musiclm pytorch
0.2.8
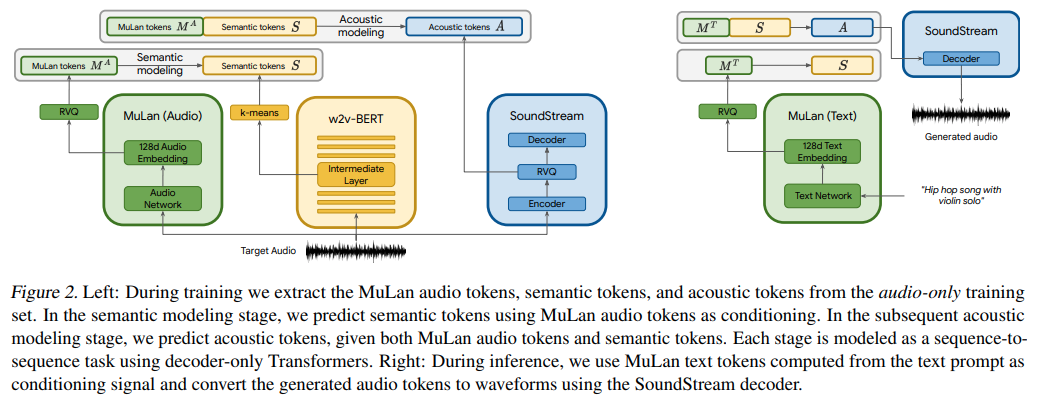
Implementação do MusicLM, o novo modelo SOTA do Google para geração de música usando redes de atenção, em Pytorch.
Eles estão basicamente usando AudioLM condicionado por texto, mas surpreendentemente com os embeddings de um modelo aprendido contrastivo de texto-áudio chamado MuLan. MuLan é o que será construído neste repositório, com AudioLM modificado do outro repositório para suportar as necessidades de geração de música aqui.
Por favor, junte-se se estiver interessado em ajudar na replicação com a comunidade LAION
O que é IA por Louis Bouchard
Stability.ai pelo generoso patrocínio ao trabalho e pesquisa de ponta em inteligência artificial de código aberto
? Huggingface por sua biblioteca de treinamento acelerado
$ pip install musiclm-pytorch
MuLaN primeiro precisa ser treinado
import torch
from musiclm_pytorch import MuLaN , AudioSpectrogramTransformer , TextTransformer
audio_transformer = AudioSpectrogramTransformer (
dim = 512 ,
depth = 6 ,
heads = 8 ,
dim_head = 64 ,
spec_n_fft = 128 ,
spec_win_length = 24 ,
spec_aug_stretch_factor = 0.8
)
text_transformer = TextTransformer (
dim = 512 ,
depth = 6 ,
heads = 8 ,
dim_head = 64
)
mulan = MuLaN (
audio_transformer = audio_transformer ,
text_transformer = text_transformer
)
# get a ton of <sound, text> pairs and train
wavs = torch . randn ( 2 , 1024 )
texts = torch . randint ( 0 , 20000 , ( 2 , 256 ))
loss = mulan ( wavs , texts )
loss . backward ()
# after much training, you can embed sounds and text into a joint embedding space
# for conditioning the audio LM
embeds = mulan . get_audio_latents ( wavs ) # during training
embeds = mulan . get_text_latents ( texts ) # during inference Para obter os embeddings de condicionamento para os três transformadores que fazem parte do AudioLM , você deve usar o MuLaNEmbedQuantizer assim
from musiclm_pytorch import MuLaNEmbedQuantizer
# setup the quantizer with the namespaced conditioning embeddings, unique per quantizer as well as namespace (per transformer)
quantizer = MuLaNEmbedQuantizer (
mulan = mulan , # pass in trained mulan from above
conditioning_dims = ( 1024 , 1024 , 1024 ), # say all three transformers have model dimensions of 1024
namespaces = ( 'semantic' , 'coarse' , 'fine' )
)
# now say you want the conditioning embeddings for semantic transformer
wavs = torch . randn ( 2 , 1024 )
conds = quantizer ( wavs = wavs , namespace = 'semantic' ) # (2, 8, 1024) - 8 is number of quantizers Para treinar (ou ajustar) os três transformadores que fazem parte do AudioLM , basta seguir as instruções em audiolm-pytorch para treinamento, mas passar a instância MulanEmbedQuantizer para as classes de treinamento sob a palavra-chave audio_conditioner
ex. SemanticTransformerTrainer
import torch
from audiolm_pytorch import HubertWithKmeans , SemanticTransformer , SemanticTransformerTrainer
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
semantic_transformer = SemanticTransformer (
num_semantic_tokens = wav2vec . codebook_size ,
dim = 1024 ,
depth = 6 ,
audio_text_condition = True # this must be set to True (same for CoarseTransformer and FineTransformers)
). cuda ()
trainer = SemanticTransformerTrainer (
transformer = semantic_transformer ,
wav2vec = wav2vec ,
audio_conditioner = quantizer , # pass in the MulanEmbedQuantizer instance above
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1
)
trainer . train () Depois de muito treinamento em todos os três transformadores (semântico, grosso, fino), você passará seu AudioLM e MuLaN ajustados ou treinados do zero embrulhados em MuLaNEmbedQuantizer para o MusicLM
# you need the trained AudioLM (audio_lm) from above
# with the MulanEmbedQuantizer (mulan_embed_quantizer)
from musiclm_pytorch import MusicLM
musiclm = MusicLM (
audio_lm = audio_lm , # `AudioLM` from https://github.com/lucidrains/audiolm-pytorch
mulan_embed_quantizer = quantizer # the `MuLaNEmbedQuantizer` from above
)
music = musiclm ( 'the crystalline sounds of the piano in a ballroom' , num_samples = 4 ) # sample 4 and pick the top match with mulan mulan parece estar usando aprendizagem contrastiva dissociada, ofereça isso como uma opção
envolva mulan com mulan wrapper e quantize a saída, projete nas dimensões do audiolm
modifique o audiolm para aceitar incorporações de condicionamento, opcionalmente cuide de diferentes dimensões através de uma projeção separada
audiolm e mulan vão para musiclm e geram, filtram com mulan
dar viés posicional dinâmico à autoatenção em AST
implementar MusicLM gerando múltiplas amostras e selecionando a melhor correspondência com MuLaN
suporta áudio de duração variável com mascaramento no transformador de áudio
adicione uma versão de mulan para abrir o clipe
definir todos os hiperparâmetros adequados do espectrograma
@inproceedings { Agostinelli2023MusicLMGM ,
title = { MusicLM: Generating Music From Text } ,
author = { Andrea Agostinelli and Timo I. Denk and Zal{'a}n Borsos and Jesse Engel and Mauro Verzetti and Antoine Caillon and Qingqing Huang and Aren Jansen and Adam Roberts and Marco Tagliasacchi and Matthew Sharifi and Neil Zeghidour and C. Frank } ,
year = { 2023 }
} @article { Huang2022MuLanAJ ,
title = { MuLan: A Joint Embedding of Music Audio and Natural Language } ,
author = { Qingqing Huang and Aren Jansen and Joonseok Lee and Ravi Ganti and Judith Yue Li and Daniel P. W. Ellis } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2208.12415 }
} @misc { https://doi.org/10.48550/arxiv.2302.01327 ,
doi = { 10.48550/ARXIV.2302.01327 } ,
url = { https://arxiv.org/abs/2302.01327 } ,
author = { Kumar, Manoj and Dehghani, Mostafa and Houlsby, Neil } ,
title = { Dual PatchNorm } ,
publisher = { arXiv } ,
year = { 2023 } ,
copyright = { Creative Commons Attribution 4.0 International }
} @article { Liu2022PatchDropoutEV ,
title = { PatchDropout: Economizing Vision Transformers Using Patch Dropout } ,
author = { Yue Liu and Christos Matsoukas and Fredrik Strand and Hossein Azizpour and Kevin Smith } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2208.07220 }
} @misc { liu2021swin ,
title = { Swin Transformer V2: Scaling Up Capacity and Resolution } ,
author = { Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo } ,
year = { 2021 } ,
eprint = { 2111.09883 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @inproceedings { Shukor2022EfficientVP ,
title = { Efficient Vision-Language Pretraining with Visual Concepts and Hierarchical Alignment } ,
author = { Mustafa Shukor and Guillaume Couairon and Matthieu Cord } ,
booktitle = { British Machine Vision Conference } ,
year = { 2022 }
} @inproceedings { Zhai2023SigmoidLF ,
title = { Sigmoid Loss for Language Image Pre-Training } ,
author = { Xiaohua Zhai and Basil Mustafa and Alexander Kolesnikov and Lucas Beyer } ,
year = { 2023 }
}A única verdade é a música. -Jack Kerouac
A música é a linguagem universal da humanidade. -Henry Wadsworth Longfellow


