antialiased cnns
v0.3
Tornando as redes convolucionais invariantes novamente
Ricardo Zhang. No ICML, 2019.
Execute pip install antialiased-cnns
import antialiased_cnns
model = antialiased_cnns . resnet50 ( pretrained = True ) Se você já possui um modelo e deseja suavizar e continuar treinando, copie seus pesos antigos:
import torchvision . models as models
old_model = models . resnet50 ( pretrained = True ) # old (aliased) model
antialiased_cnns . copy_params_buffers ( old_model , model ) # copy the weights overSe você quiser modificar seu próprio modelo, use a camada BlurPool. Mais informações sobre nossos modelos fornecidos e como usar o BlurPool estão abaixo.
C = 10 # example feature channel size
blurpool = antialiased_cnns . BlurPool ( C , stride = 2 ) # BlurPool layer; use to downsample a feature map
ex_tens = torch . Tensor ( 1 , C , 128 , 128 )
print ( blurpool ( ex_tens ). shape ) # 1xCx64x64 tensorAtualizações
pip install antialiased-cnns e carregar modelos com o sinalizador pretrained=True .BlurPoolPip instale este pacote
pip install antialiased-cnnsOu clone este repositório e instale os requisitos (principalmente PyTorch)
https://github.com/adobe/antialiased-cnns.git
cd antialiased-cnns
pip install -r requirements.txtO seguinte carrega um modelo suavizado pré-treinado, talvez como uma espinha dorsal para seu aplicativo.
import antialiased_cnns
model = antialiased_cnns . resnet50 ( pretrained = True , filter_size = 4 ) Também fornecemos pesos para AlexNet , VGG16(bn) , Resnet18,34,50,101 , Densenet121 e MobileNetv2 (consulte example_usage.py).
O módulo antialiased_cnns contém a classe BlurPool , que faz desfoque+subamostragem. Execute pip install antialiased-cnns ou copie o subdiretório antialiased_cnns .
Metodologia A metodologia é simples – primeiro avalie com passo 1 e depois use nossa camada BlurPool para fazer downsampling suavizado. Faça as seguintes alterações arquitetônicas.
import antialiased_cnns
# MaxPool --> MaxBlurPool
baseline = nn . MaxPool2d ( kernel_size = 2 , stride = 2 )
antialiased = [ nn . MaxPool2d ( kernel_size = 2 , stride = 1 ),
antialiased_cnns . BlurPool ( C , stride = 2 )]
# Conv --> ConvBlurPool
baseline = [ nn . Conv2d ( Cin , C , kernel_size = 3 , stride = 2 , padding = 1 ),
nn . ReLU ( inplace = True )]
antialiased = [ nn . Conv2d ( Cin , C , kernel_size = 3 , stride = 1 , padding = 1 ),
nn . ReLU ( inplace = True ),
antialiased_cnns . BlurPool ( C , stride = 2 )]
# AvgPool --> BlurPool
baseline = nn . AvgPool2d ( kernel_size = 2 , stride = 2 )
antialiased = antialiased_cnns . BlurPool ( C , stride = 2 ) Assumimos que o tensor de entrada possui canais C Calcular uma camada na passada 1 em vez da passada 2 adiciona memória e tempo de execução. Como tal, normalmente ignoramos o antialiasing na resolução mais alta (no início da rede), para evitar grandes aumentos.
Adicione antialiasing e continue o treinamento Se você já treinou um modelo e depois adicionou antialiasing, poderá fazer ajustes finos a partir desse modelo antigo:
antialiased_cnns . copy_params_buffers ( old_model , antialiased_model )Se isso não funcionar, basta copiar os parâmetros (e não os buffers). Adicionar antialiasing não adiciona nenhum parâmetro, portanto as listas de parâmetros são idênticas. (Ele adiciona buffers, portanto, alguma heurística é usada para corresponder aos buffers, o que pode gerar um erro.)
antialiased_cnns . copy_params ( old_model , antialiased_model )Observamos melhorias na precisão (com que frequência a imagem é classificada corretamente) e na consistência (com que frequência duas mudanças da mesma imagem são classificadas da mesma forma).
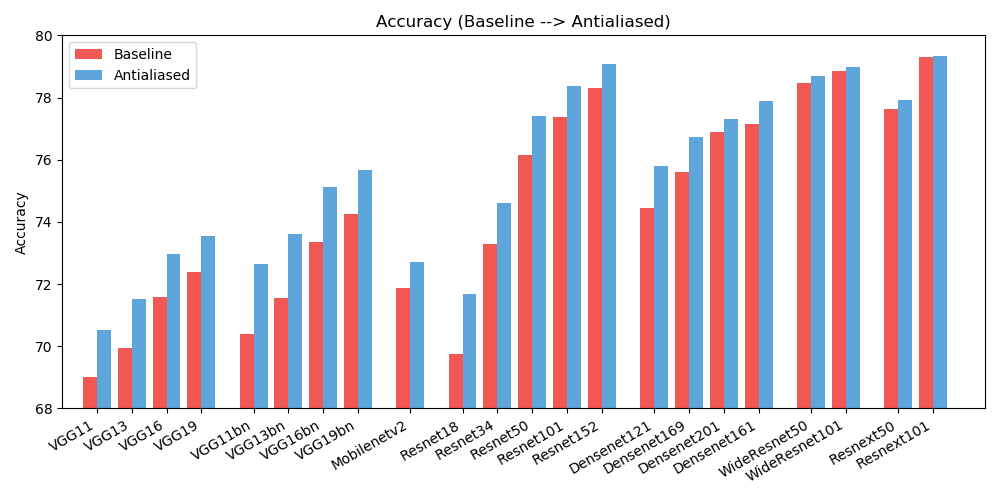
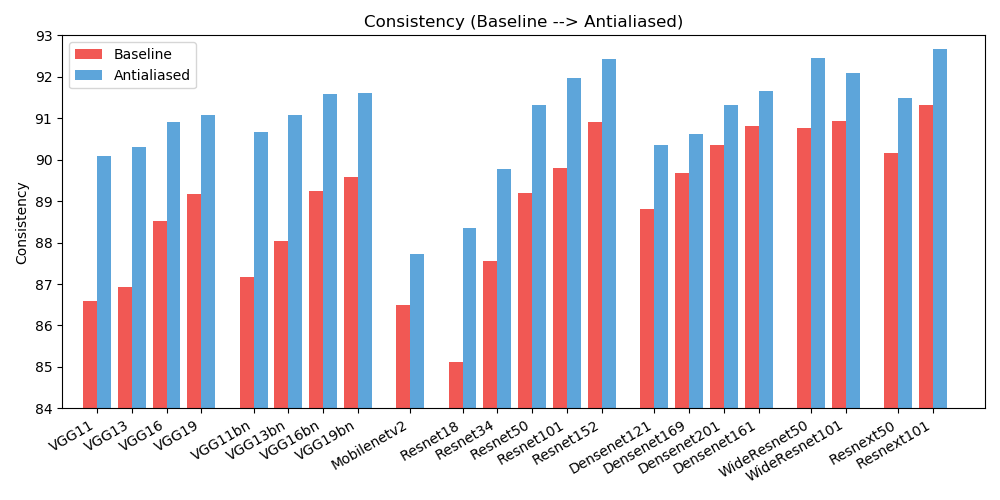
| PRECISÃO | Linha de base | Suavizado | Delta |
|---|---|---|---|
| Alex Neto | 56,55 | 56,94 | +0,39 |
| vgg11 | 69.02 | 70,51 | +1,49 |
| vgg13 | 69,93 | 71,52 | +1,59 |
| vgg16 | 71,59 | 72,96 | +1,37 |
| vgg19 | 72,38 | 73,54 | +1,16 |
| vgg11_bn | 70,38 | 72,63 | +2,25 |
| vgg13_bn | 71,55 | 73,61 | +2,06 |
| vgg16_bn | 73,36 | 75,13 | +1,77 |
| vgg19_bn | 74,24 | 75,68 | +1,44 |
| resnet18 | 69,74 | 71,67 | +1,93 |
| resnet34 | 73h30 | 74,60 | +1,30 |
| resnet50 | 76,16 | 77,41 | +1,25 |
| resnet101 | 77,37 | 78,38 | +1,01 |
| resnet152 | 78,31 | 79.07 | +0,76 |
| respróximo50_32x4d | 77,62 | 77,93 | +0,31 |
| resnext101_32x8d | 79,31 | 79,33 | +0,02 |
| wide_resnet50_2 | 78,47 | 78,70 | +0,23 |
| wide_resnet101_2 | 78,85 | 78,99 | +0,14 |
| densanet121 | 74,43 | 75,79 | +1,36 |
| densanet169 | 75,60 | 76,73 | +1,13 |
| Densenet201 | 76,90 | 77,31 | +0,41 |
| densanet161 | 77,14 | 77,88 | +0,74 |
| rede móvel_v2 | 71,88 | 72,72 | +0,84 |
| CONSISTÊNCIA | Linha de base | Suavizado | Delta |
|---|---|---|---|
| Alex Neto | 78,18 | 83,31 | +5,13 |
| vgg11 | 86,58 | 90.09 | +3,51 |
| vgg13 | 86,92 | 90,31 | +3,39 |
| vgg16 | 88,52 | 90,91 | +2,39 |
| vgg19 | 89,17 | 91.08 | +1,91 |
| vgg11_bn | 87,16 | 90,67 | +3,51 |
| vgg13_bn | 88.03 | 91.09 | +3,06 |
| vgg16_bn | 89,24 | 91,58 | +2,34 |
| vgg19_bn | 89,59 | 91,60 | +2,01 |
| resnet18 | 85.11 | 88,36 | +3,25 |
| resnet34 | 87,56 | 89,77 | +2,21 |
| resnet50 | 89,20 | 91,32 | +2,12 |
| resnet101 | 89,81 | 91,97 | +2,16 |
| resnet152 | 90,92 | 92,42 | +1,50 |
| respróximo50_32x4d | 90,17 | 91,48 | +1,31 |
| resnext101_32x8d | 91,33 | 92,67 | +1,34 |
| wide_resnet50_2 | 90,77 | 92,46 | +1,69 |
| wide_resnet101_2 | 90,93 | 92,10 | +1,17 |
| densanet121 | 88,81 | 90,35 | +1,54 |
| densanet169 | 89,68 | 90,61 | +0,93 |
| Densenet201 | 90,36 | 91,32 | +0,96 |
| densanet161 | 90,82 | 91,66 | +0,84 |
| rede móvel_v2 | 86,50 | 87,73 | +1,23 |
Para reduzir a confusão, resultados estendidos (diferentes tamanhos de filtro) estão aqui. Ajude a melhorar os resultados!
Este trabalho está licenciado sob uma Licença Creative Commons Atribuição-NãoComercial-Compartilhamento pela mesma Licença 4.0 Internacional.
Todo o material é disponibilizado sob a licença Creative Commons BY-NC-SA 4.0 da Adobe Inc. Você pode usar, redistribuir e adaptar o material para fins não comerciais , desde que dê o crédito apropriado, citando nosso artigo e indicando quaisquer alterações que você fez.
O repositório baseia-se no repositório de exemplos PyTorch e no repositório de modelos torchvision. Estes são licenciados no estilo BSD.
Se você achar isso útil para sua pesquisa, considere citar este bibtex. Entre em contato com Richard Zhang <rizhang at adobe dot com> com quaisquer comentários ou feedback.


