar um corpus inteiro ou mesmo toda a Internet como uma sequência.
@inproceedings { ding2023longnet ,
title = { LongNet: Scaling Transformers to 1,000,000,000 Tokens } ,
author = { Ding, Jiayu and Ma, Shuming and Dong, Li and Zhang, Xingxing and Huang, Shaohan and Wang, Wenhui and Wei, Furu } ,
booktitle = { Proceedings of the 10th International Conference on Learning Representations } ,
year = { 2023 }
}

