q transformer
0.3.0
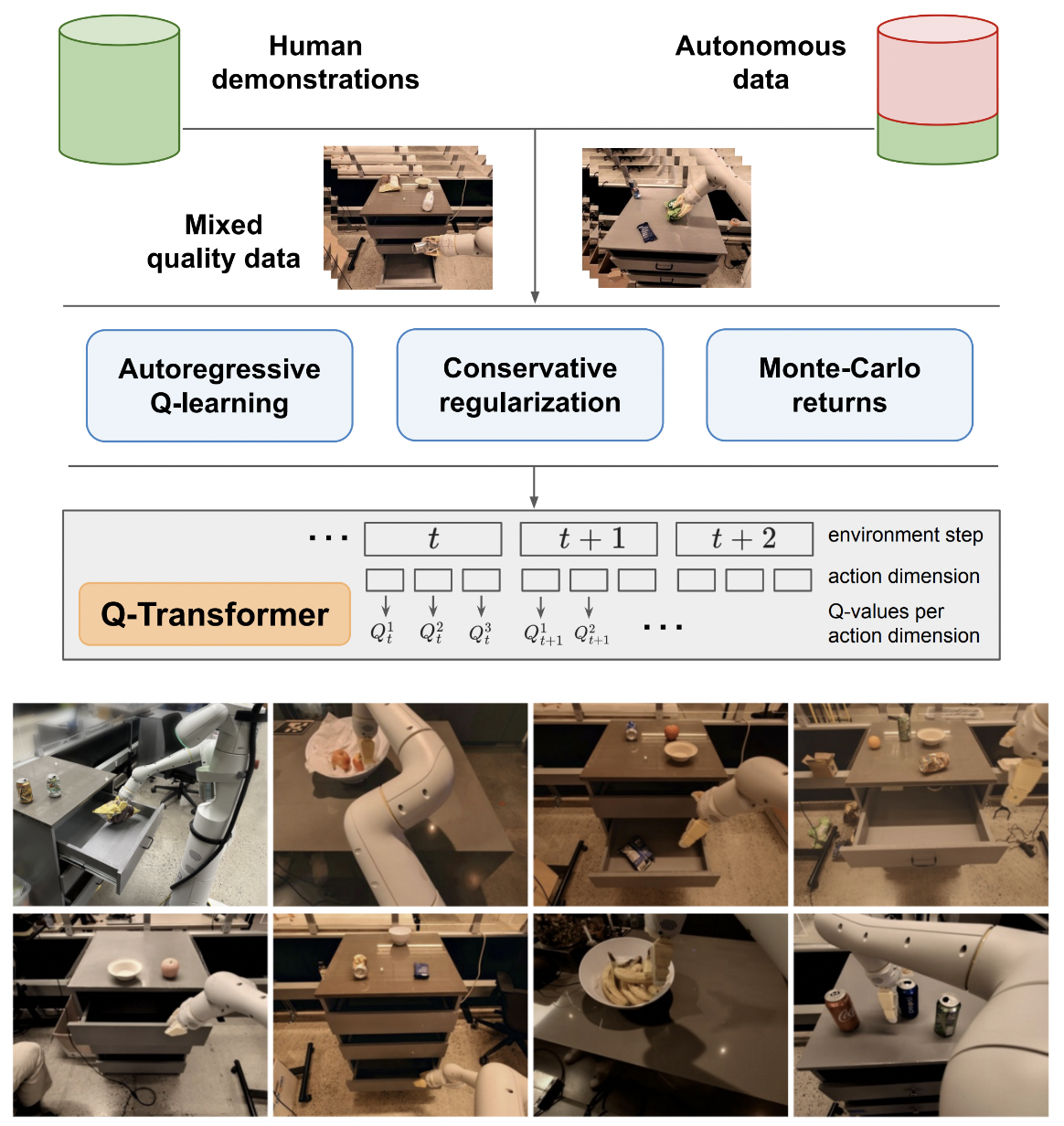
Implementação de Q-Transformer, aprendizado de reforço off-line escalável por meio de Q-Functions autoregressivas, fora do Google Deepmind
Manterei a lógica do Q-learning em ação única apenas para comparação final com o Q-learning autorregressivo proposto em múltiplas ações. Também para servir de educação para mim e para o público.
A formulação autoregressiva de Q-learning foi reproduzida por Kotb et al.
$ pip install q-transformer import torch
from q_transformer import (
QRoboticTransformer ,
QLearner ,
Agent ,
ReplayMemoryDataset
)
# the attention model
model = QRoboticTransformer (
vit = dict (
num_classes = 1000 ,
dim_conv_stem = 64 ,
dim = 64 ,
dim_head = 64 ,
depth = ( 2 , 2 , 5 , 2 ),
window_size = 7 ,
mbconv_expansion_rate = 4 ,
mbconv_shrinkage_rate = 0.25 ,
dropout = 0.1
),
num_actions = 8 ,
action_bins = 256 ,
depth = 1 ,
heads = 8 ,
dim_head = 64 ,
cond_drop_prob = 0.2 ,
dueling = True
)
# you need to supply your own environment, by overriding BaseEnvironment
from q_transformer . mocks import MockEnvironment
env = MockEnvironment (
state_shape = ( 3 , 6 , 224 , 224 ),
text_embed_shape = ( 768 ,)
)
# env.init() should return instructions and initial state: Tuple[str, Tensor[*state_shape]]
# env(actions) should return rewards, next state, and done flag: Tuple[Tensor[()], Tensor[*state_shape], Tensor[()]]
# agent is a class that allows the q-model to interact with the environment to generate a replay memory dataset for learning
agent = Agent (
model ,
environment = env ,
num_episodes = 1000 ,
max_num_steps_per_episode = 100 ,
)
agent ()
# Q learning on the replay memory dataset on the model
q_learner = QLearner (
model ,
dataset = ReplayMemoryDataset (),
num_train_steps = 10000 ,
learning_rate = 3e-4 ,
batch_size = 4 ,
grad_accum_every = 16 ,
)
q_learner ()
# after much learning
# your robot should be better at selecting optimal actions
video = torch . randn ( 2 , 3 , 6 , 224 , 224 )
instructions = [
'bring me that apple sitting on the table' ,
'please pass the butter'
]
actions = model . get_optimal_actions ( video , instructions )primeiro caminho para o apoio a uma acção única
oferecer variante sem lote padrão do maxvit, como feito no modelo meteorológico SOTA metnet3
adicione arquitetura opcional de duelo profundo
adicionar aprendizagem Q em n etapas
construir a regularização conservadora
construir a proposta principal no papel (ações discretas autorregressivas até a última ação, recompensa dada apenas na última)
variante improvisada da cabeça do decodificador, em vez de concatenar ações anteriores no estágio de quadros + tokens aprendidos. em outras palavras, use o codificador - decodificador clássico
refazer maxvit com embeddings rotativos axiais + gating sigmóide para não atender a nada. habilite a atenção flash para maxvit com esta mudança
construir uma classe criadora de conjunto de dados simples, considerando o ambiente e o modelo e retornando uma pasta que pode ser aceita por um ReplayDataset
ReplayDataset que leva na pasta lidar com múltiplas instruções corretamente
mostre um exemplo simples de ponta a ponta, no mesmo estilo de todos os outros repositórios
não lide com instruções, aproveite o condicionador nulo na biblioteca CFG
cache kv para decodificação de ação
para exploração, permitem randomizar com precisão um subconjunto de ações, e não todas as ações de uma vez
consulte alguns especialistas em RL e descubra se há algum novo progresso na resolução do preconceito delirante
descobrir se é possível treinar com ordens aleatórias de ações - a ordem pode ser enviada como um condicionamento que é concatenado ou somado antes das camadas de atenção
função simples de busca de feixe para ações ideais
improvisar atenção cruzada para ações passadas e estados de timestep, estilo transformer-xl (com eliminação de memória estruturada)
veja se a ideia principal deste artigo é aplicável aos modelos de linguagem aqui
@inproceedings { qtransformer ,
title = { Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions } ,
authors = { Yevgen Chebotar and Quan Vuong and Alex Irpan and Karol Hausman and Fei Xia and Yao Lu and Aviral Kumar and Tianhe Yu and Alexander Herzog and Karl Pertsch and Keerthana Gopalakrishnan and Julian Ibarz and Ofir Nachum and Sumedh Sontakke and Grecia Salazar and Huong T Tran and Jodilyn Peralta and Clayton Tan and Deeksha Manjunath and Jaspiar Singht and Brianna Zitkovich and Tomas Jackson and Kanishka Rao and Chelsea Finn and Sergey Levine } ,
booktitle = { 7th Annual Conference on Robot Learning } ,
year = { 2023 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Kumar2023MaintainingPI ,
title = { Maintaining Plasticity in Continual Learning via Regenerative Regularization } ,
author = { Saurabh Kumar and Henrik Marklund and Benjamin Van Roy } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:261076021 }
}

