igel
v1.0.0
Uma excelente ferramenta de aprendizado de máquina que permite treinar/ajustar, testar e usar modelos sem escrever código
Observação
Também estou trabalhando em um aplicativo de desktop GUI para igel com base nas solicitações das pessoas. Você pode encontrá-lo em Igel-UI.
Índice
O objetivo do projeto é fornecer aprendizado de máquina para todos , usuários técnicos e não técnicos.
Às vezes, eu precisava de uma ferramenta que pudesse usar para criar rapidamente um protótipo de aprendizado de máquina. Seja para construir alguma prova de conceito, criar um modelo de rascunho rápido para provar um ponto ou usar ML automático. Muitas vezes fico preso em escrever código padrão e pensando muito por onde começar. Portanto, decidi criar esta ferramenta.
igel é construído sobre outras estruturas de ML. Ele fornece uma maneira simples de usar o aprendizado de máquina sem escrever uma única linha de código . Igel é altamente personalizável , mas apenas se você quiser. Igel não obriga você a personalizar nada. Além dos valores padrão, o igel pode usar recursos de auto-ml para descobrir um modelo que funcione bem com seus dados.
Tudo que você precisa é de um arquivo yaml (ou json ), onde você precisa descrever o que está tentando fazer. É isso!
Igel suporta regressão, classificação e agrupamento. Igel suporta recursos de auto-ml como ImageClassification e TextClassification
Igel suporta os tipos de conjuntos de dados mais usados no campo da ciência de dados. Por exemplo, seu conjunto de dados de entrada pode ser um arquivo csv, txt, planilha Excel, json ou até mesmo html que você deseja buscar. Se você estiver usando recursos de auto-ml, poderá até mesmo alimentar o igel com dados brutos e ele descobrirá como lidar com isso. Mais sobre isso posteriormente nos exemplos.
$ pip install -U igel Modelos suportados pela Igel:
+--------------------+----------------------------+-------------------------+
| regression | classification | clustering |
+--------------------+----------------------------+-------------------------+
| LinearRegression | LogisticRegression | KMeans |
| Lasso | Ridge | AffinityPropagation |
| LassoLars | DecisionTree | Birch |
| BayesianRegression | ExtraTree | AgglomerativeClustering |
| HuberRegression | RandomForest | FeatureAgglomeration |
| Ridge | ExtraTrees | DBSCAN |
| PoissonRegression | SVM | MiniBatchKMeans |
| ARDRegression | LinearSVM | SpectralBiclustering |
| TweedieRegression | NuSVM | SpectralCoclustering |
| TheilSenRegression | NearestNeighbor | SpectralClustering |
| GammaRegression | NeuralNetwork | MeanShift |
| RANSACRegression | PassiveAgressiveClassifier | OPTICS |
| DecisionTree | Perceptron | KMedoids |
| ExtraTree | BernoulliRBM | ---- |
| RandomForest | BoltzmannMachine | ---- |
| ExtraTrees | CalibratedClassifier | ---- |
| SVM | Adaboost | ---- |
| LinearSVM | Bagging | ---- |
| NuSVM | GradientBoosting | ---- |
| NearestNeighbor | BernoulliNaiveBayes | ---- |
| NeuralNetwork | CategoricalNaiveBayes | ---- |
| ElasticNet | ComplementNaiveBayes | ---- |
| BernoulliRBM | GaussianNaiveBayes | ---- |
| BoltzmannMachine | MultinomialNaiveBayes | ---- |
| Adaboost | ---- | ---- |
| Bagging | ---- | ---- |
| GradientBoosting | ---- | ---- |
+--------------------+----------------------------+-------------------------+Para ML automático:
O comando help é muito útil para verificar comandos suportados e argumentos/opções correspondentes
$ igel --helpVocê também pode executar ajuda em subcomandos, por exemplo:
$ igel fit --helpIgel é altamente personalizável. Se você sabe o que quer e deseja configurar seu modelo manualmente, verifique as próximas seções, que irão orientá-lo sobre como escrever um arquivo de configuração yaml ou json. Depois disso, basta dizer ao igel o que fazer e onde encontrar seus dados e arquivo de configuração. Aqui está um exemplo:
$ igel fit --data_path ' path_to_your_csv_dataset.csv ' --yaml_path ' path_to_your_yaml_file.yaml 'No entanto, você também pode usar os recursos de auto-ml e deixar que o igel faça tudo por você. Um ótimo exemplo disso seria a classificação de imagens. Vamos imaginar que você já possui um conjunto de dados de imagens brutas armazenadas em uma pasta chamada imagens
Tudo que você precisa fazer é executar:
$ igel auto-train --data_path ' path_to_your_images_folder ' --task ImageClassificationÉ isso! Igel irá ler as imagens do diretório, processar o conjunto de dados (convertendo para matrizes, redimensionar, dividir, etc...) e começar a treinar/otimizar um modelo que funcione bem com seus dados. Como você pode ver é muito fácil, basta fornecer o caminho para seus dados e a tarefa que deseja realizar.
Observação
Este recurso é computacionalmente caro, pois o igel tentaria muitos modelos diferentes e compararia seu desempenho para encontrar o “melhor”.
Você pode executar o comando de ajuda para obter instruções. Você também pode executar ajuda em subcomandos!
$ igel --helpO primeiro passo é fornecer um arquivo yaml (você também pode usar json se quiser)
Você pode fazer isso manualmente criando um arquivo .yaml (chamado igel.yaml por convenção, mas você pode nomeá-lo se quiser) e editando-o você mesmo. No entanto, se você for preguiçoso (e provavelmente é, como eu :D), você pode usar o comando igel init para começar rapidamente, o que criará um arquivo de configuração básico para você instantaneamente.
"""
igel init --help
Example:
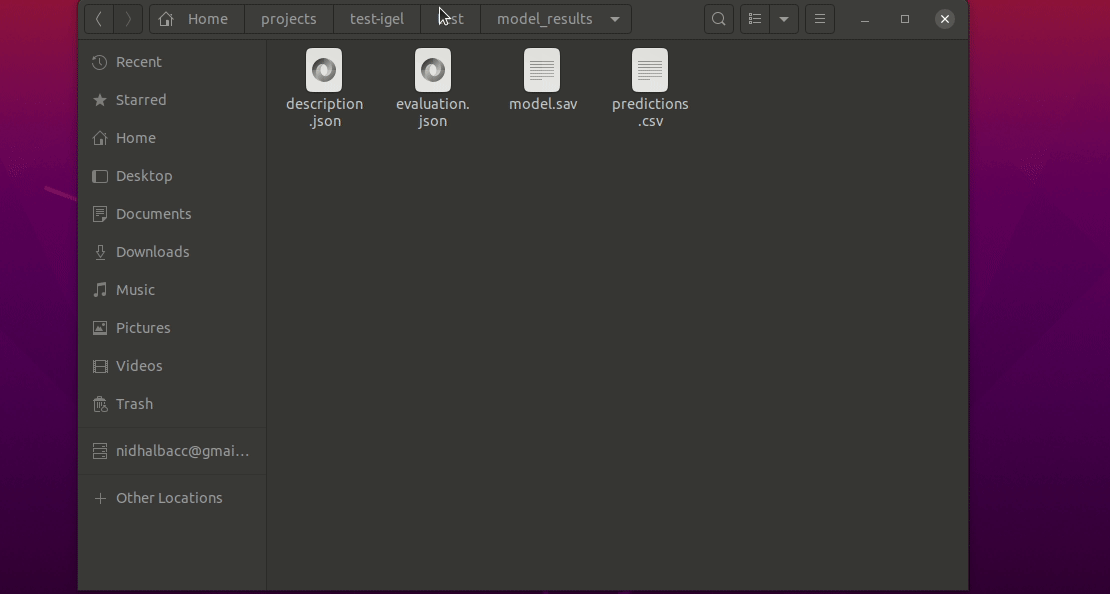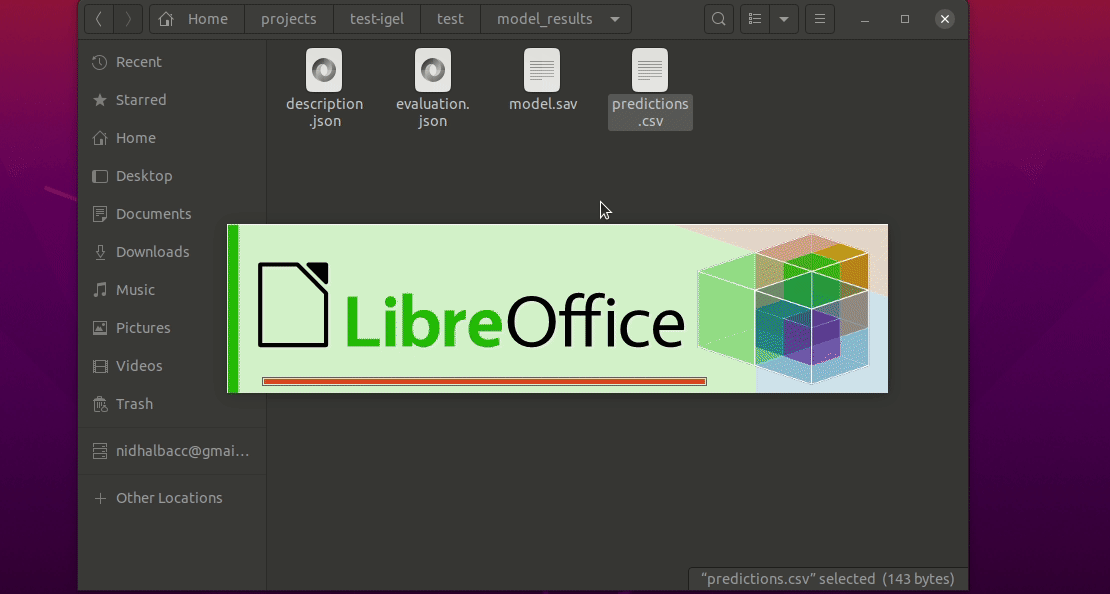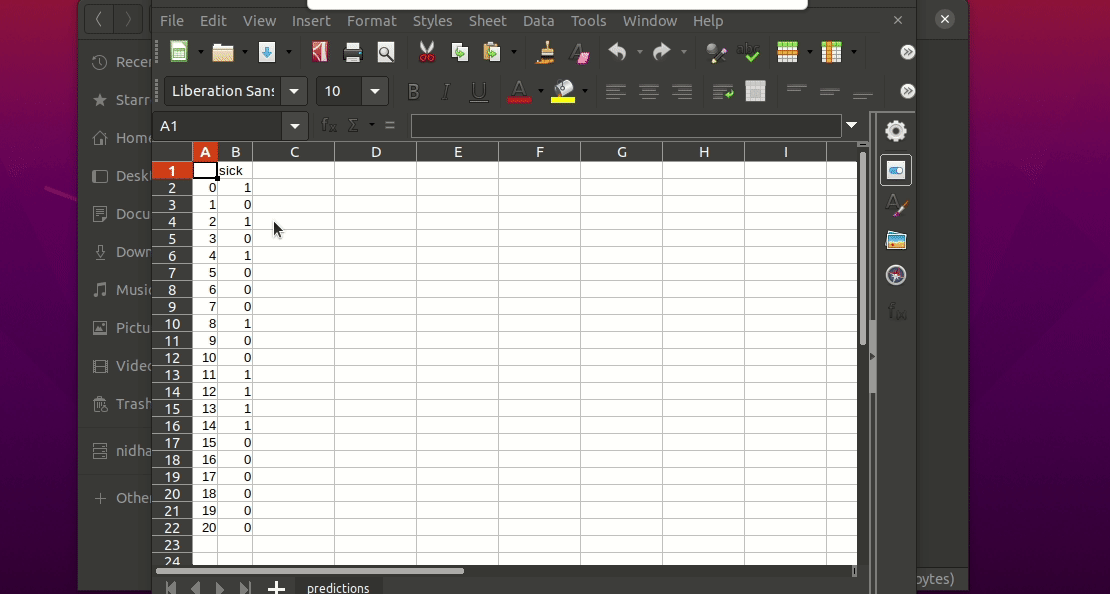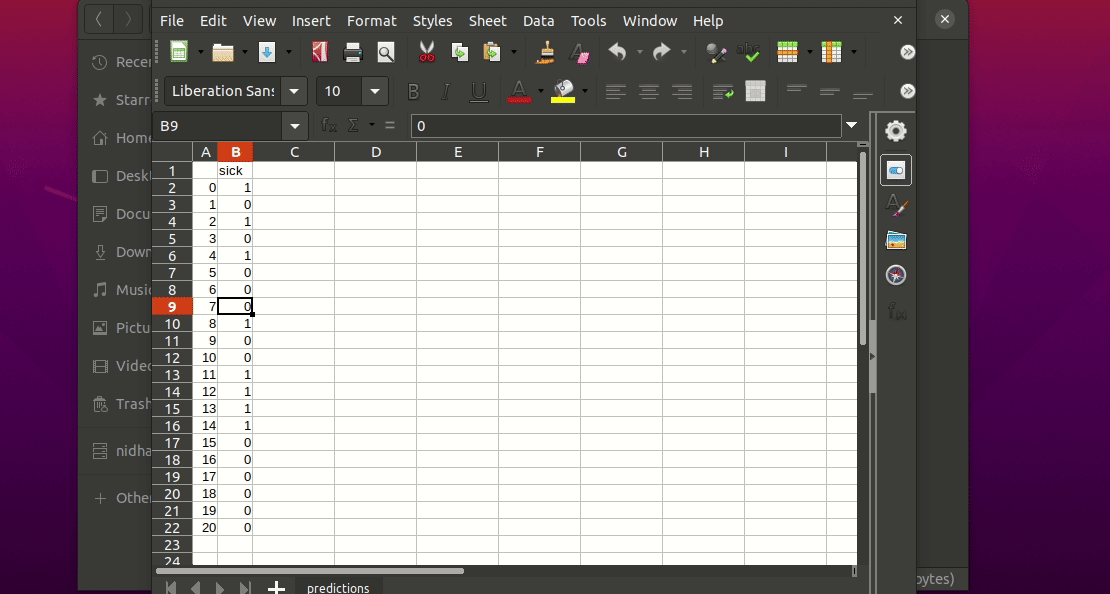
If I want to use neural networks to classify whether someone is sick or not using the indian-diabetes dataset,
then I would use this command to initialize a yaml file n.b. you may need to rename outcome column in .csv to sick:
$ igel init -type " classification " -model " NeuralNetwork " -target " sick "
"""
$ igel initApós executar o comando, um arquivo igel.yaml será criado para você no diretório de trabalho atual. Você pode conferir e modificar se quiser, caso contrário também pode criar tudo do zero.
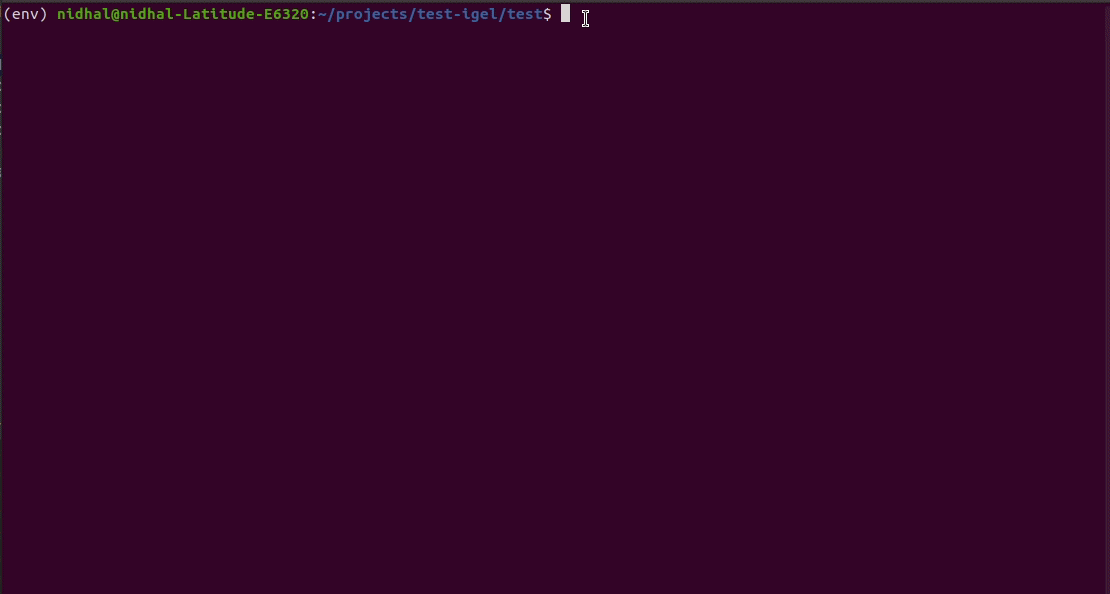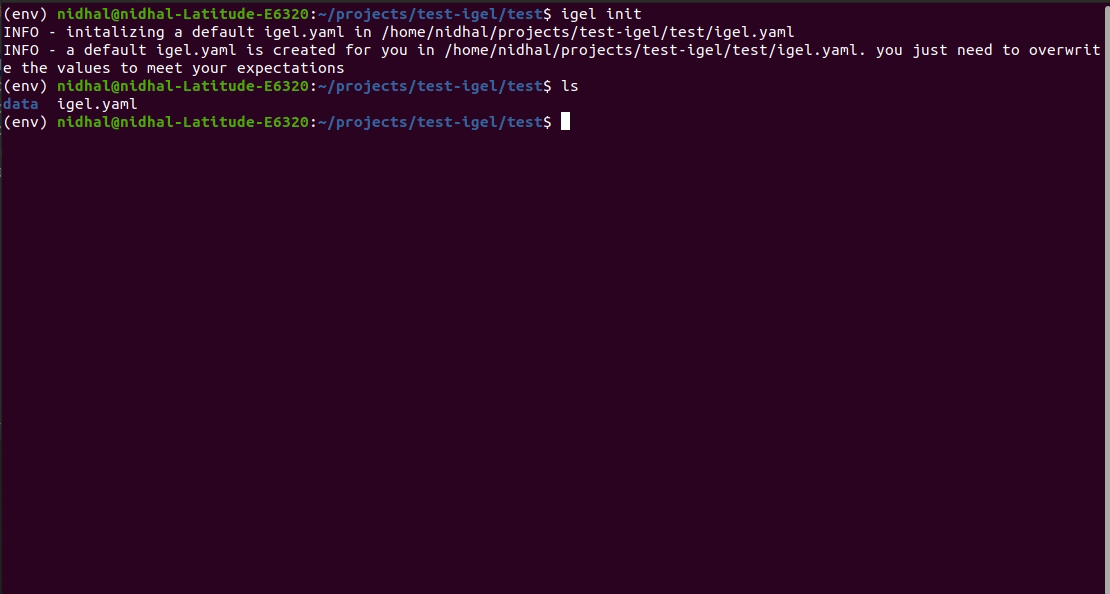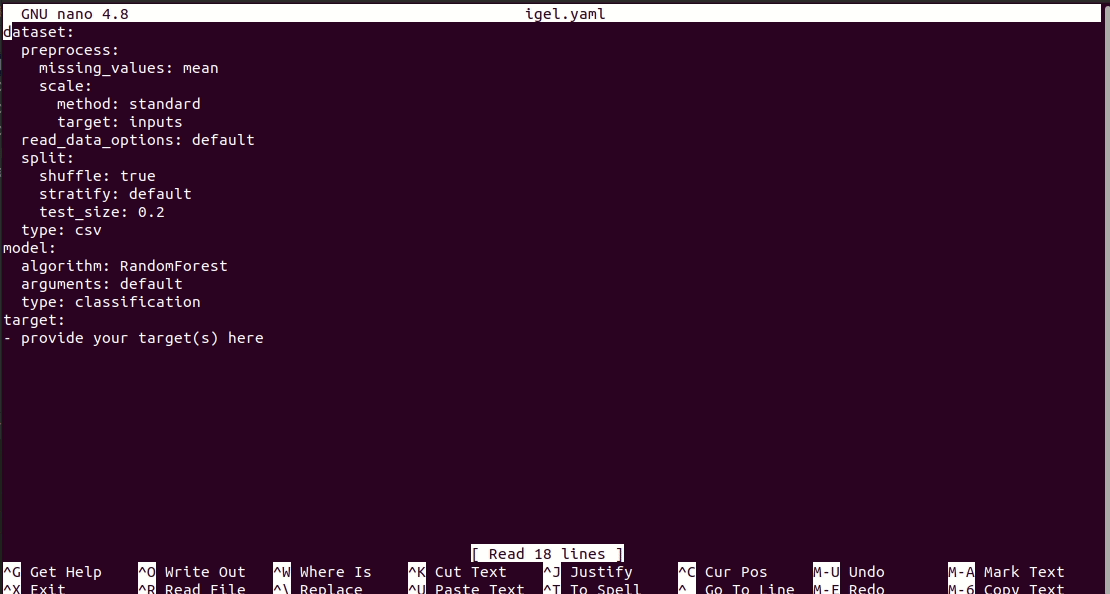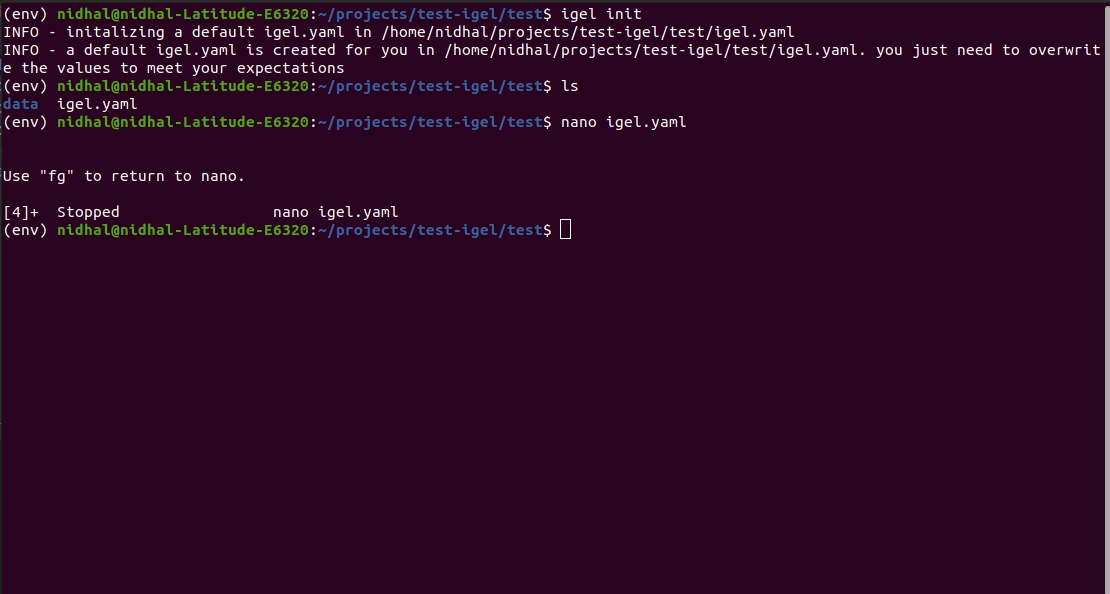
# model definition
model :
# in the type field, you can write the type of problem you want to solve. Whether regression, classification or clustering
# Then, provide the algorithm you want to use on the data. Here I'm using the random forest algorithm
type : classification
algorithm : RandomForest # make sure you write the name of the algorithm in pascal case
arguments :
n_estimators : 100 # here, I set the number of estimators (or trees) to 100
max_depth : 30 # set the max_depth of the tree
# target you want to predict
# Here, as an example, I'm using the famous indians-diabetes dataset, where I want to predict whether someone have diabetes or not.
# Depending on your data, you need to provide the target(s) you want to predict here
target :
- sickNo exemplo acima, estou usando uma floresta aleatória para classificar se alguém tem diabetes ou não dependendo de algumas características do conjunto de dados. Usei o famoso diabetes indiano neste exemplo do conjunto de dados indiano-diabetes)
Observe que passei n_estimators e max_depth como argumentos adicionais para o modelo. Se você não fornecer argumentos, o padrão será usado. Você não precisa memorizar os argumentos de cada modelo. Você sempre pode executar igel models em seu terminal, o que o levará ao modo interativo, onde será solicitado que você insira o modelo que deseja usar e o tipo de problema que deseja resolver. Igel então mostrará informações sobre o modelo e um link que você pode seguir para ver uma lista de argumentos disponíveis e como usá-los.
Execute este comando no terminal para ajustar/treinar um modelo, onde você fornece o caminho para seu conjunto de dados e o caminho para o arquivo yaml
$ igel fit --data_path ' path_to_your_csv_dataset.csv ' --yaml_path ' path_to_your_yaml_file.yaml '
# or shorter
$ igel fit -dp ' path_to_your_csv_dataset.csv ' -yml ' path_to_your_yaml_file.yaml '
"""
That's it. Your "trained" model can be now found in the model_results folder
(automatically created for you in your current working directory).
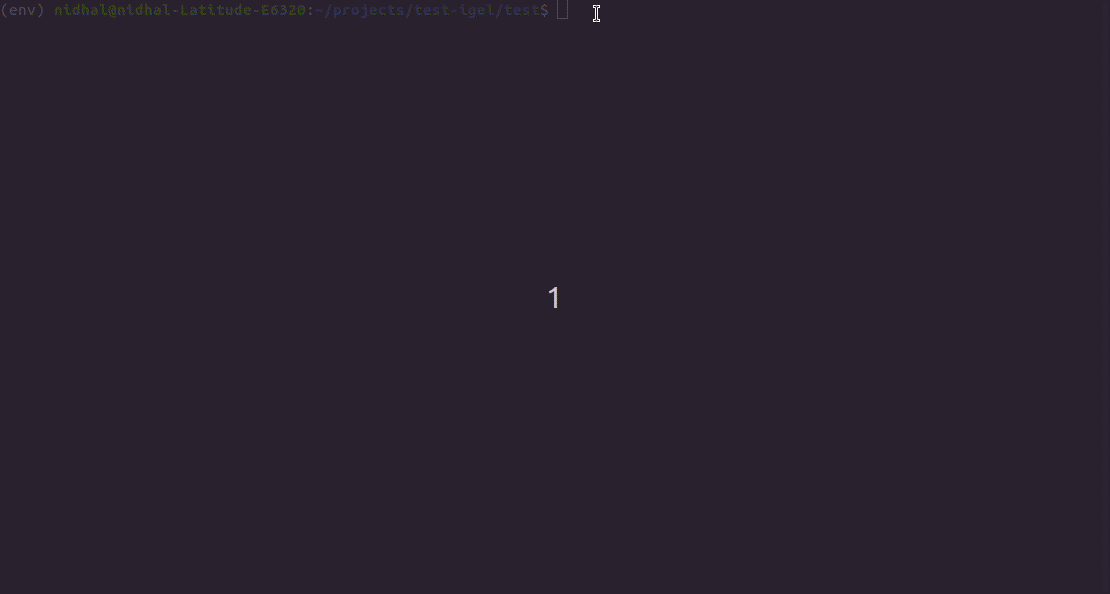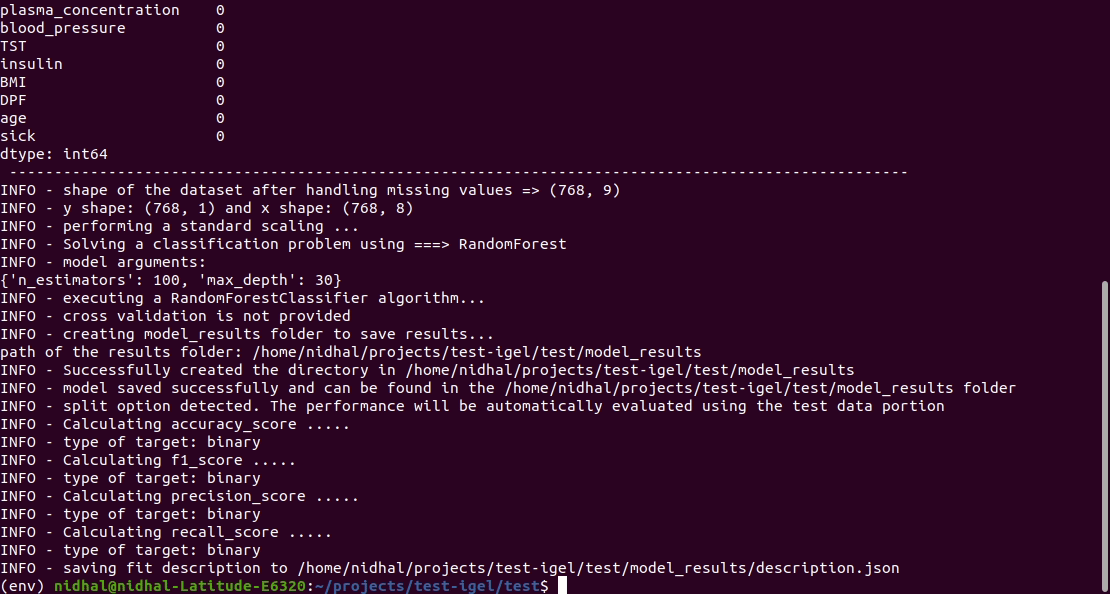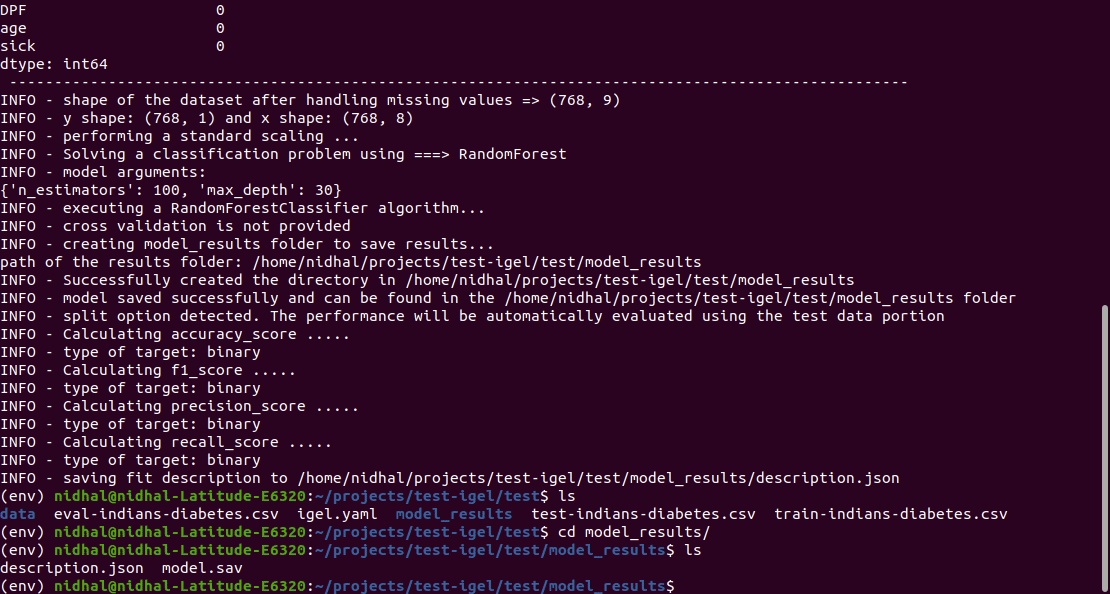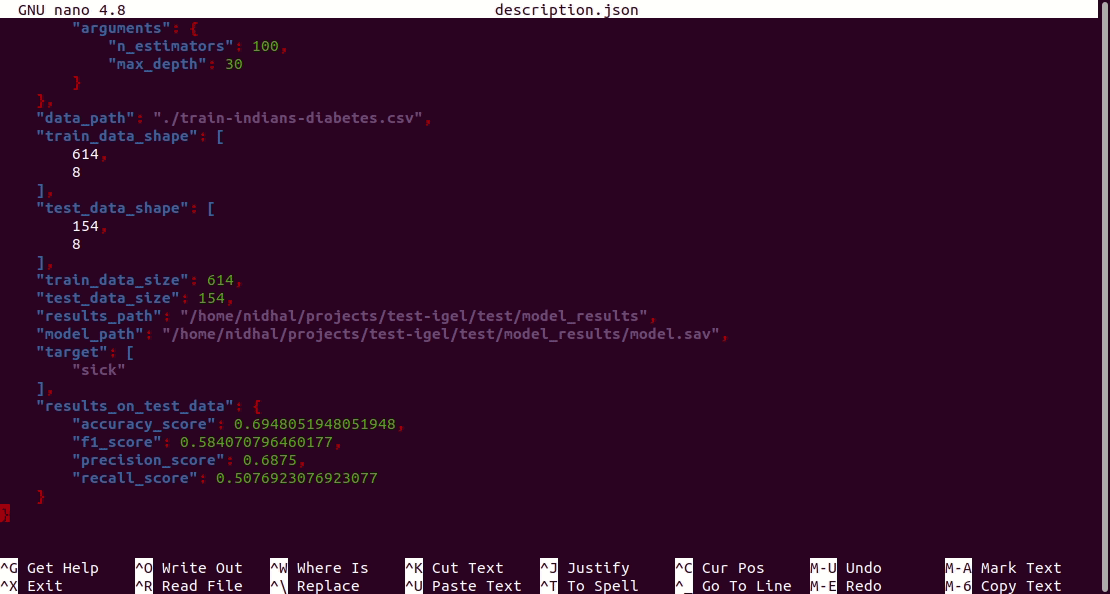
Furthermore, a description can be found in the description.json file inside the model_results folder.
"""
Você pode então avaliar o modelo treinado/pré-ajustado:
$ igel evaluate -dp ' path_to_your_evaluation_dataset.csv '
"""
This will automatically generate an evaluation.json file in the current directory, where all evaluation results are stored
"""
Finalmente, você pode usar o modelo treinado/pré-ajustado para fazer previsões se estiver satisfeito com os resultados da avaliação:
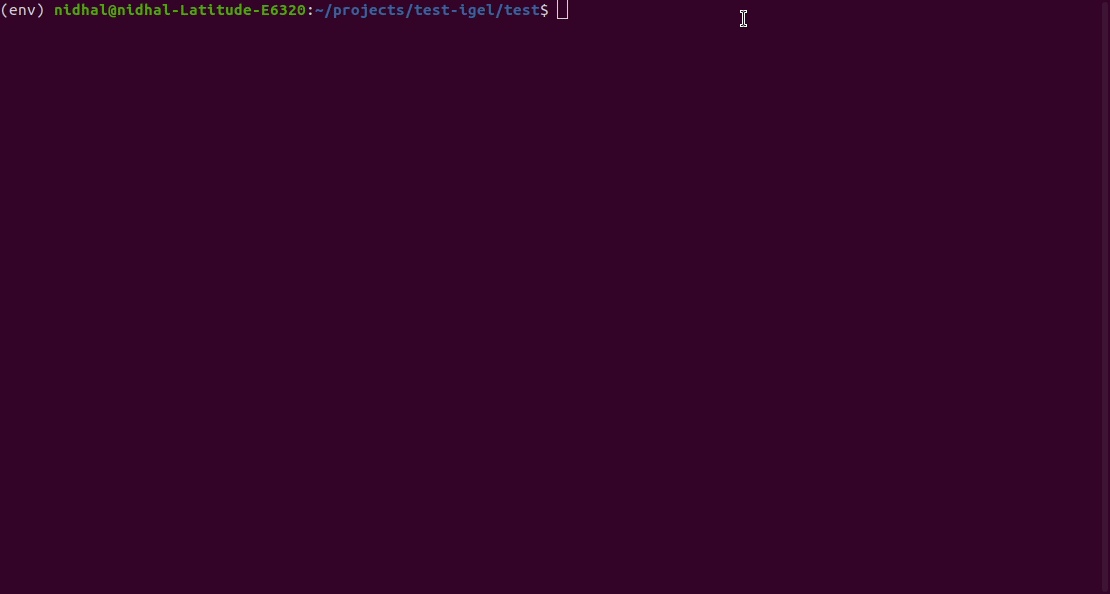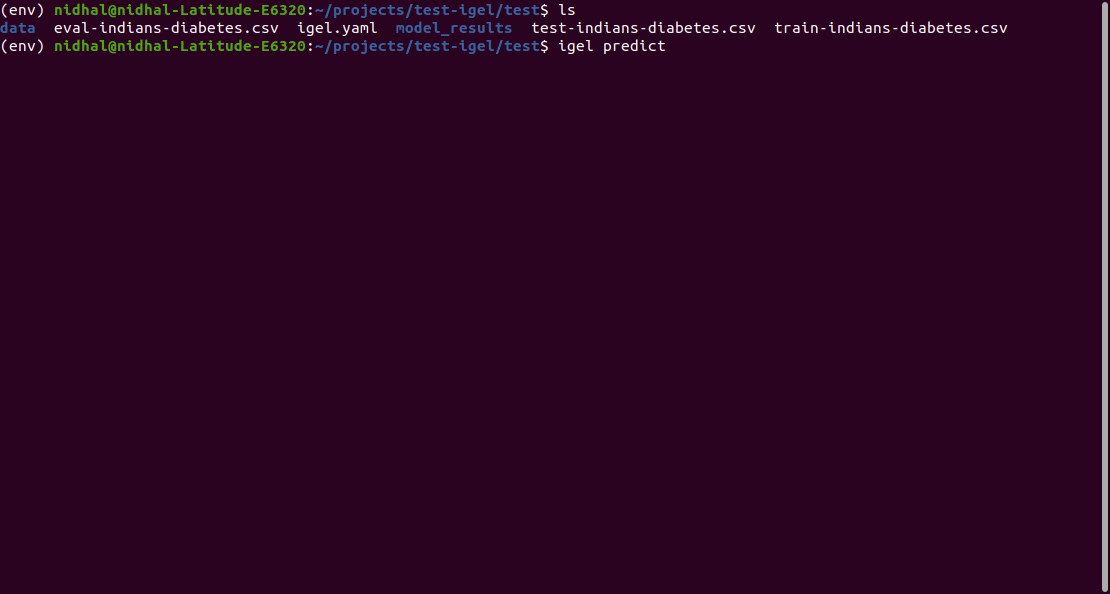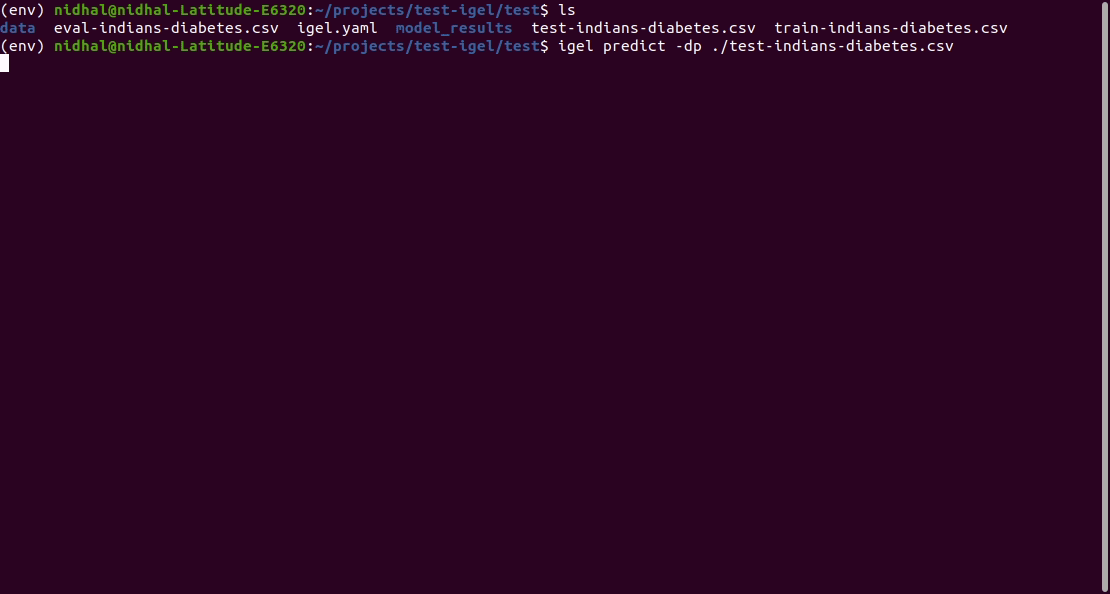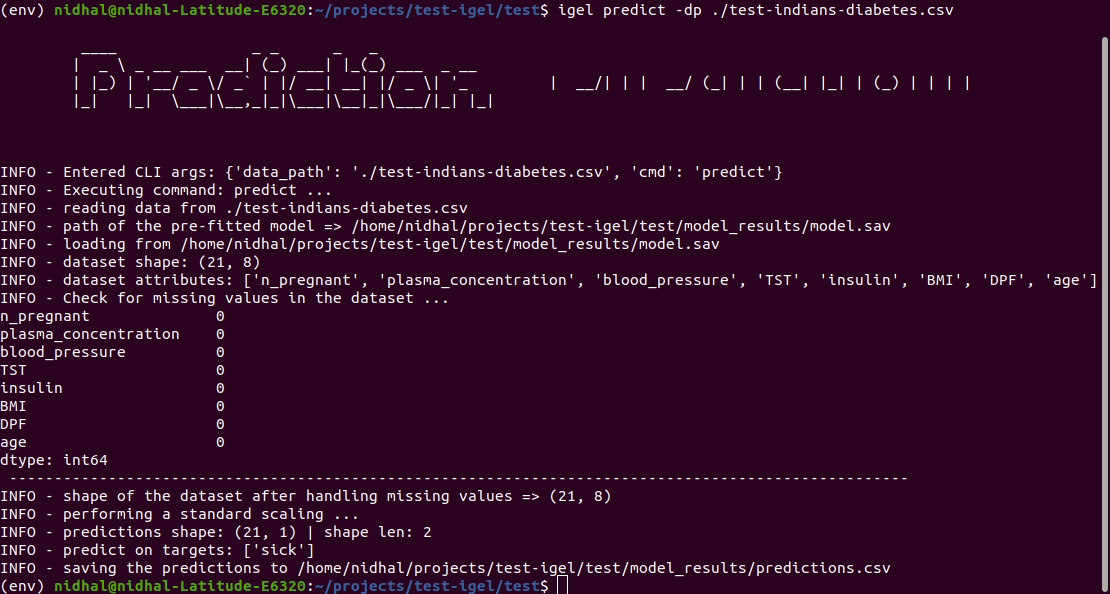
$ igel predict -dp ' path_to_your_test_dataset.csv '
"""
This will generate a predictions.csv file in your current directory, where all predictions are stored in a csv file
"""
Você pode combinar as fases de treinamento, avaliação e previsão usando um único comando chamado experimento:
$ igel experiment -DP " path_to_train_data path_to_eval_data path_to_test_data " -yml " path_to_yaml_file "
"""
This will run fit using train_data, evaluate using eval_data and further generate predictions using the test_data
"""
Você pode exportar o modelo sklearn treinado/pré-ajustado para ONNX:
$ igel export -dp " path_to_pre-fitted_sklearn_model "
"""
This will convert the sklearn model into ONNX
""" from igel import Igel
Igel ( cmd = "fit" , data_path = "path_to_your_dataset" , yaml_path = "path_to_your_yaml_file" )
"""
check the examples folder for more
"""A próxima etapa é usar seu modelo em produção. Igel também ajuda você nessa tarefa, fornecendo o comando servir. Executar o comando serve dirá ao igel para servir seu modelo. Precisamente, o igel construirá automaticamente um servidor REST e servirá seu modelo em um host e porta específicos, que você pode configurar passando-os como opções CLI.
A maneira mais fácil é executar:
$ igel serve --model_results_dir " path_to_model_results_directory "Observe que igel precisa da opção --model_results_dir ou brevemente -res_dir cli para carregar o modelo e iniciar o servidor. Por padrão, igel servirá seu modelo em localhost:8000 , no entanto, você pode facilmente substituir isso fornecendo um host e uma porta cli opções.
$ igel serve --model_results_dir " path_to_model_results_directory " --host " 127.0.0.1 " --port 8000Igel usa FastAPI para criar o servidor REST, que é uma estrutura moderna de alto desempenho e uvicorn para executá-lo nos bastidores.
Este exemplo foi feito usando um modelo pré-treinado (criado executando igel init --target ill -type rating) e o conjunto de dados Indian Diabetes em exemplos/dados. Os cabeçalhos das colunas no CSV original são 'preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi' e 'age'.
CURL:
$ curl -X POST localhost:8080/predict --header " Content-Type:application/json " -d ' {"preg": 1, "plas": 180, "pres": 50, "skin": 12, "test": 1, "mass": 456, "pedi": 0.442, "age": 50} '
Outputs: {"prediction":[[0.0]]}$ curl -X POST localhost:8080/predict --header " Content-Type:application/json " -d ' {"preg": [1, 6, 10], "plas":[192, 52, 180], "pres": [40, 30, 50], "skin": [25, 35, 12], "test": [0, 1, 1], "mass": [456, 123, 155], "pedi": [0.442, 0.22, 0.19], "age": [50, 40, 29]} '
Outputs: {"prediction":[[1.0],[0.0],[0.0]]}Advertências/Limitações:
Exemplo de uso do cliente Python:
from python_client import IgelClient
# the client allows additional args with defaults:
# scheme="http", endpoint="predict", missing_values="mean"
client = IgelClient ( host = 'localhost' , port = 8080 )
# you can post other types of files compatible with what Igel data reading allows
client . post ( "my_batch_file_for_predicting.csv" )
Outputs : < Response 200 > : { "prediction" :[[ 1.0 ],[ 0.0 ],[ 0.0 ]]}O principal objetivo do igel é fornecer uma maneira de treinar/ajustar, avaliar e usar modelos sem escrever código. Em vez disso, tudo que você precisa é fornecer/descrever o que deseja fazer em um arquivo yaml simples.
Basicamente, você fornece uma descrição, ou melhor, configurações no arquivo yaml como pares de valores-chave. Aqui está uma visão geral de todas as configurações suportadas (por enquanto):
# dataset operations
dataset :
type : csv # [str] -> type of your dataset
read_data_options : # options you want to supply for reading your data (See the detailed overview about this in the next section)
sep : # [str] -> Delimiter to use.
delimiter : # [str] -> Alias for sep.
header : # [int, list of int] -> Row number(s) to use as the column names, and the start of the data.
names : # [list] -> List of column names to use
index_col : # [int, str, list of int, list of str, False] -> Column(s) to use as the row labels of the DataFrame,
usecols : # [list, callable] -> Return a subset of the columns
squeeze : # [bool] -> If the parsed data only contains one column then return a Series.
prefix : # [str] -> Prefix to add to column numbers when no header, e.g. ‘X’ for X0, X1, …
mangle_dupe_cols : # [bool] -> Duplicate columns will be specified as ‘X’, ‘X.1’, …’X.N’, rather than ‘X’…’X’. Passing in False will cause data to be overwritten if there are duplicate names in the columns.
dtype : # [Type name, dict maping column name to type] -> Data type for data or columns
engine : # [str] -> Parser engine to use. The C engine is faster while the python engine is currently more feature-complete.
converters : # [dict] -> Dict of functions for converting values in certain columns. Keys can either be integers or column labels.
true_values : # [list] -> Values to consider as True.
false_values : # [list] -> Values to consider as False.
skipinitialspace : # [bool] -> Skip spaces after delimiter.
skiprows : # [list-like] -> Line numbers to skip (0-indexed) or number of lines to skip (int) at the start of the file.
skipfooter : # [int] -> Number of lines at bottom of file to skip
nrows : # [int] -> Number of rows of file to read. Useful for reading pieces of large files.
na_values : # [scalar, str, list, dict] -> Additional strings to recognize as NA/NaN.
keep_default_na : # [bool] -> Whether or not to include the default NaN values when parsing the data.
na_filter : # [bool] -> Detect missing value markers (empty strings and the value of na_values). In data without any NAs, passing na_filter=False can improve the performance of reading a large file.
verbose : # [bool] -> Indicate number of NA values placed in non-numeric columns.
skip_blank_lines : # [bool] -> If True, skip over blank lines rather than interpreting as NaN values.
parse_dates : # [bool, list of int, list of str, list of lists, dict] -> try parsing the dates
infer_datetime_format : # [bool] -> If True and parse_dates is enabled, pandas will attempt to infer the format of the datetime strings in the columns, and if it can be inferred, switch to a faster method of parsing them.
keep_date_col : # [bool] -> If True and parse_dates specifies combining multiple columns then keep the original columns.
dayfirst : # [bool] -> DD/MM format dates, international and European format.
cache_dates : # [bool] -> If True, use a cache of unique, converted dates to apply the datetime conversion.
thousands : # [str] -> the thousands operator
decimal : # [str] -> Character to recognize as decimal point (e.g. use ‘,’ for European data).
lineterminator : # [str] -> Character to break file into lines.
escapechar : # [str] -> One-character string used to escape other characters.
comment : # [str] -> Indicates remainder of line should not be parsed. If found at the beginning of a line, the line will be ignored altogether. This parameter must be a single character.
encoding : # [str] -> Encoding to use for UTF when reading/writing (ex. ‘utf-8’).
dialect : # [str, csv.Dialect] -> If provided, this parameter will override values (default or not) for the following parameters: delimiter, doublequote, escapechar, skipinitialspace, quotechar, and quoting
delim_whitespace : # [bool] -> Specifies whether or not whitespace (e.g. ' ' or ' ') will be used as the sep
low_memory : # [bool] -> Internally process the file in chunks, resulting in lower memory use while parsing, but possibly mixed type inference.
memory_map : # [bool] -> If a filepath is provided for filepath_or_buffer, map the file object directly onto memory and access the data directly from there. Using this option can improve performance because there is no longer any I/O overhead.
random_numbers : # random numbers options in case you wanted to generate the same random numbers on each run
generate_reproducible : # [bool] -> set this to true to generate reproducible results
seed : # [int] -> the seed number is optional. A seed will be set up for you if you didn't provide any
split : # split options
test_size : 0.2 # [float] -> 0.2 means 20% for the test data, so 80% are automatically for training
shuffle : true # [bool] -> whether to shuffle the data before/while splitting
stratify : None # [list, None] -> If not None, data is split in a stratified fashion, using this as the class labels.
preprocess : # preprocessing options
missing_values : mean # [str] -> other possible values: [drop, median, most_frequent, constant] check the docs for more
encoding :
type : oneHotEncoding # [str] -> other possible values: [labelEncoding]
scale : # scaling options
method : standard # [str] -> standardization will scale values to have a 0 mean and 1 standard deviation | you can also try minmax
target : inputs # [str] -> scale inputs. | other possible values: [outputs, all] # if you choose all then all values in the dataset will be scaled
# model definition
model :
type : classification # [str] -> type of the problem you want to solve. | possible values: [regression, classification, clustering]
algorithm : NeuralNetwork # [str (notice the pascal case)] -> which algorithm you want to use. | type igel algorithms in the Terminal to know more
arguments : # model arguments: you can check the available arguments for each model by running igel help in your terminal
use_cv_estimator : false # [bool] -> if this is true, the CV class of the specific model will be used if it is supported
cross_validate :
cv : # [int] -> number of kfold (default 5)
n_jobs : # [signed int] -> The number of CPUs to use to do the computation (default None)
verbose : # [int] -> The verbosity level. (default 0)
hyperparameter_search :
method : grid_search # method you want to use: grid_search and random_search are supported
parameter_grid : # put your parameters grid here that you want to use, an example is provided below
param1 : [val1, val2]
param2 : [val1, val2]
arguments : # additional arguments you want to provide for the hyperparameter search
cv : 5 # number of folds
refit : true # whether to refit the model after the search
return_train_score : false # whether to return the train score
verbose : 0 # verbosity level
# target you want to predict
target : # list of strings: basically put here the column(s), you want to predict that exist in your csv dataset
- put the target you want to predict here
- you can assign many target if you are making a multioutput prediction Observação
igel usa pandas nos bastidores para ler e analisar os dados. Portanto, você pode encontrar esses parâmetros opcionais de dados também na documentação oficial do pandas.
Uma visão geral detalhada das configurações que você pode fornecer no arquivo yaml (ou json) é fornecida abaixo. Observe que você certamente não precisará de todos os valores de configuração do conjunto de dados. Eles são opcionais. Geralmente, o igel descobrirá como ler seu conjunto de dados.
No entanto, você pode ajudar fornecendo campos extras usando esta seção read_data_options. Por exemplo, um dos valores úteis na minha opinião é "sep", que define como suas colunas no conjunto de dados csv são separadas. Geralmente, os conjuntos de dados csv são separados por vírgulas, que também é o valor padrão aqui. No entanto, pode ser separado por ponto e vírgula no seu caso.
Portanto, você pode fornecer isso em read_data_options. Basta adicionar o sep: ";" em read_data_options.
| Parâmetro | Tipo | Explicação |
|---|---|---|
| setembro | str, padrão ',' | Delimitador a ser usado. Se sep for None, o mecanismo C não poderá detectar automaticamente o separador, mas o mecanismo de análise Python poderá, o que significa que o último será usado e detectará automaticamente o separador pela ferramenta sniffer integrada do Python, csv.Sniffer. Além disso, separadores com mais de 1 caractere e diferentes de 's+' serão interpretados como expressões regulares e também forçarão o uso do mecanismo de análise Python. Observe que os delimitadores regex tendem a ignorar os dados citados. Exemplo de Regex: 'rt'. |
| delimitador | padrão Nenhum | Alias para setembro. |
| cabeçalho | int, lista de int, padrão 'inferir' | Número(s) de linha a serem usados como nomes de colunas e o início dos dados. O comportamento padrão é inferir os nomes das colunas: se nenhum nome for passado, o comportamento será idêntico ao header=0 e os nomes das colunas serão inferidos a partir da primeira linha do arquivo, se os nomes das colunas forem passados explicitamente, o comportamento será idêntico ao header=None . Passe explicitamente header=0 para poder substituir nomes existentes. O cabeçalho pode ser uma lista de números inteiros que especificam as localizações das linhas para um índice múltiplo nas colunas, por exemplo, [0,1,3]. As linhas intermediárias que não forem especificadas serão ignoradas (por exemplo, 2 neste exemplo são ignoradas). Observe que este parâmetro ignora linhas comentadas e linhas vazias se skip_blank_lines=True, então header=0 denota a primeira linha de dados em vez da primeira linha do arquivo. |
| nomes | tipo array, opcional | Lista de nomes de colunas a serem usados. Se o arquivo contiver uma linha de cabeçalho, você deverá passar explicitamente header=0 para substituir os nomes das colunas. Duplicatas nesta lista não são permitidas. |
| índice_col | int, str, sequência de int / str, ou False, padrão Nenhum | Coluna(s) a serem usadas como rótulos de linha do DataFrame, fornecidos como nome de string ou índice de coluna. Se uma sequência de int/str for fornecida, um MultiIndex será usado. Nota: index_col=False pode ser usado para forçar o pandas a não usar a primeira coluna como índice, por exemplo, quando você tem um arquivo malformado com delimitadores no final de cada linha. |
| usar cols | semelhante a uma lista ou chamável, opcional | Retorne um subconjunto das colunas. Se for semelhante a uma lista, todos os elementos devem ser posicionais (ou seja, índices inteiros nas colunas do documento) ou strings que correspondam aos nomes das colunas fornecidos pelo usuário em nomes ou inferidos da(s) linha(s) do cabeçalho do documento. Por exemplo, um parâmetro usecols semelhante a uma lista válido seria [0, 1, 2] ou ['foo', 'bar', 'baz']. A ordem dos elementos é ignorada, então usecols=[0, 1] é igual a [1, 0]. Para instanciar um DataFrame a partir de dados com ordem de elemento preservada, use pd.read_csv(data, usecols=['foo', 'bar'])[['foo', 'bar']] para colunas em ['foo', 'bar '] pedido ou pd.read_csv(data, usecols=['foo', 'bar'])[['bar', 'foo']] para ['bar', 'foo'] ordem. Se puder ser chamada, a função que pode ser chamada será avaliada em relação aos nomes das colunas, retornando nomes onde a função que pode ser chamada for avaliada como True. Um exemplo de argumento que pode ser chamado válido seria lambda x: x.upper() in ['AAA', 'BBB', 'DDD']. Usar esse parâmetro resulta em tempo de análise muito mais rápido e menor uso de memória. |
| espremer | bool, padrão Falso | Se os dados analisados contiverem apenas uma coluna, retorne uma série. |
| prefixo | str, opcional | Prefixo para adicionar aos números das colunas quando não há cabeçalho, por exemplo, 'X' para X0, X1,… |
| mangle_dupe_cols | bool, padrão Verdadeiro | Colunas duplicadas serão especificadas como 'X', 'X.1',…'X.N', em vez de 'X'…'X'. Passar False fará com que os dados sejam sobrescritos se houver nomes duplicados nas colunas. |
| tipo d | {'c', 'python'}, opcional | Mecanismo de analisador a ser usado. O mecanismo C é mais rápido, enquanto o mecanismo python é atualmente mais completo em recursos. |
| conversores | ditado, opcional | Ditado de funções para conversão de valores em determinadas colunas. As chaves podem ser números inteiros ou rótulos de coluna. |
| valores_verdadeiro | lista, opcional | Valores a considerar como Verdadeiros. |
| valores_falsos | lista, opcional | Valores a considerar como falsos. |
| pular espaço inicial | bool, padrão Falso | Pule espaços após o delimitador. |
| skiprows | semelhante a uma lista, int ou chamável, opcional | Números de linhas a serem ignoradas (indexadas em 0) ou número de linhas a serem ignoradas (int) no início do arquivo. Se puder ser chamada, a função que pode ser chamada será avaliada em relação aos índices de linha, retornando True se a linha deve ser ignorada e False caso contrário. Um exemplo de argumento que pode ser chamado válido seria lambda x: x in [0, 2]. |
| saltador | interno, padrão 0 | Número de linhas na parte inferior do arquivo a serem ignoradas (não suportado com engine='c'). |
| agora | interno, opcional | Número de linhas do arquivo a serem lidas. Útil para ler pedaços de arquivos grandes. |
| na_valores | escalar, str, tipo lista ou dict, opcional | Strings adicionais a serem reconhecidas como NA/NaN. Se o dict for aprovado, valores NA específicos por coluna. Por padrão, os seguintes valores são interpretados como NaN: '', '#N/A', '#N/AN/A', '#NA', '-1.#IND', '-1.#QNAN', '-NaN', '-nan', '1.#IND', '1.#QNAN', '<NA>', 'N/A', 'NA', 'NULL', 'NaN', 'n /a', 'nan', 'nulo'. |
| keep_default_na | bool, padrão Verdadeiro | Incluir ou não os valores NaN padrão ao analisar os dados. Dependendo se na_values for passado, o comportamento será o seguinte: Se keep_default_na for True e na_values forem especificados, na_values será anexado aos valores NaN padrão usados para análise. Se keep_default_na for True e na_values não forem especificados, apenas os valores NaN padrão serão usados para análise. Se keep_default_na for False e na_values forem especificados, apenas os valores NaN especificados na_values serão usados para análise. Se keep_default_na for False e na_values não forem especificados, nenhuma string será analisada como NaN. Observe que se na_filter for passado como False, os parâmetros keep_default_na e na_values serão ignorados. |
| na_filtro | bool, padrão Verdadeiro | Detecte marcadores de valor ausentes (strings vazias e o valor de na_values). Em dados sem NAs, passar na_filter=False pode melhorar o desempenho da leitura de um arquivo grande. |
| detalhado | bool, padrão Falso | Indique o número de valores NA colocados em colunas não numéricas. |
| skip_blank_lines | bool, padrão Verdadeiro | Se for True, ignore as linhas em branco em vez de interpretar como valores NaN. |
| parse_dates | bool ou lista de int ou nomes ou lista de listas ou dict, padrão False | O comportamento é o seguinte: booleano. Se True -> tente analisar o índice. lista de int ou nomes. por exemplo, If [1, 2, 3] -> tente analisar as colunas 1, 2, 3 cada uma como uma coluna de data separada. lista de listas. por exemplo, If [[1, 3]] -> combine as colunas 1 e 3 e analise como uma única coluna de data. dict, por exemplo, {'foo': [1, 3]} -> analisa as colunas 1, 3 como data e chama o resultado 'foo' Se uma coluna ou índice não pode ser representado como uma matriz de datas e horas, digamos por causa de um valor não analisável ou uma mistura de fusos horários, a coluna ou índice será retornado inalterado como um tipo de dados de objeto. |
| infer_datetime_format | bool, padrão Falso | Se True e parse_dates estiverem habilitados, o pandas tentará inferir o formato das strings de data e hora nas colunas e, se puder ser inferido, mudará para um método mais rápido de analisá-las. Em alguns casos, isso pode aumentar a velocidade de análise em 5 a 10x. |
| keep_date_col | bool, padrão Falso | Se True e parse_dates especificarem a combinação de múltiplas colunas, mantenha as colunas originais. |
| data_parser | função, opcional | Função a ser usada para converter uma sequência de colunas de string em uma matriz de instâncias de data e hora. O padrão usa dateutil.parser.parser para fazer a conversão. O Pandas tentará chamar date_parser de três maneiras diferentes, avançando para a próxima se ocorrer uma exceção: 1) Passar um ou mais arrays (conforme definido por parse_dates) como argumentos; 2) concatenar (linha) os valores da string das colunas definidas por parse_dates em um único array e passá-lo; e 3) chamar date_parser uma vez para cada linha usando uma ou mais strings (correspondentes às colunas definidas por parse_dates) como argumentos. |
| primeiro dia | bool, padrão Falso | Datas em formato DD/MM, formato internacional e europeu. |
| datas_cache | bool, padrão Verdadeiro | Se for True, use um cache de datas convertidas exclusivas para aplicar a conversão de data e hora. Pode produzir uma aceleração significativa ao analisar sequências de datas duplicadas, especialmente aquelas com diferenças de fuso horário. |
| milhares | str, opcional | Separador de milhares. |
| decimal | str, padrão '.' | Caractere a reconhecer como ponto decimal (por exemplo, use ',' para dados europeus). |
| terminador de linha | str (comprimento 1), opcional | Caractere para dividir o arquivo em linhas. Válido apenas com analisador C. |
| escapechar | str (comprimento 1), opcional | String de um caractere usada para escapar de outros caracteres. |
| comentário | str, opcional | Indica que o restante da linha não deve ser analisado. Se for encontrado no início de uma linha, a linha será totalmente ignorada. |
| codificação | str, opcional | Codificação a ser usada para UTF ao ler/escrever (ex. 'utf-8'). |
| dialeto | str ou csv.Dialect, opcional | Se fornecido, este parâmetro substituirá os valores (padrão ou não) dos seguintes parâmetros: delimitador, aspas duplas, escapechar, skipinitialspace, quotechar e aspas |
| memória_baixa | bool, padrão Verdadeiro | Processe internamente o arquivo em partes, resultando em menor uso de memória durante a análise, mas possivelmente em inferência de tipo misto. Para garantir que não haja tipos mistos, defina False ou especifique o tipo com o parâmetro dtype. Observe que o arquivo inteiro é lido em um único DataFrame independentemente, |
| mapa_de_memória | bool, padrão Falso | mapeie o objeto de arquivo diretamente na memória e acesse os dados diretamente de lá. Usar esta opção pode melhorar o desempenho porque não há mais sobrecarga de E/S. |
Uma solução completa de ponta a ponta é fornecida nesta seção para provar as capacidades do igel . Conforme explicado anteriormente, você precisa criar um arquivo de configuração yaml. Aqui está um exemplo completo para prever se alguém tem diabetes ou não usando o algoritmo da árvore de decisão . O conjunto de dados pode ser encontrado na pasta de exemplos.
model :
type : classification
algorithm : DecisionTree
target :
- sick $ igel fit -dp path_to_the_dataset -yml path_to_the_yaml_fileÉ isso, o igel agora irá ajustar o modelo para você e salvá-lo em uma pasta model_results em seu diretório atual.
Avalie o modelo pré-ajustado. Igel irá carregar o modelo pré-ajustado do diretório model_results e avaliá-lo para você. Você só precisa executar o comando avaliar e fornecer o caminho para seus dados de avaliação.
$ igel evaluate -dp path_to_the_evaluation_datasetÉ isso! Igel avaliará o modelo e armazenará estatísticas/resultados em um arquivo assessment.json dentro da pasta model_results
Use o modelo pré-ajustado para prever novos dados. Isso é feito automaticamente pelo igel, você só precisa fornecer o caminho para os dados nos quais deseja usar a previsão.
$ igel predict -dp path_to_the_new_datasetÉ isso! Igel usará o modelo pré-ajustado para fazer previsões e salvá-lo em um arquivo Predictions.csv dentro da pasta model_results
Você também pode realizar alguns métodos de pré-processamento ou outras operações, fornecendo-os no arquivo yaml. Aqui está um exemplo, onde os dados são divididos em 80% para treinamento e 20% para validação/teste. Além disso, os dados são embaralhados durante a divisão.
Além disso, os dados são pré-processados substituindo os valores ausentes pela média (você também pode usar mediana, moda, etc.). verifique este link para mais informações
# dataset operations
dataset :
split :
test_size : 0.2
shuffle : True
stratify : default
preprocess : # preprocessing options
missing_values : mean # other possible values: [drop, median, most_frequent, constant] check the docs for more
encoding :
type : oneHotEncoding # other possible values: [labelEncoding]
scale : # scaling options
method : standard # standardization will scale values to have a 0 mean and 1 standard deviation | you can also try minmax
target : inputs # scale inputs. | other possible values: [outputs, all] # if you choose all then all values in the dataset will be scaled
# model definition
model :
type : classification
algorithm : RandomForest
arguments :
# notice that this is the available args for the random forest model. check different available args for all supported models by running igel help
n_estimators : 100
max_depth : 20
# target you want to predict
target :
- sickEntão, você pode ajustar o modelo executando o comando igel conforme mostrado nos outros exemplos
$ igel fit -dp path_to_the_dataset -yml path_to_the_yaml_filePara avaliação
$ igel evaluate -dp path_to_the_evaluation_datasetPara produção
$ igel predict -dp path_to_the_new_dataset Na pasta de exemplos do repositório, você encontrará uma pasta de dados, onde os famosos conjuntos de dados indian-diabetes, iris e linnerud (do sklearn) estão armazenados. Além disso, existem exemplos completos dentro de cada pasta, onde existem scripts e arquivos yaml que ajudarão você a começar.
A pasta indian-diabetes-example contém dois exemplos para ajudá-lo a começar:
A pasta iris-example contém um exemplo de regressão logística , onde algum pré-processamento (uma codificação dinâmica) é conduzido na coluna de destino para mostrar mais os recursos do igel.
Além disso, o exemplo de múltiplas saídas contém um exemplo de regressão de múltiplas saídas . Finalmente, o exemplo cv contém um exemplo usando o classificador Ridge usando validação cruzada.
Você também pode encontrar exemplos de validação cruzada e pesquisa de hiperparâmetros na pasta.
Eu sugiro que você brinque com os exemplos e o igel cli. No entanto, você também pode executar diretamente fit.py,avaliar.py e prever.py se desejar.
Primeiro, crie ou modifique um conjunto de dados de imagens categorizadas em subpastas com base no rótulo/classe da imagem. Por exemplo, se você tiver imagens de cães e gatos, precisará de 2 subpastas:
Supondo que essas duas subpastas estejam contidas em uma pasta pai chamada imagens, basta alimentar os dados para igel:
$ igel auto-train -dp ./images --task ImageClassificationIgel cuidará de tudo, desde o pré-processamento dos dados até a otimização dos hiperparâmetros. Ao final, o melhor modelo será armazenado no diretório de trabalho atual.
Primeiro, crie ou modifique um conjunto de dados de texto categorizado em subpastas com base no rótulo/classe de texto. Por exemplo, se você tiver um conjunto de dados de texto de feedbacks positivos e negativos, precisará de 2 subpastas:
Supondo que essas duas subpastas estejam contidas em uma pasta pai chamada textos, basta alimentar os dados para igel:
$ igel auto-train -dp ./texts --task TextClassificationIgel cuidará de tudo, desde o pré-processamento dos dados até a otimização dos hiperparâmetros. Ao final, o melhor modelo será armazenado no diretório de trabalho atual.
Você também pode executar a UI do igel se não estiver familiarizado com o terminal. Basta instalar o igel em sua máquina conforme mencionado acima. Em seguida, execute este único comando em seu terminal
$ igel guiIsso abrirá a interface gráfica, que é muito simples de usar. Confira exemplos de aparência da interface gráfica e como usá-la aqui: https://github.com/nidhaloff/igel-ui
Você pode extrair a imagem primeiro do docker hub
$ docker pull nidhaloff/igelEntão use-o:
$ docker run -it --rm -v $( pwd ) :/data nidhaloff/igel fit -yml ' your_file.yaml ' -dp ' your_dataset.csv 'Você pode executar o igel dentro do docker construindo primeiro a imagem:
$ docker build -t igel .E então executá-lo e anexar seu diretório atual (não precisa ser o diretório igel) como /data (o workdir) dentro do contêiner:
$ docker run -it --rm -v $( pwd ) :/data igel fit -yml ' your_file.yaml ' -dp ' your_dataset.csv ' Se você estiver enfrentando algum problema, sinta-se à vontade para abrir um problema. Além disso, você pode entrar em contato com o autor para maiores informações/dúvidas.
Você gosta de igel? Você sempre pode ajudar no desenvolvimento deste projeto:
Você acha que este projeto é útil e quer trazer novas ideias, novos recursos, correções de bugs, ampliar a documentação?
Contribuições são sempre bem-vindas. Certifique-se de ler as diretrizes primeiro
Licença MIT
Copyright (c) 2020 até o presente, Nidhal Baccouri


