awesome mojo
1.0.0

Mojo — uma nova linguagem de programação para todos os desenvolvedores, cientistas de IA/ML e engenheiros de software.
Uma lista selecionada de códigos Mojo incríveis, soluções de problemas, soluções e, em futuras bibliotecas, estruturas, software e recursos.
Vamos acumular aqui novos conhecimentos tecnológicos e melhores práticas.
Mojo é uma linguagem de programação que combina a facilidade de uso do Python com os recursos de desempenho do C++ e Rust. Além disso, o Mojo permite que os usuários aproveitem o vasto ecossistema de bibliotecas Python.
Em um breve
Mojo é uma nova linguagem de programação que preenche a lacuna entre pesquisa e produção, combinando o melhor da sintaxe Python com programação de sistemas e metaprogramação.
hello.mojo ou hello. a extensão do arquivo pode ser um emoji!
Você pode ler mais sobre por que a Modular está fazendo isso. Por que Mojo
O que queríamos era um modelo de programação inovador e escalável que pudesse atingir aceleradores e outros sistemas heterogêneos que são difundidos no campo da IA. ... Os sistemas de IA aplicados precisam resolver todos esses problemas, e decidimos que não havia razão para que isso não pudesse ser feito com apenas um idioma. Assim nasceu Mojo.
Mas Python fez seu trabalho muito bem =)
Não vimos necessidade de inovar na sintaxe ou na comunidade da linguagem. Então escolhemos abraçar o ecossistema Python porque ele é amplamente utilizado, é adorado pelo ecossistema de IA e porque acreditamos que é uma linguagem muito boa.
Mojo significa “um encanto mágico” ou “poderes mágicos”. Achamos que este era um nome adequado para uma linguagem que traz poderes mágicos ao Python :python:, incluindo o desbloqueio de um modelo de programação inovador para aceleradores e outros sistemas heterogêneos difundidos na IA hoje.
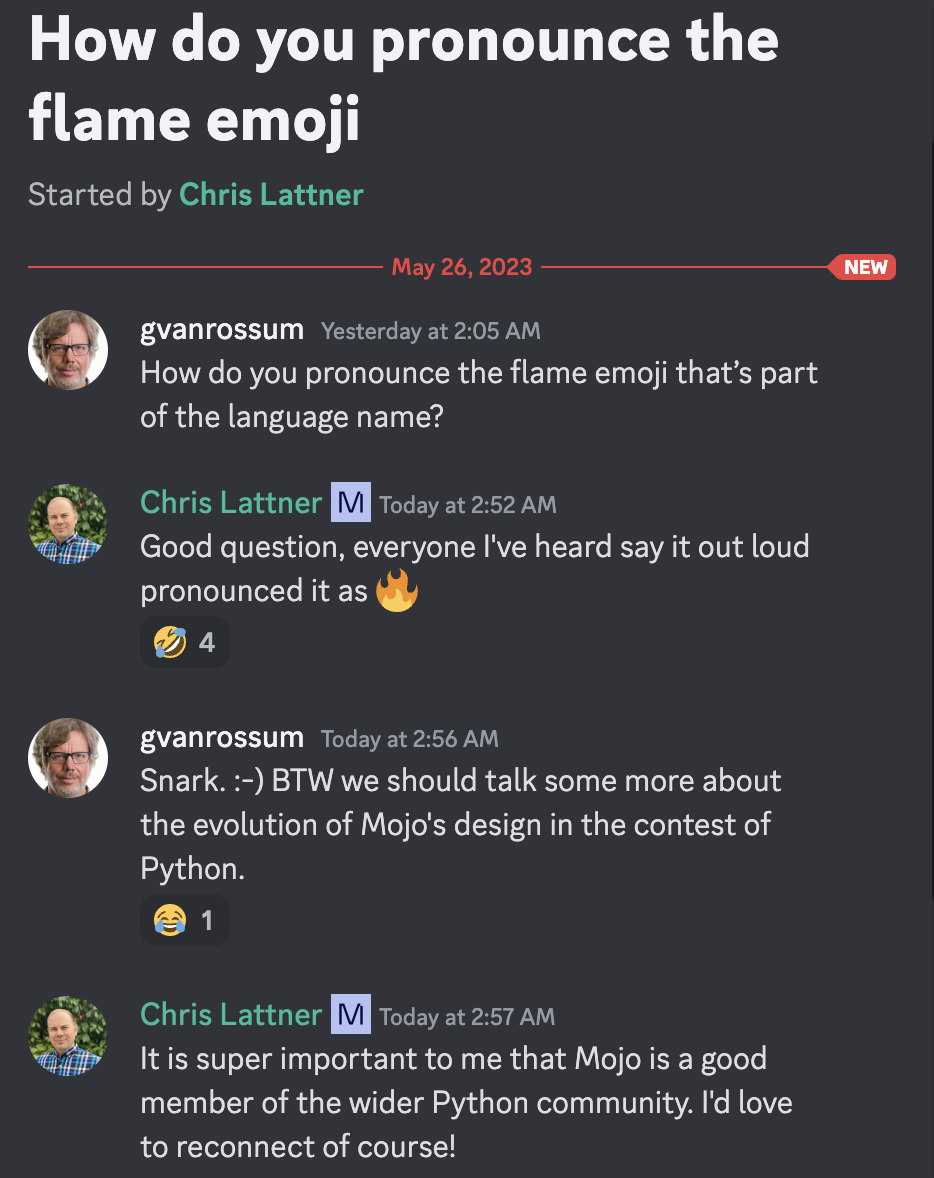
Guido van Rossum ditador benevolente vitalício e Christopher Arthur Lattner ilustre inventor, criador e líder conhecido sobre a pronúncia Mojo =)
De acordo com a descrição
Quem sabe essas linguagens de programação ficarão muito felizes, pois o Mojo se beneficia de tremendas lições aprendidas com outras linguagens Rust, Swift, Julia, Zig, Nim, etc.
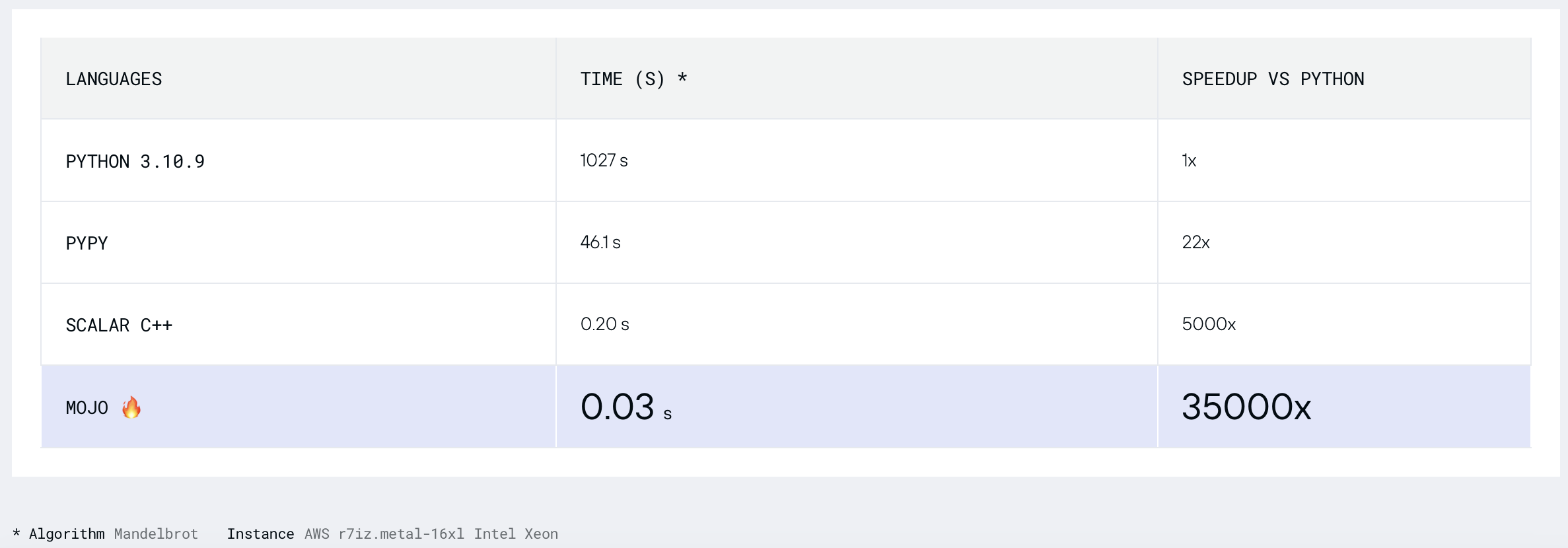
[novo]
Github agora detecta automaticamente o código Mojo!
Estrutura HTTP simples e rápida para Mojo! Perfeito para construir serviços web e APIs simples. Para Mojicianos
Estrutura de benchmarking de implementações LLama
Tradução automatizada de código Python para Mojo
Pesquisa de banco de dados de linguagem de programação
19 de outubro de 2023 Mojo já está disponível no Mac! Usar o console do desenvolvedor
Chris Lattner: Futuro da programação e IA | Podcast Lex Fridman #381
Sistema de tipo Mojo e Python explicado | Chris Lattner e Lex Fridman
O Mojo pode executar código Python? | Chris Lattner e Lex Fridman
Mudando da linguagem de programação Python para Mojo | Chris Lattner e Lex Fridman
Novo tópico do GitHub mojo-lang. Então você pode segui-lo.
Guido van Rossum sobre Mojo = Python com desempenho C++/GPU?
Estrutura tensor com algumas operações básicas #251
Matriz fn com numpy #267
Atualizações sobre lambda e fechamentos de parameter e funções de ordem superior no mojo #244
25 de maio de 2023, Guido van Rossum (gvanrossum#8415), criador e emérito BDFL do Python, visite o Discord Chat público do Mojo
Esperando por um destaque de sintaxe do Mojo no GitHub
Novo lançamento do Mojo 24/05/2023
[velho]
Mojo
brew install hyperfinebrew install macchinapip3 install numpy matplotlib scipybrew install silicon
Versões Python/Mojo/Codon/Rust
> python3 --version
Python 3.11.6
> mojo --version
mojo 0.4.0 (9e33b013)
> codon --version
0.16.3
> rustc --version
rustc 1.65.0-nightly (9243168fa 2022-08-31)Vamos encontrar a sequência de Fibonacci onde
N = 100
def fibonacci_recursion ( n ):
return n if n < 2 else fibonacci_recursion ( n - 1 ) + fibonacci_recursion ( n - 2 )
fibonacci_recursion ( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json python_recursion.json ' python3 benchmarks/fibonacci_sequence/python_recursion.py 'RESULTADO: TIMEOUT, cancelei o cálculo após 1m
def fibonacci_iteration ( n ):
a , b = 0 , 1
for _ in range ( n ):
a , b = b , a + b
return a
fibonacci_iteration ( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/python_iteration.json ' python3 benchmarks/fibonacci_sequence/python_iteration.py ' RESULTADO :
Referência 1: benchmarks python3/fibonacci_sequence/python_iteration.py
Tempo (média ± σ): 16374,7 µs ± 904,0 µs [Usuário: 11483,5 µs, Sistema: 3680,0 µs]
Faixa (mín… máx.): 15.361,0 µs… 22.863,3 µs 100 execuções
python3 -m compileall benchmarks/fibonacci_sequence/python_recursion.py
python3 -m compileall benchmarks/fibonacci_sequence/python_iteration.pyhyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/python_recursion.cpython-311.json ' python3 benchmarks/fibonacci_sequence/__pycache__/python_recursion.cpython-311.pyc '
# TIMEOUT!
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/python_iteration.cpython-311.json ' python3 benchmarks/fibonacci_sequence/__pycache__/python_iteration.cpython-311.pyc ' RESULTADO :
Referência 1: benchmarks python3/fibonacci_sequence/ pycache /python_iteration.cpython-311.pyc
Tempo (média ± σ): 16.584,6 µs ± 761,5 µs [Usuário: 11.451,8 µs, Sistema: 3.813,3 µs]
Faixa (mín… máx.): 15.592,0 µs… 20.953,2 µs 100 execuções
fn fibonacci_recursion ( n : Int) -> Int:
return n if n < 2 else fibonacci_recursion(n - 1 ) + fibonacci_recursion(n - 2 )
fn main ():
_ = fibonacci_recursion( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_recursion.json ' mojo run benchmarks/fibonacci_sequence/mojo_recursion.mojo 'RESULTADO: TIMEOUT, cancelei o cálculo após 1m
fn fibonacci_iteration ( n : Int) -> Int:
var a : Int = 0
var b : Int = 1
for _ in range (n):
a = b
b = a + b
return a
fn main ():
_ = fibonacci_iteration( 100 )hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_iteration.json ' mojo run benchmarks/fibonacci_sequence/mojo_iteration.mojo ' RESULTADO :
Referência 1: mojo run benchmarks/fibonacci_sequence/mojo_iteration.mojo
Tempo (média ± σ): 43.852,7 µs ± 1.353,5 µs [Usuário: 38.156,0 µs, Sistema: 10.407,3 µs]
Faixa (mín… máx): 42.033,6 µs… 49.357,3 µs 100 execuções
mojo build benchmarks/fibonacci_sequence/mojo_recursion.mojo
mojo build benchmarks/fibonacci_sequence/mojo_iteration.mojohyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_recursion.exe.json ' ./benchmarks/fibonacci_sequence/mojo_recursion '
# TIMEOUT!
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/mojo_iteration.exe.json ' ./benchmarks/fibonacci_sequence/mojo_iteration ' RESULTADO :
Referência 1: ./benchmarks/fibonacci_sequence/mojo_iteration
Tempo (média ± σ): 934,6 µs ± 468,9 µs [Usuário: 409,8 µs, Sistema: 247,8 µs]
Faixa (mín… máx.): 552,7 µs… 4522,9 µs 100 execuções
def fibonacci_recursion(n):
return n if n < 2 else fibonacci_recursion(n - 1) + fibonacci_recursion(n - 2)
fibonacci_recursion(100)
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/codon_recursion.json ' codon run --release benchmarks/fibonacci_sequence/codon_recursion.codon 'RESULTADO: TIMEOUT, cancelei o cálculo após 1m
def fibonacci_iteration(n):
a, b = 0, 1
for _ in range(n):
a, b = b, a+b
return a
fibonacci_iteration(100)
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/codon_iteration.json ' codon run --release benchmarks/fibonacci_sequence/codon_iteration.codon ' RESULTADO :
Referência 1: codon run --release benchmarks/fibonacci_sequence/codon_iteration.codon
Tempo (média ± σ): 628.060,1 µs ± 10.430,5 µs [Usuário: 584.524,3 µs, Sistema: 39.358,5 µs]
Faixa (mín… máx.): 612742,5 µs… 662716,9 µs 100 execuções
codon build --release -exe benchmarks/fibonacci_sequence/codon_recursion.codon
codon build --release -exe benchmarks/fibonacci_sequence/codon_iteration.codonhyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json codon_recursion.exe.json ' ./benchmarks/fibonacci_sequence/codon_recursion '
# TIMEOUT!
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/codon_iteration.exe.json ' ./benchmarks/fibonacci_sequence/codon_iteration ' RESULTADO :
Referência 1: ./benchmarks/fibonacci_sequence/codon_iteration
Tempo (média ± σ): 2732,7 µs ± 1145,5 µs [Usuário: 1466,0 µs, Sistema: 1061,5 µs]
Faixa (mín… máx): 2.036,6 µs… 13.236,3 µs 100 execuções
fn fibonacci_recursive ( n : i64 ) -> i64 {
if n < 2 {
return n ;
}
return fibonacci_recursive ( n - 1 ) + fibonacci_recursive ( n - 2 ) ;
}
fn main ( ) {
let _ = fibonacci_recursive ( 100 ) ;
} rustc -C opt-level=3 benchmarks/fibonacci_sequence/rust_recursion.rs -o benchmarks/fibonacci_sequence/rust_recursion
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/rust_recursion.json ' ./benchmarks/fibonacci_sequence/rust_recursion 'RESULTADO: TIMEOUT, cancelei o cálculo após 1m
fn fibonacci_iteration ( n : usize ) -> usize {
let mut a = 1 ;
let mut b = 1 ;
for _ in 1 ..n {
let old = a ;
a = b ;
b += old ;
}
b
}
fn main ( ) {
let _ = fibonacci_iteration ( 100 ) ;
} rustc -C opt-level=3 benchmarks/fibonacci_sequence/rust_iteration.rs -o benchmarks/fibonacci_sequence/rust_iteration
hyperfine --warmup 10 -r 100 --time-unit=microsecond --export-json benchmarks/fibonacci_sequence/rust_iteration.json ' ./benchmarks/fibonacci_sequence/rust_iteration ' RESULTADO :
Referência 1: ./benchmarks/fibonacci_sequence/rust_iteration
Tempo (média ± σ): 848,9 µs ± 283,2 µs [Usuário: 371,8 µs, Sistema: 261,4 µs]
Faixa (mín… máx): 525,9 µs… 2607,3 µs 100 execuções
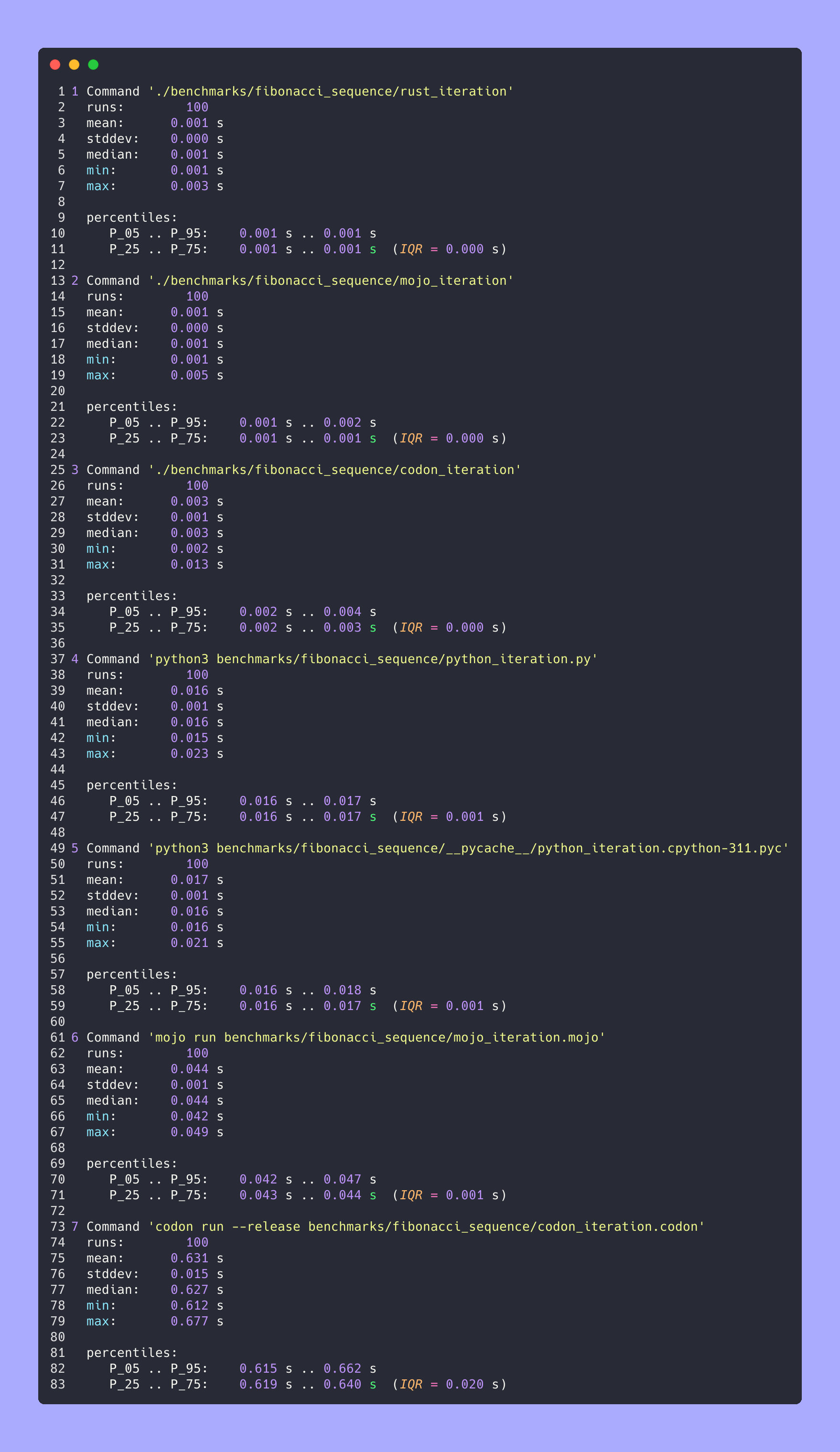
# Merge all JSON files into benchmarks.json
python3 benchmarks/hyperfine-scripts/merge_jsons.py benchmarks/fibonacci_sequence/ benchmarks/fibonacci_sequence/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot2.py benchmarks/fibonacci_sequence/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot3.py benchmarks/fibonacci_sequence/benchmarks.json
python3 benchmarks/hyperfine-scripts/advanced_statistics.py benchmarks/fibonacci_sequence/benchmarks.json > benchmarks/fibonacci_sequence/benchmarks.json.md
silicon benchmarks/fibonacci_sequence/benchmarks.json.md -l python -o benchmarks/fibonacci_sequence/benchmarks.json.md.pngEstatísticas avançadas
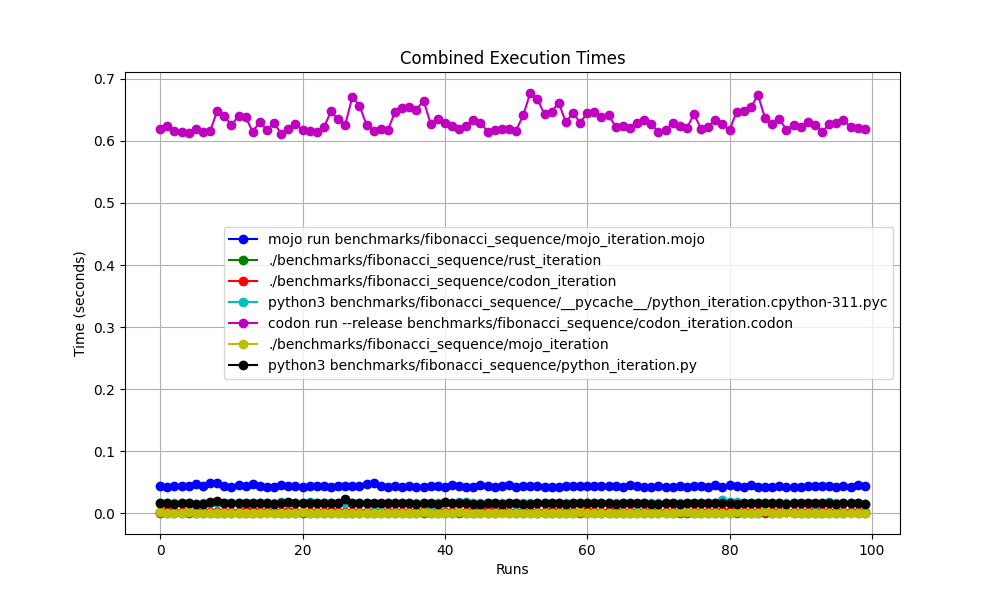
Todos juntos
Ampliado
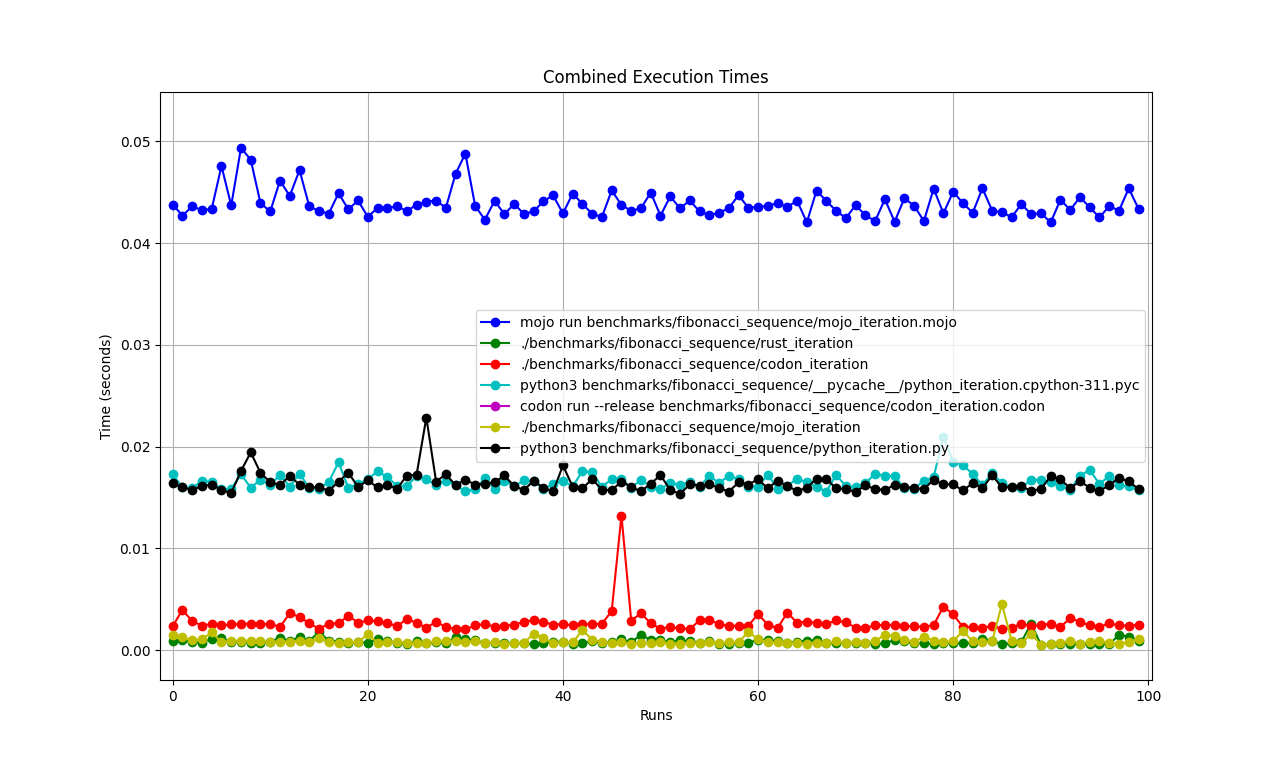
Detalhado um por um
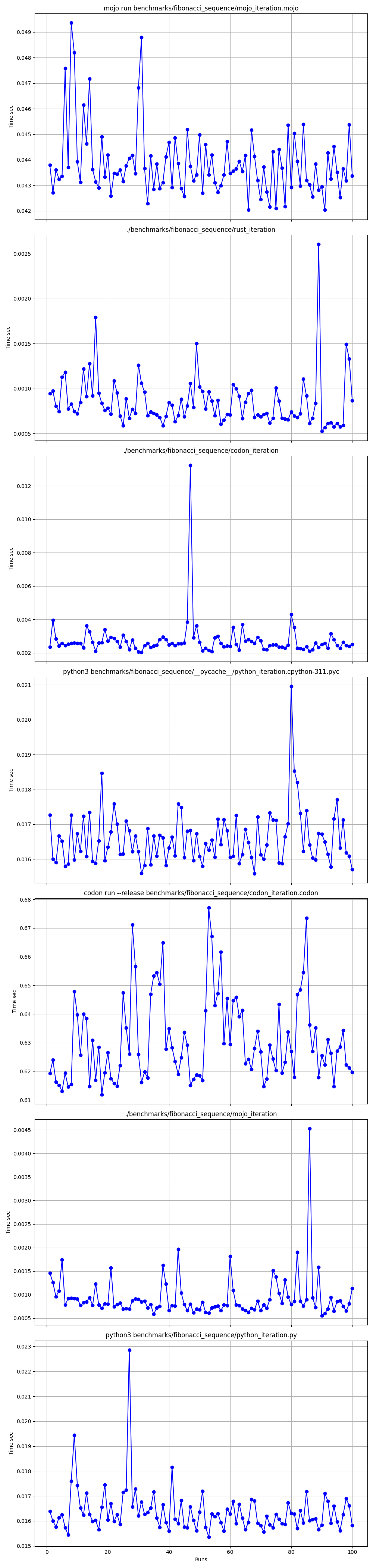
Lugares
Mas aqui há muitas perguntas:
mojo run tão devagar?codon run --release tão lento?run mais rápido que o Mojo/Codon?Então, podemos dizer que o Mojo é tão rápido quanto o Rust no Mac!
Vamos encontrar o Conjunto Mandelbrot onde
LARGURA = 960
ALTURA = 960
MAX_ITERS = 200
MIN_X = -2,0
MAX_X = 0,6
MIN_Y = -1,5
MAX_Y = 1,5
def mandelbrot_kernel ( c ):
z = c
for i in range ( MAX_ITERS ):
z = z * z + c # Change this for different Multibrot sets (e.g., 2 for Mandelbrot)
if z . real * z . real + z . imag * z . imag > 4 :
return i
return MAX_ITERS
def compute_mandelbrot ():
t = [[ 0 for _ in range ( WIDTH )] for _ in range ( HEIGHT )] # Pixel matrix
dx = ( MAX_X - MIN_X ) / WIDTH
dy = ( MAX_Y - MIN_Y ) / HEIGHT
for row in range ( HEIGHT ):
for col in range ( WIDTH ):
t [ row ][ col ] = mandelbrot_kernel ( complex ( MIN_X + col * dx , MIN_Y + row * dy ))
return t
compute_mandelbrot ()python3 -m compileall benchmarks/multibrot_set/multibrot.py
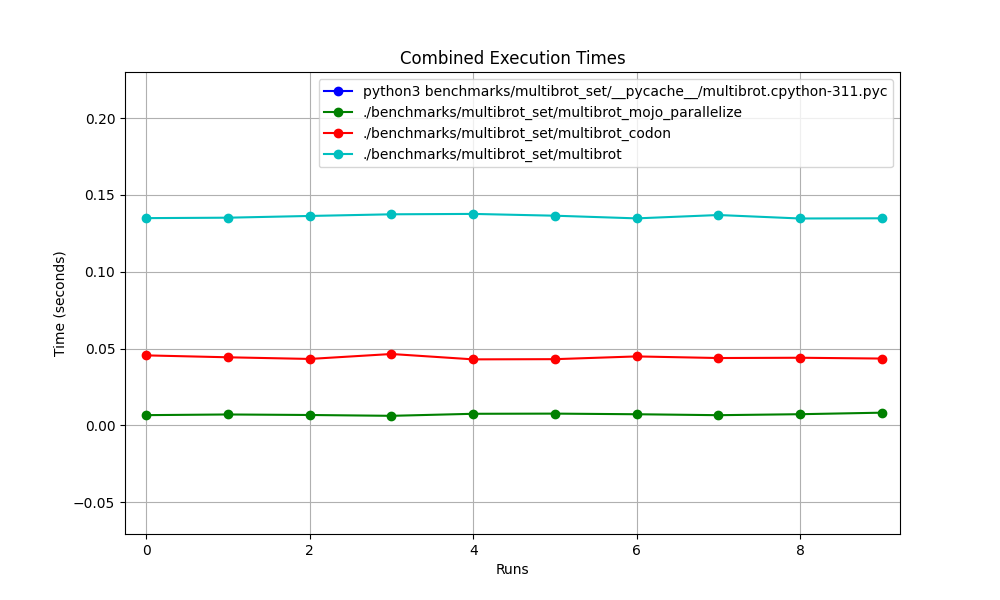
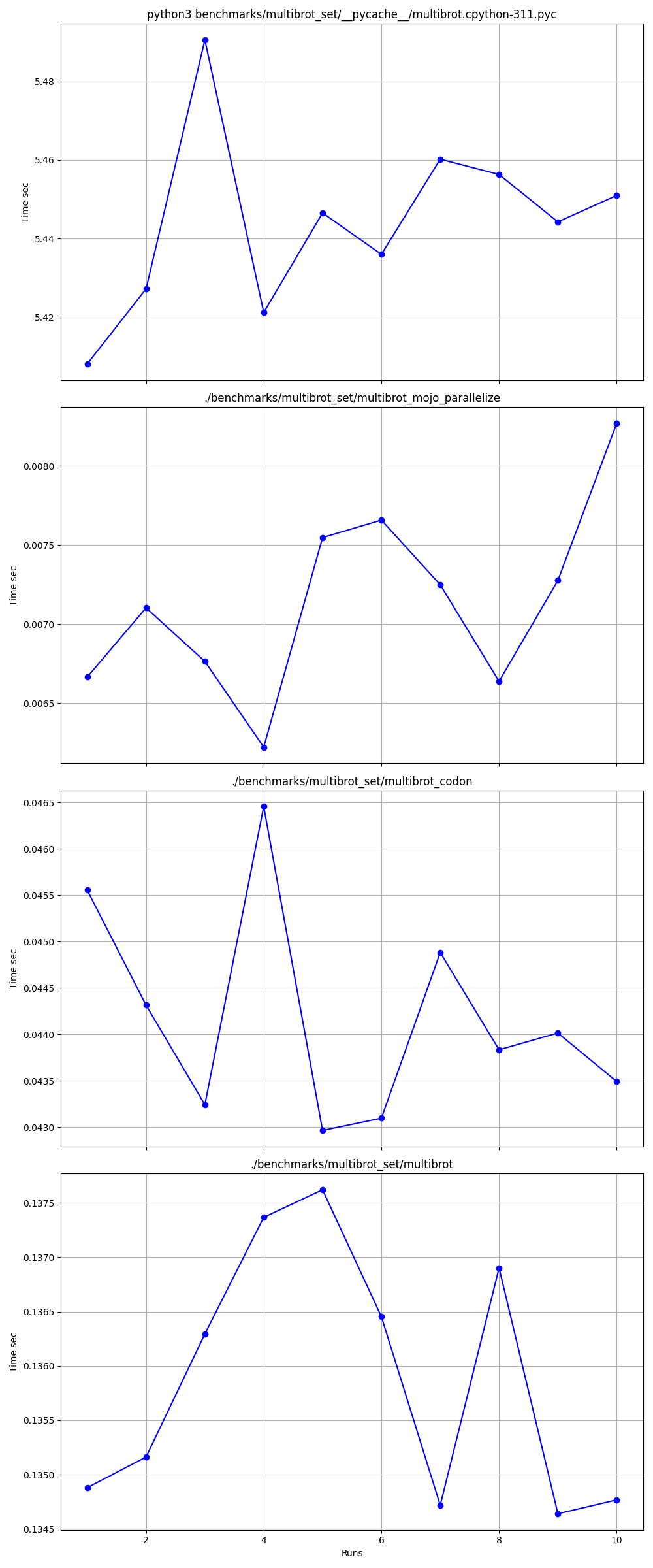
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot.cpython-311.json ' python3 benchmarks/multibrot_set/__pycache__/multibrot.cpython-311.pyc ' RESULTADO :
Referência 1: benchmarks python3/multibrot_set/ pycache /multibrot.cpython-311.pyc
Tempo (média ± σ): 5444155,4 µs ± 23059,7 µs [Usuário: 5419790,1 µs, Sistema: 18131,3 µs]
Faixa (mín… máx.): 5408155,3 µs… 5490548,4 µs 10 execuções
Versão Mojo sem otimização.
# Compute the number of steps to escape.
def multibrot_kernel ( c : ComplexFloat64) -> Int:
z = c
for i in range ( MAX_ITERS ):
z = z * z + c # Change this for different Multibrot sets (e.g., 2 for Mandelbrot)
if z.squared_norm() > 4 :
return i
return MAX_ITERS
def compute_multibrot () -> Tensor[FloatType]:
# create a matrix. Each element of the matrix corresponds to a pixel
t = Tensor[FloatType]( HEIGHT , WIDTH )
dx = ( MAX_X - MIN_X ) / WIDTH
dy = ( MAX_Y - MIN_Y ) / HEIGHT
y = MIN_Y
for row in range ( HEIGHT ):
x = MIN_X
for col in range ( WIDTH ):
t[Index(row, col)] = multibrot_kernel(ComplexFloat64(x, y))
x += dx
y += dy
return t
_ = compute_multibrot()mojo build benchmarks/multibrot_set/multibrot.mojo
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot.exe.json ' ./benchmarks/multibrot_set/multibrot ' RESULTADO :
Referência 1: ./benchmarks/multibrot_set/multibrot
Tempo (média ± σ): 135880,5 µs ± 1175,4 µs [Usuário: 133309,3 µs, Sistema: 1700,1 µs]
Faixa (mín… máx.): 134.639,9 µs… 137.621,4 µs 10 execuções
fn mandelbrot_kernel_SIMD [
simd_width : Int
]( c : ComplexSIMD[float_type, simd_width]) -> SIMD [float_type, simd_width]:
""" A vectorized implementation of the inner mandelbrot computation. """
let cx = c.re
let cy = c.im
var x = SIMD [float_type, simd_width]( 0 )
var y = SIMD [float_type, simd_width]( 0 )
var y2 = SIMD [float_type, simd_width]( 0 )
var iters = SIMD [float_type, simd_width]( 0 )
var t : SIMD [DType.bool, simd_width] = True
for i in range ( MAX_ITERS ):
if not t.reduce_or():
break
y2 = y * y
y = x.fma(y + y, cy)
t = x.fma(x, y2) <= 4
x = x.fma(x, cx - y2)
iters = t.select(iters + 1 , iters)
return iters
fn compute_multibrot_parallelized () -> Tensor[float_type]:
let t = Tensor[float_type](height, width)
@parameter
fn worker ( row : Int):
let scale_x = (max_x - min_x) / width
let scale_y = (max_y - min_y) / height
@parameter
fn compute_vector [ simd_width : Int]( col : Int):
""" Each time we operate on a `simd_width` vector of pixels. """
let cx = min_x + (col + iota[float_type, simd_width]()) * scale_x
let cy = min_y + row * scale_y
let c = ComplexSIMD[float_type, simd_width](cx, cy)
t.data().simd_store[simd_width](
row * width + col, mandelbrot_kernel_SIMD[simd_width](c)
)
# Vectorize the call to compute_vector where call gets a chunk of pixels.
vectorize[simd_width, compute_vector](width)
# Parallelized
parallelize[worker](height, height)
return t
def main ():
_ = compute_multibrot_parallelized()mojo build benchmarks/multibrot_set/multibrot_mojo_parallelize.mojo
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot_mojo_parallelize.exe.json ' ./benchmarks/multibrot_set/multibrot_mojo_parallelize ' RESULTADO :
Referência 1: ./benchmarks/multibrot_set/multibrot_mojo_parallelize
Tempo (média ± σ): 7139,4 µs ± 596,4 µs [Usuário: 36535,2 µs, Sistema: 6670,1 µs]
Faixa (mín… máx.): 6.222,6 µs… 8.269,7 µs 10 execuções
def mandelbrot_kernel(c):
z = c
for i in range(MAX_ITERS):
z = z * z + c # Change this for different Multibrot sets (e.g., 2 for Mandelbrot)
if z.real * z.real + z.imag * z.imag > 4:
return i
return MAX_ITERS
def compute_mandelbrot():
t = [[0 for _ in range(WIDTH)] for _ in range(HEIGHT)] # Pixel matrix
dx = (MAX_X - MIN_X) / WIDTH
dy = (MAX_Y - MIN_Y) / HEIGHT
@par(collapse=2)
for row in range(HEIGHT):
for col in range(WIDTH):
t[row][col] = mandelbrot_kernel(complex(MIN_X + col * dx, MIN_Y + row * dy))
return t
compute_mandelbrot()
Para execução de teste ou plotagem (descomente o código no arquivo)
CODON_PYTHON=/opt/homebrew/opt/[email protected]/Frameworks/Python.framework/Versions/3.11/lib/libpython3.11.dylib codon run --release benchmarks/multibrot_set/multibrot.codonConstruir e executar
codon build --release -exe benchmarks/multibrot_set/multibrot.codon -o benchmarks/multibrot_set/multibrot_codon
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot_codon.json ' ./benchmarks/multibrot_set/multibrot_codon ' RESULTADO :
Referência 1: ./benchmarks/multibrot_set/multibrot_codon
Tempo (média ± σ): 44184,7 µs ± 1142,0 µs [Usuário: 248773,9 µs, Sistema: 72935,3 µs]
Faixa (mín… máx.): 42.963,8 µs… 46.456,2 µs 10 execuções
codon build --release -exe benchmarks/multibrot_set/multibrot_codon_par.codon -o benchmarks/multibrot_set/multibrot_codon_par
hyperfine --warmup 10 -r 10 --time-unit=microsecond --export-json benchmarks/multibrot_set/multibrot_codon_par.json ' ./benchmarks/multibrot_set/multibrot_codon_par ' # Merge all JSON files into benchmarks.json
python3 benchmarks/hyperfine-scripts/merge_jsons.py benchmarks/multibrot_set/ benchmarks/multibrot_set/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot2.py benchmarks/multibrot_set/benchmarks.json
python3 benchmarks/hyperfine-scripts/plot3.py benchmarks/multibrot_set/benchmarks.json
python3 benchmarks/hyperfine-scripts/advanced_statistics.py benchmarks/multibrot_set/benchmarks.json > benchmarks/multibrot_set/benchmarks.json.md
silicon benchmarks/multibrot_set/benchmarks.json.md -l python -o benchmarks/multibrot_set/benchmarks.json.md.pngEstatísticas avançadas
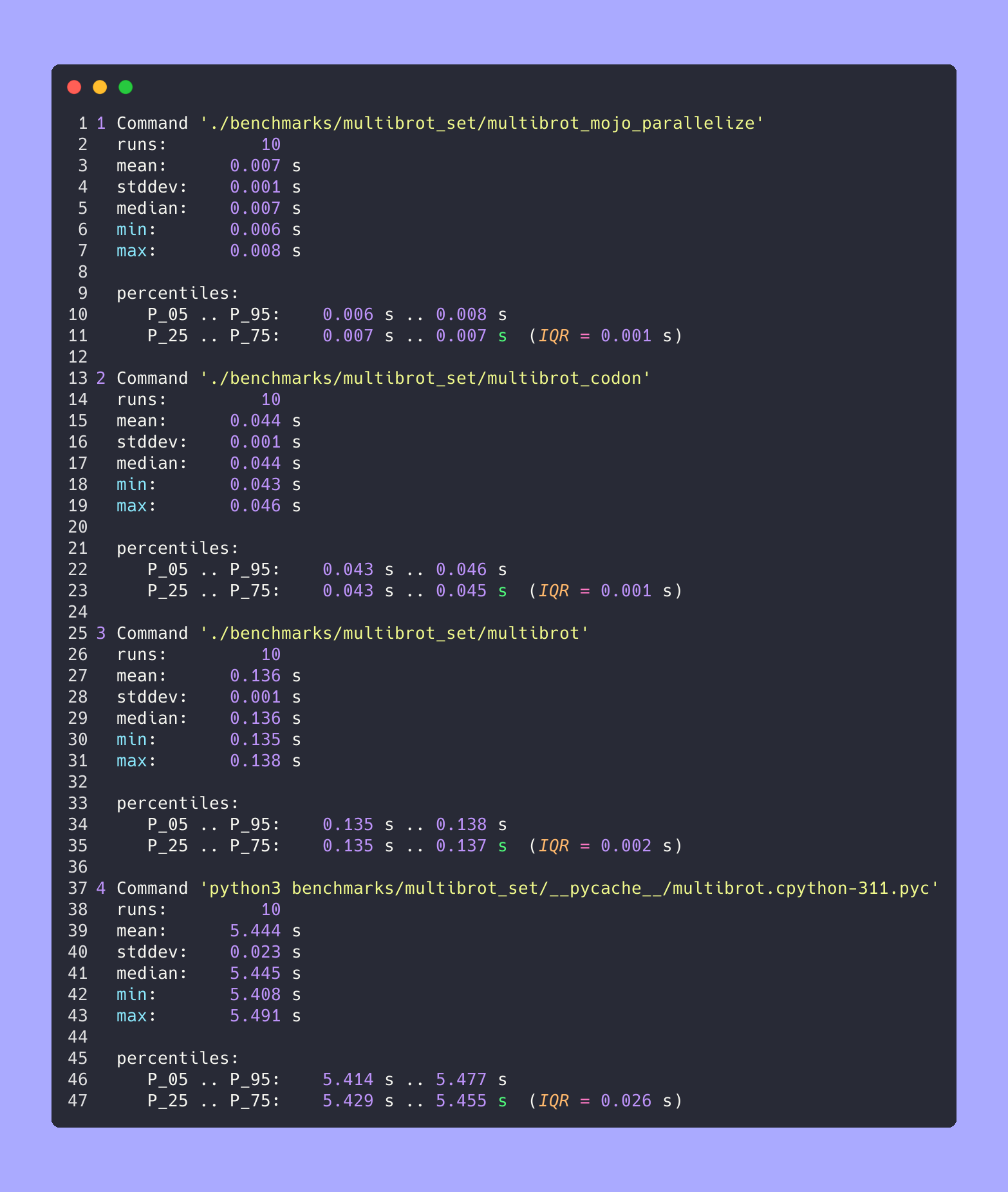
Todos juntos
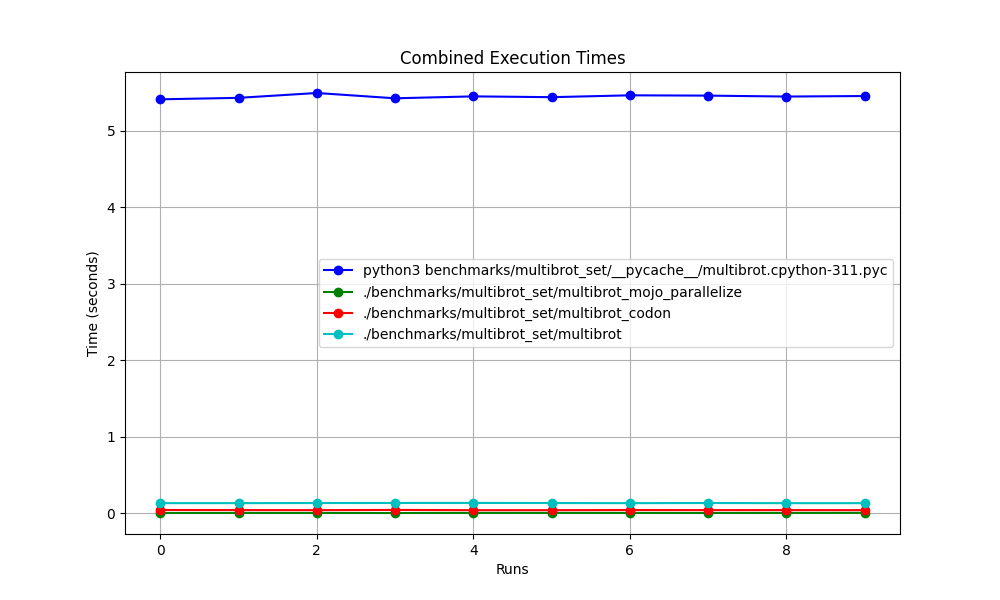
Ampliado
Detalhado um por um
Lugares
Links:
Mandelbrot = Multibrot com power = 2
z = z ** power + c # You can change this for different setAlmofada embutida ImagingEffectMandelbrot
Versão Exaloop Codon de Mandelbrot
Versão modular Mojo de Mandelbrot
Complexo Mojo squared_norm
MatplotlibMandelbrot
Na ciência da computação, o algoritmo de pesquisa binária, também conhecido como pesquisa de meio intervalo, pesquisa logarítmica ou corte binário, é um algoritmo de pesquisa que encontra a posição de um valor alvo dentro de uma matriz classificada.
Vamos fazer alguns códigos com Python, Mojo, Swift, V, Julia, Nim, Zig.
Obs: Para as versões Python e Mojo , deixo algumas otimizações e torno o código semelhante para medição e comparação.
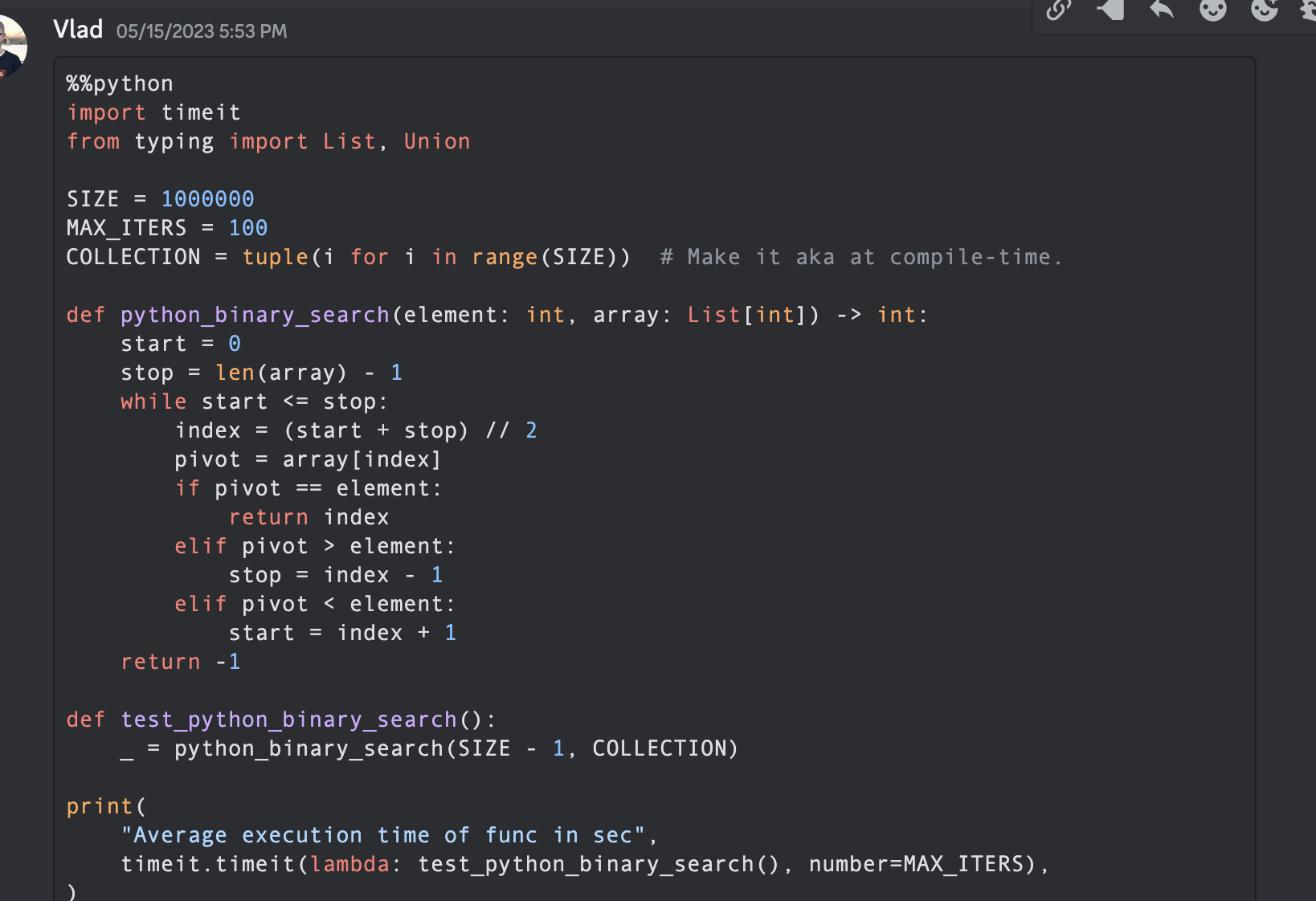
from typing import List
import timeit
SIZE = 1000000
MAX_ITERS = 100
COLLECTION = tuple ( i for i in range ( SIZE )) # Make it aka at compile-time.
def python_binary_search ( element : int , array : List [ int ]) -> int :
start = 0
stop = len ( array ) - 1
while start <= stop :
index = ( start + stop ) // 2
pivot = array [ index ]
if pivot == element :
return index
elif pivot > element :
stop = index - 1
elif pivot < element :
start = index + 1
return - 1
def test_python_binary_search ():
_ = python_binary_search ( SIZE - 1 , COLLECTION )
print (
"Average execution time of func in sec" ,
timeit . timeit ( lambda : test_python_binary_search (), number = MAX_ITERS ),
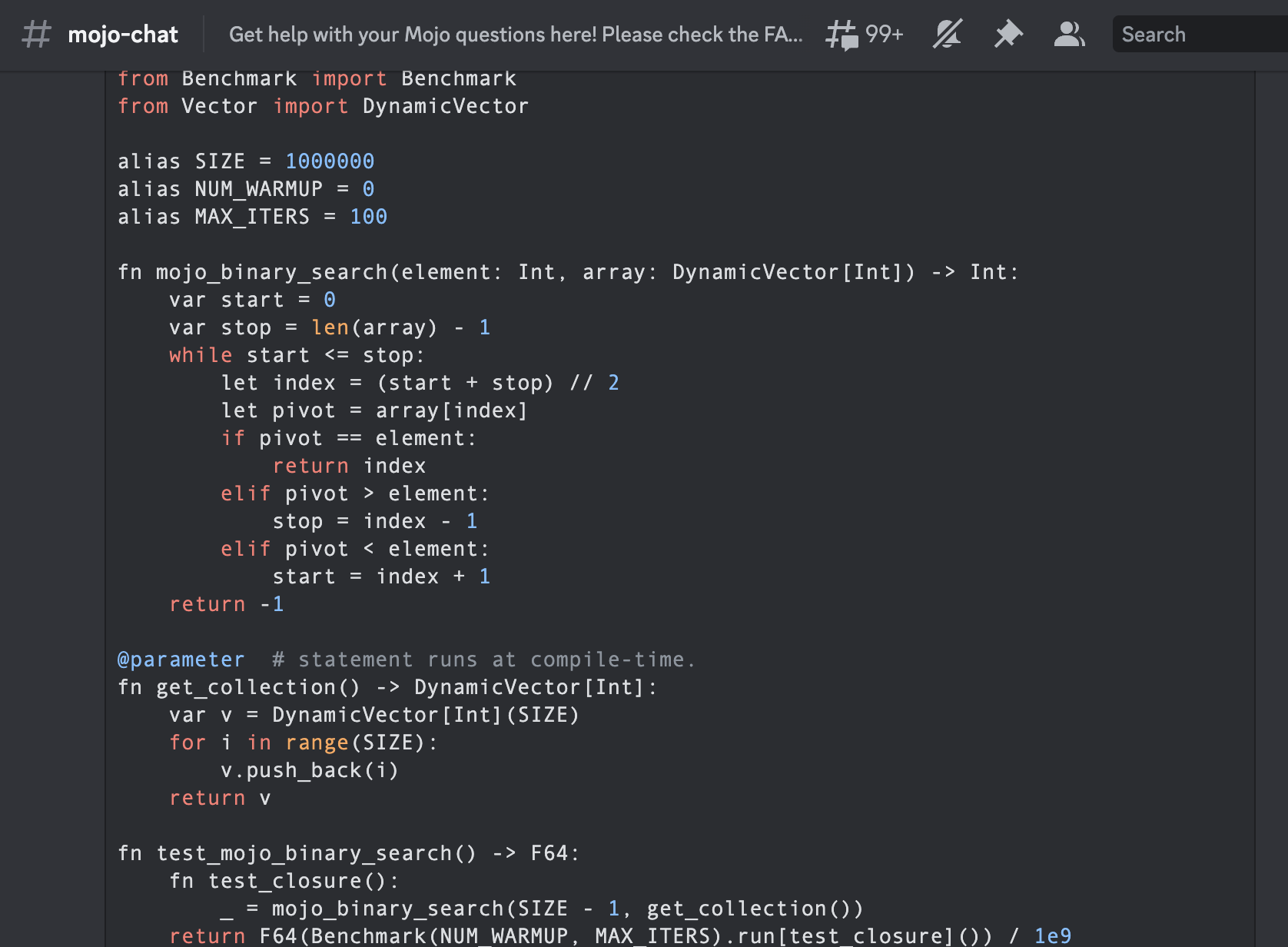
) """Implements basic binary search."""
from Benchmark import Benchmark
from Vector import DynamicVector
alias SIZE = 1000000
alias NUM_WARMUP = 0
alias MAX_ITERS = 100
fn mojo_binary_search ( element : Int , array : DynamicVector [ Int ]) - > Int :
var start = 0
var stop = len ( array ) - 1
while start <= stop :
let index = ( start + stop ) // 2
let pivot = array [ index ]
if pivot == element :
return index
elif pivot > element :
stop = index - 1
elif pivot < element :
start = index + 1
return - 1
@ parameter # statement runs at compile-time.
fn get_collection () - > DynamicVector [ Int ]:
var v = DynamicVector [ Int ]( SIZE )
for i in range ( SIZE ):
v . push_back ( i )
return v
fn test_mojo_binary_search () - > F64 :
fn test_closure ():
_ = mojo_binary_search ( SIZE - 1 , get_collection ())
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ test_closure ]()) / 1e9
print (
"Average execution time of func in sec " ,
test_mojo_binary_search (),
)É a primeira pesquisa binária escrita na comunidade Mojoby (@ego) e postada no mojo-chat.
func binarySearch ( items : [ Int ] , elem : Int ) -> Int {
var low = 0
var high = items . count - 1
var mid = 0
while low <= high {
mid = Int ( ( high + low ) / 2 )
if items [ mid ] < elem {
low = mid + 1
} else if items [ mid ] > elem {
high = mid - 1
} else {
return mid
}
}
return - 1
}
let items = [ 1 , 2 , 3 , 4 , 0 ] . sorted ( )
let res = binarySearch ( items : items , elem : 4 )
print ( res ) function binarysearch (lst :: Vector{T} , val :: T ) where T
low = 1
high = length (lst)
while low ≤ high
mid = (low + high) ÷ 2
if lst[mid] > val
high = mid - 1
elseif lst[mid] < val
low = mid + 1
else
return mid
end
end
return 0
end proc binarySearch [T](a: openArray [T], key: T): int =
var b = len (a)
while result < b:
var mid = ( result + b) div 2
if a[mid] < key: result = mid + 1
else : b = mid
if result >= len (a) or a[ result ] != key: result = - 1
let res = @ [ 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 12 , 14 , 16 , 18 , 20 , 22 , 25 , 27 , 30 ]
echo binarySearch (res, 10 ) const std = @import ( "std" );
fn binarySearch ( comptime T : type , arr : [] const T , target : T ) ? usize {
var lo : usize = 0 ;
var hi : usize = arr . len - 1 ;
while ( lo <= hi ) {
var mid : usize = ( lo + hi ) / 2 ;
if ( arr [ mid ] == target ) {
return mid ;
} else if ( arr [ mid ] < target ) {
lo = mid + 1 ;
} else {
hi = mid - 1 ;
}
}
return null ;
} fn binary_search (a [] int , value int ) int {
mut low := 0
mut high := a.len - 1
for low < = high {
mid := (low + high) / 2
if a[mid] > value {
high = mid - 1
} else if a[mid] < value {
low = mid + 1
} else {
return mid
}
}
return - 1
}
fn main () {
search_list := [ 1 , 2 , 3 , 5 , 6 , 7 , 8 , 9 , 10 ]
println ( binary_search (search_list, 9 ))
} fn breadth_first_search_path (graph map [ string ][] string , vertex string , target string ) [] string {
mut path := [] string {}
mut visited := [] string {init: vertex}
mut queue := [][][] string {}
queue << [[vertex], path]
for queue.len > 0 {
mut idx := queue.len - 1
node := queue[idx][ 0 ][ 0 ]
path = queue[idx][ 1 ]
queue. delete (idx)
if node == target {
path << node
return path
}
for child in graph[node] {
mut tmp := path. clone ()
if child ! in visited {
visited << child
tmp << node
queue << [[child], tmp]
}
}
}
return path
}
fn main () {
graph := map {
'A' : [ 'B' , 'C' ]
'B' : [ 'A' , 'D' , 'E' ]
'C' : [ 'A' , 'F' ]
'D' : [ 'B' ]
'E' : [ 'B' , 'F' ]
'F' : [ 'C' , 'E' ]
}
println ( 'Graph: $graph ' )
path := breadth_first_search_path (graph, 'A' , 'F' )
println ( 'The shortest path from node A to node F is: $path ' )
assert path == [ 'A' , 'C' , 'F' ]
} import timeit
SIZE = 100
MAX_ITERS = 100
def _fizz_buzz (): # Make it aka at compile-time.
res = []
for n in range ( 1 , SIZE + 1 ):
if ( n % 3 == 0 ) and ( n % 5 == 0 ):
s = "FizzBuzz"
elif n % 3 == 0 :
s = "Fizz"
elif n % 5 == 0 :
s = "Buzz"
else :
s = str ( n )
res . append ( s )
return res
DATA = _fizz_buzz ()
def fizz_buzz ():
print ( " n " . join ( DATA ))
print (
"Average execution time of Python func in sec" ,
timeit . timeit ( lambda : fizz_buzz (), number = MAX_ITERS ),
)
# Average execution time of Python func in sec 0.005334990004485007 ( import '[java.io OutputStream])
( require '[clojure.java.io :as io])
( def devnull ( io/writer ( OutputStream/nullOutputStream )))
( defmacro timeit [n expr]
`(with-out-str ( time
( dotimes [_# ~( Math/pow 1 n)]
( binding [*out* devnull]
~expr)))))
( defmacro macro-fizz-buzz [n]
`( fn []
( print
~( apply str
( for [i ( range 1 ( inc n))]
( cond
( zero? ( mod i 15 )) " FizzBuzz n "
( zero? ( mod i 5 )) " Buzz n "
( zero? ( mod i 3 )) " Fizz n "
:else ( str i " n " )))))))
( print ( timeit 100 ( macro-fizz-buzz 100 )))
; ; "Elapsed time: 0.175486 msecs"
; ; Average execution time of Clojure func in sec 0.000175486 seconds from String import String
from Benchmark import Benchmark
alias SIZE = 100
alias NUM_WARMUP = 0
alias MAX_ITERS = 100
@ parameter # statement runs at compile-time.
fn _fizz_buzz () - > String :
var res : String = ""
for n in range ( 1 , SIZE + 1 ):
if ( n % 3 == 0 ) and ( n % 5 == 0 ):
res += "FizzBuzz"
elif n % 3 == 0 :
res += "Fizz"
elif n % 5 == 0 :
res += "Buzz"
else :
res += String ( n )
res += " n "
return res
fn fizz_buzz ():
print ( _fizz_buzz ())
fn run_benchmark () - > F64 :
fn _closure ():
_ = fizz_buzz ()
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ _closure ]()) / 1e9
print (
"Average execution time of func in sec " ,
run_benchmark (),
)
# Average execution time of func in sec 0.000104 É o primeiro buzz Fizz escrito em Mojo pela comunidade (@Ego).
Usaremos o algoritmo da referência bem conhecida para o livro de algoritmos Introdução aos Algoritmos A3
A sua fama levou ao uso comum da abreviatura “ CLRS ” (Cormen, Leiserson, Rivest, Stein), ou, na primeira edição, “ CLR ” (Cormen, Leiserson, Rivest).
Capítulo 2 "2.3.1 A abordagem de dividir para conquistar".
% % python
import timeit
MAX_ITERS = 100
def merge ( A , p , q , r ):
n1 = q - p + 1
n2 = r - q
L = [ None ] * n1
R = [ None ] * n2
for i in range ( n1 ):
L [ i ] = A [ p + i ]
for j in range ( n2 ):
R [ j ] = A [ q + 1 + j ]
i = 0
j = 0
k = p
while i < n1 and j < n2 :
if L [ i ] <= R [ j ]:
A [ k ] = L [ i ]
i += 1
else :
A [ k ] = R [ j ]
j += 1
k += 1
while i < n1 :
A [ k ] = L [ i ]
i += 1
k += 1
while j < n2 :
A [ k ] = R [ j ]
j += 1
k += 1
def merge_sort ( A , p , r ):
if p < r :
q = ( p + r ) // 2
merge_sort ( A , p , q )
merge_sort ( A , q + 1 , r )
merge ( A , p , q , r )
def run_benchmark_merge_sort ():
A = [ 14 , 72 , 50 , 83 , 18 , 20 , 13 , 30 , 17 , 87 , 94 , 65 , 24 , 99 , 70 , 44 , 5 , 12 , 74 , 6 , 32 , 63 , 91 , 88 , 43 , 54 , 27 , 39 , 64 , 78 , 29 , 62 , 58 , 59 , 61 , 89 , 2 , 15 , 41 , 9 , 93 , 90 , 23 , 96 , 73 , 14 , 8 , 28 , 11 , 42 , 77 , 34 , 52 , 80 , 57 , 84 , 21 , 60 , 66 , 40 , 7 , 85 , 47 , 98 , 97 , 35 , 82 , 36 , 49 , 3 , 68 , 22 , 67 , 81 , 56 , 71 , 4 , 38 , 69 , 95 , 16 , 48 , 1 , 31 , 75 , 19 , 10 , 25 , 79 , 45 , 76 , 33 , 53 , 55 , 46 , 37 , 26 , 51 , 92 , 86 ]
merge_sort ( A , 0 , len ( A ) - 1 )
print (
"Average execution time of Python `merge_sort` in sec" ,
timeit . timeit ( lambda : run_benchmark_merge_sort (), number = MAX_ITERS ),
)
# Average execution time of Python `merge_sort` in sec 0.019136679999064654
def run_benchmark_sort ():
A = [ 14 , 72 , 50 , 83 , 18 , 20 , 13 , 30 , 17 , 87 , 94 , 65 , 24 , 99 , 70 , 44 , 5 , 12 , 74 , 6 , 32 , 63 , 91 , 88 , 43 , 54 , 27 , 39 , 64 , 78 , 29 , 62 , 58 , 59 , 61 , 89 , 2 , 15 , 41 , 9 , 93 , 90 , 23 , 96 , 73 , 14 , 8 , 28 , 11 , 42 , 77 , 34 , 52 , 80 , 57 , 84 , 21 , 60 , 66 , 40 , 7 , 85 , 47 , 98 , 97 , 35 , 82 , 36 , 49 , 3 , 68 , 22 , 67 , 81 , 56 , 71 , 4 , 38 , 69 , 95 , 16 , 48 , 1 , 31 , 75 , 19 , 10 , 25 , 79 , 45 , 76 , 33 , 53 , 55 , 46 , 37 , 26 , 51 , 92 , 86 ]
A . sort ()
print (
"Average execution time of Python builtin `sort` in sec" ,
timeit . timeit ( lambda : run_benchmark_sort (), number = MAX_ITERS ),
)
# Average execution time of Python builtin `sort` in sec 0.00019922800129279494 from Benchmark import Benchmark
from Vector import DynamicVector
from StaticTuple import StaticTuple
from Sort import sort
alias NUM_WARMUP = 0
alias MAX_ITERS = 100
fn merge ( inout A : DynamicVector [ Int ], p : Int , q : Int , r : Int ):
let n1 = q - p + 1
let n2 = r - q
var L = DynamicVector [ Int ]( n1 )
var R = DynamicVector [ Int ]( n2 )
for i in range ( n1 ):
L [ i ] = A [ p + i ]
for j in range ( n2 ):
R [ j ] = A [ q + 1 + j ]
var i = 0
var j = 0
var k = p
while i < n1 and j < n2 :
if L [ i ] <= R [ j ]:
A [ k ] = L [ i ]
i += 1
else :
A [ k ] = R [ j ]
j += 1
k += 1
while i < n1 :
A [ k ] = L [ i ]
i += 1
k += 1
while j < n2 :
A [ k ] = R [ j ]
j += 1
k += 1
fn merge_sort ( inout A : DynamicVector [ Int ], p : Int , r : Int ):
if p < r :
let q = ( p + r ) // 2
merge_sort ( A , p , q )
merge_sort ( A , q + 1 , r )
merge ( A , p , q , r )
@ parameter
fn create_vertor () - > DynamicVector [ Int ]:
let st = StaticTuple [ MAX_ITERS , Int ]( 14 , 72 , 50 , 83 , 18 , 20 , 13 , 30 , 17 , 87 , 94 , 65 , 24 , 99 , 70 , 44 , 5 , 12 , 74 , 6 , 32 , 63 , 91 , 88 , 43 , 54 , 27 , 39 , 64 , 78 , 29 , 62 , 58 , 59 , 61 , 89 , 2 , 15 , 41 , 9 , 93 , 90 , 23 , 96 , 73 , 14 , 8 , 28 , 11 , 42 , 77 , 34 , 52 , 80 , 57 , 84 , 21 , 60 , 66 , 40 , 7 , 85 , 47 , 98 , 97 , 35 , 82 , 36 , 49 , 3 , 68 , 22 , 67 , 81 , 56 , 71 , 4 , 38 , 69 , 95 , 16 , 48 , 1 , 31 , 75 , 19 , 10 , 25 , 79 , 45 , 76 , 33 , 53 , 55 , 46 , 37 , 26 , 51 , 92 , 86 )
var v = DynamicVector [ Int ]( st . __len__ ())
for i in range ( st . __len__ ()):
v . push_back ( st [ i ])
return v
fn run_benchmark_merge_sort () - > F64 :
fn _closure ():
var A = create_vertor ()
merge_sort ( A , 0 , len ( A ) - 1 )
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ _closure ]()) / 1e9
print (
"Average execution time of Mojo `merge_sort` in sec " ,
run_benchmark_merge_sort (),
)
# Average execution time of Mojo `merge_sort` in sec 1.1345999999999999e-05
fn run_benchmark_sort () - > F64 :
fn _closure ():
var A = create_vertor ()
sort ( A )
return F64 ( Benchmark ( NUM_WARMUP , MAX_ITERS ). run [ _closure ]()) / 1e9
print (
"Average execution time of Mojo builtin `sort` in sec " ,
run_benchmark_sort (),
)
# Average execution time of Mojo builtin `sort` in sec 2.988e-06Você pode usá-lo como:
# Usage: merge_sort
var A = create_vertor ()
merge_sort ( A , 0 , len ( A ) - 1 )
print ( len ( A ))
print ( A [ 0 ], A [ 99 ]) Integrado from Sort import sort quicksort um pouco mais rápido que nossa implementação, mas podemos otimizá-lo profundamente na linguagem e como de costume com algoritmos =) e paradigmas de programação.
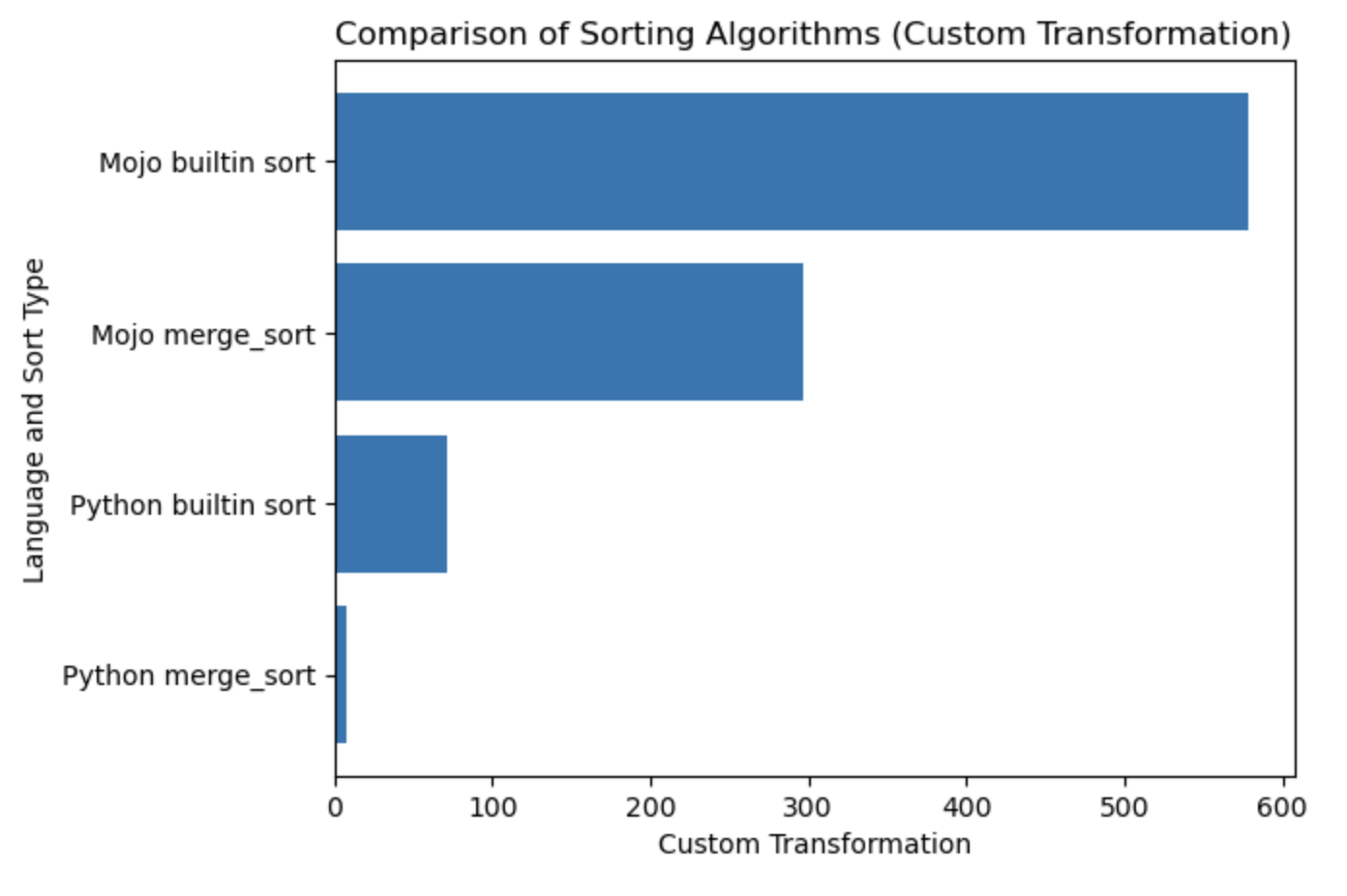
| Lang | segundo |
|---|---|
| Merge_sort em Python | 0,019136679 |
| Classificação interna do Python | 0,000199228 |
| Mojo merge_sort | 0,000011346 |
| Classificação interna do Mojo | 0,000002988 |
Vamos construir um gráfico para esta tabela.
#%%python
import matplotlib . pyplot as plt
import numpy as np
languages = [ 'Python merge_sort' , 'Python builtin sort' , 'Mojo merge_sort' , 'Mojo builtin sort' ]
seconds = [ 0.019136679 , 0.000199228 , 0.000011346 , 0.000002988 ]
# Apply a custom transformation to the values
transformed_seconds = [ np . sqrt ( 1 / x ) for x in seconds ]
plt . barh ( languages , transformed_seconds )
plt . xlabel ( 'Custom Transformation' )
plt . ylabel ( 'Language and Sort Type' )
plt . title ( 'Comparison of Sorting Algorithms (Custom Transformation)' )
plt . show ()Notas do enredo, mais é melhor e mais rápido.
Eu recomendo fortemente começar aqui HelloMojo e entender a parametrização de [parâmetros] e [expressões de parâmetros] aqui. Como neste exemplo:
fn concat [ len1 : Int , len2 : Int ]( lhs : MySIMD [ len1 ], rhs : MySIMD [ len2 ]) - > MySIMD [ len1 + len2 ]:
let result = MySIMD [ len1 + len2 ]()
for i in range ( len1 ):
result [ i ] = lhs [ i ]
for j in range ( len2 ):
result [ len1 + j ] = rhs [ j ]
return result
let a = MySIMD [ 2 ]( 1 , 2 )
let x = concat [ 2 , 2 ]( a , a )
x . dump () Tempo de compilação [Parâmetros]: fn concat[len1: Int, len2: Int] .
Tempo de execução (Args) : fn concat(lhs: MySIMD, rhs: MySIMD) .
Sintaxe dos parâmetros PEP695 entre colchetes [] .
Agora em Python:
def func ( a : _T , b : _T ) -> _T :
...Agora no Mojo:
def func [ T ]( a : T , b : T ) -> T :
... [Parâmetros] são nomeados e possuem tipos como valores normais em um programa Mojo, mas parameters[] são avaliados em tempo de compilação .
O programa de tempo de execução pode usar o valor de [parâmetros] - porque os parâmetros são resolvidos em tempo de compilação antes de serem necessários ao programa de tempo de execução - mas as expressões de parâmetro de tempo de compilação não podem usar valores de tempo de execução.
Self de PEP673
fn __sub__ ( self , rhs : Self ) - > Self :
let result = MySIMD [ size ]()
for i in range ( size ):
result [ i ] = self [ i ] - rhs [ i ]
return resultNos documentos você pode encontrar a palavra Campos, também conhecida como atributos de classe no Python.
Então, você os chama com dot .
from DType import DType
let bool_type = DType . bool from DType import DType
DType . si8 from DType import DType
from SIMD import SIMD , SI8
alias MY_SIMD_DType_si8 = SIMD [ DType . si8 , 1 ]
alias MY_SI8 = SI8
print ( MY_SIMD_DType_si8 == MY_SI8 )
# true from DType import DType
from SIMD import SIMD , SI8
from Vector import DynamicVector
from String import String
alias a = DynamicVector [ SIMD [ DType . si8 , 1 ]]
alias b = DynamicVector [ SI8 ]
print ( a == b )
print ( a == String )
print ( b == String )
# all true Portanto, String é apenas um alias para algo como DynamicVector[SIMD[DType.si8, 1]] .
VariadicList para desestruturar/descompactar/acessar argumentos from List import VariadicList
fn destructuring_arguments ( * args : Int ):
let my_var_list = VariadicList ( args )
for i in range ( len ( my_var_list )):
print ( "argument" , i , ":" , my_var_list [ i ])
destructuring_arguments ( 1 , 2 , 3 , 4 )É muito útil para criar coleções iniciais. Podemos escrever assim:
from Vector import DynamicVector
from StaticTuple import StaticTuple
fn create_vertor () - > DynamicVector [ Int ]:
let st = StaticTuple [ 4 , Int ]( 1 , 2 , 3 , 4 )
var v = DynamicVector [ Int ]( st . __len__ ())
for i in range ( st . __len__ ()):
v . push_back ( st [ i ])
return v
v = create_vertor ()
print ( v [ 0 ], v [ 3 ])
# or
from List import VariadicList
fn create_vertor () - > DynamicVector [ Int ]:
let var_list = VariadicList ( 1 , 2 , 3 , 4 )
var v = DynamicVector [ Int ]( len ( var_list ))
for i in range ( len ( var_list )):
v . push_back ( var_list [ i ])
return v
v = create_vertor ()
print ( v [ 0 ], v [ 3 ])Leia mais sobre as funções def e fn
from String import String
# String concatenation
print ( String ( "'" ) + String ( 1 ) + "' n " )
# Python's join
print ( String ( "|" ). join ( "a" , "b" , "c" ))
# String format
from IO import _printf as print
let x : Int = 1
print ( "'%i' n " , x . value )Para uma string, você pode usar o Builtin Slice com o formato string slice[start:end:step].
from String import String
let hello_mojo = String ( "Hello Mojo!" )
print ( "Till the end:" , hello_mojo [ 0 ::])
print ( "Before last 2 chars:" , hello_mojo [ 0 : - 2 ])
print ( "From start to the end with step 2:" , hello_mojo [ 0 :: 2 ])
print ( "From start to the before last with step 3:" , hello_mojo [ 0 : - 1 : 3 ])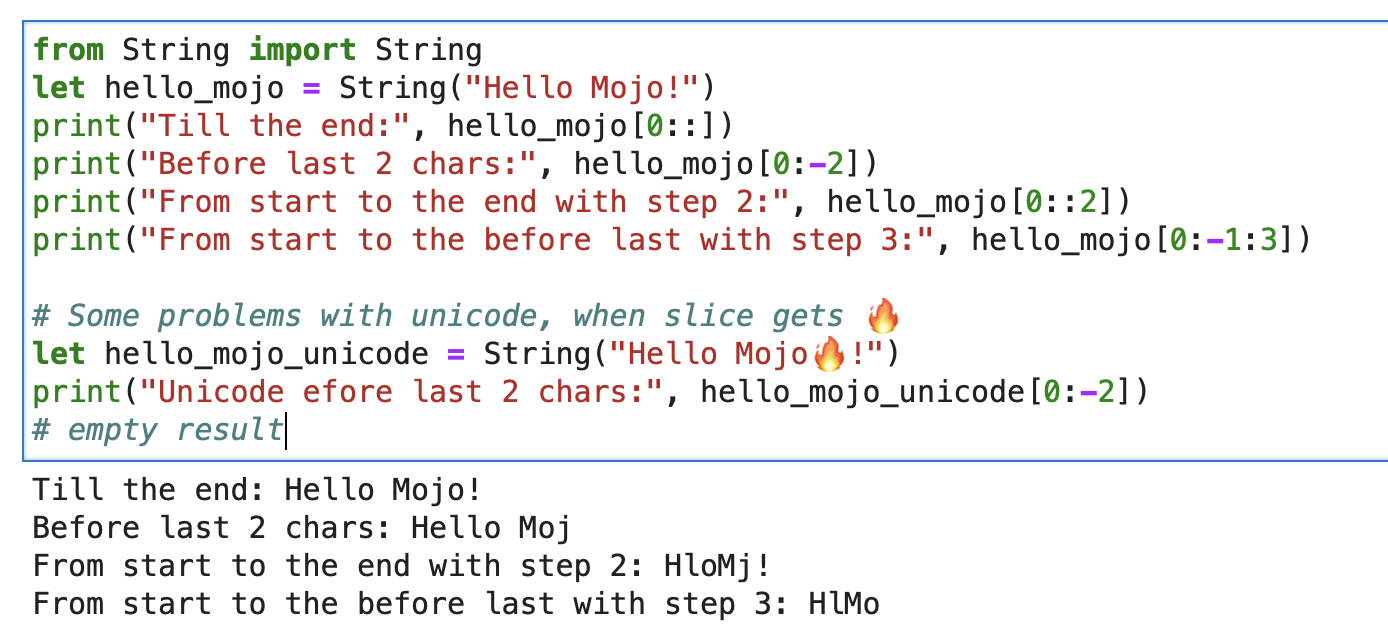
Há algum problema com o Unicode ao fatiar:
let hello_mojo_unicode = String ( "Hello Mojo!" )
print ( "Unicode efore last 2 chars:" , hello_mojo_unicode [ 0 : - 2 ])
# no result, silentsAqui está uma explicação e alguma discussão.
mbstowcs - converte uma string multibyte em uma string de caracteres largos
decorador struct , também conhecido como Python @dataclass . Ele irá gerar métodos __init__ , __copyinit__ , __moveinit__ para você automaticamente.
@ value
struct dataclass :
var name : String
var age : Int Observe que o decorador @value funciona apenas em tipos cujos membros são copyable e/ou movable .
Tipos triviais. Este decorador diz ao Mojo que o tipo deve ser copiável __copyinit__ e móvel __moveinit__ . Também diz ao Mojo para preferir passar o valor nos registros da CPU. Permite que structs optem por serem passadas em um register em vez de passarem pela memory .
@ register_passable ( "trivial" )
struct Int :
var value : __mlir_type . `!pop.scalar<index>`Decoradores que fornecem controle total sobre as otimizações do compilador . Instrui o compilador a sempre incorporar esta função quando ela for chamada.
@ always_inline
fn foo ( x : Int , y : Int ) - > Int :
return x + y
fn bar ( z : Int ):
let r = foo ( z , z ) # This call will be inlinedEle pode ser colocado em funções aninhadas que capturam valores de tempo de execução para criar fechamentos de captura “paramétricos”. Ele permite que encerramentos que capturam valores de tempo de execução sejam passados como valores de parâmetro.
@ always_inline
@ parameter
fn test (): return Alguns exemplos de elenco
s : StringLiteral
let p = DTypePointer [ DType . si8 ]( s . data ()). bitcast [ DType . ui8 ]()
var result = 0
result += (( p . simd_load [ 64 ]( offset ) >> 6 ) != 0b10 ). cast [ DType . ui8 ](). reduce_add (). to_int ()
let rest_p : DTypePointer [ DType . ui8 ] = stack_allocation [ simd_width , UI8 , 1 ]()
from Bit import ctlz
s : String
i : Int
let code = s . buffer . data . load ( i )
let byte_length_code = ctlz ( ~ code ). to_int ()DTypePointer - armazena um endereço com um determinado DType, permitindo alocar, carregar e modificar dados com acesso conveniente às operações SIMD.
from Pointer import DTypePointer
from DType import DType
from Random import rand
from Memory import memset_zero
# `heap`
var my_pointer_on_heap = DTypePointer [ DType . ui8 ]. alloc ( 8 )
memset_zero ( my_pointer_on_heap , 8 )
# `stack or register`
var data = my_pointer_on_heap . simd_load [ 8 ]( 0 )
print ( data )
rand ( my_pointer_on_heap , 4 )
# `data` does not contain a reference to the `heap`, so load the data again
data = my_pointer_on_heap . simd_load [ 8 ]( 0 )
print ( data )
# simd_load and simd_store
var half = my_pointer_on_heap . simd_load [ 4 ]( 0 )
half = half + 1
my_pointer_on_heap . simd_store [ 4 ]( 4 , half )
print ( my_pointer_on_heap . simd_load [ 8 ]( 0 ))
# Pointer move back
my_pointer_on_heap -= 1
print ( my_pointer_on_heap . simd_load [ 8 ]( 0 ))
# Mast free memory
my_pointer_on_heap . free ()Struct pode minimizar o potencial perigoso de ponteiros, limitando o aproveitamento.
Excelente artigo no blog Mojo Dojo sobre DTypePointer aqui
Além de seu exemplo Matrix Struct e DTypePointer
O ponteiro armazena um endereço para qualquer register_passable type e aloca n quantidade deles para o heap .
from Pointer import Pointer
from Memory import memset_zero
from String import String
@ register_passable # for syntaxt like `let coord = p1[0]` and let it be passed through registers.
struct Coord : # memory-only type
var x : UI8
var y : UI8
var p1 = Pointer [ Coord ]. alloc ( 2 )
memset_zero ( p1 , 2 )
var coord = p1 [ 0 ] # is an identifier to memory on the stack or in a register
print ( coord . x )
# Store the value
coord . x = 5
coord . y = 5
print ( coord . x )
# We need to store the data.
p1 . store ( 0 , coord )
print ( p1 [ 0 ]. x )
# Mast free memory
p1 . free ()Artigo completo sobre Ponteiro
Mais exemplo de ponteiro e estrutura
Modular Intrinsics é algum tipo de back-end de execução :
Mojo-> Dialetos MLIR -> backends de execução com código e arquiteturas de otimização.
MLIR é uma infraestrutura de compilador que implementa vários passos de transformação e otimização para diferentes linguagens de programação e arquiteturas .
O próprio MLIR não fornece funcionalidade direta para interagir com syscalls do sistema operacional.
Que são interfaces de baixo nível para serviços do sistema operacional, normalmente são tratadas no nível da linguagem de programação alvo ou do próprio sistema operacional. O MLIR foi projetado para ser independente de idioma e alvo, e seu foco principal é fornecer uma representação intermediária para realizar otimizações. Para realizar syscalls do sistema operacional no MLIR, precisamos usar um back-end específico do destino.
Mas com esses execution backends , basicamente, temos acesso aos syscalls do sistema operacional. E temos todo o mundo de coisas C/LLVM/Python nos bastidores.
Vamos dar uma olhada rápida na prática:
from OS import getenv
print ( getenv ( "PATH" ))
print ( getenv ( StringRef ( "PATH" )))
# or like this
from SIMD import SI8
from Intrinsics import external_call
var path1 = external_call [ "getenv" , StringRef ]( StringRef ( "PATH" ))
print ( path1 . data )
var path2 = external_call [ "getenv" , StringRef ]( "PATH" )
print ( path2 . data )
let abs_10 = external_call [ "abs" , SI8 , Int ]( - 10 )
print ( abs_10 ) Neste exemplo simples usamos external_call para obter a variável de ambiente do sistema operacional com um tipo de conversão entre as funções Mojo e libc. Muito legal, sim!
Tenho muitas ideias sobre este tópico e aguardo ansiosamente a oportunidade de implementá-las em breve. Agir pode levar a resultados surpreendentes =)
Vamos fazer algo interessante - chamar libc function gethostname.
A função possui esta interface int gethostname (char *name, size_t size) .
Para isso podemos usar a função auxiliar external_call do módulo Intrinsics ou escrever o próprio MLIR.
Vamos ao código:
from Intrinsics import external_call
from SIMD import SIMD , SI8
from DType import DType
from Vector import DynamicVector
from DType import DType
from Pointer import DTypePointer , Pointer
# We can use `from String import String` but for clarification we will use a full form.
# DynamicVector[SIMD[DType.si8, 1]] == DynamicVector[SI8] == String
# Compile time stuff.
alias cArrayOfStrings = DynamicVector [ SIMD [ DType . si8 , 1 ]]
alias capacity = 1024
var c_pointer_to_array_of_strings = DTypePointer [ DType . si8 ]( cArrayOfStrings ( capacity ). data )
var c_int_result = external_call [ "gethostname" , Int , DTypePointer [ DType . si8 ], Int ]( c_pointer_to_array_of_strings , capacity )
let mojo_string_result = String ( c_pointer_to_array_of_strings . address )
print ( "C function gethostname result code:" , c_int_result )
print ( "C function gethostname result value:" , star_hostname ( mojo_string_result ))
@ always_inline
fn star_hostname ( hostname : String ) - > String :
# [Builtin Slice](https://docs.modular.com/mojo/MojoBuiltin/BuiltinSlice.html)
# string slice[start:end:step]
return hostname [ 0 : - 1 : 2 ]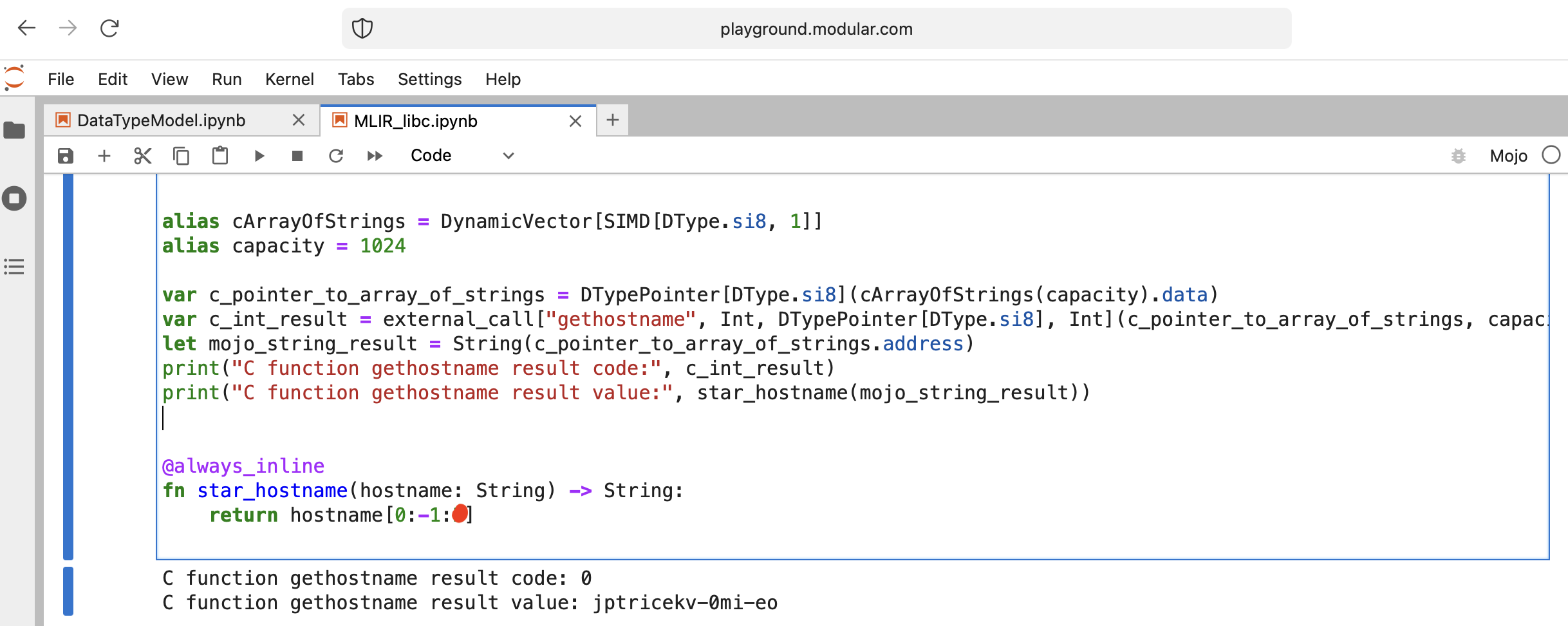
Vamos fazer algumas coisas para uma WEB com Mojo. Não temos acesso à Internet em playground.modular.com, mas podemos roubar e fazer algumas coisas interessantes, como TCP, em uma máquina.
Vamos escrever o primeiro código cliente-servidor TCP em Mojo com PythonInterface
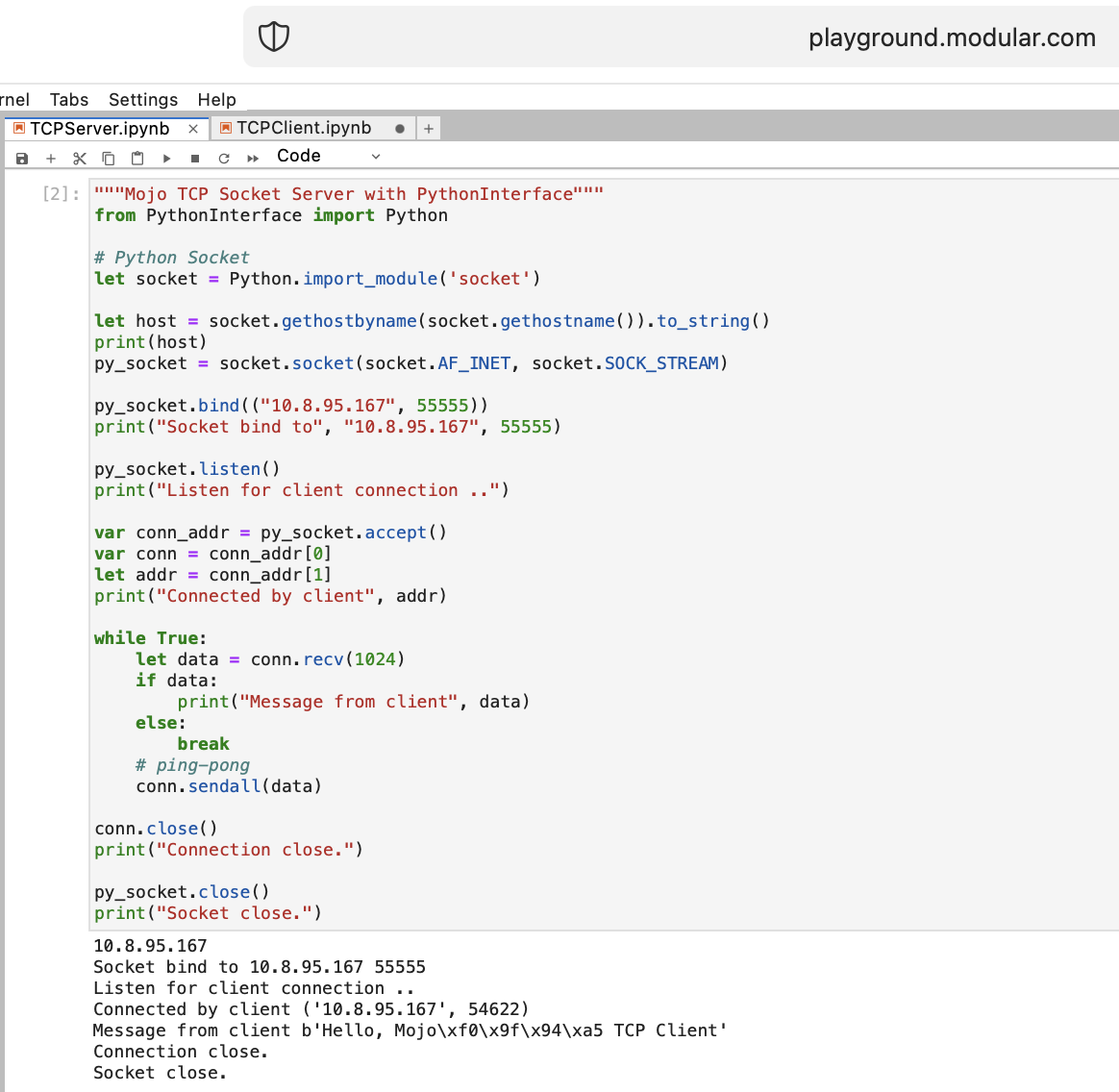
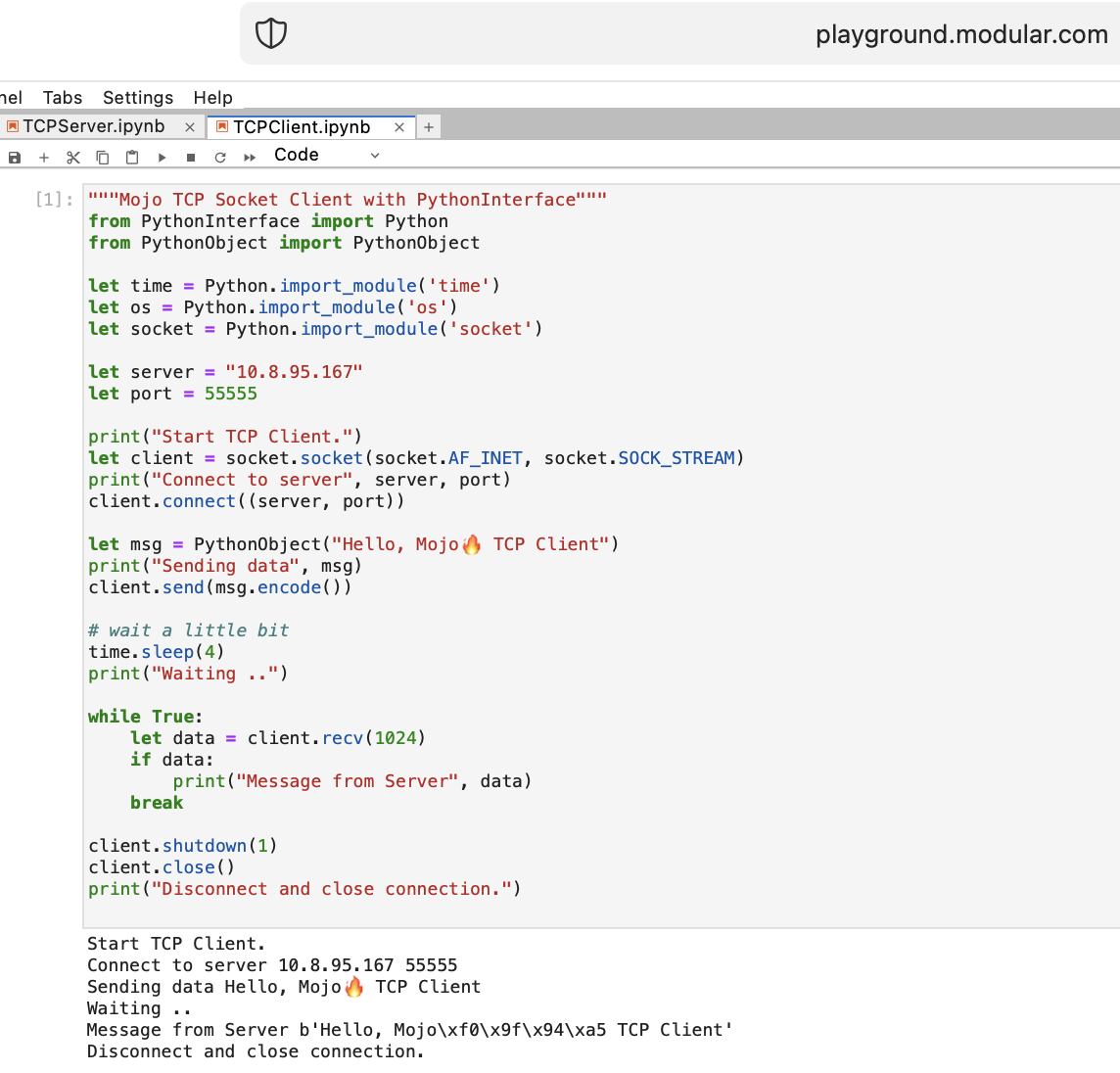
Você deve criar dois notebooks separados e executar TCPSocketServer primeiro e depois TCPSocketClient .
A versão Python deste código é quase a mesma, exceto:
with sintaxelet atribuira, b = (1, 2)Depois do TCP Server no Mojo vamos em frente =)
É uma loucura, mas vamos tentar executar o moderno servidor web Python FastAPI com Mojo!
Precisamos fazer upload do código FastAPI para o playground. Então, na sua máquina local faça
pip install --target=web fastapi uvicorn
tar -czPf web.tar.gz web e carregue web.tar.gz para o playground via interface web.
Depois precisamos install -lo, basta colocar na pasta apropriada:
% % python
import os
import site
site_packages_path = site . getsitepackages ()[ 0 ]
# install fastapi
os . system ( f"tar xzf web.tar.gz -C { site_packages_path } " )
os . system ( f"cp -r { site_packages_path } /web/* { site_packages_path } /" )
os . system ( f"ls { site_packages_path } | grep fastapi" )
# clean packages
os . system ( f"rm -rf { site_packages_path } /web" )
os . system ( f"rm web.tar.gz" ) from PythonInterface import Python
# Python fastapi
let fastapi = Python . import_module ( "fastapi" )
let uvicorn = Python . import_module ( "uvicorn" )
var app = fastapi . FastAPI ()
var router = fastapi . APIRouter ()
# tricky part
let py = Python ()
let py_code = """lambda: 'Hello Mojo!'"""
let py_obj = py . evaluate ( py_code )
print ( py_obj )
router . add_api_route ( "/mojo" , py_obj )
app . include_router ( router )
print ( "Start FastAPI WEB Server" )
uvicorn . run ( app )
print ( "Done" ) from PythonInterface import Python
let http_client = Python . import_module ( "http.client" )
let conn = http_client . HTTPConnection ( "localhost" , 8000 )
conn . request ( "GET" , "/mojo" )
let response = conn . getresponse ()
print ( response . status , response . reason , response . read ())Como de costume, você deve criar dois notebooks separados e executar FastAPI primeiro e depois FastAPIClient .
Há muitas questões em aberto, mas basicamente atingimos o objetivo.
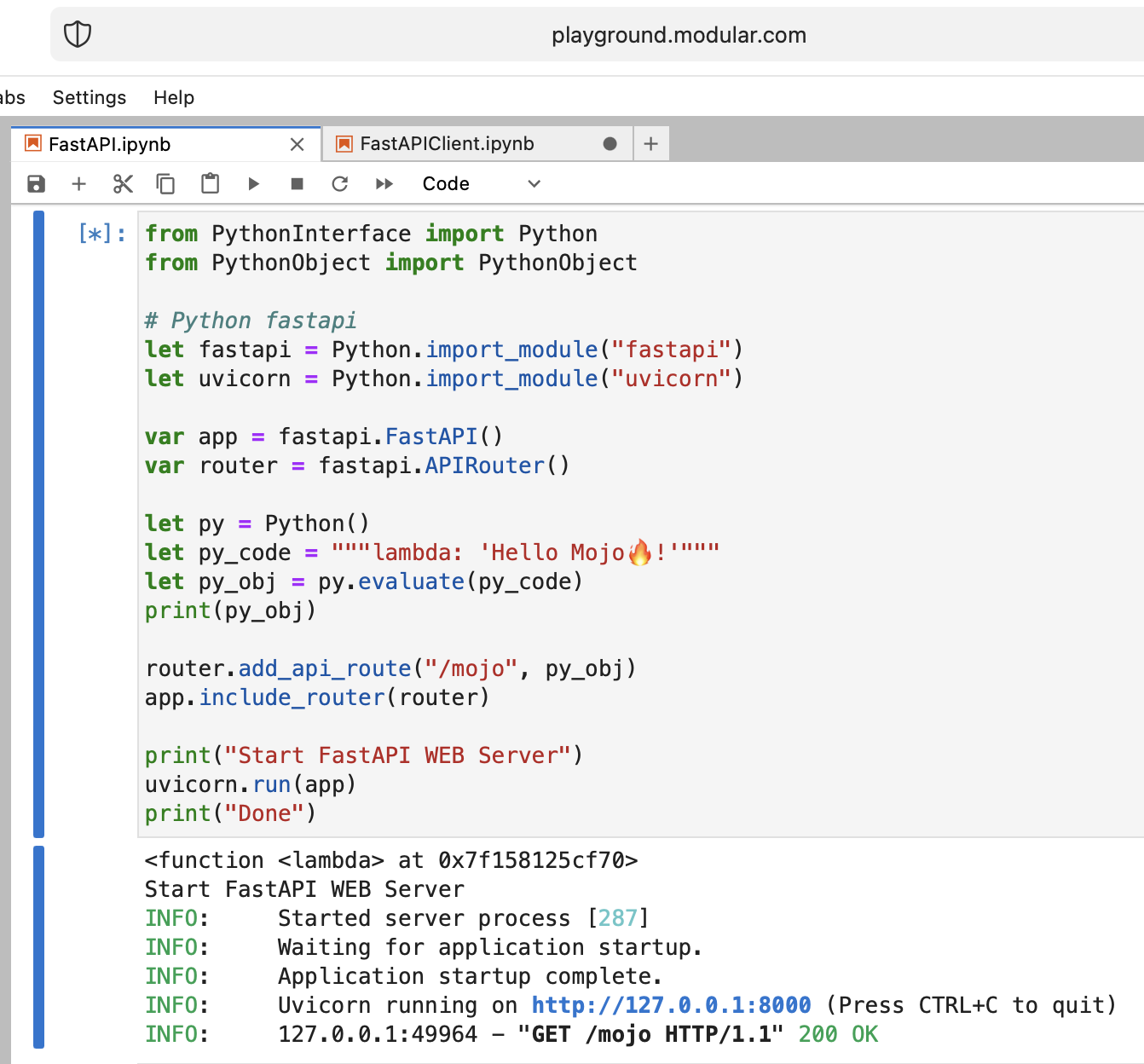
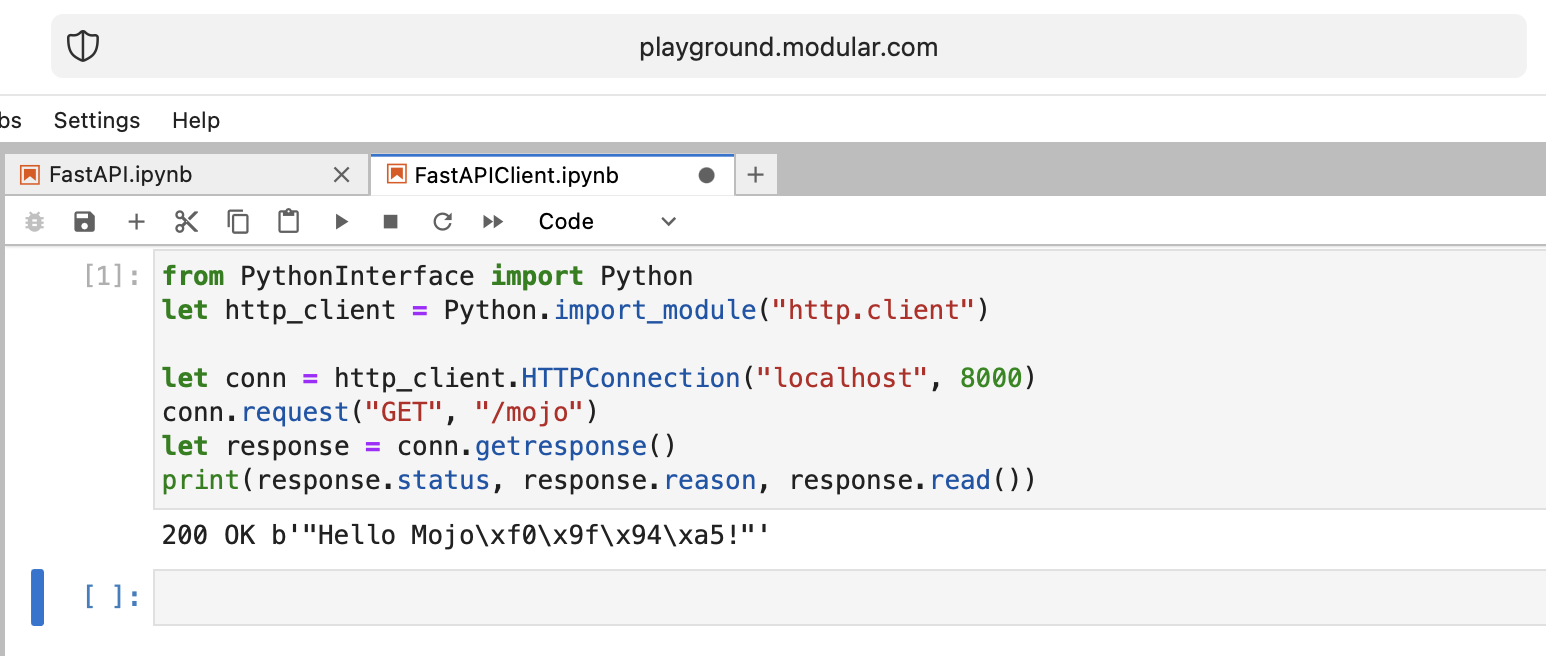
Muito bem!
Algumas questões abertas:
from PythonInterface import Python
let pyfn = Python . evaluate ( "lambda x, y: x+y" )
let functools = Python . import_module ( "functools" )
print ( functools . reduce ( pyfn , [ 1 , 2 , 3 , 4 ]))
# How to, without Mojo pyfn.so?
def pyfn ( x , y ):
retyrn x + yO futuro parece muito otimista!
Links:
Referência Mojo vs Numba por Nick Wogan
Utilitários de tempo por Samay Kapadia @Zalando
Conectando-se ao seu playground mojo a partir do VSCode ou DataSpell
por Maxim Zaks
from String import String
from PythonInterface import Python
let pathlib = Python . import_module ( 'pathlib' )
let txt = pathlib . Path ( 'nfl.csv' ). read_text ()
let s : String = txt . to_string ()implementação libc
from DType import DType
from Buffer import Buffer
from Pointer import Pointer
from String import String , chr
let hello = "hello"
let pointer = Pointer ( hello . data ())
print ( "variant 1" )
var result = String ()
for i in range ( len ( hello )):
result += chr ( pointer . bitcast [ Int8 ](). offset ( i ). load (). to_int ())
print ( result )
print ( "variant 2" )
print ( StringRef ( hello . data ()))
print ( "variant 3" )
print ( StringRef ( pointer . address ))
print ( "variant 4" )
let pm : Pointer [ __mlir_type . `!pop.scalar<si8>` ] = Pointer ( hello . data ())
print ( StringRef ( pm . address ))
print ( "variant 5" )
print ( String ( pointer . address ))
print ( "variant 6" )
let x = Buffer [ 8 , DType . int8 ]( pointer )
let array = x . simd_load [ 10 ]( 0 )
var result = String ()
for i in range ( len ( array )):
result += chr ( array [ i ]. to_int ())
print ( result )right click no arquivo no explorer e pressione Open With > Editorselect all e copy.ipynbO Github o renderiza corretamente e, se alguém quiser experimentar o código em seu playground, poderá copiar e colar o código bruto.
É minha opinião pessoal, então não me julgue com muita severidade.
Não posso dizer que o Mojo seja uma linguagem de programação fácil de aprender, como o Python por exemplo.
Requer muita compreensão, paciência e experiência em qualquer outra linguagem de programação.
Se você quiser construir algo que não seja trivial, será difícil, mas engraçado!
Já se passaram 2 semanas desde que embarquei nesta jornada e estou emocionado em compartilhar que agora me familiarizei bem com o Mojo.
As complexidades da sua estrutura e sintaxe começaram a desvendar-se diante dos meus olhos e estou repleto de uma nova compreensão .
Tenho orgulho de dizer que agora posso criar códigos nessa linguagem com confiança, o que me permite dar vida a uma ampla gama de ideias .
Mojo é uma linguagem de programação Modular Inc. Por que Mojo discutimos aqui. Sobre a Company sabemos menos, mas ela tem um nome muito bacana Modular , que pode ser referenciado:
"Em outras palavras: Mojo não é mágico, é modular."
Tudo sobre computação, programação, IA/ML. Um nome de domínio muito bom que descreve com precisão o significado da Empresa.
Existem alguns materiais adicionais sobre a história da marca da Modular e como ajudar a Modular a humanizar a IA por meio da marca
Hoje eu gostaria de contar uma história sobre o problema do Python Enum. Como engenheiros de software, frequentemente encontramos isso na WEB. Suponha que temos este esquema de banco de dados (PostgreSQL) com status enum :
CREATE TYPE public .status_type AS ENUM (
' FIRST ' ,
' SECOND '
);Em um código Python, precisamos de nomes e valores como strings (suponha que usamos GraphQL com algum tipo ENUM para nosso frontend) e precisamos manter sua ordem e ter capacidade de comparar essas enumerações:
order2.status > order1.status > 'FIRST'
Portanto, é um problema para a maioria das linguagens comuns =), mas podemos usar um recurso little-known do Python e substituir o método da classe enum: __new__ .
MALE -> 1 , FEMALE -> 2 , como o PostgreSQL faz.len ! import enum
from functools import total_ordering
@ total_ordering
@ enum . unique
class BaseUniqueSortedEnum ( enum . Enum ):
"""Base unique enum class with ordering."""
def __new__ ( cls , * args , ** kwargs ):
obj = object . __new__ ( cls )
obj . index = len ( cls . __members__ ) + 1 # This code line is a piece of advice, an insight and a tip!
return obj
# and then boring Python's magic methods as usual...
def __hash__ ( self ) -> int :
return hash (
f" { self . __module__ } _ { self . __class__ . __name__ } _ { self . name } _ { self . value } "
)
def __eq__ ( self , other ) -> bool :
self . _check_type ( other )
return super (). __eq__ ( other )
def __lt__ ( self , other ) -> bool :
self . _check_type ( other )
return self . index < other . index
def _check_type ( self , other ) -> None :
if type ( self ) != type ( other ):
raise TypeError ( f"Different types of Enum: { self } != { other } " )
class Dog ( BaseUniqueSortedEnum ):
# THIS ORDER MATTERS!
BLOODHOUND = "BLOODHOUND"
WEIMARANER = "WEIMARANER"
SAME = "SAME"
class Cat ( BaseUniqueSortedEnum )
# THIS ORDER MATTERS!
BRITISH = "BRITISH"
SCOTTISH = "SCOTTISH"
SAME = "SAME"
# and some tests
assert Dog . BLOODHOUND < Dog . WEIMARANER
assert Dog . BLOODHOUND <= Dog . WEIMARANER
assert Dog . BLOODHOUND != Dog . WEIMARANER
assert Dog . BLOODHOUND == Dog . BLOODHOUND
assert Dog . WEIMARANER == Dog . WEIMARANER
assert Dog . WEIMARANER > Dog . BLOODHOUND
assert Dog . WEIMARANER >= Dog . BLOODHOUND
assert Cat . BRITISH < Cat . SCOTTISH
assert Cat . BRITISH <= Cat . SCOTTISH
assert Cat . BRITISH != Cat . SCOTTISH
assert Cat . BRITISH == Cat . BRITISH
assert Cat . SCOTTISH == Cat . SCOTTISH
assert Cat . SCOTTISH > Cat . BRITISH
assert Cat . SCOTTISH >= Cat . BRITISH
assert hash ( Dog . BLOODHOUND ) == hash ( Dog . BLOODHOUND )
assert hash ( Dog . WEIMARANER ) == hash ( Dog . WEIMARANER )
assert hash ( Dog . BLOODHOUND ) != hash ( Dog . WEIMARANER )
assert hash ( Dog . SAME ) != hash ( Cat . SAME )
# raise TypeError
Dog . SAME <= Cat . SAME
Dog . SAME < Cat . SAME
Dog . SAME > Cat . SAME
Dog . SAME >= Cat . SAME
Dog . SAME != Cat . SAME O fim da história. e use este insight Python ENUM para sua boa codificação!


