cnn svm
1.0.0
Este projeto foi inspirado no Deep Learning de Y. Tang usando Linear Support Vector Machines (2013).
O artigo completo sobre este projeto pode ser lido em arXiv.org.
As redes neurais convolucionais (CNNs) são semelhantes às redes neurais "comuns" no sentido de que são compostas de camadas ocultas que consistem em neurônios com parâmetros "aprendíveis". Esses neurônios recebem entradas, executam um produto escalar e o seguem com uma não linearidade. Toda a rede expressa o mapeamento entre os pixels da imagem bruta e suas pontuações de classe. Convencionalmente, a função Softmax é o classificador utilizado na última camada desta rede. No entanto, existem estudos (Alalshekmubarak e Smith, 2013; Agarap, 2017; Tang, 2013) realizados para desafiar esta norma. Os estudos citados introduzem o uso de máquina de vetores de suporte linear (SVM) em uma arquitetura de rede neural artificial. Este projeto é mais uma abordagem ao assunto e é inspirado em (Tang, 2013). Dados empíricos mostraram que o modelo CNN-SVM foi capaz de atingir uma precisão de teste de ~99,04% usando o conjunto de dados MNIST (LeCun, Cortes e Burges, 2010). Por outro lado, o CNN-Softmax conseguiu atingir uma precisão de teste de ~99,23% usando o mesmo conjunto de dados. Ambos os modelos também foram testados no conjunto de dados Fashion-MNIST recentemente publicado (Xiao, Rasul e Vollgraf, 2017), que é suposto ser um conjunto de dados de classificação de imagens mais difícil do que o MNIST (Zalandoresearch, 2017). Isso provou ser o caso, pois o CNN-SVM atingiu uma precisão de teste de ~90,72%, enquanto o CNN-Softmax atingiu uma precisão de teste de ~91,86%. Os referidos resultados podem ser melhorados se técnicas de pré-processamento de dados forem empregadas nos conjuntos de dados, e se o modelo base da CNN for relativamente mais sofisticado do que o utilizado neste estudo.
Primeiro, clone o projeto.
git clone https://github.com/AFAgarap/cnn-svm.git/ Execute setup.sh para garantir que as bibliotecas de pré-requisitos estejam instaladas no ambiente.
sudo chmod +x setup.sh
./setup.shParâmetros do programa.
usage: main.py [-h] -m MODEL -d DATASET [-p PENALTY_PARAMETER] -c
CHECKPOINT_PATH -l LOG_PATH
CNN & CNN-SVM for Image Classification
optional arguments:
-h, --help show this help message and exit
Arguments:
-m MODEL, --model MODEL
[1] CNN-Softmax, [2] CNN-SVM
-d DATASET, --dataset DATASET
path of the MNIST dataset
-p PENALTY_PARAMETER, --penalty_parameter PENALTY_PARAMETER
the SVM C penalty parameter
-c CHECKPOINT_PATH, --checkpoint_path CHECKPOINT_PATH
path where to save the trained model
-l LOG_PATH, --log_path LOG_PATH
path where to save the TensorBoard logs Em seguida, acesse o diretório do repositório e execute o módulo main.py conforme os parâmetros desejados.
cd cnn-svm
python3 main.py --model 2 --dataset ./MNIST_data --penalty_parameter 1 --checkpoint_path ./checkpoint --log_path ./logsOs hiperparâmetros utilizados neste projeto foram atribuídos manualmente, e não por meio de otimização.
| Hiperparâmetros | CNN-Softmax | CNN-SVM |
|---|---|---|
| Tamanho do lote | 128 | 128 |
| Taxa de aprendizagem | 1e-3 | 1e-3 |
| Passos | 10.000 | 10.000 |
| SVMC | N / D | 1 |
Os experimentos foram conduzidos em um laptop com CPU Intel Core (TM) i5-6300HQ a 2,30 GHz x 4, 16 GB de RAM DDR3 e GPU NVIDIA GeForce GTX 960M 4 GB DDR5.
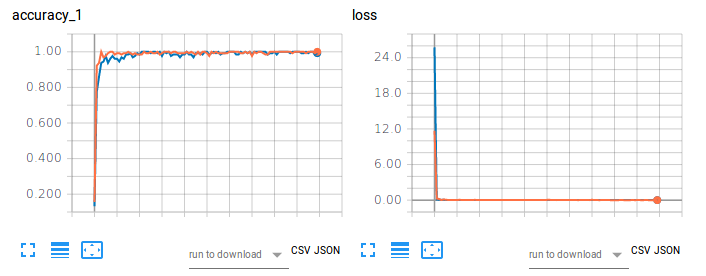
Figura 1. Precisão de treinamento (esquerda) e perda (direita) de CNN-Softmax e CNN-SVM na classificação de imagens usando MNIST.
O gráfico laranja refere-se à precisão e perda de treinamento do CNN-Softmax, com uma precisão de teste de 99,22999739646912%. Por outro lado, o gráfico azul refere-se à acurácia e perda de treinamento do CNN-SVM, com acurácia do teste de 99,04000163078308%. Os resultados não corroboram os achados de Tang (2017) para a classificação de dígitos manuscritos do MNIST. Isto pode ser atribuído ao fato de que nenhum pré-processamento de dados nem redução de dimensionalidade foram feitos no conjunto de dados deste projeto.
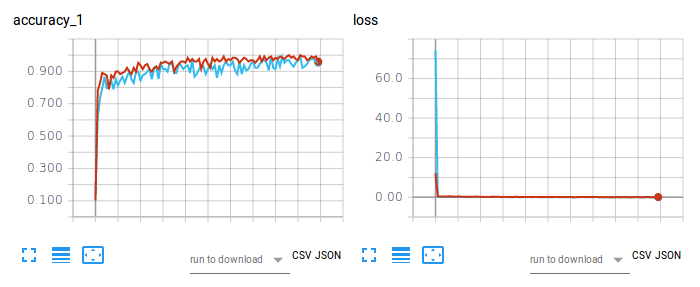
Figura 2. Precisão de treinamento (esquerda) e perda (direita) de CNN-Softmax e CNN-SVM na classificação de imagens usando Fashion-MNIST.
O gráfico vermelho refere-se à precisão e perda de treinamento do CNN-Softmax, com uma precisão de teste de 91,86000227928162%. Por outro lado, o gráfico em azul claro refere-se à precisão do treinamento e perda do CNN-SVM, com precisão do teste de 90,71999788284302%. O resultado da CNN-Softmax corrobora a constatação da zalandoresearch no Fashion-MNIST.
Para citar o artigo, por favor use a seguinte entrada BibTex:
@article{agarap2017architecture,
title={An Architecture Combining Convolutional Neural Network (CNN) and Support Vector Machine (SVM) for Image Classification},
author={Agarap, Abien Fred},
journal={arXiv preprint arXiv:1712.03541},
year={2017}
}
Para citar o repositório/software, use a seguinte entrada BibTex:
@misc{abien_fred_agarap_2017_1098369,
author = {Abien Fred Agarap},
title = {AFAgarap/cnn-svm v0.1.0-alpha},
month = dec,
year = 2017,
doi = {10.5281/zenodo.1098369},
url = {https://doi.org/10.5281/zenodo.1098369}
}
Copyright 2017-2020 Abien Fred Agarap
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


